논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
언어 모델에서의 다중 모달 사고 과정 추론
Zhuosheng Zhang Aston Zhang Mu Li Hai Zhao George Karypis Alex Smola
초록
대규모 언어 모델(LLMs)은 사고 과정 추론(chain-of-thought, ) 프롬프팅을 활용하여 중간 추론 과정을 생성하고 그 근거를 바탕으로 답을 추론함으로써 복잡한 추론 작업에서 인상적인 성능을 보여주었습니다. 그러나 기존의 CoT 연구는 언어 모달리티에 초점을 맞추었습니다. 우리는 언어(텍스트)와 시각(이미지) 모달리티를 포함하는 이단계 프레임워크인 다중 모달-CoT(Multimodal-CoT)을 제안합니다. 이를 통해 답변 추론은 다중 모달 정보에 기반한 더 나은 근거를 생성하여 활용할 수 있습니다. 다중 모달-CoT를 사용하여, 10억 개 미만의 파라미터를 가진 우리 모델은 이전 최고 성능의 LLM(GPT-3.5)을 16 퍼센트 포인트 정확도 상회하며 심지어 ScienceQA 벤치마크에서 인간의 성능을 뛰어넘습니다. 코드는 공개적으로 이용 가능합니다.
1. 서론
그림이나 표가 없는 교과서를 상상해보세요. 우리의 지식 습득 능력은 시각, 언어, 오디오와 같은 다양한 데이터 모달리티를 함께 모델링함으로써 크게 강화됩니다. 최근 대규모 언어 모델(LLMs) (Brown et al., 2020; Thoppilan et al., 2022; Rae et al., 2021; Chowdhery et al., 2022)은 답을 추론하기 전에 중간 추론 단계를 생성함으로써 복잡한 추론 작업에서 인상적인 성능을 보여주었습니다. 이 흥미로운 기술은 사고 과정 추론(chain-of-thought, CoT)이라고 불립니다 (Wei et al., 2022b; Kojima et al., 2022; Zhang et al., 2022).
그러나 기존의 CoT 추론 관련 연구는 대부분 언어 모달리티에 한정되어 있으며 (Wang et al., 2022b; Zhou et al., 2022; Lu et al., 2022b; Fu et al., 2022), 다중 모달 시나리오를 거의 고려하지 않았습니다. 다중 모달 상황에서 CoT 추론을 유도하기 위해, 우리는 다중 모달-CoT(Multimodal-CoT)을 제안합니다.(https://github.com/amazon-science/mm-cot)
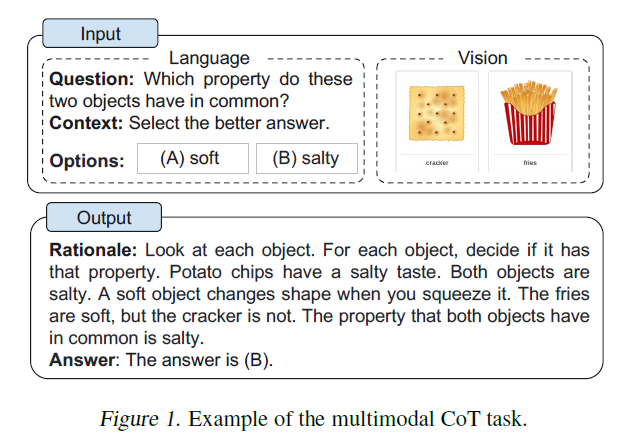
그림 1. 다중모달 CoT 과제의 예.
CoT 패러다임. 다양한 모달리티의 입력을 주어진 상태에서, 다중모달-CoT는 다단계 문제를 중간 추론 단계(이유)로 분해한 다음 답을 추론합니다. 시각과 언어가 가장 인기 있는 모달리티이므로, 이 작업에서는 이 두 모달리티에 초점을 맞춥니다. 예시는 그림 1에 나와 있습니다. 일반적으로, 다중모달 CoT 추론을 유도하는 두 가지 방법은 다음과 같습니다: (i) LLMs에 프롬프트를 주기 (ii) 작은 모델을 미세조정하기.
다중모달-CoT를 수행하는 가장 직접적인 방법은 다른 모달리티의 입력을 하나의 모달리티로 변환하고 LLMs에 CoT를 수행하도록 프롬프트를 주는 것입니다. 예를 들어, 이미지의 캡션을 캡셔닝 모델로 추출한 다음, 원래의 언어 입력과 함께 연결하여 LLMs에 입력하는 것이 가능합니다(루 외, 2022a). 그러나 캡셔닝 과정에서 심각한 정보 손실이 발생하기 때문에, 캡션(시각 특징과 대비하여)을 사용하는 것은 다른 모달리티의 표현 공간에서 상호 시너지가 부족할 수 있습니다.
모달리티 간 상호작용을 촉진하기 위한 또 다른 가능한 해결책은 다중모달 특징을 융합하여 작은 언어 모델(LMs)을 미세조정하는 것입니다(장 외, 2023). 이 접근법은 모델 아키텍처를 조정하여 다중모달 특징을 통합할 수 있는 유연성을 제공하기 때문에, 우리는 이 작업에서 LLMs에 프롬프트를 주는 대신 모델을 미세조정하는 것을 연구합니다. 주요 도전 과제는 1000억 개 미만의 파라미터를 가진 언어 모델이 답 추론을 오도하는 환상적인 이유를 생성하는 경향이 있다는 것입니다(호 외, 2022; 마지스터 외, [^2]
표 1. 전형적인 CoT 기술(FT: 미세조정; KD: 지식 증류). 세그먼트 1: 문맥 내 학습 기술; 세그먼트 2: 미세조정 기술. 우리가 알기로, 우리의 작업은 다른 모달리티에서 CoT 추론을 연구하는 최초의 작업입니다. 또한, 우리는 LLMs의 출력에 의존하지 않고 10억 모델에 초점을 맞춥니다.
환각(hallucination) 문제를 완화하기 위해, 우리는 언어(텍스트)와 시각(이미지) 모달리티를 포함하는 Multimodal-CoT를 제안합니다. 이는 근거 생성과 답변 추론을 분리하는 두 단계 프레임워크를 사용합니다. 이 방식을 통해 답변 추론은 다중 모달 정보에 기반한 더 나은 생성된 근거를 활용할 수 있습니다. 우리의 실험은 ScienceQA 벤치마크(Lu et al., 2022a)에서 수행되었는데, 이는 주석이 달린 추론 체인이 있는 최신의 다중 모달 추론 벤치마크입니다. 실험 결과, 우리의 방법은 벤치마크에서 이전의 최신 기술인 GPT-3.5 모델을 로 능가함을 보여줍니다. 우리의 기여는 다음과 같이 요약됩니다:
(i) 우리가 알기로, 이 작업은 다른 모달리티에서 CoT 추론을 연구하는 최초의 작업입니다.
(ii) 우리는 언어 모델을 미세 조정하여 시각과 언어 표현을 융합하고 Multimodal-CoT를 수행하는 두 단계 프레임워크를 제안합니다. 이 모델은 최종 답변을 추론하는 데 도움이 되는 정보적인 근거를 생성할 수 있습니다.
(iii) 우리의 방법은 ScienceQA 벤치마크에서 새로운 최신 기술 성능을 달성하여 GPT-3.5의 정확도를 능가하고 심지어 인간의 성능까지 능가합니다.
2. 배경
이 섹션에서는 언어 모델을 프롬프트하고 미세 조정하여 CoT 추론을 유도하는 최근의 진전을 검토합니다.
2.1. LLMs와 CoT 추론
최근에 CoT는 LLMs의 다단계 추론 능력을 유도하는 데 널리 사용되었습니다(Wei et al., 2022b). 구체적으로, CoT 기술은 LLM이 문제를 해결하기 위한 중간 추론 체인을 생성하도록 장려합니다. 연구에 따르면 LLMs는 두 가지 주요 기술 패러다임을 사용하여 CoT 추론을 수행할 수 있습니다: Zero-Shot-CoT(Kojima et al., 2022)과 Few-Shot-CoT(Wei et al., 2022b; Zhang et al., 2022). Zero-Shot-CoT의 경우, Kojima et al. (2022)은 "Let's think step by step"과 같은 프롬프트를 테스트 질문 뒤에 추가하여 CoT 추론을 유도함으로써 LLMs가 괜찮은 제로샷 추론자임을 보여주었습니다. Few-Shot-CoT의 경우, 몇 가지 단계별 추론 시연이 추론을 위한 조건으로 사용됩니다. 각 시연에는 질문과 최종 답변으로 이어지는 추론 체인이 있습니다. 이 시연들은 일반적으로 수작업으로 만들어지거나 자동 생성됩니다. 따라서 해당 기술은 Manual-CoT(Wei et al., 2022b)과 Auto-CoT(Zhang et al., 2022)로 불립니다.
효과적인 시연(demonstrations)을 통해 Few-Shot-CoT는 종종 Zero-Shot-CoT보다 더 강력한 성능을 달성하며 더 많은 연구 관심을 끌고 있습니다. 따라서 최근 연구들은 Few-Shot-CoT를 개선하는 방법에 초점을 맞추고 있습니다. 이러한 연구들은 두 가지 주요 연구 분야로 분류됩니다: (i) 시연 최적화; (ii) 추론 체인 최적화. 표 1은 전형적인 CoT 기술들을 비교합니다.
시연 최적화(Few-Shot-CoT의 성능은 시연의 질에 달려 있습니다. Wei et al. (2022b)에 따르면, 서로 다른 주석자(annotators)가 작성한 시연을 사용하면 기호 추론 작업(symbolic reasoning task)에서 정확도에 큰 차이가 발생합니다. 시연을 수작업으로 만드는 것을 넘어서, 최근 연구들은 시연 선택 과정을 최적화하는 방법을 조사하고 있습니다. 특히 Rubin et al. (2022)은 테스트 인스턴스와 의미적으로 유사한 시연을 검색했습니다. 그러나 이 접근법은 추론 체인에 오류가 있을 때 성능이 저하된다는 것을 보여줍니다(Zhang et al., 2022). 이러한 한계를 해결하기 위해, Zhang et al. (2022)은 시연 질문의 다양성이 핵심이라는 것을 발견하고 Auto-CoT을 제안했습니다: (i) 주어진 데이터셋의 질문을 몇 개의 클러스터로 나누기; (ii) 각 클러스터에서 대표 질문을 샘플링하고 간단한 휴리스틱(heuristics)을 사용하여 Zero-Shot-CoT으로 그 추론 체인을 생성하기. 또한, 강화 학습(reinforcement learning, RL)과 복잡도 기반 선택 전략도 효과적인 시연을 얻기 위해 제안되었습니다. Fu et al. (2022)은 복잡한 추론 체인(즉, 더 많은 추론 단계를 가진)을 가진 예시들을 시연으로 선택했습니다. Lu et al. (2022b)은 후보군에서 최적의 문맥 예시(in-context examples)를 찾고 GPT-3.5와 상호 작용할 때 주어진 훈련 예시들에 대한 예측 보상을 극대화하는 에이전트를 훈련시켰습니다.
추론 체인 최적화 추론 체인을 최적화하는 주목할 만한 방법은 문제 분해(problem decomposition)입니다. Zhou et al. (2022)은 복잡한 문제를 하위 문제로 분해하고 이러한 하위 문제들을 순차적으로 해결하는 최소-최대 프롬프팅(least-to-most prompting)을 제안했습니다. 결과적으로, 주어진 하위 문제를 해결하는 것은 이전에 해결된 하위 문제들의 답에 의해 용이해집니다. 마찬가지로, Khot et al. (2022)은 다양한 분해 구조를 사용하고 각 하위 질문에 답하기 위해 다른 프롬프트를 설계했습니다. 추론 체인을 자연어 텍스트로 프롬프팅하는 것 외에도, Chen et al. (2022)은 추론 과정을 프로그램으로 모델링하고 생성된 프로그램을 실행하여 답을 도출하도록 LLMs(Large Language Models)에 프롬프트하는 프로그램-오브-생각(program-of-thoughts, PoT)을 제안했습니다. 또 다른 추세는 테스트 질문에 대해 여러 추론 경로에 투표하는 것입니다. Wang et al. (2022a)은 LLMs의 여러 출력을 샘플링하고 최종 답변에 대한 다수결을 취하는 자체 일관성(self-consistency) 디코딩 전략을 도입했습니다. Wang et al. (2022b)과 Li et al. (2022b)은 입력 공간에 무작위성을 도입하여 투표를 위한 더 다양한 출력을 생성했습니다.
2.2. CoT 추론 유도를 위한 모델 파인튜닝
최근에는 언어 모델을 파인튜닝하여 추론을 유도하는 데 관심이 쏠리고 있습니다. Lu et al. (2022a)은 주석이 달린 대규모 데이터셋에서 인코더-디코더 모델을 파인튜닝했습니다. 그러나 CoT를 사용하여 답을 추론할 때, 즉 답변 전에 추론 체인을 생성할 때 현저한 성능 저하가 관찰되었습니다. 대신 CoT는 답변 후 설명으로만 사용됩니다. Magister et al. (2022)과 Ho et al. (2022)은 더 큰 교사 모델이 생성한 사고의 흐름(chain-of-thought) 출력을 기반으로 학생 모델을 파인튜닝하는 지식 증류(knowledge distillation)를 사용했습니다. 제안된 방법들은 산술, 상식, 그리고 상징적 추론 과제에서 성능 향상을 보였습니다.
1B-모델을 CoT 추론자로 훈련하는 데에는 핵심적인 도전이 있습니다. Wei et al. (2022b)에 따르면, 1000억 개 미만의 파라미터를 가진 모델들은 잘못된 답으로 이어지는 비논리적인 CoT를 생성하는 경향이 있습니다. 즉, 1B-모델이 직접 답을 생성하는 것보다 효과적인 CoT를 생성하는 것이 더 어려울 수 있습니다. 질문에 답하는 것이 다중 모달 입력을 이해하는 것을 요구하는 다중 모달 설정에서는 이 도전이 더욱 어려워집니다. 다음 부분에서는 Multimodal-CoT의 도전을 탐구하고 효과적인 다단계 추론을 수행하는 방법을 조사할 것입니다.
3. Multimodal-CoT의 도전
기존 연구들은 언어 모델이 특정 규모, 예를 들어 1000억 개 이상의 파라미터에서 추론 능력이 나타날 수 있다고 제안했습니다 (Wei et al., 2022a). 그러나 1B-모델에서 이러한 추론 능력을 유도하는 것은 여전히 해결되지 않은 도전 과제이며, 다중 모달 시나리오에서는 더욱 그렇습니다. 이 작업은 소비자 등급 GPU(예: 메모리)로 파인튜닝하고 배포할 수 있는 1B-모델에 초점을 맞추고 있습니다. 이 섹션에서는 1B-모델이 추론에 실패하는 이유를 조사하고 도전을 극복하기 위한 효과적인 접근 방법을 설계하는 방법을 연구할 것입니다.
3.1. CoT의 역할에 대하여
우선, 우리는 ScienceQA 벤치마크(Lu et al., 2022a)에서 CoT 추론을 위한 텍스트 전용 기준선을 미세 조정합니다. Lu et al. (2022a)을 따라, 우리는 UnifiedQA Base (Khashabi et al., 2020)를 백본 언어 모델로 채택합니다. 우리의 작업은 텍스트 생성 문제로 모델링되며, 모델은 텍스트 정보를 입력으로 받아 근거와 답을 포함하는 출력 시퀀스를 생성합니다. 그림 1에 보여진 예시처럼, 모델은 질문 텍스트 , 문맥 텍스트(C), 그리고 다수의 선택지(M)의 토큰들을 연결한 것을 입력으로 받습니다. CoT의 효과를 연구하기 위해, 우리는 세 가지 변형과 성능을 비교합니다: (i) No-CoT는 직접적으로 답을 예측합니다 ; (ii) 추론은 답의 추론이 근거에 의존합니다 ; (iii) 설명은 근거를 사용하여 답의 추론을 설명합니다 .
표 2. 단일 단계 설정에서 CoT의 효과.

놀랍게도, 모델이 답변 전에 근거를 예측하는 경우 정확도가 감소한다는 것을 관찰합니다 . 이 결과는 근거가 반드시 올바른 답을 예측하는 데 기여하지 않을 수도 있다는 것을 시사합니다. 유사한 현상이 et al. (2022a)에서 관찰되었는데, 그 가능한 이유는 모델이 필요한 답을 얻기 전에 최대 토큰 한도를 초과하거나 예측 생성을 일찍 중단할 수 있기 때문일 수 있습니다. 그러나 우리는 생성된 출력(RA)의 최대 길이가 항상 400 토큰 미만이며, 이는 언어 모델의 길이 한도(즉, UnifiedQA Base의 512)보다 낮다는 것을 발견했습니다. 따라서 근거가 답의 추론에 해를 끼치는 이유에 대해 더 깊이 조사할 필요가 있습니다.[^3]

질문: 이 자석들은 서로 끌리거나 밀어낼까요?
맥락: 두 개의 자석이 아래와 같이 배치되어 있습니다. 힌트: 서로 끌리는 자석은 가까워지고, 서로 밀치는 자석은 멀어집니다. S
정답 근거: 자석은 서로 닿지 않고도 서로를 끌거나 밀 수 있습니다. 자석이 끌릴 때, 그들은 서로 가까워집니다. 자석이 밀칠 때, 그들은 서로 멀어집니다. 자석이 다른 자석을 끌리거나 밀치는 것은 그 자석의 극, 즉 끝 부분의 위치에 달려 있습니다. 모든 자석에는 북극과 남극이라고 불리는 두 개의 극이 있습니다. 여기 몇 가지 자석의 예가 있습니다. 각 자석의 북극은 으로 표시되고, 남극은 로 표시됩니다. 서로 다른 극이 가장 가까이 있으면 자석은 끌립니다. 아래 쌍의 자석들은 끌립니다. 같은 극이 가장 가까이 있으면 자석은 밀칩니다. 아래 두 쌍의 자석들은 밀칩니다. 이 자석들은 끌릴까요, 밀칠까요? 알아보려면 어느 극이 서로 가장 가까운지 살펴보세요. 한 자석의 북극이 다른 자석의 남극과 가장 가까이 있습니다. 서로 다른 극은 끌립니다. 그러므로, 이 자석들은 서로 끌릴 것입니다. 답: 정답은 입니다.
기본선
생성된 근거: 자석은 서로 닿지 않고도 서로를 끌거나 밀 수 있습니다. 자석이 끌릴 때, 그들은 서로 가까워집니다. 자석이 밀칠 때, 그들은 서로 멀어집니다. 자석이 다른 자석을 끌리거나 밀치는 것은 그 자석의 극, 즉 끝 부분의 위치에 달려 있습니다. 모든 자석에는 북극과 남극이라고 불리는 두 개의 극이 있습니다. 여기 몇 가지 자석의 예가 있습니다. 각 자석의 북극은 으로 표시되고, 남극은 로 표시됩니다. 서로 다른 극이 가장 가까이 있으면 자석은 끌립니다. 아래 쌍의 자석들은 끌립니다. 같은 극이 가장 가까이 있으면 자석은 밀칩니다. 아래 두 쌍의 자석들은 밀칩니다. 이 자석들은 끌릴까요, 밀칠까요? 알아보려면 어느 극이 서로 가장 가까운지 살펴보세요. 한 자석의 남극이 다른 자석의 남극과 가장 가까이 있습니다. 같은 극은 서로 밀칩니다. 그러므로, 이 자석들은 서로 밀칠 것입니다. 답: 정답은 (B)입니다.
시각 특징(Vision Features)
생성된 근거: 자석은 서로 닿지 않고도 서로를 끌어당기거나 밀어낼 수 있습니다. 자석이 서로를 끌어당길 때, 그들은 서로 가까워집니다. 자석이 서로를 밀어낼 때, 그들은 서로 멀어집니다. 자석이 다른 자석을 끌어당기거나 밀어내는 것은 그 자석의 극, 즉 끝 부분의 위치에 달려 있습니다. 모든 자석에는 북극과 남극이라고 불리는 두 개의 극이 있습니다. 여기 몇 가지 자석의 예가 있습니다. 각 자석의 북극은 으로 표시되고, 남극은 로 표시됩니다. 서로 다른 극이 가장 가까이 있으면, 자석은 서로를 끌어당깁니다. 아래의 한 쌍의 자석은 서로를 끌어당깁니다. 같은 극이 가장 가까이 있으면, 자석은 서로를 밀어냅니다. 아래의 두 쌍의 자석은 서로를 밀어냅니다. 이 자석들은 서로를 끌어당길까요, 밀어낼까요? 알아보려면, 어느 극이 서로에게 가장 가까운지 살펴보세요. 한 자석의 북극은 다른 자석의 남극에 가장 가깝습니다. 서로 다른 극은 서로를 끌어당깁니다. 그러므로, 이 자석들은 서로를 끌어당길 것입니다. 답: 답은 입니다.
그림 2. 근거 생성과 답변 예측을 위한 시각 기능이 없는 두 단계 프레임워크(기준선)와 시각 기능이 있는 프레임워크(우리의 방법)의 예. 상단은 금색 근거와 함께 문제의 세부 사항을 제시하고, 하단은 기준선과 시각 기능이 통합된 우리의 방법의 출력을 보여줍니다. 우리는 기준선이 환상적인 근거에 의해 오도되어 올바른 답을 예측하지 못하는 것을 관찰합니다. 더 많은 예시는 부록 A.1에 나와 있습니다.
3.2. 환상적인 근거에 의한 오도
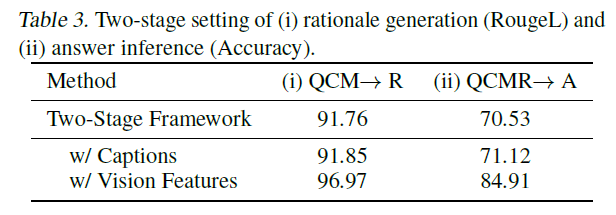
근거가 답변 예측에 미치는 영향을 파악하기 위해, 우리는 CoT 문제를 근거 생성과 답변 추론의 두 단계로 분리합니다. 우리는 근거 생성과 답변 추론에 대한 RougeL 점수와 정확도를 각각 보고합니다. 표 3은 두 단계 프레임워크를 기반으로 한 결과를 보여줍니다. 두 단계 기준선 모델은 근거 생성의 RougeL 점수에서 91.76점을 달성했지만, 답변 추론의 정확도는 70.53%에 불과합니다. 표 2의 변형(80.40%)과 비교했을 때, 두 단계 프레임워크에서 생성된 근거가 답변의 정확도를 향상시키지 않는다는 것을 보여줍니다.
표 3. (i) 근거 생성(RougeL)과 (ii) 답변 추론(정확도)의 두 단계 설정.
그런 다음, 우리는 50개의 오류 사례를 무작위로 샘플링하여 모델이 답변 추론을 오도하는 환각적인 근거(hallucinated rationales)를 생성하는 경향이 있다는 것을 발견했습니다. 그림 2에 나와 있는 예시에서, 모델(왼쪽 부분)은 시각적 내용에 대한 참조가 부족하여 "한 자석의 남극이 다른 자석의 남극에 가장 가깝다"라고 환각합니다. 이러한 실수가 오류 사례 중 의 비율로 발생한다는 것을 발견했습니다.

(a) 환각 실수 비율
(b) 시각적 특징을 포함한 수정 비율 vision features
그림 3. 환각 실수 비율(a)과 시각적 특징을 포함한 수정 비율(b) (그림 3(a)).
3.3. 다중모달성은 효과적인 근거 제공에 기여한다
우리는 이러한 환각 현상이 효과적인 다중모달 연쇄추론(Multimodal-CoT)을 수행하기 위한 필요한 시각적 맥락의 부족 때문이라고 추측합니다. 시각 정보를 주입하는 간단한 방법은 짝지어진 이미지를 캡션으로 변환(Lu et al., 2022a)한 다음, 두 단계의 입력에 캡션을 추가하는 것입니다. 그러나 표 3에 나와 있는 것처럼, 캡션만을 사용하는 것은 소폭의 성능 향상만을 가져옵니다 . 그런 다음, 우리는 언어 모델에 시각적 특징을 통합하는 고급 기술을 탐구합니다. 구체적으로, 우리는 짝지어진 이미지를 DETR 모델(Carion et al., 2020)에 입력하여 시각적 특징을 추출합니다. 그런 다음 우리는 시각적 특징을 융합합니다.
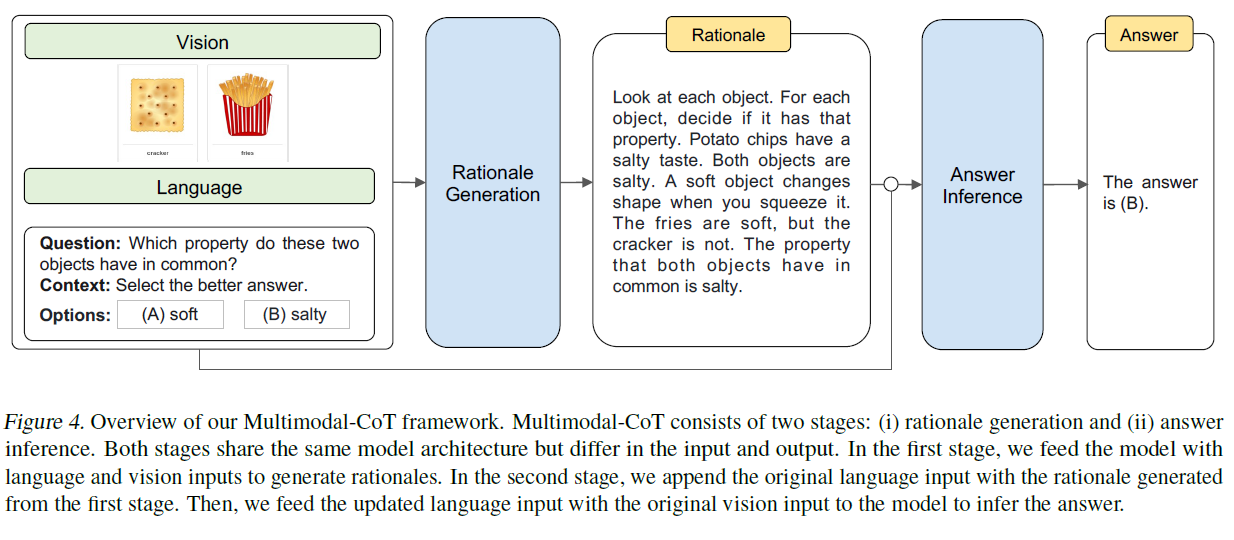
그림 4. 우리의 다중모달 연쇄추론(Multimodal-CoT) 프레임워크 개요. 다중모달 연쇄추론은 두 단계로 구성됩니다: (i) 근거 생성과 (ii) 답변 추론. 두 단계는 같은 모델 구조를 공유하지만 입력과 출력에서 차이가 있습니다. 첫 번째 단계에서는 언어와 시각 입력을 모델에 입력하여 근거를 생성합니다. 두 번째 단계에서는 첫 번째 단계에서 생성된 근거를 원래의 언어 입력에 추가합니다. 그런 다음, 업데이트된 언어 입력과 원래의 시각 입력을 모델에 입력하여 답변을 추론합니다.
인코딩된 언어 표현을 디코더(decoder)에 입력하기 전에 함께 사용하는 방법에 대한 자세한 내용은 4장에서 소개할 예정입니다. 흥미롭게도, 비전 기능(vision features)을 사용함으로써, 근거 생성(rationale generation)의 RougeL 점수가 로 향상되었으며, 이는 답변 정확도(answer accuracy)를 로 개선하는 데 기여했습니다. 이러한 효과적인 근거들로 인해 환각 현상(hallucination)이 완화되었으며, 3.2절에서 언급된 의 환각 오류가 수정되었습니다(그림 3(b) 참조), 예를 들어 그림 2(오른쪽 부분)에 나타난 바와 같습니다. 지금까지의 분석은 비전 기능이 실제로 효과적인 근거 생성과 정확한 답변 추론에 도움이 된다는 것을 설득력 있게 보여줍니다. 표 3의 이단계 방법(이 표 2의 모든 일단계 방법보다 더 나은 성능을 달성했기 때문에, 우리는 Multimodal-CoT 프레임워크에서 이단계 방법을 선택합니다.
4. Multimodal-CoT
3장에서의 관찰과 토론을 바탕으로, 우리는 언어(텍스트)와 비전(이미지) 모달리티를 이단계 프레임워크에 통합하는 Multimodal-CoT를 제안합니다. 이 장에서는 프레임워크의 절차를 개관한 다음 모델 아키텍처의 기술적 설계에 대해 자세히 설명할 것입니다.
4.1. 프레임워크 개관
Multimodal-CoT는 두 가지 훈련 단계로 구성됩니다: (i) 근거 생성(rationale generation)과 (ii) 답변 추론(answer inference). 두 단계는 동일한 모델 아키텍처를 공유하지만 입력 와 출력 에서 차이가 있습니다. 전체 절차는 그림 4에 나와 있습니다. 우리는 비전-언어(vision-language)를 예로 들어 Multimodal-CoT가 어떻게 작동하는지 보여줄 것입니다.[^4]
근거 생성 단계에서, 우리는 모델에 을 입력합니다. 여기서 은 첫 번째 단계의 언어 입력을 나타내고, 은 비전 입력, 즉 이미지를 나타냅니다. 예를 들어, 는 다중 선택 추론 문제의 질문, 맥락, 옵션을 연결한 것으로 구체화될 수 있습니다(Lu et al., 2022a) 그림 4에 나와 있습니다. 목표는 근거 생성 모델 을 학습하는 것이며, 여기서 은 근거입니다.
답변 추론 단계에서, 근거 은 원래의 언어 입력 에 추가되어 두 번째 단계의 언어 입력 을 구성합니다. 여기서 는 연결(concatenation)을 나타냅니다. 그런 다음 업데이트된 입력 을 답변 추론 모델에 입력하여 최종 답변 을 추론합니다.
두 단계 모두에서, 우리는 동일한 구조의 두 모델을 독립적으로 훈련합니다. 이들은 훈련 세트에서 주석이 달린 요소들(예: )을 각각 지도 학습(supervised learning)을 위해 사용합니다. 추론 중에, 주어진 에 대해, 테스트 세트의 근거들은 첫 번째 단계에서 훈련된 모델을 사용하여 생성되며, 이들은 두 번째 단계에서 답변 추론을 위해 사용됩니다.
4.2. 모델 구조
언어 입력 과 시각 입력 이 주어지면, 우리는 길이 의 대상 텍스트 (그림 4에서 근거나 답변)를 생성할 확률을 다음과 같이 계산합니다:
여기서 는 트랜스포머 기반 네트워크(Transformer-based network) (Vaswani et al., 2017)로 구현됩니다. 이 네트워크는 세 가지 주요 절차를 가지고 있습니다: 인코딩(encoding), 상호 작용(interaction),

그리고 디코딩(decoding). 구체적으로, 우리는 언어 텍스트를 트랜스포머 인코더(Transformer encoder)에 입력하여 텍스트 표현을 얻은 다음, 이를 시각 표현과 상호 작용하고 융합한 후 트랜스포머 디코더(Transformer decoder)에 입력합니다.
인코딩 모델 은 언어와 시각 입력을 모두 받아들여 다음 함수를 통해 텍스트 표현 와 이미지 특징 을 얻습니다:
여기서 LanguageEncoder( )는 트랜스포머(Transformer) 모델로 구현됩니다. 우리는 트랜스포머 인코더의 마지막 레이어의 은닉 상태를 언어 표현 로 사용하는데, 여기서 은 언어 입력의 길이를 나타내고, 는 은닉 차원을 의미합니다. 한편, VisionExtractor()는 입력 이미지를 시각적 특징으로 벡터화하는 데 사용됩니다. 비전 트랜스포머(Vision Transformers)의 최근 성공에 영감을 받아, 우리는 기성품 시각 추출 모델들, 예를 들어 DETR (Carion et al., 2020)을 사용하여 패치 수준의 특징을 가져옵니다. 패치 수준의 시각적 특징을 얻은 후, 학습 가능한 투영 행렬 를 적용하여 VisionExtractor 의 형태를 의 형태로 변환합니다; 따라서 우리는 를 가지게 되는데, 여기서 은 패치의 수입니다.
상호작용 언어와 시각 표현을 얻은 후, 우리는 단일 헤드(single-head) 주의 네트워크를 사용하여 텍스트 토큰과 이미지 패치를 상관시킵니다. 여기서 쿼리 , 키 및 값 은 각각 및 입니다.[^5]
주의 출력 는 다음과 같이 정의됩니다:
여기서 는 단일 헤드가 사용되기 때문에 의 차원과 동일합니다.
그런 다음, 우리는 게이트 융합 메커니즘(gated fusion mechanism) (Zhang et al., 2020; Wu et al., 2021; et al., 2022a)을 적용하여 와 을 융합합니다. 융합된 출력 는 다음과 같이 얻어집니다:
여기서 과 는 학습 가능한 매개변수입니다.
디코딩 마지막으로, 융합된 출력 는 Transformer 디코더에 입력되어 대상 를 예측합니다. Multimodal-CoT의 전체 절차는 알고리즘 1에 나와 있습니다.
5. 실험
이 섹션에서는 벤치마크 데이터셋, 우리 기술의 구현, 그리고 비교를 위한 기준선들을 제시할 것입니다. 그 다음, 우리의 주요 결과와 발견을 보고할 것입니다.
5.1. 데이터셋
우리의 방법은 ScienceQA 벤치마크(Lu et al., 2022a)에서 평가됩니다. ScienceQA는 상세한 강의와 설명으로 답변을 주석 처리한 최초의 대규모 다중모달 과학 질문 데이터셋입니다. 이 데이터셋은 3개 과목, 26개 주제, 127개 카테고리, 그리고 379개 기술에 걸쳐 풍부한 도메인 다양성을 가진 개의 다중모달 객관식 질문을 포함하고 있습니다. 벤치마크 데이터셋은 각각 12726, 4241, 4241 예제로 훈련, 검증, 테스트 분할로 나뉩니다.
5.2. 구현
다음 부분에서는 Multimodal-CoT와 기준선 방법들의 실험 설정을 제시합니다.
실험 설정
Multimodal-CoT(다중모달-사고 과정) 작업은 추론 체인을 생성하고 시각적 특징을 활용해야 하므로, 우리는 인코더-디코더 구조(Raffel et al., 2020)를 사용합니다. 구체적으로, 우리는 두 단계에서 모델을 초기화하기 위해 UnifiedQA(Khashabi et al., 2020)를 채택했는데, 이는 Lu et al. (2022a)에서 가장 좋은 미세조정 결과를 달성했기 때문입니다. 다른 언어 모델(LMs)에서 접근법의 일반성을 검증하기 위해, 우리는 또한 6.3절에서 FLAN-T5(Chung et al., 2022)를 백본으로 사용합니다. 3.3절에서 이미지 캡션을 사용해도 성능 향상이 크지 않기 때문에, 우리는 캡션을 사용하지 않았습니다. 우리는 모델을 최대 20 에포크까지 미세조정하며, 학습률은 입니다.
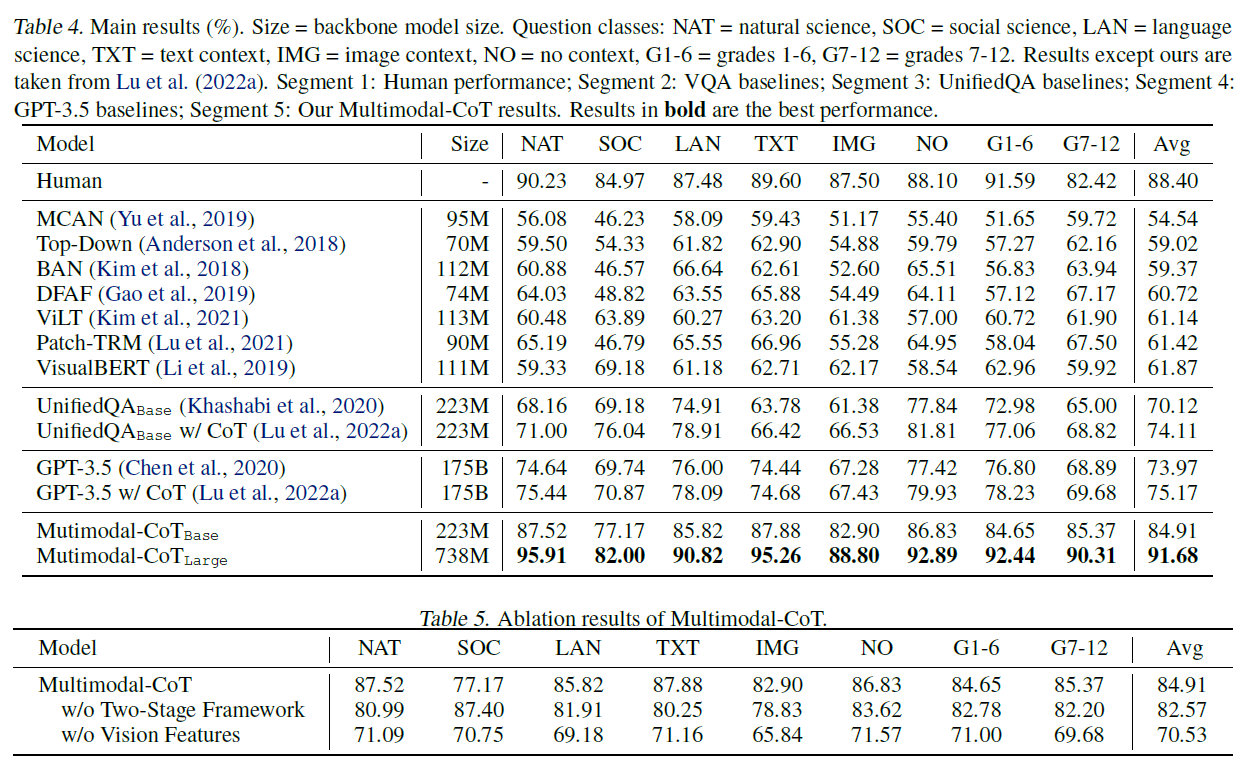
표 4. 주요 결과 . 크기 백본 모델 크기. 질문 분류: NAT 자연 과학, 사회 과학, 언어 과학, 텍스트 맥락, 이미지 맥락, 맥락 없음, G1-6 = 1-6학년, G7-12 = 7-12학년. 우리의 결과를 제외한 결과는 Lu et al. (2022a)에서 가져왔습니다. 세그먼트 1: 인간의 성능; 세그먼트 2: VQA 기본선; 세그먼트 3: UnifiedQA 기본선; 세그먼트 4: GPT-3.5 기본선; 세그먼트 5: 우리의 Multimodal-CoT 결과. 굵은 글씨로 표시된 결과는 최고의 성능입니다.
표 5. 다중모달-CoT(Multimodal-CoT)의 분석
최대 입력 시퀀스 길이는 512입니다. 베이스(base) 모델과 라지(large) 모델의 배치 크기는 각각 16과 8입니다. 우리의 실험은 4개의 NVIDIA Tesla V100 32G GPU에서 실행됩니다.
기준 모델들 기준 모델로는 Lu et al. (2022a)을 따라 (i) 시각적 질문 응답(Visual question answering, VQA) 모델들 (Anderson et al., 2018; Kim et al., 2018; Yu et al., 2019; Gao et al., 2019; Kim et al., 2021; Lu et al., 2021; Li et al., 2019); (ii) 텍스트-투-텍스트(Text-to-text) 언어 모델(Language Model, LM)들. (Khashabi et al., 2020); (iii) GPT-3.5 모델들 (Chen et al., 2020)이 포함됩니다. 더 자세한 내용은 부록 B.1에 제시되어 있습니다.
5.3. 주요 결과
표 4는 주요 결과를 보여줍니다. 다중모달-CoT(Mutimodal-CoT) 는 GPT-3.5를 로 능가하며 인간의 성능을 초과합니다. 특히, 8개의 질문 유형 중에서 다중모달-CoT 는 짝지어진 이미지(IMG)가 있는 질문에 대해 의 성능 향상을 달성합니다. 기존의 UnifiedQA와 GPT-3.5 방법들이 시각적 의미를 제공하기 위해 컨텍스트 내 이미지 캡션을 활용하는 것과 비교했을 때, 이미지 특징을 사용하는 것이 더 효과적임을 결과가 시사합니다. 또한, 우리의 2단계 프레임워크는 표 5의 절단 연구(ablation study) 결과에 따라 우수한 결과에 기여합니다. 전반적으로, 결과는 다중모달성의 효과와 우리의 2단계 프레임워크를 통해 1B-모델로 CoT 추론을 달성할 수 있는 잠재력을 검증합니다.
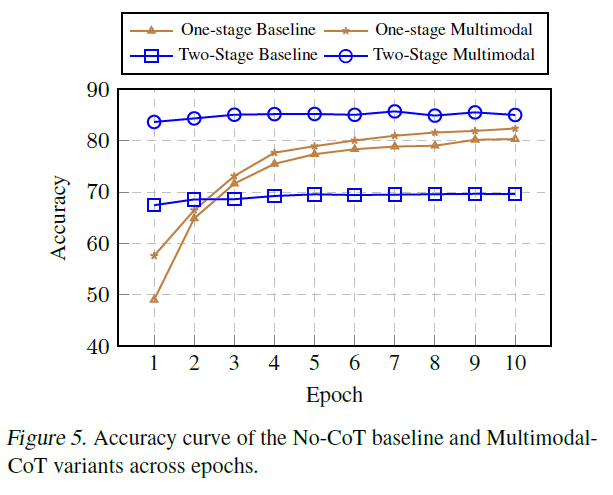
그림 5. No-CoT 기준선과 다중모달CoT 변형 모델들의 에폭에 따른 정확도 곡선.
6. 분석
다음 분석에서는 다중모달CoT가 어떻게 작동하는지 조사하고 기여 요인과 한계에 대해 논의할 것입니다. 특별히 명시하지 않는 한, 분석을 위해 베이스 크기의 모델을 사용합니다.
6.1. 다중모달성은 수렴을 촉진합니다
그림 5는 기준 모델(baseline)과 다중 모달 사고 과정(Multimodal-CoT)의 평가 정확도 곡선을 다른 훈련 에포크(training epochs)에서 보여줍니다. "단일 단계(Onestage)"는 표 2에서 가장 좋은 성능을 달성한 QCM A 입력-출력 형식을 기반으로 하며, "이단계(Two-stage)"는 우리의 이단계 프레임워크입니다. 우리는 이단계 방법이 사고 과정(CoT) 없이 직접 답을 생성하는 단일 단계 기준 모델보다 처음에 상대적으로 더 높은 정확도를 달성한다는 것을 발견했습니다. 그러나 시각적 특징(vision features) 없이는 3절에서 관찰된 것처럼 낮은 품질의 근거(rationales) 때문에 훈련이 진행됨에 따라 이단계 기준 모델이 더 나은 결과를 내지 못합니다. 반면, 시각적 특징을 사용하면 더 효과적인 근거를 생성하는 데 도움이 되어 우리의 이단계 다중 모달 변형에서 더 나은 답변 정확도에 기여합니다.
6.2. 다양한 시각적 특징 사용하기
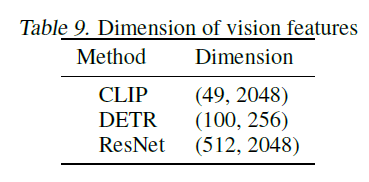
다양한 시각적 특징은 모델 성능에 영향을 줄 수 있습니다. 우리는 널리 사용되는 세 가지 유형의 시각적 특징, CLIP (Radford et al., 2021), DETR (Carion et al., 2020), 그리고 ResNet (He et al., 2016)을 비교합니다. CLIP과 DETR은 패치와 같은 특징(patch-like features)이며, DETR은 객체 감지(object detection)를 기반으로 합니다. ResNet 특징의 경우, 텍스트 시퀀스와 같은 길이로 ResNet50의 풀링된 특징을 반복하여 패치와 같은 특징을 모방합니다. 여기서 각 패치는 풀링된 이미지 특징과 동일합니다. 시각적 특징에 대한 자세한 내용은 부록 B.2에 제시되어 있습니다.
표 6. 다양한 시각적 특징을 사용했을 때의 정확도(%).
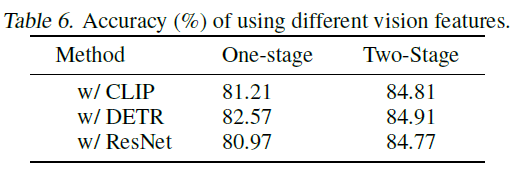
표 6은 시각적 특징의 비교 결과를 보여줍니다. 우리는 일반적으로 시각적 특징을 사용하는 것이 언어만을 기반으로 한 기준 모델보다 더 나은 성능을 달성한다는 것을 관찰합니다. 특히, DETR은 일반적으로 상대적으로 더 나은 성능을 달성합니다. 따라서 우리는 Multimodal-CoT에서 기본적으로 DETR을 사용합니다.
6.3. 백본 모델들에 대한 일반적인 효과성
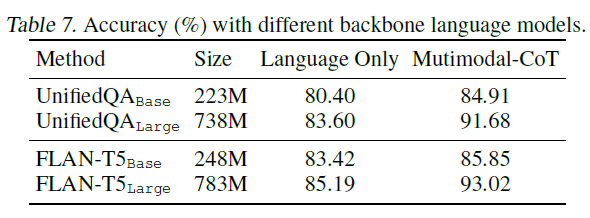
우리의 접근법이 다른 백본 모델들에 대한 이점의 일반성을 테스트하기 위해, 우리는 기본 언어 모델(LMs)을 다양한 크기나 유형의 다른 변형으로 변경합니다. 표 7에 나타난 바와 같이, 우리의 접근법은 널리 사용되는 백본 모델들에 대해 일반적으로 효과적입니다.
표 7. 다른 백본 언어 모델들을 사용했을 때의 정확도(%).
6.4. 오류 분석(Error Analysis)
다중모달-CoT(Multimodal-CoT)의 행동을 더 잘 이해하고 향후 연구를 촉진하기 위해, 우리는 접근 방식으로 생성된 무작위로 선택된 예시들을 수동으로 조사했습니다. 표 8은 다중모달-CoT(MultimodalCoT)에 의해 생성된 분류 결과를 요약합니다. 우리는 정답이 맞은 50개의 샘플과 틀린 50개의 샘플을 무작위로 선택했습니다. 각 카테고리에서 해당하는 예시들은 부록 C에 제시되어 있습니다.
표 8. 다중모달-CoT(Multimodal-CoT)의 분류 분석.

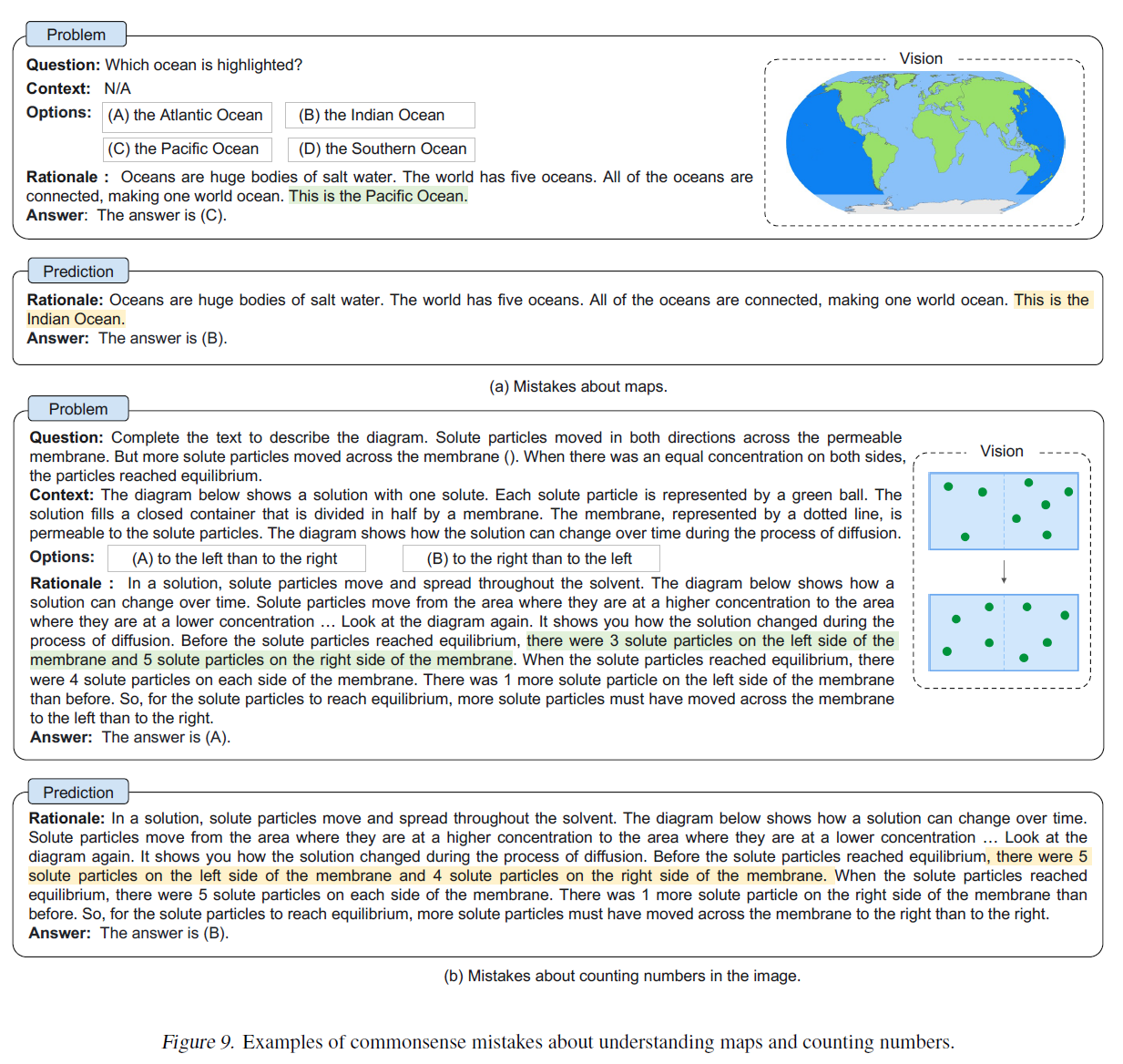
우리는 정답이 맞은 샘플들(즉, 답이 정확한 샘플들)이 잘못된 사고의 흐름(chain-of-thought)을 포함하고 있다는 것을 발견했습니다(10%). 결과는 CoT가 항상 답 추론에 도움이 되는 것은 아니며, 모델이 어느 정도 강인함을 가지고 있음을 나타냅니다 - 잘못된 근거를 무시하고 정답을 예측할 수 있습니다. 오답이 맞은 샘플들(즉, 답이 틀린 샘플들)의 경우, CoT에서 상식적인 실수가 가장 흔한 오류 유형입니다(88%). 모델은 종종 상식 지식이 필요한 질문에 답할 때 상식적인 실수를 합니다. 예를 들어, 이미지 속 지도를 이해하고 숫자를 세는 것(Figure 9), 알파벳을 활용하는 것(Figure 10) 등입니다. 다른 유형의 실수는 논리적인 실수(12%)로, 추론 과정에서 모순이 있습니다(Figure 11). 또한, CoT가 정확함에도 불구하고 답이 틀린 경우(6%)도 있지만, 반드시 답 옵션과 관련이 있지는 않을 수 있습니다(Figure 12).
분석에 따르면 미래 연구를 위한 유망한 방향이 있습니다. MultimodalCoT을 개선하기 위해서는 (i) 더 유익한 시각적 특징을 통합하고 지도를 이해하고 숫자를 세는 능력을 갖추기 위해 언어-시각 상호작용을 개선하는 것; (ii) 상식 지식을 주입하는 것; (iii) 필터링 메커니즘을 적용하는 것, 예를 들어 효과적인 CoT만을 사용하여 답을 추론하고 관련 없는 CoT를 제거하는 것이 가능합니다.
7. 결론
우리는 멀티모달 CoT의 문제를 공식적으로 연구합니다. 우리는 언어와 시각 모달리티를 통합하여 이성적 근거 생성과 답변 추론을 분리하는 두 단계 프레임워크인 Multimodal-CoT을 제안합니다. 이를 통해 답변 추론이 멀티모달 정보로부터 더 잘 생성된 근거를 활용할 수 있습니다. Multimodal-CoT을 사용함으로써, 우리의 방법이 ScienceQA 벤치마크에서 GPT-3.5를 16 퍼센트 포인트의 정확도로 능가한다는 것을 보여줍니다. 우리의 오류 분석은 더 효과적인 시각적 특징을 활용하고, 상식 지식을 주입하며, 필터링 메커니즘을 적용하여 미래 연구에서 CoT 추론을 개선할 잠재력이 있음을 보여줍니다.
A. Multimodal-CoT의 도전 과제에 대한 추가 분석
A.1. 환상적인 근거에 의한 오도의 더 많은 예시들
우리의 사례 연구(섹션 3.2)에 따르면, 기준선은 환상적인 근거를 생성하는 경향이 있다는 것을 발견했습니다. 그림 6에서 보여주는 것처럼 추가적인 예시들을 제공합니다.[^6]

그림 6. 근거를 생성하고 답변을 예측하기 위한 시각 특징이 없는 두 단계 프레임워크(기준)와 시각 특징이 있는 프레임워크(우리의 방법)의 예시입니다. 상단은 문제의 세부 사항을 제시하고, 하단은 기준 방법과 우리 방법의 출력을 보여줍니다.
A.2. 다양한 크기의 언어 모델(LMs)을 사용한 두 단계 훈련 성능
3장에서 우리는 시각 특징을 통합하는 것이 더 효과적인 근거를 생성하고, 따라서 답변 정확도를 향상시킨다는 것을 관찰했습니다. 시각 특징을 통합하는 것 외에도, 잘못된 근거의 문제를 완화하기 위해 언어 모델(LM)의 크기를 확장할 수 있습니다. 그림 7은 UnifiedQA 와 UnifiedQA 를 사용했을 때의 답변 정확도를 보여줍니다. 더 큰 을 사용할 때, 시각 특징이 없는 기준(baseline)의 정확도가 향상됩니다. 이 결과는 언어 모델의 크기를 확장하는 것이 잘못된 근거의 문제를 완화할 수 있음을 나타냅니다. 그러나 성능은 여전히 시각 특징을 사용하는 것에 비해 훨씬 열등합니다. 이 결과는 다양한 크기의 언어 모델을 사용한 우리의 Multimodal-CoT의 효과를 더욱 검증합니다.
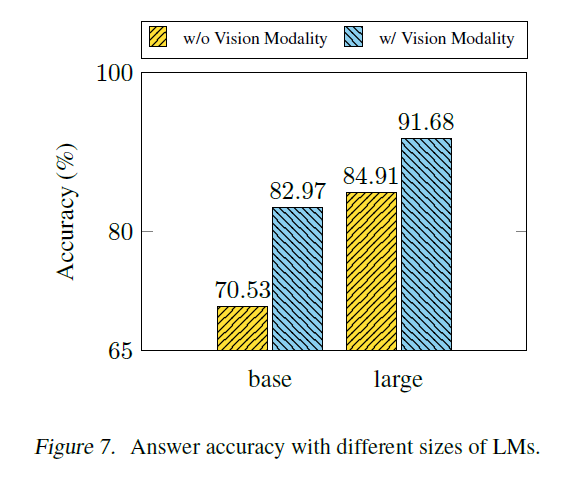
그림 7. 다양한 크기의 언어 모델(LMs)을 사용한 답변 정확도.
B. 실험 세부 사항
B.1. 기준 방법
Lu et al. (2022a)을 따라, 우리의 기준 방법들은 세 가지 유형을 포함합니다:
(i) 시각적 질문 응답(Visual question answering, VQA) 모델들 (Yu et al., 2019; Anderson et al., 2018; Kim et al., 2018; Gao et al., 2019; Lu et al., 2021; Li et al., 2019). VQA 기준 방법들은 질문, 맥락, 선택지를 텍스트 입력으로 받고, 이미지를 시각 입력으로 받아 선형 분류기를 통해 선택지 후보들에 대한 점수 분포를 예측합니다.
(ii) 텍스트-투-텍스트 언어 모델(Text-to-text LM) 모델들. UnifiedQA (Khashabi et al., 2020)는 Lu et al. (2022a)에서 가장 좋은 파인튜닝 모델로 채택되었습니다. UnifiedQA는 텍스트 정보를 입력으로 받고 답변 옵션을 출력합니다. 이미지는 ViT와 GPT-2를 기반으로 한 이미지 캡셔닝 모델에 의해 추출된 캡션으로 변환됩니다. UnifiedQA는 우리의 과제를 텍스트 생성 문제로 취급합니다. Lu et al. (2022a)에서는 후보 옵션 중 하나인 목표 답변 텍스트를 생성하도록 훈련되었습니다. 그런 다음 가장 유사한 옵션이 최종 예측으로 선택되어 질문 응답 정확도를 평가합니다.
(iii) 텍스트-davinci-002 엔진을 기반으로 한 GPT-3.5 모델들 (Chen et al., 2020). 추론은 트레이닝 세트에서 두 개의 인-컨텍스트 예시를 테스트 인스턴스 앞에 연결하는 퓨샷 프롬프팅(few-shot prompting)을 기반으로 합니다.
UnifiedQA와 GPT-3.5에 대해서는 답변 후에 CoT(Chain of Thought)가 적용됩니다 (Lu et al., 2022a). 위의 기준 방법들 외에도, 우리는 UnifiedQA의 출력 형식을 약간 수정하여 더 강력한 기준 방법을 개발했습니다. 답변 텍스트를 예측하는 대신, 우리의 기준 방법은 직접 선택지를 예측합니다. 예를 들어, 답변은 입니다. 이 설정은 기존의 UnifiedQA보다 우리의 기준 방법이 더 좋은 결과를 달성하는 데 도움이 됩니다. 따라서, 우리는 언어만을 사용하는 기준 방법으로 더 강력한 방법을 분석을 위해 사용합니다.
B.2. 시각 특징의 세부 사항
6.2절에서는 네 가지 유형의 비전 특징, CLIP(Radford et al., 2021), DETR(Carion et al., 2020), 그리고 ResNet(He et al., 2016)을 비교했습니다. 구체적인 모델은 다음과 같습니다: (i) CLIP: RN101; (ii) DETR: resnet101_dc (iii) ResNet: 사전 훈련된 ResNet50 CNN의 평균 풀링된 특징을 사용했습니다[^7]. 표 9는 방정식 3의 함수 VisionExtractor(.)를 거친 후의 비전 특징의 차원을 보여줍니다. ResNet-50의 경우, 텍스트 시퀀스와 같은 길이가 되도록 ResNet-50의 풀링된 특징을 반복하여 패치와 같은 특징을 모방했습니다. 여기서 각 패치는 풀링된 이미지 특징과 동일합니다.
C. 사례 연구의 예
Multimodal-CoT의 동작을 더 잘 이해하기 위해, 우리는 접근 방식으로 생성된 무작위로 선택된 예제들을 수동으로 조사했습니다. 표 8은 Multimodal-CoT에 의해 생성된 분류 결과를 요약합니다. 우리는 예측 결과가 정확한 50개의 샘플과 예측 결과가 부정확한 50개의 샘플을 무작위로 선택했습니다.
우리는 정확한 샘플들이 일정량의 부정확한 사고 과정(chain-of-thought)을 포함하고 있다는 것을 발견했습니다. 그림 8(b)에서 보여지듯이, 모델은 부정확한 근거 "동물은 다른 유기체를 소화함으로써 그들의 음식을 먹을 수 없다"를 생성하지만 예측된 답변은 정확합니다. 이 결과는 CoT가 항상 답변 추론에 도움이 되는 것은 아니며, 모델이 부정확한 근거를 무시하고 정확한 답변을 예측할 수 있는 어느 정도의 강인함을 가지고 있음을 나타냅니다.
부정확한 샘플의 경우, 상식적인 실수가 가장 흔한 오류 유형입니다. 모델은 또한 상식적인 지식이 필요한 질문에 답할 때 상식적인 실수를 합니다. 예를 들어, 이미지 속 지도를 이해하고 숫자를 세는 것(Figure 9), 알파벳을 활용하는 것(Figure 10) 등입니다. 다른 유형의 실수는 논리적인 실수로, 추론 체인에 모순이 있는 경우입니다(Figure 11). 또한, CoT가 정확하지만 반드시 답변 옵션과 관련이 없을 수 있으므로 모델이 부정확한 답변을 선택하는 경우도 있습니다.
이 분석은 미래 연구를 위한 전망 있는 방향을 가리킵니다. 한편으로는 (i) 언어와 비전 특징의 더 세밀한 상호작용을 사용하고; (ii) 상식 지식을 주입함으로써 CoT의 품질을 향상시킬 수 있습니다. 다른 한편으로는, 답변을 추론하는 데 효과적인 CoT만을 사용하고 관련 없는 CoT를 제거하는 필터링 메커니즘을 적용할 수 있습니다.