Multi-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training - 논문 정리
Paper Review
지속적으로 neural script knowledge, 그리고 Visual Question-Answer 관련 논문을 읽어서, 이번에는 정말 specific한 domain인 medical domain에서의 Vision-Language multimodal 논문을 읽어보았다.
뭔가, MERLOT RESERVE을 최근에 읽어서인지 모르겠지만, 음성이 포함된 데이터셋을 구축하고, 해당 데이터셋으로 학습하면 성능이 더 좋아질 것 같다! VLU 성능이 더 좋아지지 않을까?!
4 Questions
1. What did the autors try to accomplish?
- develop a model that can learn multipurpose joint representations of vision and text in medical domain
- build a model for vision-language understanding and generation-based downstream tasks, including diagnosis classification, medical image-report retrieval, medical visual question answering, and radiology report generation.
2. What were the key elements of the approach?
1. Masked Language Modeling
- follows BERT to replace 15% of the input of text tokens with special MASK token, a random token, or the original token with probability of 80%, 10%, 10%.
2. Image Report Matching
- encourages the model to learn both visual and textual features by training the model to predict whether a given pair of image and report is matching pair or not.
- non-matching : defined as ones that are extracted different positive diagnosis labels than the matching report.
3. Bidirectional Auto-Regressive(BAR)
- allows image features to be mixed with language features during pretraining, while preserving the casual-nature of auto-regressive language generation.
- enhances joint embeding between vision-language modalities and perform well in both generation and understanding tasks.
3. What can you use yourself?
- Semantic Embedding Vector to differentiate the modalities.
4. What other references do you want to follow?
- seq2seq attention.
0. Abstract
- explores a broad set of multimodal representation learning tasks in the medical domain, specifically using radiology images(방사선 사진) and the unstructured report.
- proposed model Medical Vision Language Learner (MedViLL) adopts a BERT-based architecture bombined with Bidirectional Auto-Regressive(BAR) to maximize generalization performance for both vision-language understanding tasks and vision-language generation task.
- statistically and rigorously evaluates proposed model on four downstream tasks with three radiographic image-report datasets(MIMIC-CSR, Open-I, and VQA-RAD).
1. Introduction
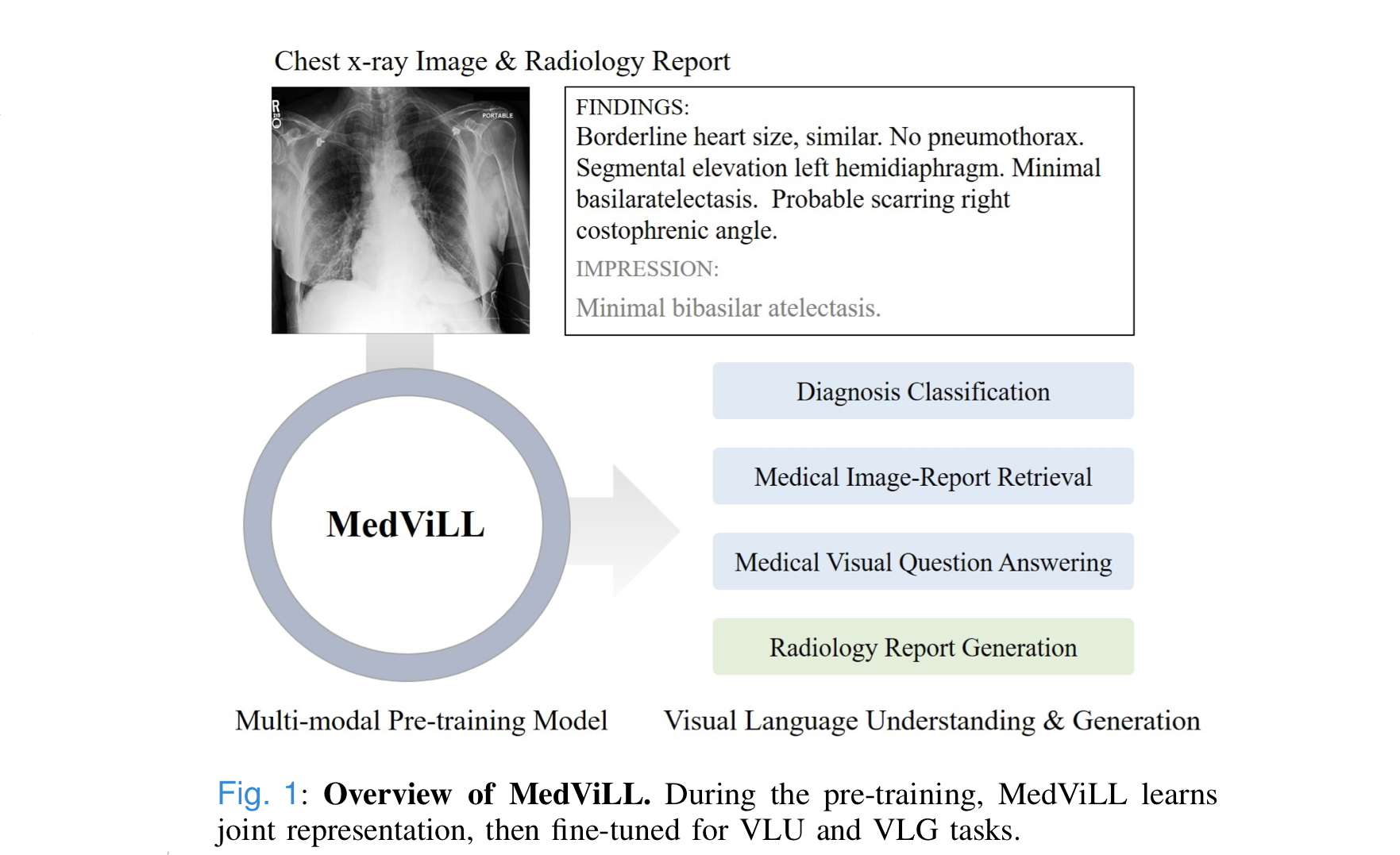
- Advances in VL(Vision-Language) multimodal research can be beneficial in improving the quality of clinical care by providing automated support for a variety of tasks such as diagnosis classification, report generation.
- Vision and Language information is frequently used in medical domain, often produced in the form of radiology images and corresponding free-text report. Therefore, VL muultimodal pretraining has great potential to be widely used in healthcare such impoving diagnosis accuracy, automatically generating reports, or answering questions from physicians.
- most previous studies focus on either the VLU tasks or VLG tasks, but this work focuses on both.
Main contributions of this paper can be summarized as follows:
- 1)
- Medical Vision Language Learner(MedViL) proposed
- multimodal pre-training model for medical images and reports with a novel self-attention scheme.
- 2)
- demonstrates the effectiveness of the proposed approach with detailed ablation study on extensive vision-language understanding and generation-based downstream tasks
- 3)
- demonstrates the generalization ability of the proposed approach under the transfer learning setting using two separate Chest X-ray datasets
- pretrains with one dataset, and performs diverse downstream tasks on another
2. Related Work
A. Radiology Practices
In radiology practices, physicians identify various clinical findings based on radiographic images and the patient's clinical history, then summarize these findings and overall impressions in a clinical report.
- diagnostic observations described as positive, negative, or uncertain about clinical findings, including the detailed location and severity(심각성) of the findings.
B. VL Multimodal Researches in the Medical Domain
- CNN-RNN based models still dominate in VL multi-modal learning in the medical domain, but are designed only for either VLU or VLG tasks.
- Li et al. compares 4 different BERT-based pre-training models on a VLU task.
- Liu et al. proposed a Transformer encoder-decoder based prior and posterior knowledge distilling approaches using 3 different modalities(Vision, Language, and Knowledge Graph)
- This paper focuses on learning a joint representation of a single image(frontal view) and its corresponding report to perform both VLU and VLG tasks with fine-tuning.
C. VL Multimodal Researches in the General Domain
Among numerous variants of VL pretraining setup, focuses on three most relevant componenets to the approach:
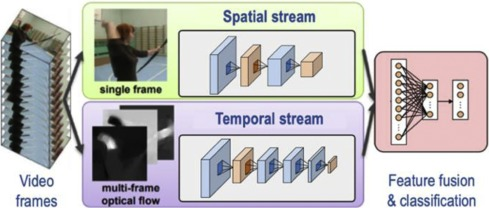
1) Input Embedding Stream:
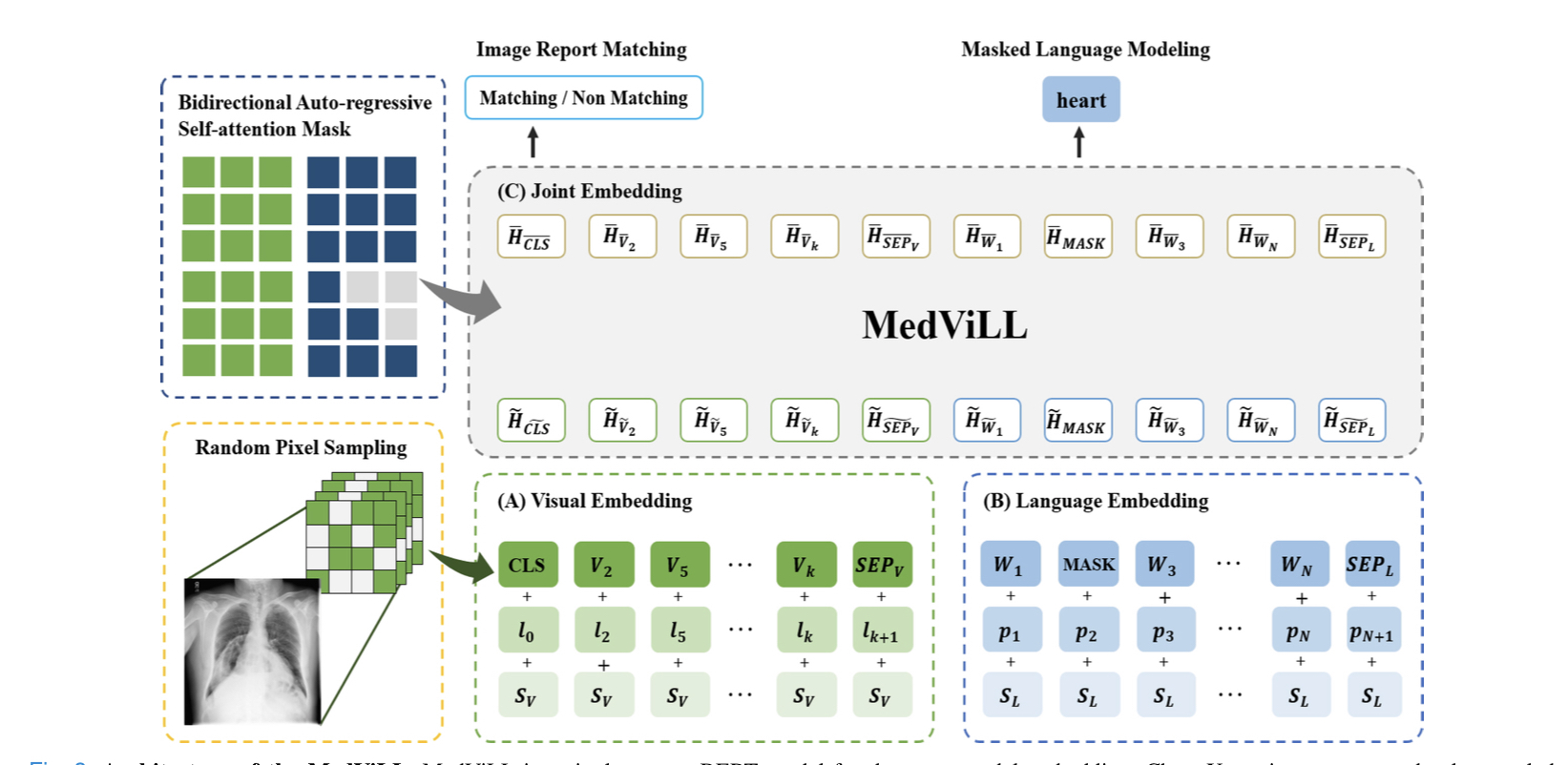
- for architectural simplicity and time/space efficiency, MedViL is single-stream architecture, instead of two-stream architecture. Beneath is the two-stream architecture.
2) Visual Feature Embedding:
- most of the recent works utilizes pre-trained object detectors to extract region-based visual inputs. This approach is limited by the given categories of the object detection task.
- PixelBERT suggest CNN-based visual encoder with random pixel sampling to improve the robustness of visual feature learning to avoid over-fitting.
- there is no applicable off-the-shelf object detector(현재 존재하는 적용가능한 object detector이 없음) to extract region-based feature in the medical domain, this work adapts CNN-based visual feature embedding.
3) Downstream Tasks:
- unified VLP, Unified vision-language pre-training for image captioning and vqa. conducts VLU and VLG both with a single BERT-based architecture by repeatedly alternating the mask type with a fixed ratio between bidirectional and sequence-to-sequence mask during pre-training.
- inspired by unified pre-training approach, this work explores dirrent types of masks and their effects on divers VLU and VLG downstream tasks.
3. Materials and Methods
A. Dataset
The dataset contains frontal and lateral view of images, so it is required to distinguish between view positions to avoid miss-match findings between an image and a report pair.
The dominance of the anteroposterior(AP) frontal view in ICU(중환자실) settings, we perform all experiments unique 91,685 AP view image and associated report pairs following the official split of datasets below.
1) MIMIC-CXR Dataset
- contains 377,110 chest X-ray images corresponding to free-text reports.
- uses train 89,395, valid 759, test 1,531.
- all models are pre-trained on MIMIC-CXR
2) Open-I Dataset
- contains 3,851 reports and 7,466 Chest X-ray images.
- uses 3,547 image-report pairs.
- used to test the generalization of the models
B. VL Pre-training Model
MedViLL is a single BERT-based model that learn unified contextualized vision-language representation.
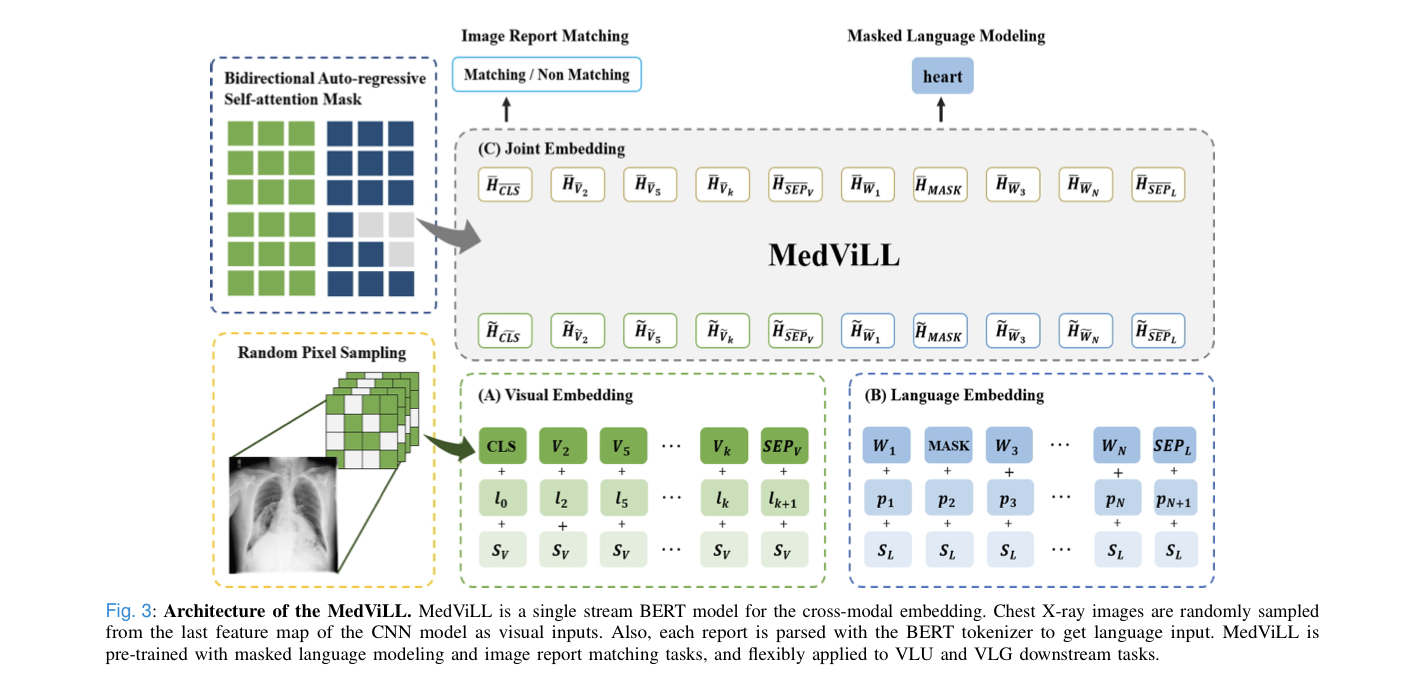

1) Visual Feature Embedding
- use CNN to extract visual features from medical image.
- visual features obtained from the last conv. layer, then flattend along the spatial dimension.
- encode the absolute positions of visual input as additional information(입력된 시각 정보의 절대적인 위치도 추가적인 정보로 encoding) for explicitly injecting the same body position information in the x-ray images.
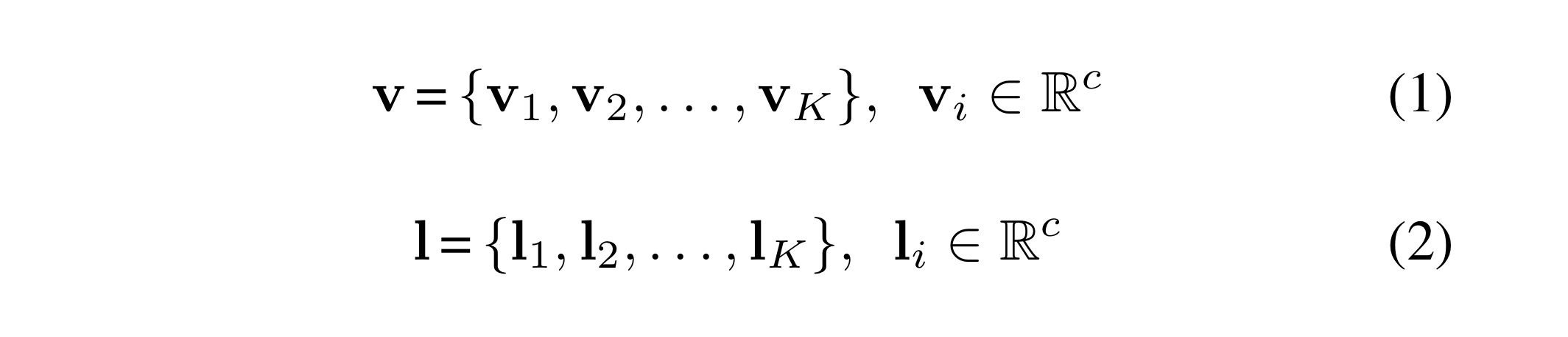
v = flattened visual feature obtained from the last CNN layer
l = location feature
k = the number of visual features(i.e., height x width)
c = the hidden dimension size(i.e., channel size)
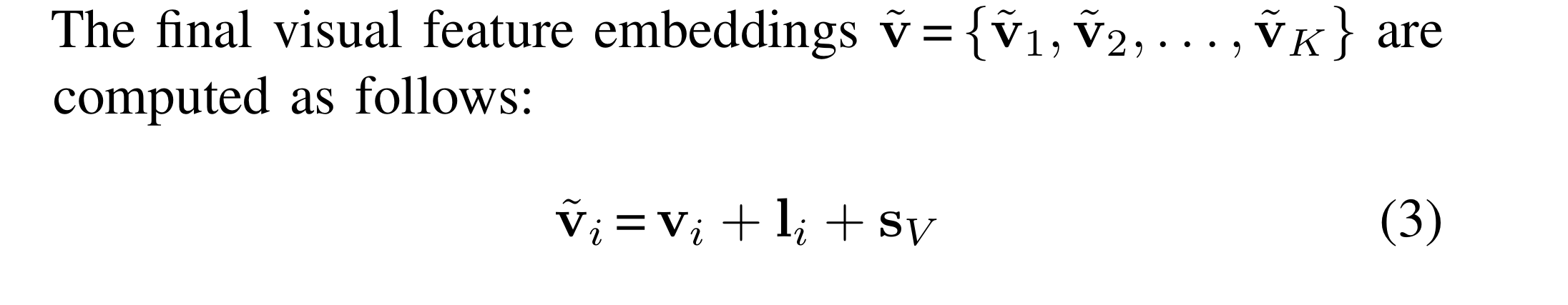
sv = semantic embedding vector shared by all visual feature to differentiate themselves from language embeddings.
The final visual features v ̃ are fed into a fully connected layer.
During pre-training:
- subset of the final visual features randomly sampled to avoid overfitting and enhance the semantic knowledge learning of visual input.
K = the number of all visual features.
2) Language Feature Embedding
- use BERT to encode the textual information.
- given clinical report w is first split into a sequence of N tokens(i.e. subwords) using the WordPiece tokenizer.
- tokens then converted to vector representations via lookup table.
w = tokens converted to vector representations
p = position embeddings
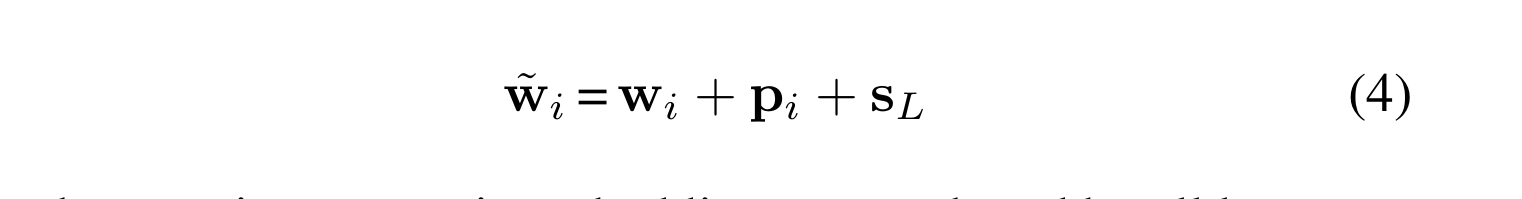
w ̃ = final language feature embeddings
S = semantic embedding vector shared by all language feature to differentiate themselves from visual embeddings.
MERLOT에서도 audio랑 text랑 둘 중 하나만 사용하는게 아니라 아예 여기처럼 semantic embedding vector으로 differentiate할 수 있게 하면 안되나?
3) Joint Embedding
-
concatenate v ̃ and w ̃ to construct the input sequence to the joint embedding component(Fig.3 (C)).
-
defines the input to the joint embedding block by using additional special tokens CLS and SEP.
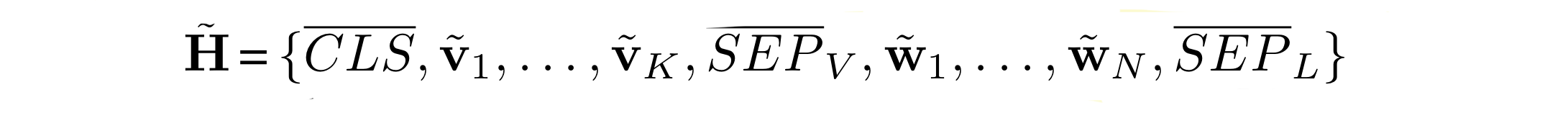
-
CLS, SEPL, SEPV are obtained by summing the special tokens with corresponding position and semantic embeddings in Fig.3(l + k).
-
contextualized embedding produced by the joint embedding block:

4) Pre-training Objectives
To pretrain MedViLL and align visual features with language features, this work takes Masked Language Modeling(MLM) and Image Report Matching(IRM) tasks.
Masked Language Modeling(MLM)
- follows BERT to replace 15% of the input text tokens with MASK token, a random token, or the original token with a probability of 80%, 10% and 10% respectively.
- model is trained to recover these masked tokens based on the contextual observation of their surrounding language tokens and the visual tokens, by minimizing the following negative log-likelihood.
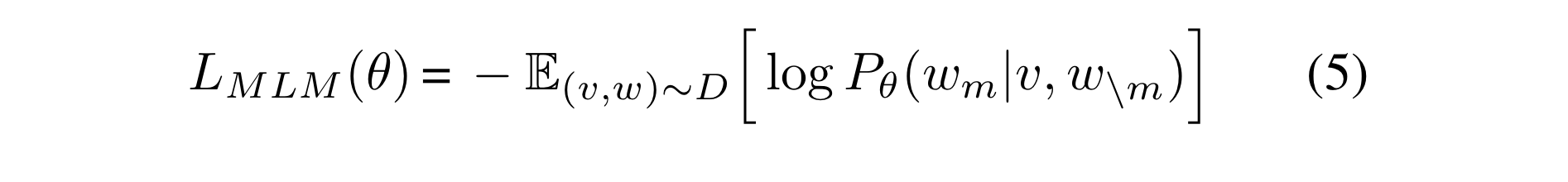
- θ is trainable parameter of the model.
(v, w) = a pair of images and its corresponding report, sampled from the traning set D.
wm = w divided into the masked tokens.
w\m * E(v, m)~D = average for the training set D
Pθ(wm|v, w\m) = probability of wm given v and w\m.
Image Report Matching(IRM)
- encourages the model to learn both visual and textual features by training the model to predict whether a given pair of image and report (v, w) is a matching pair or not.
- during pre-training, both matching image-report pairs and non-matching image-report pairs randomly sampled with 1:1 ratio from the raio.
- a non-matching report is defined as the ones that are extracted different positive diagnosis labels than the matching report.
- The joint contextualized embedding CLS is used to classify whether the input image and report are a matching pair or not, with the following loss function,
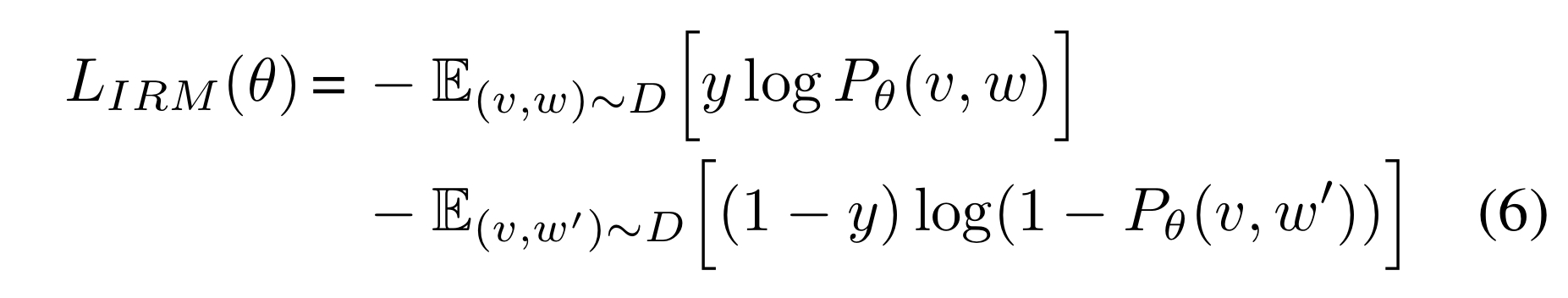
(v, m) = matching image-report pair
(v, w') = non-matching image-report pair
y = label. 1 for matching, 0 for unmatching
E(v,w)∼D = average for the training set D
Pθ(v,w) = probability of the (v, w) being paired.
C. Self-Attention Mask Schemes
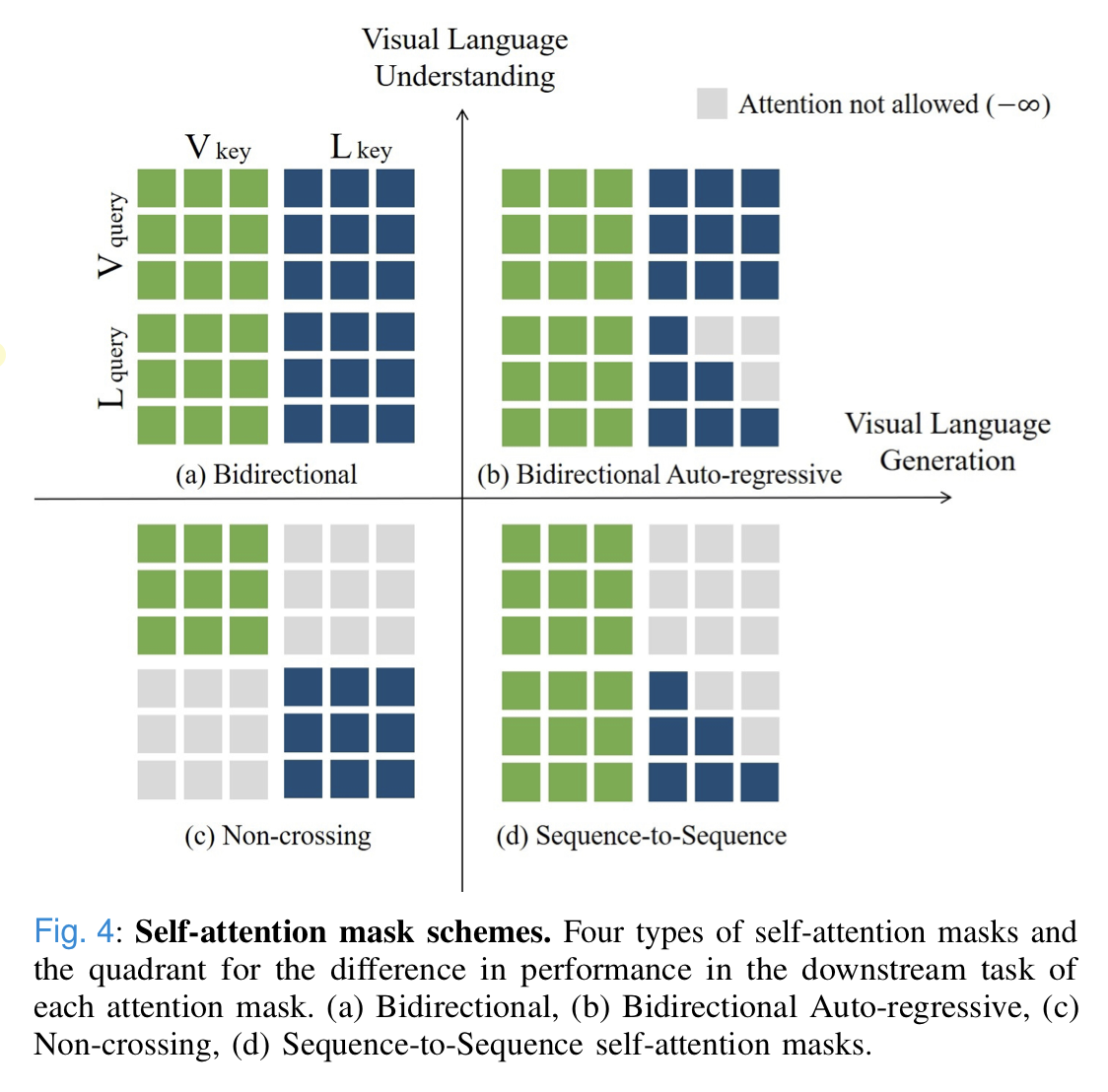
Bidirectional Attention Mask
- all inputs interact freely for unconstrained context learning between the visual-language modalities.
S2S(Sequence-to-Sequence) causal attention mask
- allows restricted context learning.
- Language features are only allowed to attend to previous words, while visual features are not allowed to attend to any language features in order to prevent leaking information from the future.
Bidirectional Auto-Regressive (BAR)
-
allows image features to be mixed with language features during pre-training, while preserving the causal nature of auto-regressive language generation.

-
single attention head in the self-attention module can be formulated as follows:

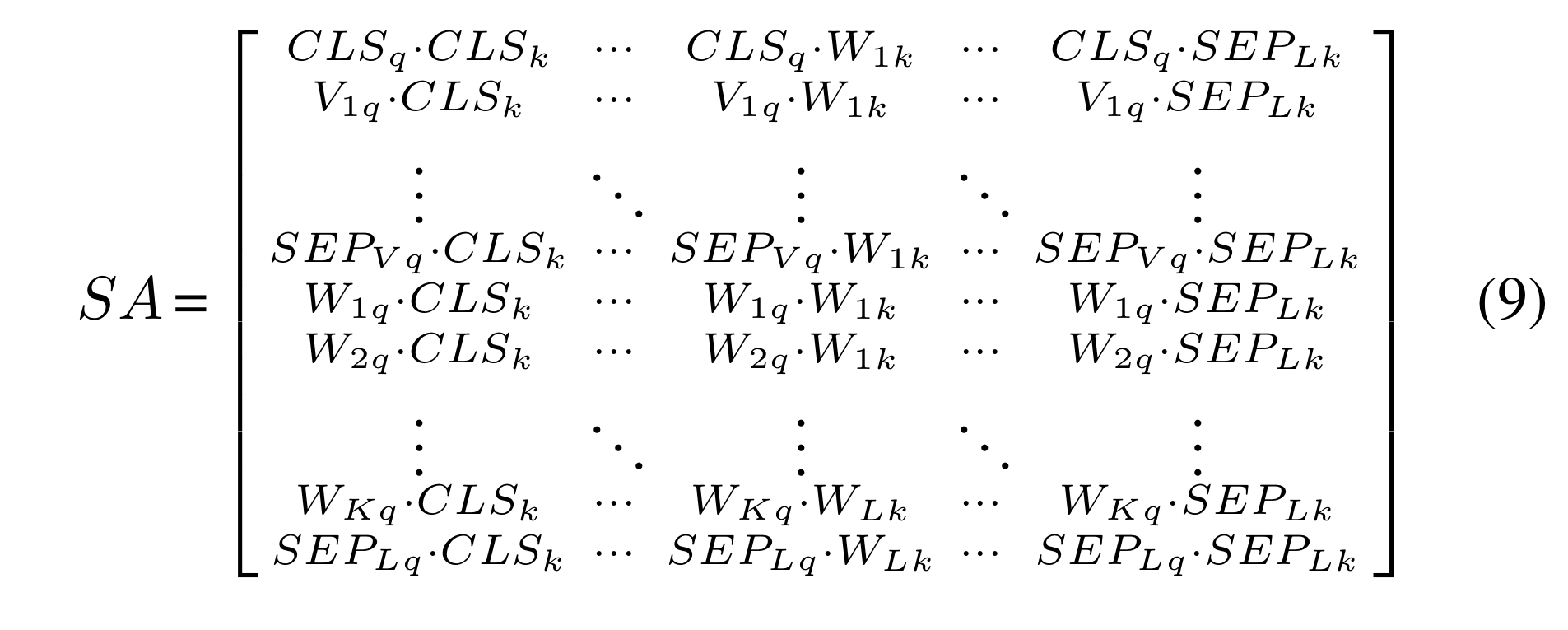
-
q = query vector
-
k = key vector
-
the computed self-attention matrix can be divided into 4 subparts of queries and key combinations by modality type.
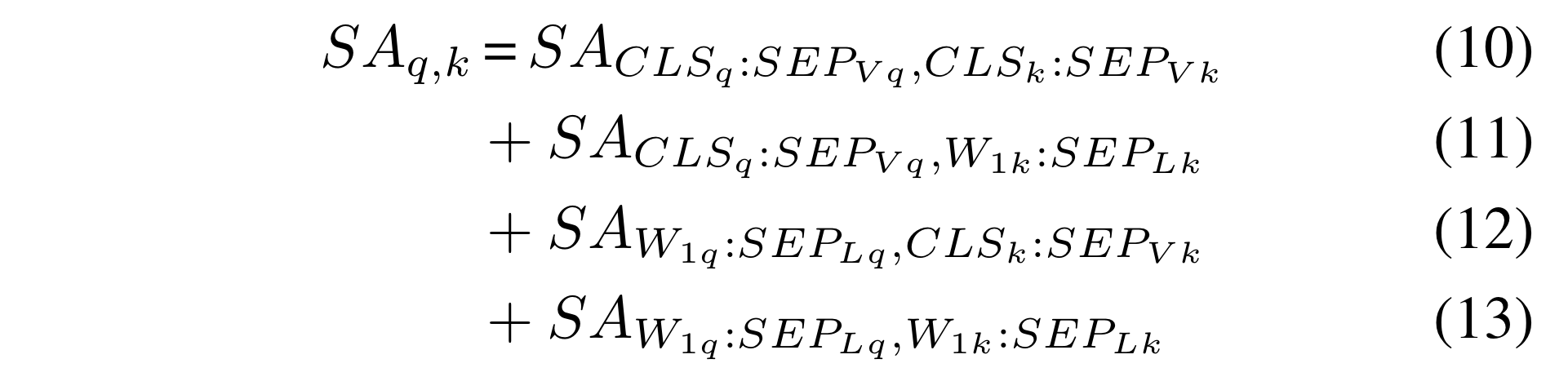
-
Eq.(10) = attention of query and key from vision
-
Eq.(11) = attention mask of query from the vision and key from language
-
Eq.(12) = attention mask of query from the language and key from vision
-
Eq.(13) = attention mask of query and key from language
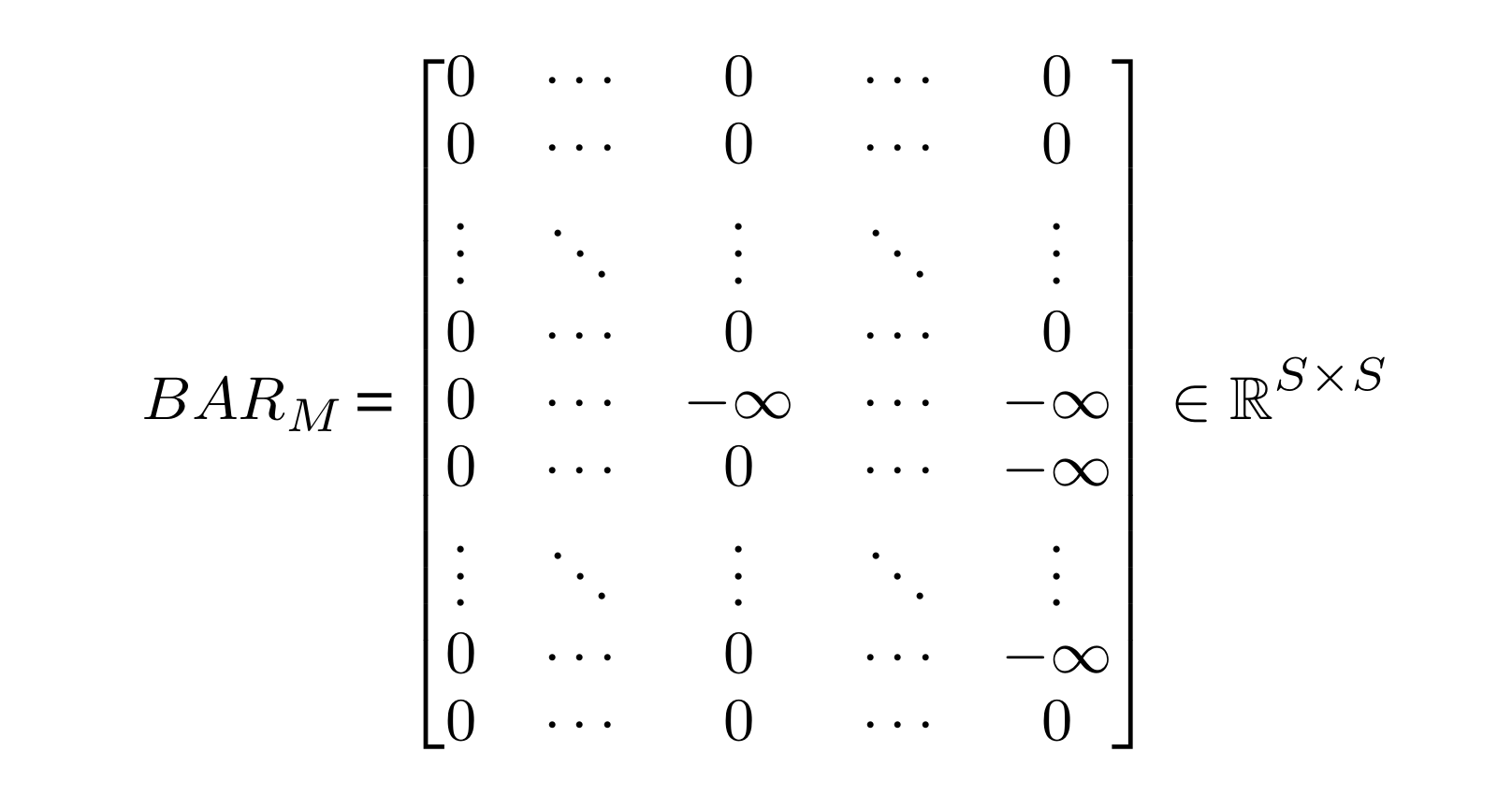
-
the attention mask matrix M is combined with the subparts of SA because adding negative infinity to the calculated attention value will result in zero in the softmax operation.
-
therefore, BAR attention mask(above picture) allows the attention calculations of all possible combinations except for Eq.(13).
-
for Eq.(13), auto-regressive attention masks are applied to language modality to enhance joint embedding between vision and language modalities and perform well in both generation and understanding tasks.
IV. Results and Discussion
A. Dataset Analysis
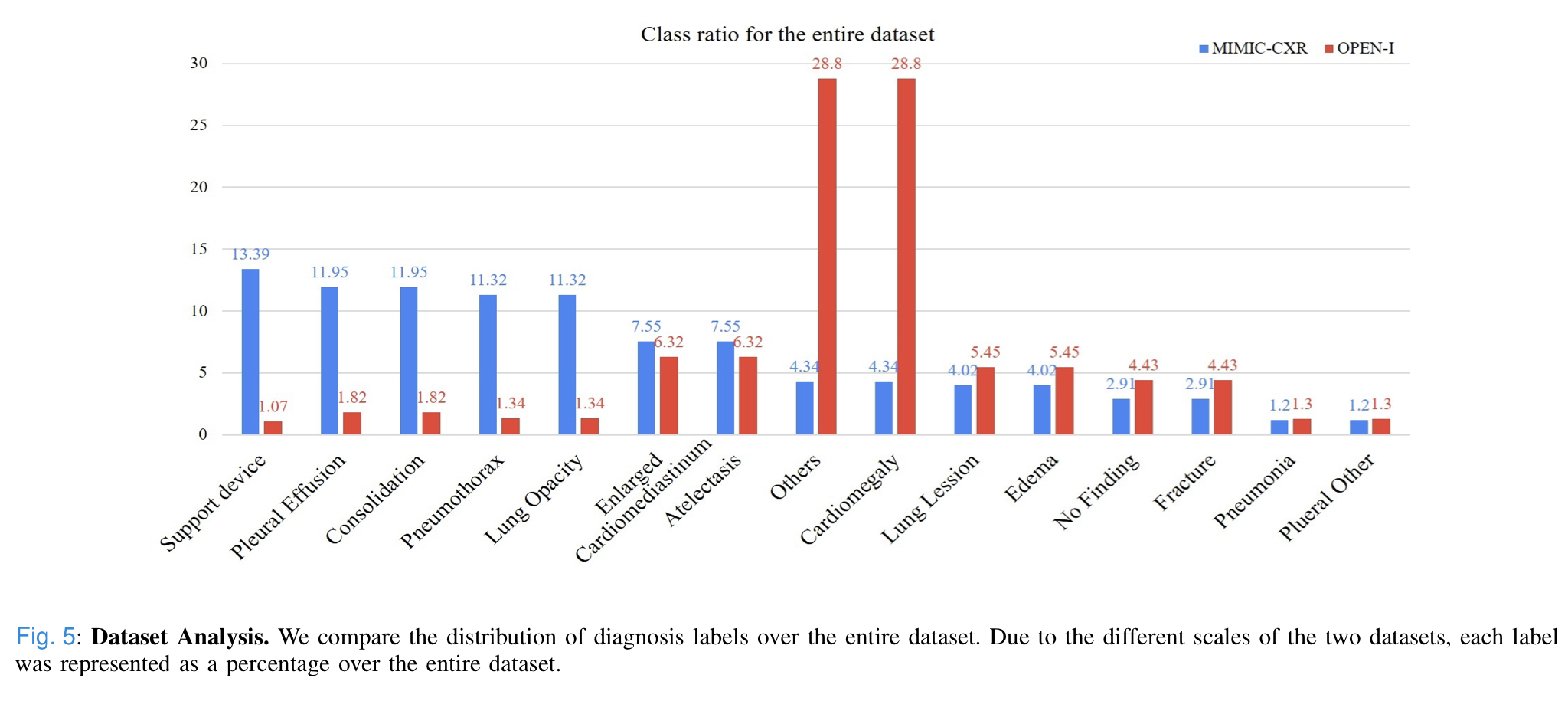
- Above shows that Open-I not only differs from MIMIC-CSR in terms of data volume, but also in terms of clinical properties.
- Therefore, evaluating the MIMIC-CSV pre-trained models on Open-I is an appropriate setup to test the generalization capability of the models.
B. Implementation Details
Visual
- ResNet-50 pre-trained on ImageNet is used as a visual feature extractor
- input image size = (512 x 512 x 3)
- last feature map = (16 x 16 x 2048)
- last feature map is flattened by spatial dimensions and 180 visual features(180 x 2048) is randomly sampled during pre-training.
Language
- To embed the text token, each sequence from reports is truncated or padded(자르거나 패딩한다) to 253 tokens in length by considering maximum embedding size.
- BERT-base architecture comprised of 12 Transformer layers.
- Each layer contains 12 attention heads, 768 embedded hidden size and 0.1 drop-out probability.
Both
- AdamW optimizer with learning rate 1e-5 setting for visual and transformer.
- trained with batch size of 128 and 50 epochs for pre-training model.
C. Task-specific Downstream Model Strategy & D. Downstream Taks Result
MedViLL is compared to four pre-training models trained with different attention masks. Two more baselines are also included: 1)Fine-tuning Only, which follows the same model architecture as MedViLL, but directly fine-tuned on each downstream task without any pre-training. 2) CNN & Transformer, which uses the CNN module for encodeing image only, and Transformer module for encoding report only, and the outputs from each module are used for downstream tasks. Also does not pretrain.
In summary, MedViLL achieved the best or second-best performance by analyzing statistical significance.
Also, shows superior generalization ability by outperforming most of the models in out-of-domain evaluations.
1) Diagnosis Classification
Model Strategy
- for a given image-report pair, the positive labels are extracted from the report by Chexpert labeler as the diagnosis labels.
- because single pair can have multiple diagnosis up to 14, 14 linear heads on top of CLS is used and the model is fine-tuned to used the binary cross-entropy.
- evaluated with AUROC, F1 score.
Task Result
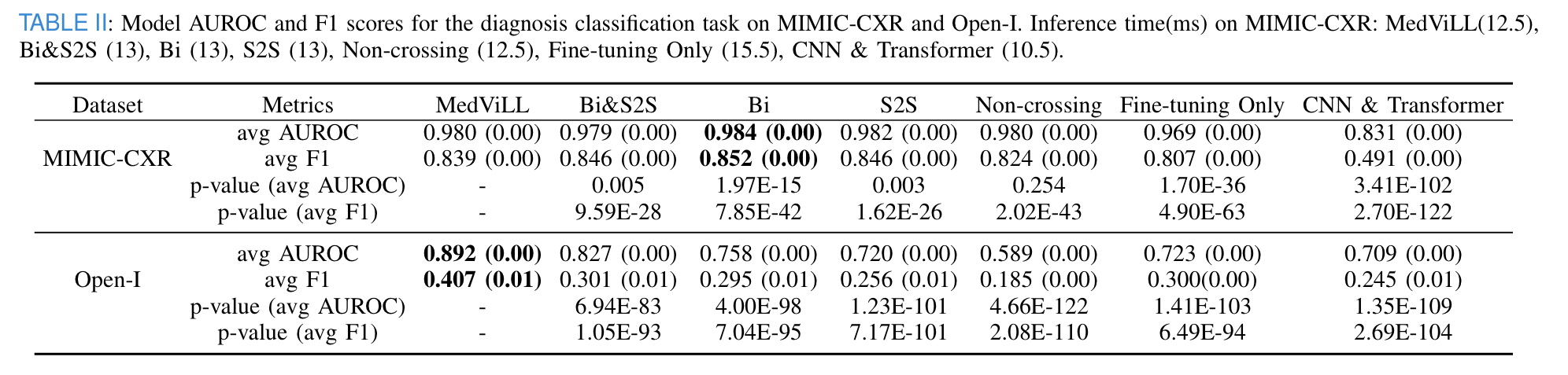
- MedViLL outperforms all other baselines with a statistically meaningful difference in MIMIC-CSR.
- Also outperforms all models statistically significantly when transferred to Open-I.
- taking advantage of both Bi and S2S mask demonstrates much better generalization than the individual tasks.
2) Medical Image-Report Retrieval
Model Strategy
Image-to-report(I2R) Retrieval, Report-to-Image(R2I) Retrieval
- requires the model to retrieve the most relevant report from a large pool of reports given an image, and vice versa for R2I Retrieval.
- given an image, any report that contains the same Chexpert diagnosis labels as the original matching report is considered a positive image-report pair, and negative pair otherwise. The final multi-modal representation CLS is used as the input to a binary classifier to classify the given pair, which is trained by the binary cross-entropy loss.
- evaluated by Hit@K, Recall@K, Precision@K(K = 5), and mean reciproal rank(MRR)
Task Result
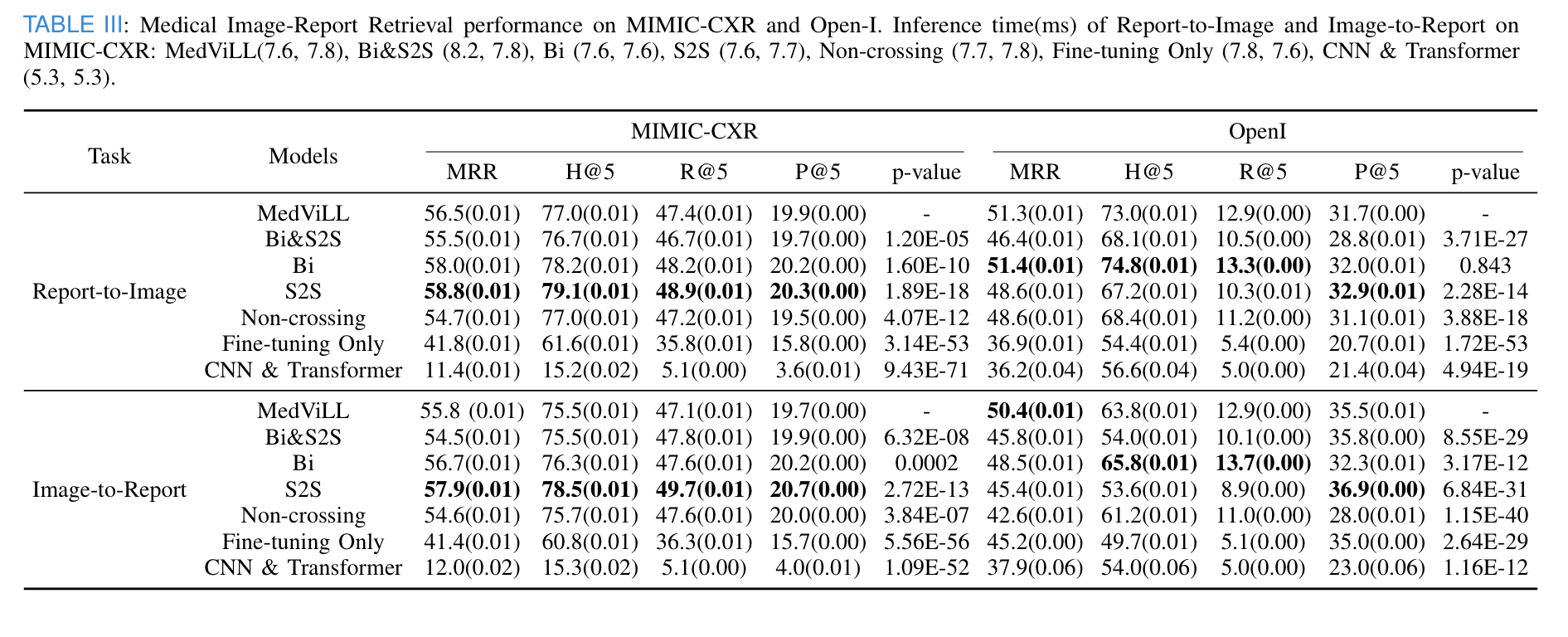
- all pre-trained models significantly outperform naive baselines for the MIMIC-CXR dataset.
- MedViLL outperforms when fine-tuend on the unseen Open-I dataset except for Bi. However, although Bi outperforms MedViLL, there is no statistically significant difference.
- In I2R Retrieval, S2S statistically outperforms MedViLL in MIMIC-CSR, but MedViLL is superior to all baselines with a statistically meaningful difference in Open-I.
3) Medical Visual Question Answering
Model Strategy
- VQA on the VQA-RAD dataset, which contains 3515 question-answer pairs on 315 images.
- given a pair of an image and a free-text question, final representation CLS is used to predict a one-hot encoded answer.
- evaluated with accuracy, but separately for the closed questions and the open-ended questions.
Task Result
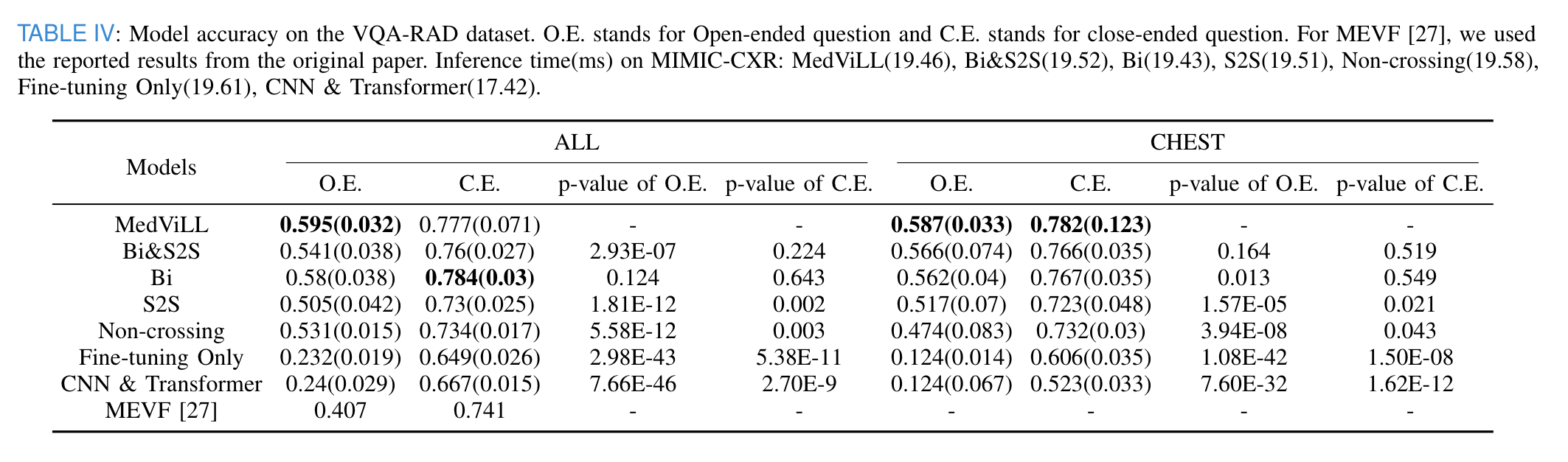
- the table above shows the VQA accuracy when models were fine-tuned with all image types(ALL), and only with the Chest X-ray images(CHEST).
- MedViLL significantly outperforms MEVF, the state-of-the-art model for the VQA-RAD dataset, which indicates the effectiveness of the multi-modal pretraing for this complex multi-modal reasoning task.
- MedViLL shows significantly higher performance than all models for open-ended questions of 'ALL' and 'CHEST' statistically.
- For close-ended questions of ALL, Bi performed the best of all models, followed by MedViLL, but not statistically meaningful.
- For close-ended questions of CHEST, MedViLL outperforms all baselines, but not statistically significant against Bi&S2S and Bi.
4) Radiology Report Generation
Model Strategy
- self-attention mask fixed to S2S for all models.
- at inference, reports can be generated by sequentially recovering the MASK Tokens; given visual features followed by a single MASK token. the model can predict the first language token.
- Then the first MASK is replaced with sampled token, and a new MASK token is appended. Process is repeated until the model predicts SEP token as a stop sign.
- evaluated by perplexity, clinical efficacy, and BLEU score.
Perplexity : evaluates the linguistic fluency of the model.
Clinical Efficacy : evaluates if the model can capture the semantics of the given image.
obtained by applying the Chexpert labeler on both the original matching report and generated report.
BLEU : evaluates how similar the generated report is to the reference report.
Task Result
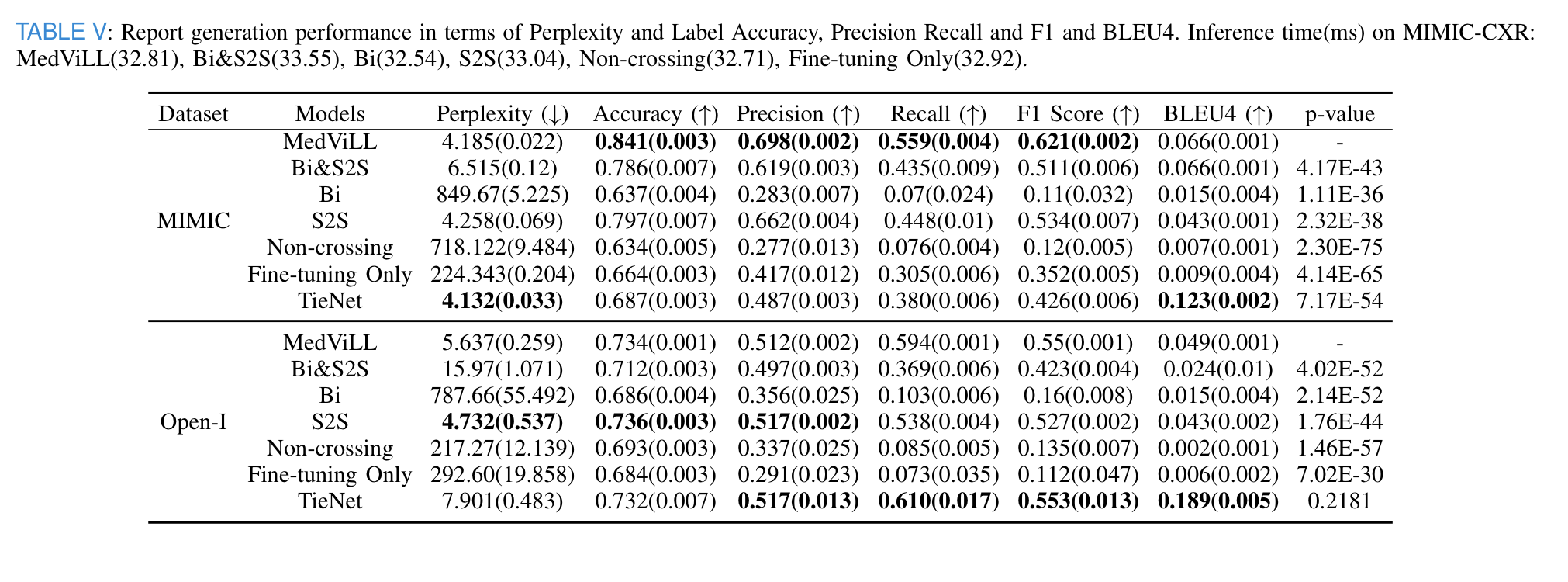
- models pretrained with auto-regressive manners(MedViLL, Bi&S2S, S2S) all significantly outperform the other models in terms of both perplexity(except for TieNet) and clinical efficacy metrics for the MIMIC-CXR dataset.
- MedViLL achieved the best performance on the MIMIC dataset with a statistically significant difference.
- MedViLL best captures the semantics embedded in the image given the highest F1 Score.
- When fine-tuned on unseen Open-I dataset, TieNet performs the best of all models followed by MedViLL, but statistically not significant between the two.
- the bidirectional mask seems to be evidently harmful for the VLG task, most likely due to its incompatibility with the auto-regressive nature of VLG.
E. Qualitative Results and Analysis
1) Attention Map Visualization
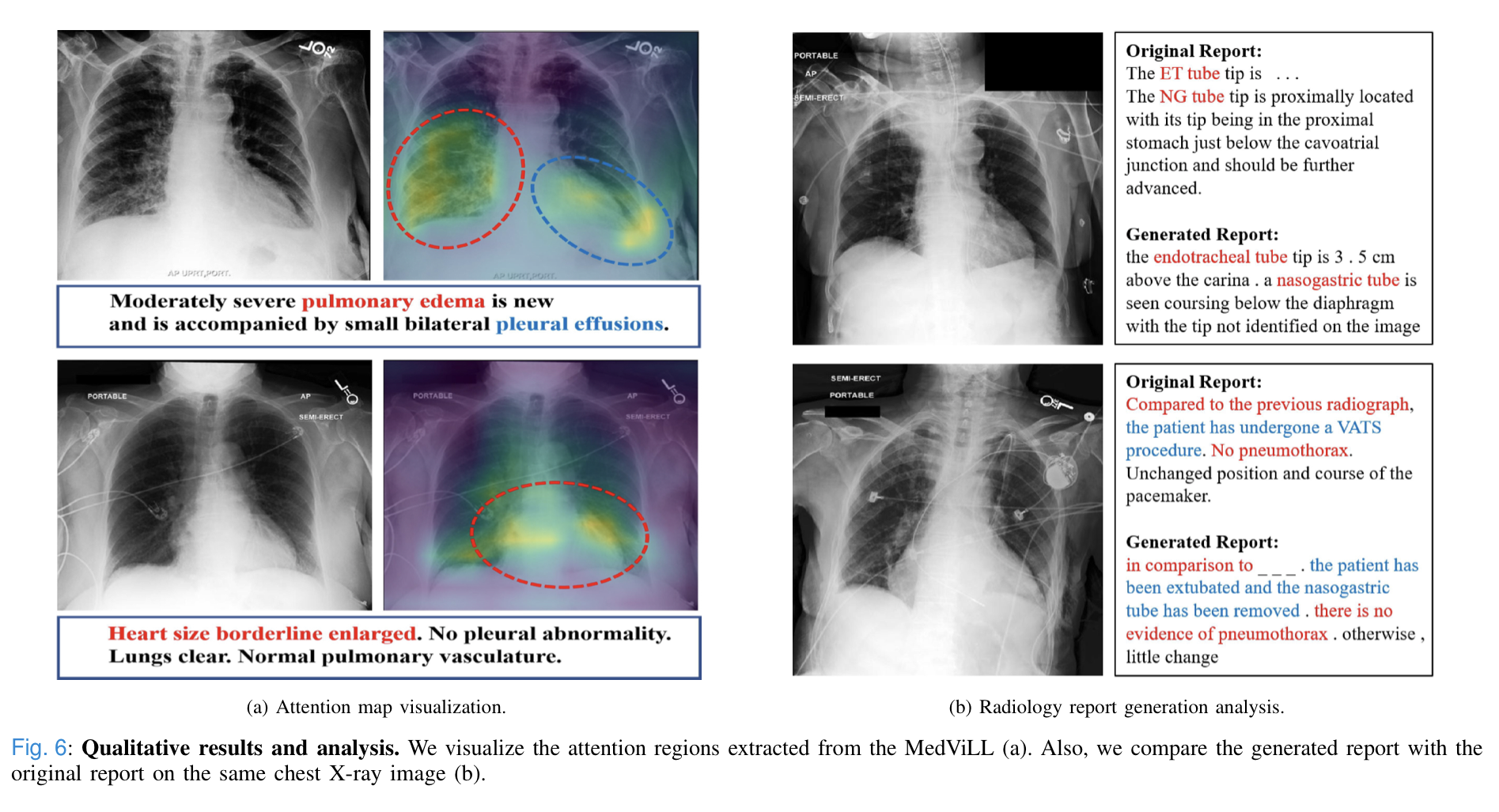
- Above is the visualization of the attention maps of the intermediate Transformer layers of MedViLL.
- Although MedViLL uses only report and images for training without any annotations, it can well attend to the disease-discriminatory regions written in the reports, as confirmed by a professional cardiologist.
2) Radiology Report Generation
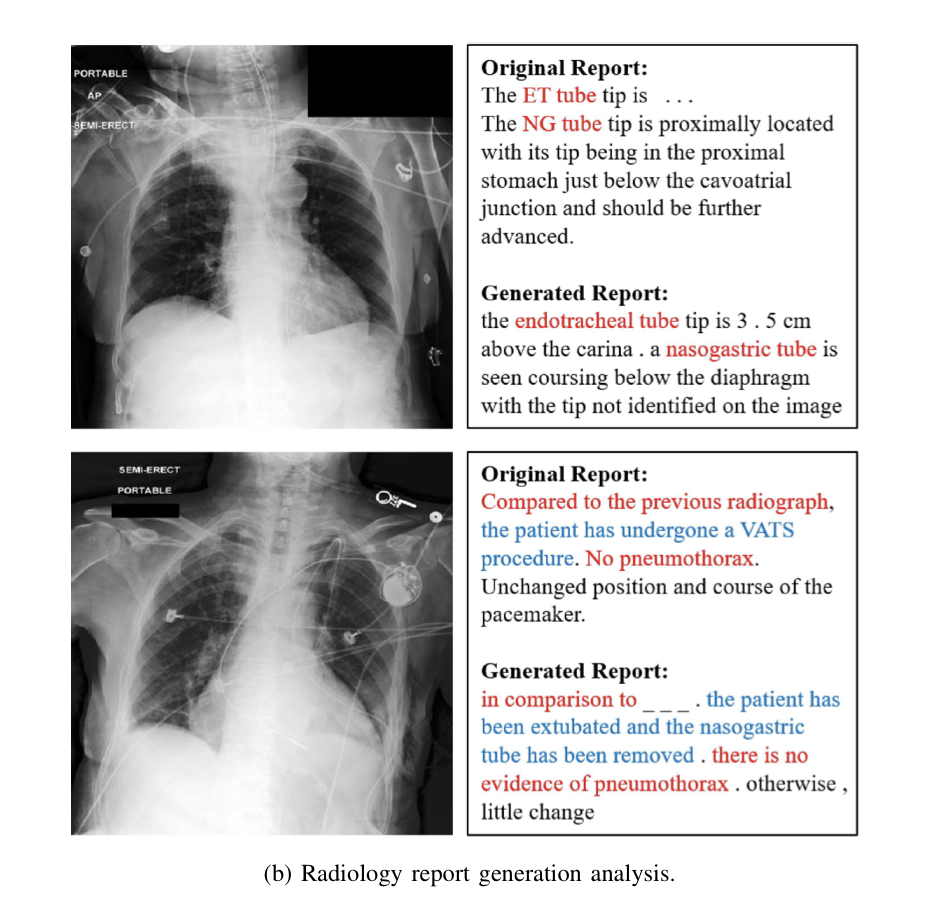
- Above shows that MedViLL is able to generate clinically appropriate reports.
- MedViLL generates a report with abbreviated medical terms expanded to the original terms(ET -> endotracheal tube).
- The blue text in the original report describes the completion of VATS, and the generated report describes extubation and nasogastric tube removal, which is a part of VATS. This indicates that BLEU score is not an appropriate measure to evaluate report generation especially in the medical domain.
3) Medical Image-Report Retrieval
- Above demonstrates the clinical understanding of MedViLL. We can observe that the results in the top-3 retrieved samples all share the same diagnosis labels as the given query.
- the samples in the low rank contain labels irrelevant to the given query.

Pre-training involves preparing a model on a large dataset before fine-tuning it for specific tasks. This process enhances the model's accuracy and efficiency, making it ideal for complex applications. For instance, in the field of aesthetic medicine, practitioners might buy xeomin for pre-treatment procedures to ensure optimal results. Pre-training can similarly refine AI models, ensuring high performance and reliability in diverse professional domains.