Paper Review
1.Going Deeper with Convolutions(InceptionV1) - 논문 구현
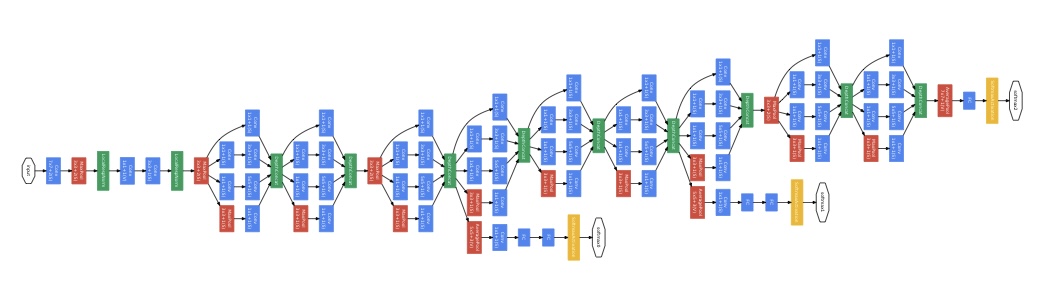
이번 포스팅에서는 GoogLeNet(Inceptionv1) 논문을 정리해보려고 한다. 1. Abstract 이 논문의 초록에서는 GoogLeNet에 대해 간략히 설명하고 있다. GoogLeNet의 가장 중요한 특징은 연산을 하기 위해 소모되는 자원의 사용 효율이 개
2.Very Deep Convolutional Networks for Large-Scale Image Recognition(VGGNet) - 논문 구현
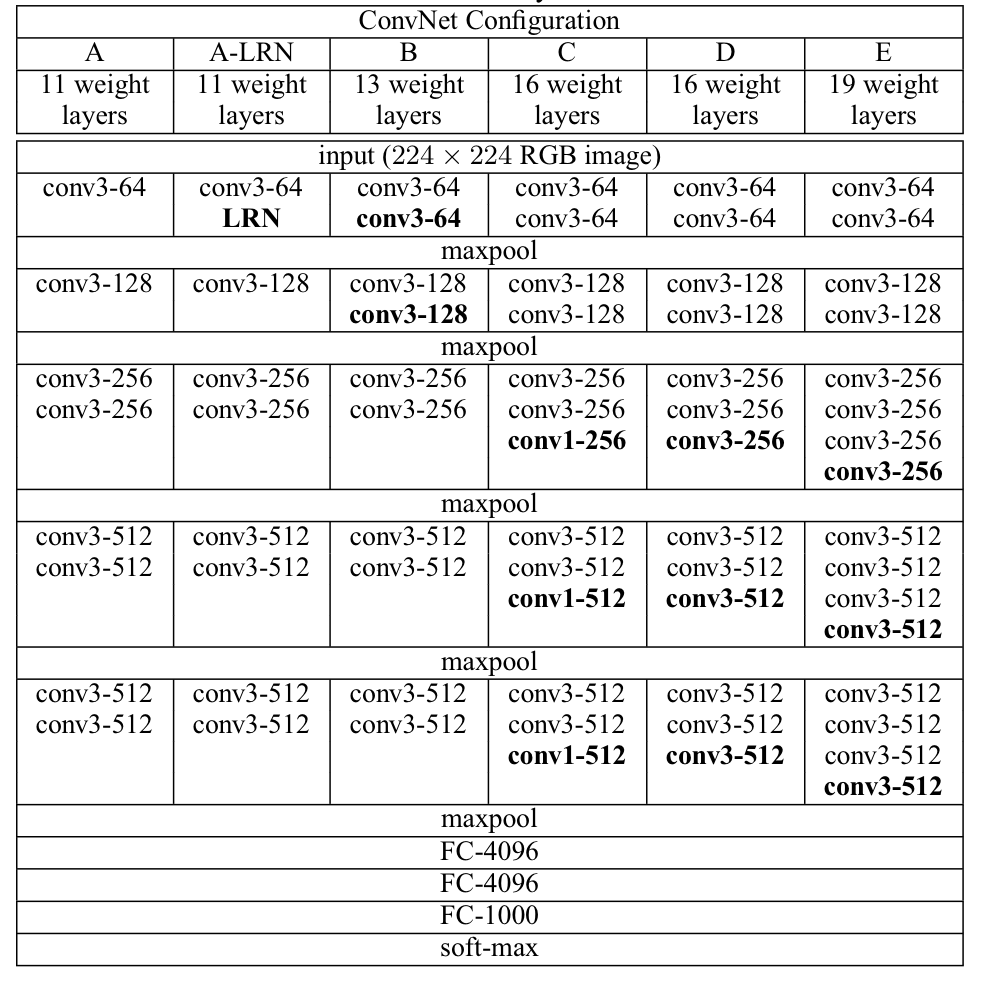
VGGNet은 ILSVRC 2014에서 2등을 한 컴퓨터 비전 모델이다. 이번 포스팅에서는 본 논문의 Introduction, ConvNet Configurations를 정리하고, VGGNet의 구현 코드를 작성해볼 예정이다. 최근 Convolutional Networ
3.TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering - 논문 정리
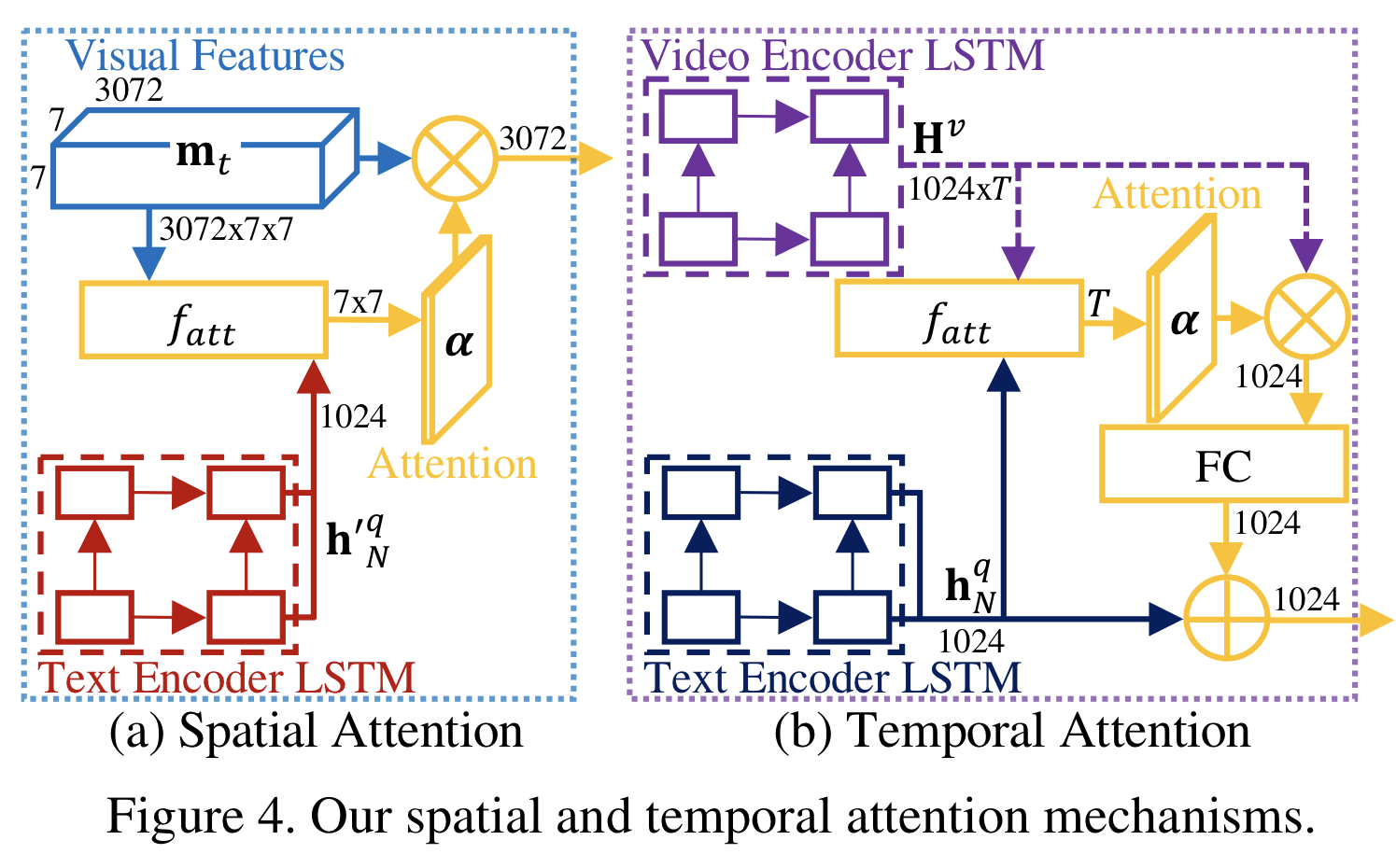
CMU MMML 강의 수강을 시작하면서 multimodal의 활용 분야들을 알게 되었는데, 이 논문은 여러 분야들 중 Visual Question Answering, 특히 영상에서 VQA를 수행할 때 고려해야하는 새로운 시각을 제안한다. 0. Abstract (초
4.A Joint Sequence Fusion Model for Video Question Answering and Retrieval - 논문 정리
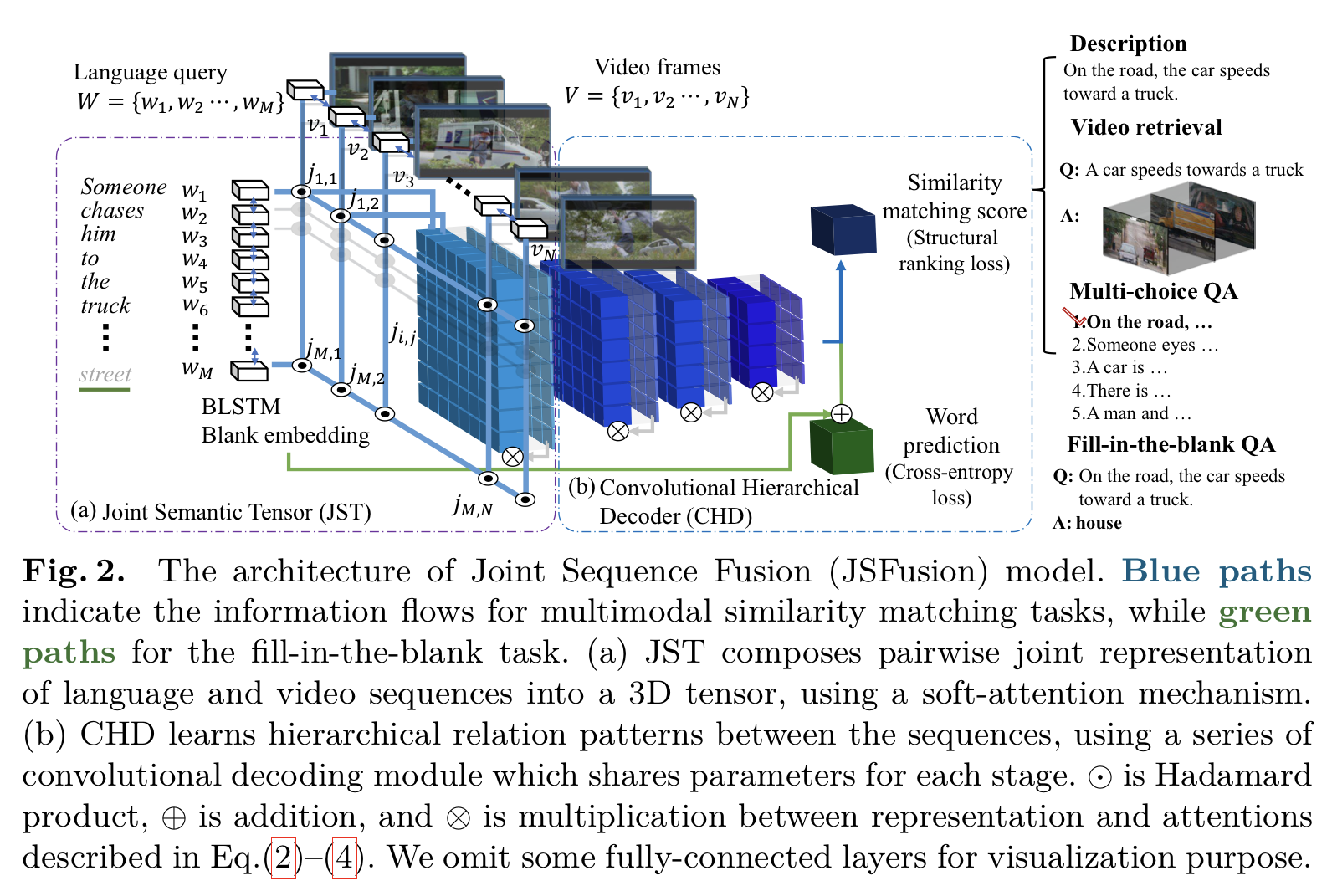
이번 게시물에서는 어떤 multimodal sequence가 주어졌을 때 의미론적 유사성을 측정할 수 있는 JSFusion이라는 접근법과 관련된 논문을 정리하고자 한다. Abstract 본 논문에서는 두 개의 multimodal sequence 데이터 사이의 의미론
5.MERLOT: Multimodal Neural Script Knowledge Models - 논문 정리 (+BERT 정리)
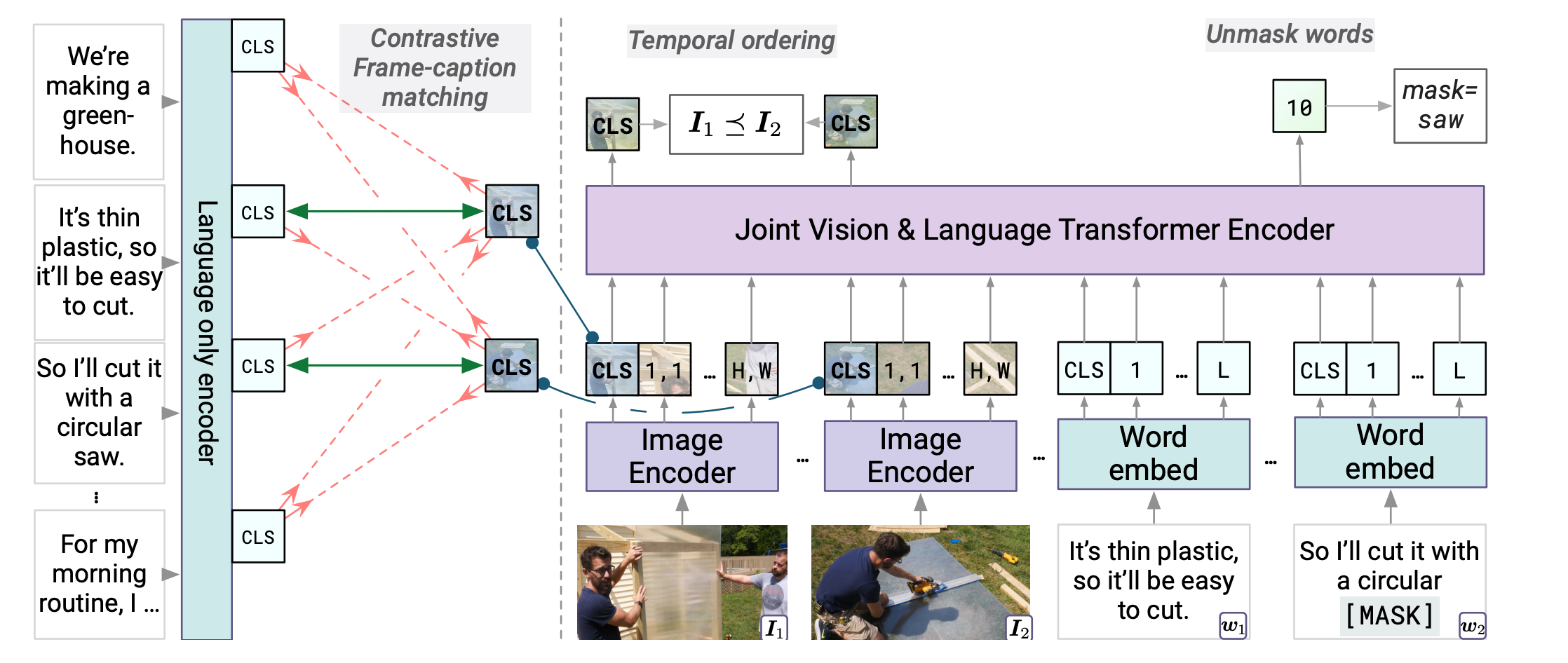
이번 게시물에서는 유튜브 영상으로 label 없이 multimodal script knowledge를 학습하는 self-supervised model인 MERLOT의 논문을 정리하고자 한다. 논문 읽기 전 - BERT 정리 논문을 이해하기 위해 알아야하는 BERT를
6.MERLOT RESERVE: Neural Script Knowledge through Vision and Language and Sound - 논문 정리
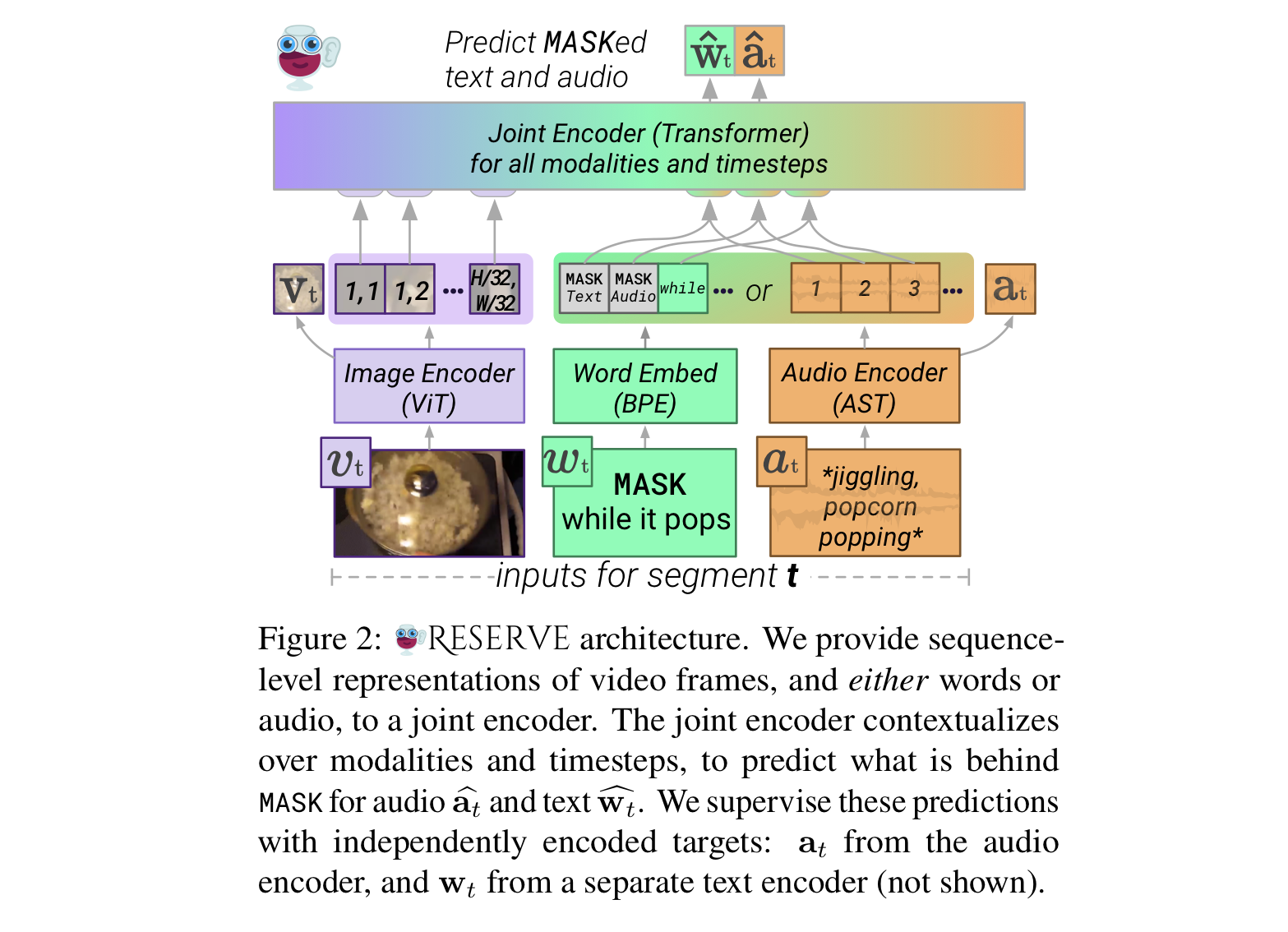
MERLOT RESERVE는 MERLOT 이후에 등장한 neural script knowledge 모델이다. MERLOT은 그래도 이해를 하면서 읽었는데, 이번 논문을 이해하지 못하는 부분이 조금 많았다. 그래도 읽고 이해를 해보려고 노력해봤으니... 정리를 하려고 한
7.Multi-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training - 논문 정리
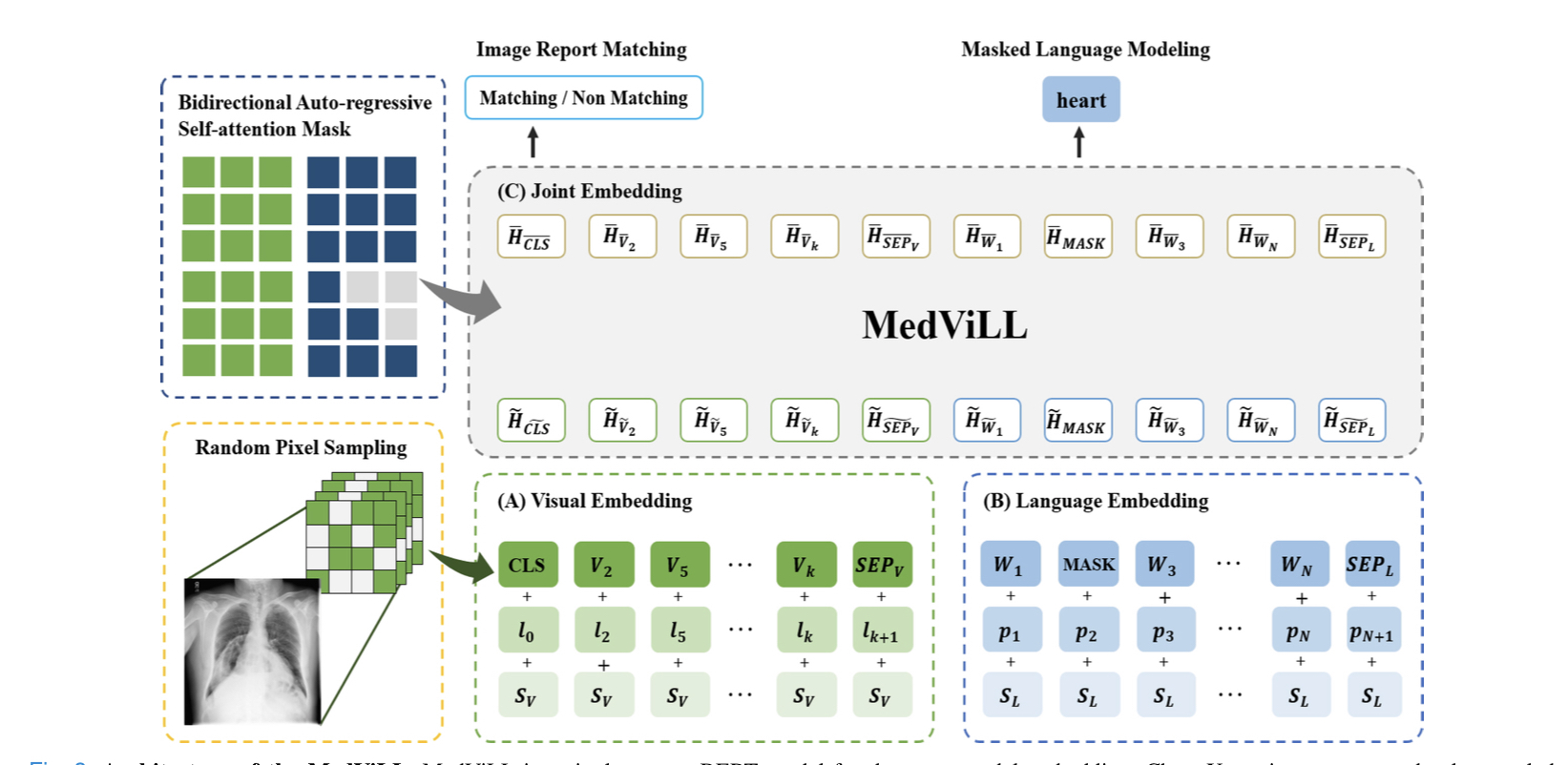
지속적으로 neural script knowledge, 그리고 Visual Question-Answer 관련 논문을 읽어서, 이번에는 정말 specific한 domain인 medical domain에서의 Vision-Language multimodal 논문을 읽어보았다