MERLOT RESERVE: Neural Script Knowledge through Vision and Language and Sound - 논문 정리
Paper Review
MERLOT RESERVE는 MERLOT 이후에 등장한 neural script knowledge 모델이다. MERLOT은 그래도 이해를 하면서 읽었는데, 이번 논문을 이해하지 못하는 부분이 조금 많았다. 그래도 읽고 이해를 해보려고 노력해봤으니... 정리를 하려고 한다. 정리하면서 조금은 더 많이 이해하게 된 것 같다..!
4 Questions to Answer
What did authors try to accomplish?
- build a model that learns self-supervised representations of videos through all their modalities(audio, subtitle, vision) teaching eachother.
What were the key elements of the approach?
1. Contrastive Span Learning
- enables learning across and between modalities
- for each videoframe, three subsegments that are either text or audio is included.
- 25% of these text and audio subsegments are replaced with a special MASK token.
- The model must match the representation atop the MASK only with an independant encoding of its span.
2. Contextualized encoding of the transcript
- joint encoder encodes the entire video's transcript at once, extracting a single hidden representation per segment.
- critical for learning visual recognition from self-supervised videos.
3. Simultaneously training on two kinds of MASKed videos to avoid shortcut learning
same input modality and output modality leads to shortcut learning, low training loss but poor representations.
i) audio only as target
- video and subtitle provided
- produce representation of both audio and text that fill MASKed blanks
ii) audio as input
- video frame, subtitle or audio provided
- Because the audio is given as input somewhere, the model only produces representations for MASKed text.
What can you use yourself?
- Using Audio to train. Audio helps the model to have better understanding of the video and text(human children learn by reentry).
- using two kinds of MASKed videos to avoid shortcut learning
What other references do you want to follow?
- bidirectional transformer
- visual transformer
- audio spectogram transformer
0. Abstract
- About MERLOT RESERVE:
- a model that represents videos jointly over time - through a new training objective that learns from audio, subtitles, and video frames.
- Given a video, the snippets(조각/부분) of text and audio are replaced with a MASK token; the model learns by choosing the correct masked-out snippet.
- pretrained on 20 million YouTube videos.
- Results of MERLOT RESERVE:
- When finetuned, it sets state-of-the-art on Visual Commonsense Reasoning(VCR_, TVQA, and Kinetics-600; outperforming work by 5%, 7%, and 1.5% respectively.
- ablations show that these tasks benefit from audio pretraining.
- strong multimodal commonsense understanding.
- even in the fully zero-shot setting, outperforms supervised approaches on the Situated Reasoning(STAR) benchmark.
1. Introduction
- predicting sound is an instance of learning from reentry: where time-locked(시간이 정해진) correlations enable one modality to educate others.
- This work introduces a model that learns self-supervised representations of videos, through all their modalities(audio, subtitles, vision).
- MERLOT RESERVE : Multimodal Event Representation Learning Over Time, with RE-entrant SupERVision of Events.
- learns joint representations from all modalities of a video, using each modality to teach others.
- introduce a new contrastive masked span learning objective to learn script knowledge across modalities. generalizes and outperforms previously proposed approches.
- the model must:
- figure out which span of text (or audio) was MASKed out of a video sequence.
- match each video frame to a contextualized representation of the video's transcript.
- Experimental results show that RESERVE learns powerful representations.
- RESERVE performs well in zero-shot settings.
Key contributions :
1. RESERVE, a model for multimodal script knowledge, fusing vision, audio, and text.
2. A new contrastive span matching objective, enabling the model to learn from text and audio self-supervision.
3. Experiments, ablations, and analysis, that demonstrate strong multimodal video representations.
2. Related Work
Joint representations of multiple modalities
Joint Representations of Multiple Modalities
Other Works
- VisualBERT family
- typically uses a supervised object detector image encoder backbone.
- pretrain on images paired with literal captions.
- Cross-modal interactions learned in part through a masked language modeling(MLM) objective.
- MERLOT
- learns joint vision-text model from web videos with automatic speech recognition(ASR).
- strong results on a variety of video QA benchmarks when finetuned.
- but lacks audio: which means that it is limited to representing video frames paired with subtitles.
MERLOT RESERVE
- represents and learns from audio, outperforms MERLOT.
Co-Supervision between Modalities
- complex inter-modal interactions : a common pitfall when training a joint multimodal model, because the interactions can be ignored during learning, in favor of simpler intra-model interactions.
Other Works
- Thus learns independant modality-specific encoders, using objectives that cannot be shortcutted with simple intra-modal patterns.
- independent encoders can be combined through the late fusion, yet late fusion is strictly less expressive than early fusion approach.
MERLOT RESERVE
- model learns for jointly representing videos, through all their modalities.
- train using a new learning objective that enables co-supervision between modalities.
3. Model: RESERVE
Model Abstract
- represents a video by fusing its constituent(구성하는) modalities(vision, audio, and text) together, and over time. representations enable both finetuned and zero-shot downstream applications
- formally, we split a video V into a sequence of non-overlapping segments in time {S}.
- Each segment has:
- A frame V from the middle of the segment.
- The ASR tokens W spoken during the segment
- The audio a of the segment.
- segments default to 5 seconds in length.
- for each segment S, exactly one of text or audio is provide to the model. -> because text W was transcribed by given audio a.
3.1 Model Architecture
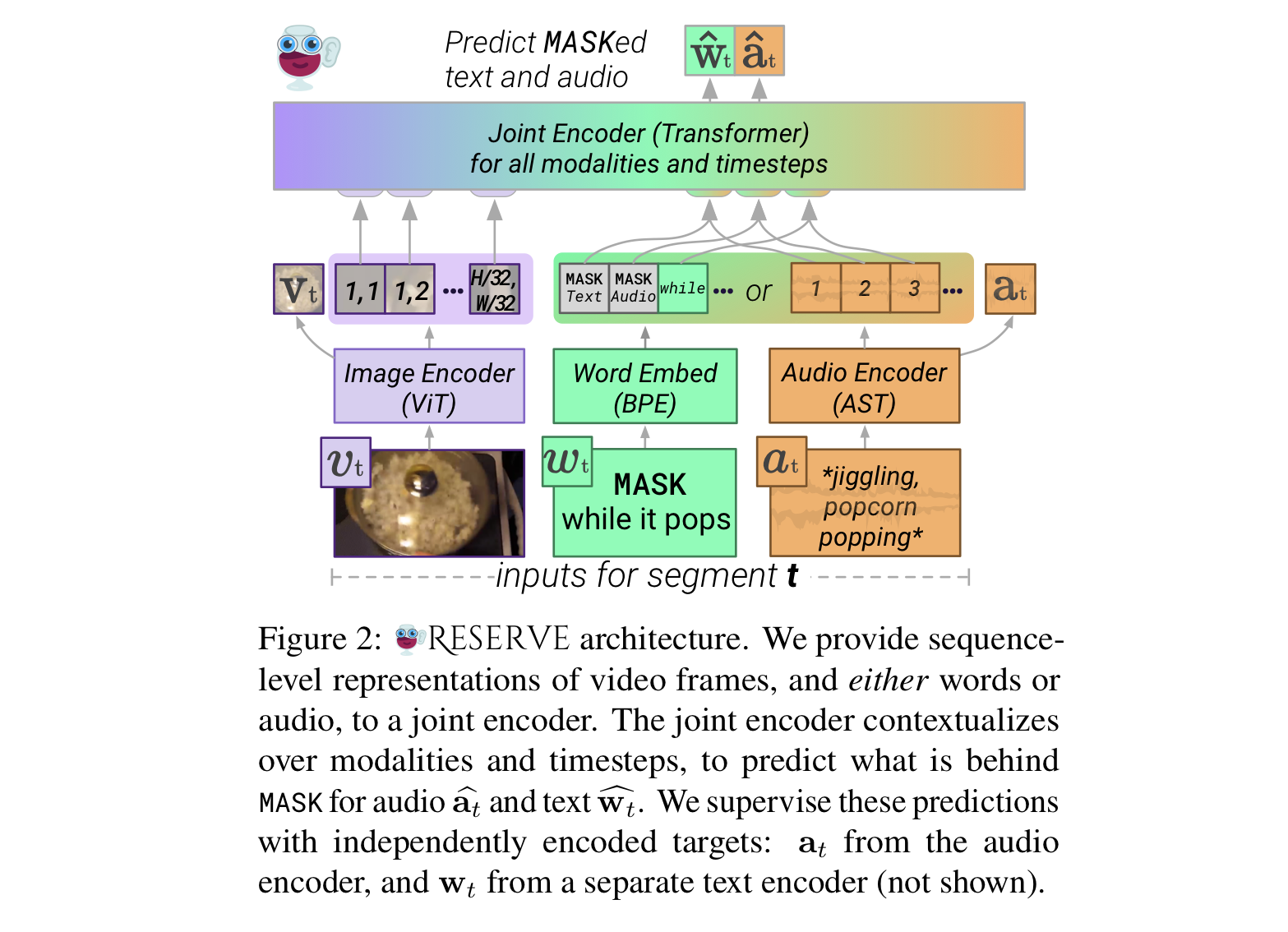
- first, pre-encdoe each modality independantly
- images/audio : Transformer
- text : BPE embedding table
- then, learn a joint encoder to fuse all representations, together and over time.
Image Encoder
- uses a Vision Transformer(ViT) to encode each frame independently.
- uses a patch size of 16 and apply a 2x2 query-key-value attention pool after the Transformer. (which converts an image size H x W into H/32 x W/32 feature map of dimension d.
Audio Encoder
- audio in each segement a is splitted into three equal-sized subsegments. (which is for compatibility with the lengths at which we mask text.)
- uses Audio Spectogram Transformer(AST) to encode each subsegment independently.
- three feature maps are concatenated; the result is of size 18 x d for every 5 seconds of audio.
Joint Encoder
- uses Bidirectional Transformer to jointly encode all modalities
- uses linear projection of the final layer's hidden states for all objectives(e.g. predicted W, predicted a).
Independently-Encoded Targets
- supervises the joint encoder by simultaneously learning independently-encoded 'target' representations for each modality(각각 독립적으로 encoding된 target representation들을 동시에).
- doing above is straightforward for the image and audio encoders:
- a CLS is added to their respective inputs, and extract the final hidden state V or a at that position.
- for text, separate bidirectional Transformer span encoder, which computes targets W from a CLS and embedded tokens of candidate text span.
Architecture Sizes
-
RESERVE-B:
hidden size=768, 12-layer ViT-B/16 image encoder, 12-layer joint encoder -
RESERVE-L:
hidden size=1024, 24-layer ViT-L/16 image encoder, 24-layer joint encoder -
12-layer audio encoder, and a 4-layer text span encoder always used.
3.2 Contrastive Span Training
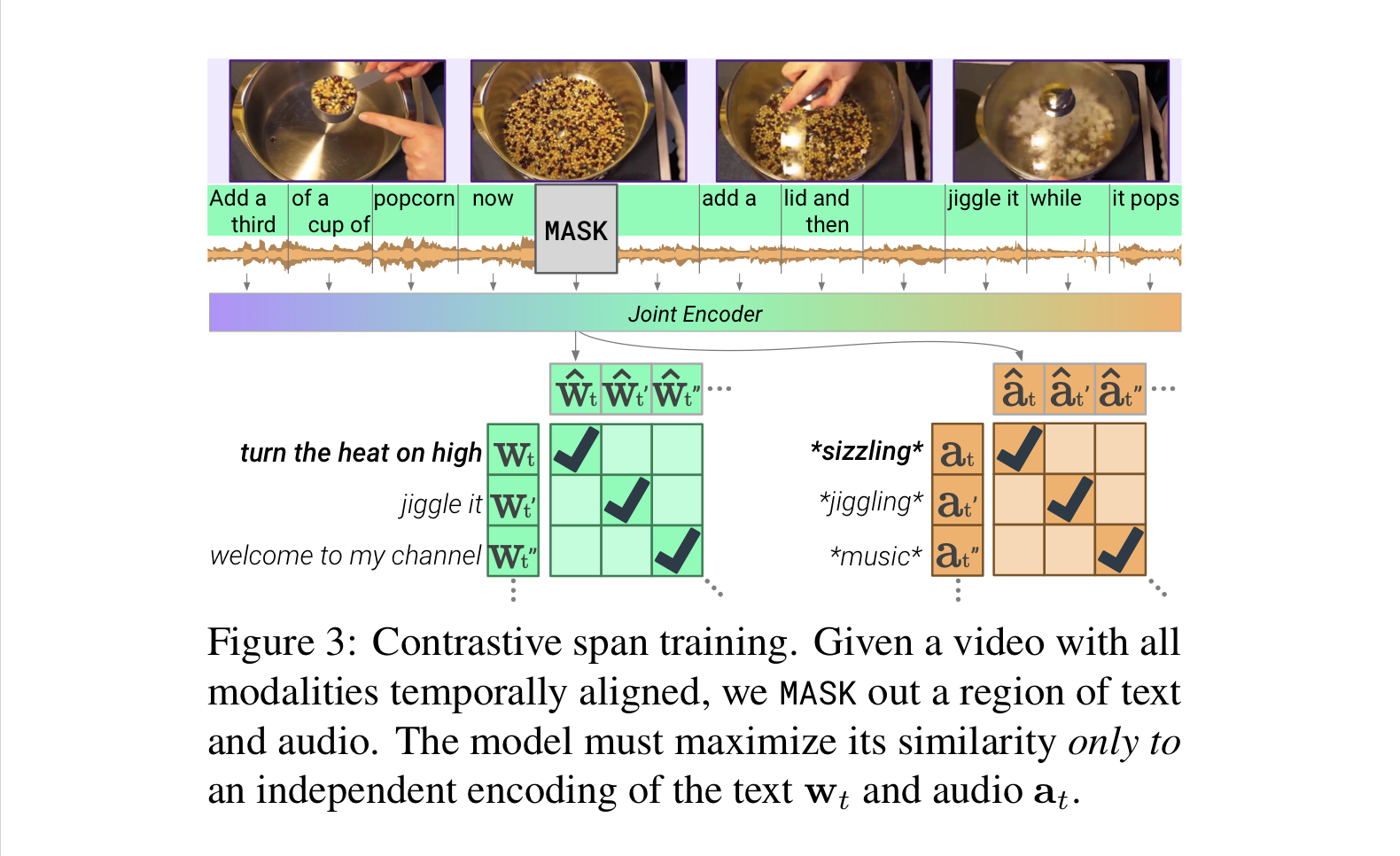
- Contrastive Span training enables learning across and between three modalities.
- the model is given a sequence of video segments.
- for each segment, the video frame, and three 'subsegments' that are each either text or audio is included. (subdivided audio segments are encoded independently by Audio encoder before being fused by Joint Encoder.)
- replace 25% of these text and audio subsegments with a MASK token for training
- the model must match the representation atop the MASK only with an independent encoding of its span.(이부분 이해가 안간다. )
- predict representations at a higher-level semantic unit than individual tokens.
- also enables the model to learn from both audio and text, while discouraging memorization of raw perceptual input, or tokens(which can harm representation quality).
- minimizes the cross entropy between the MASKed prediction W and its corresponding phrase representation W, versus others in the batch:
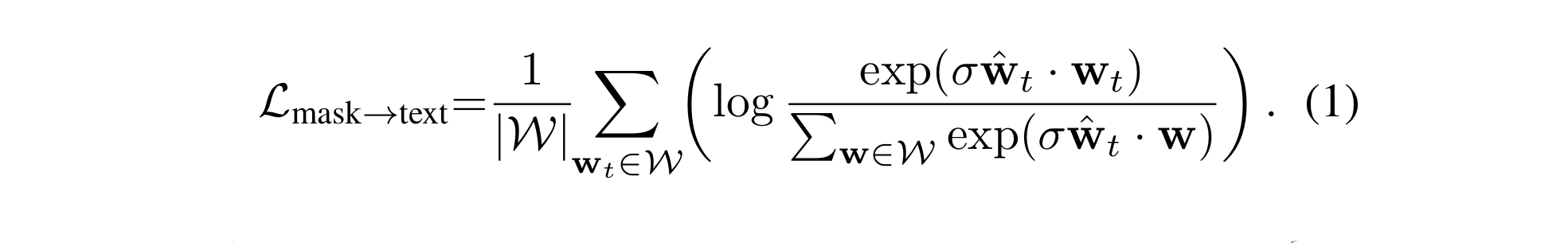
- first, L2 normalize w and predicted w, and scale their dot product with a parameter σ.
- add above to its transposed version L text->mask which returns text-based loss L text.
- similarly, L audio for audio, between the MASKed prediction a and its target a, versus other a in the batch.
- also simultaneously trains the model to match video frames with contextualized encoding of the transcript.
- Joint encoder encodes the entire video's transcript, and extracts a single hidden representation per segment predicted V.
- same contrastive setup is used as Equation 1, which returns frame-based loss L frame.
- The final loss is the sum of the component losses:
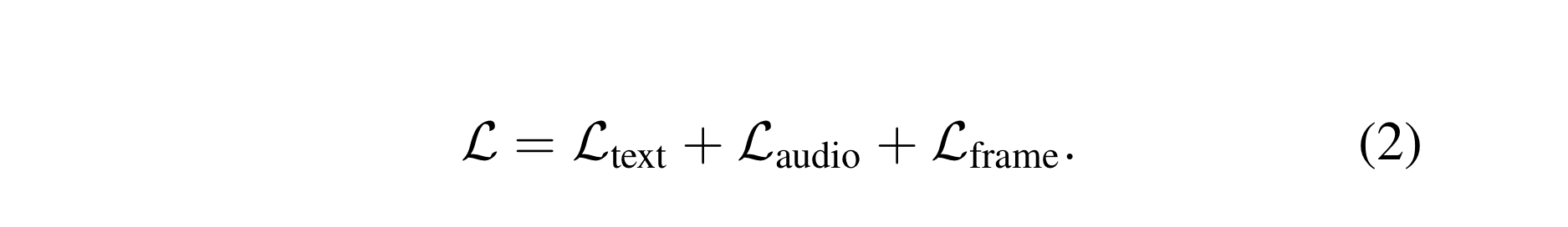
Avoiding Shortcut Learning
- predicting a perceptual modality from the same modality input -> shortcut learning(low training loss, but poor representations)
- to avoid shortcut learning, while still using audio as target, simultaneosly trains on two kinds of masked videos:
- Audio only as target:
Provide only video frames and subtitles.
model produces representations of both audio and text that fill in MASKed blanks. - Audio as input:
provide video frames, and subtitles or audio at each segment.
the model only produces representations for MASKed text.
- Audio only as target:
Pretraining Setup
- batch size of 1024 videos, each with N=16 segments(split into two groups of 8 segments each)
- AdamW used to minimize Equation 2.
3.3 Pretraining Dataset
- prior work demonstrated empirical improvements by increasing dataset size.
- YT-Temporal-1B:
- 20 million English-subtitled YouTube videos, 1 billion frames
4. Experiments
4.1 Visual Commonsense Reasoning(VCR)
- Most competitive models for VCR are pretrained exclusively on images paried with captions.
VCR Task
- A model is given an image from a movie, and a question, and has to choose the right answer between 4 multiple choice options(Q -> A).
- it then is given four rationales justifying the answer(답을 정의하기위한 근거들), and the model has to choose the correct one(QA -> R).
- the model must choose the right answer and then the right rationale, to get the question 'correct'.
Finetuning Approach
- for both Q->A and QA -> R, it is scored independently.
- pool a hidden representation from a MASK inserted after the text, and pass this through a newly initialized linear layer to extract a logit, which we optimize through cross-entropy.
4.1.1 Ablations: contrastive learning with audio helps

Contrastive Span helps for Vision+Text modeling
- comparing pretraining objectives for learning from YouTube ASR and Video alone:
- a. MASK LM.
- this objective trains bidirectional model -> independently predict masked-out tokens.
- uses SpanBERT-style masking, where text spans are masked out. Each span W is replaced kby a MASK token.
- each of its subwords W predicted independently.
- b. VirTex
- mask text subsegments and extract their hidden states.
- sequentially predict tokens W, using a left-to-right language model(LM).
- contrastive span objective boosts performance by over 2%, after one epoch of pretraining only on vision and text.
Audio pretraining helps, even for the audio-less VCR:
- d. Audio as target
- the model is only given video frames and ASR text as input.
- contrastive span pretraining over the missing text spans and audio span.
- boosts VCR accuracy by 0.7%.
- e. Audio as input and target
- audio as target + simultaneously given video+text+audio sequences, wherein it must predict missing text.
- boosts accuracy by 1%.
- f. Sans strict localization
- corret subsegments at the true position t as a correct match, also counts adjacent MASKed out regions. (이해 안됨)
- all together, contrastive span pretraining outperforms mask LM, with improved performance when audio is used both as input and target.
4.1.2 VCR Results
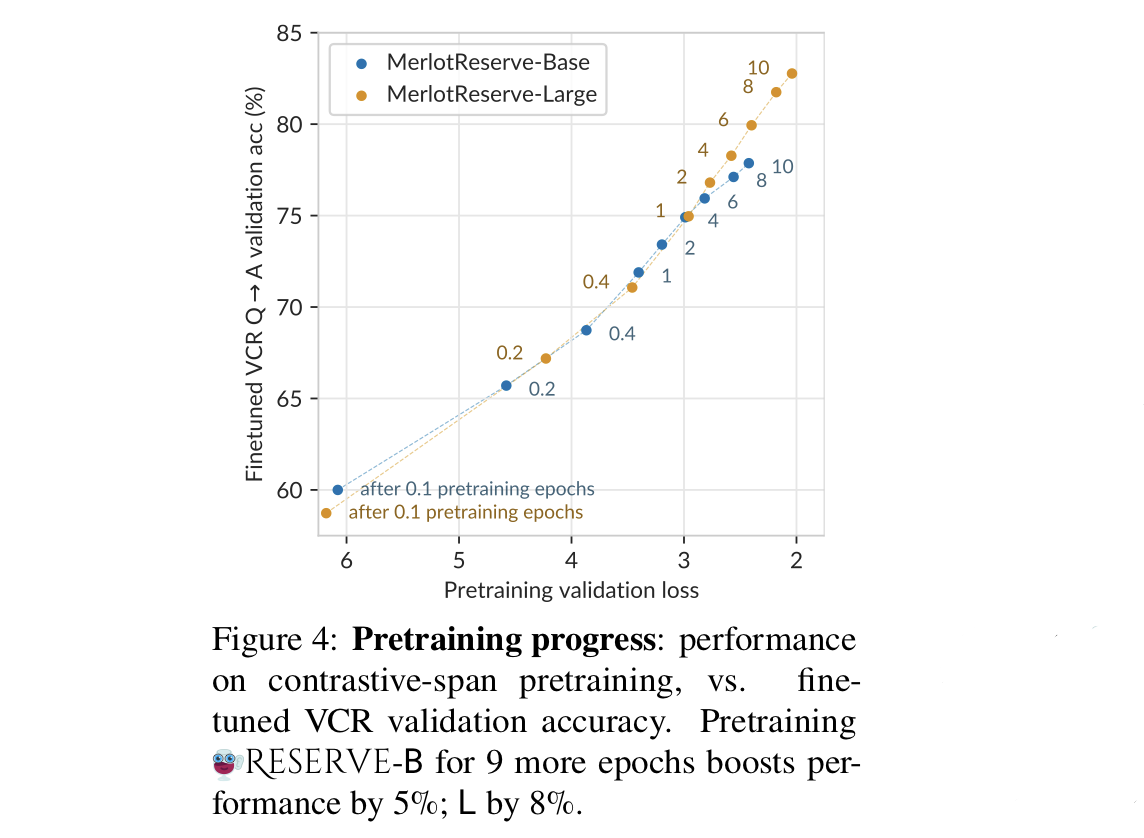
- above figure demonstrates that fine-tuned VCR performance tracks with the number of pretraining epochs, and validation loss.
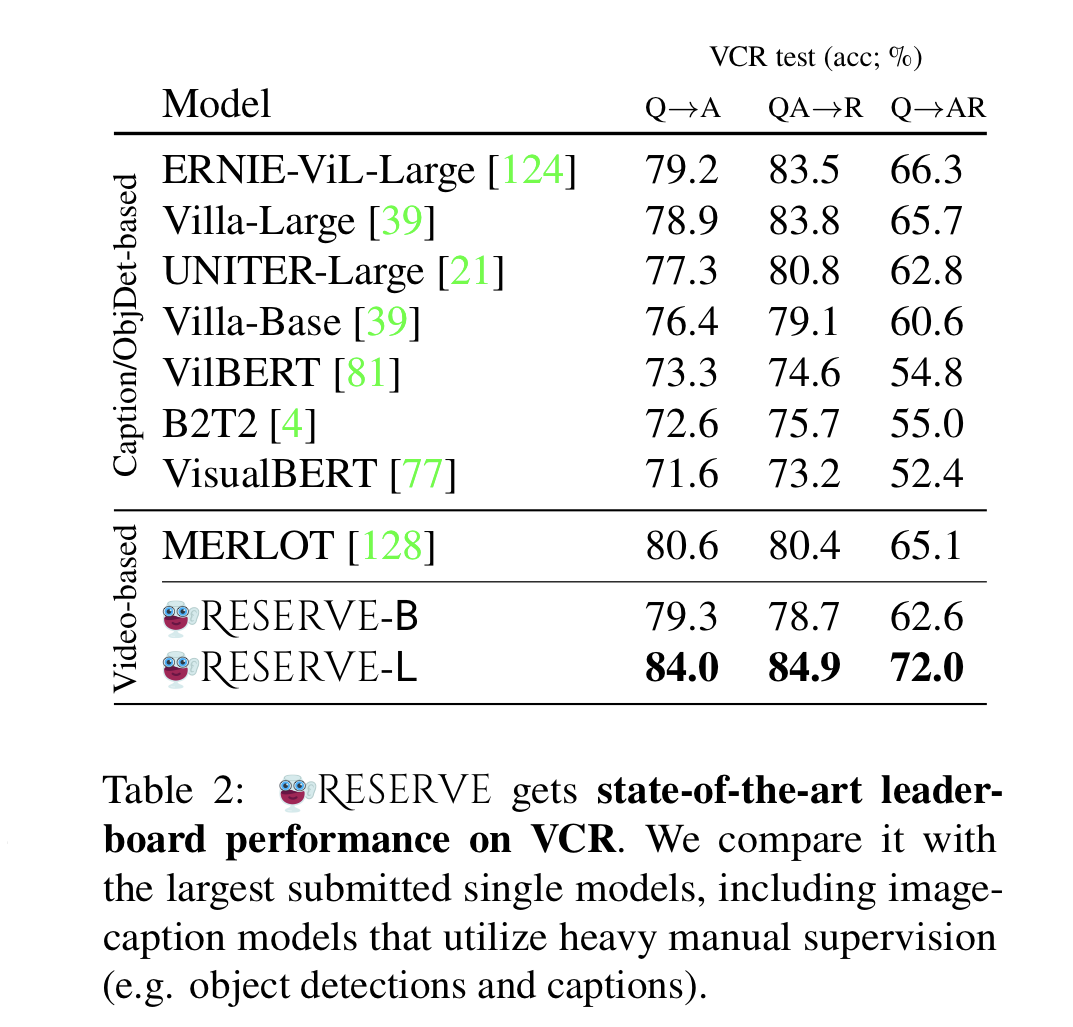
- comparisons of RESERVE against the largest published models from the VCR leaderboard.
- RESERVE-L outperforms all prior work, by over 5% on Q->AR Metric.
Efficiency
- RESERVE-L requires one-fifth the FLOPs of detector-based systems(e.g. UNITER-L).
- RESERVE-L uses a pure ViT backbone, which uses fewer FLOPs than MERLOT.
4.2 Finetuning on TVQA
- TVQA evaluates RESERVE's capacity to transfer to multimodal video understanding tasks.
- models are given a video, a question, and five answer choices.
Results
- RESERVE-L improves over prior work by 7.6%.
4.3 Finetuning on Kinetics-600 Activity Recognition
- uses Kinetics-600 to compare RESERVE's activity understanding versus prior work(includes models that do not integrate audio).
- has to classify a 10-second video clip as one of 600 categories.
- RESERVE finetuned 1) vision only, 2) vision+audio
Results
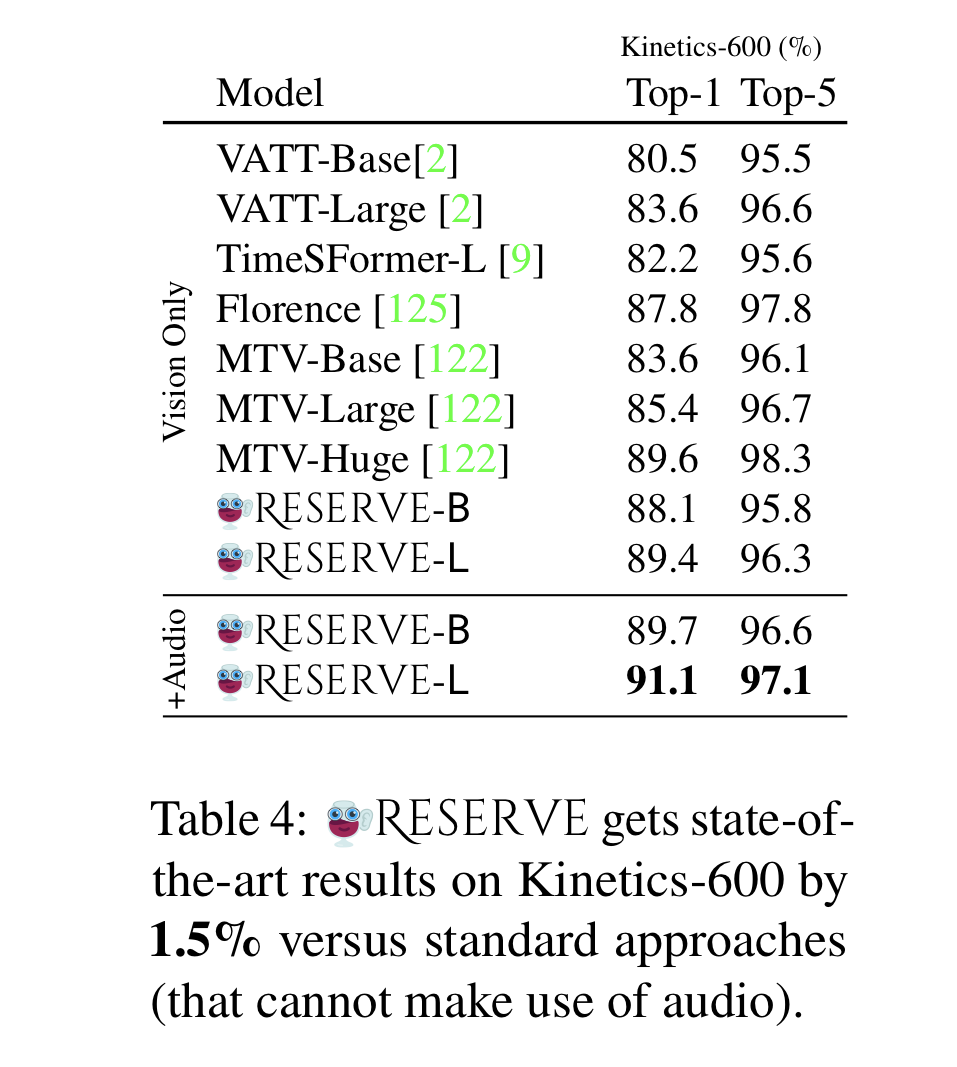
- represents audio independently from vision, along with the larger MTV-Huge model by 1.5%.
4.4 Zero-Shot Experiments
- zero-shot interface is enabled by contrastive span objective.
- QA tasks that require predicting an option from a label space of short phrases, the label space is encoded as vectors, and closes phrase is predicted to a MASKed input.
- considerations:
- i. Situated Reasoning(STAR)
- model has to reason over short situations in videos(covering interaction, sequence, prediction, and feasibility).
- given a video, a templated question, and 4 answer choices.
- templated questions are converted into literal statements
- label space is the set of four options.
- ii. Action Anticipation in Epic Kitchens
- model has to predict future actions given a video clip, which requires reasoning temporally over an actor's motivations and intentions.
- dataset contains rare action combinations to make zero-shot inference challenging.
- given a single MASK token as text input, and use the label space of all combinations of verbs and nouns in the vocabulary(e.g. 'cook avocado').
- iii. LSMDC
- given a video clip, along with a video description(with a MASK to be filled in).
- iv. MSR-VTT QA
- open-ended video QA task about what is literally happening in a web video.
- uses GPT3 to reword the questions into statements with MASKs.
- uses a label space of the top 1k options.
- For above tasks, N=8 video segments are used, and provides audio input when possible.
- i. Situated Reasoning(STAR)
Results
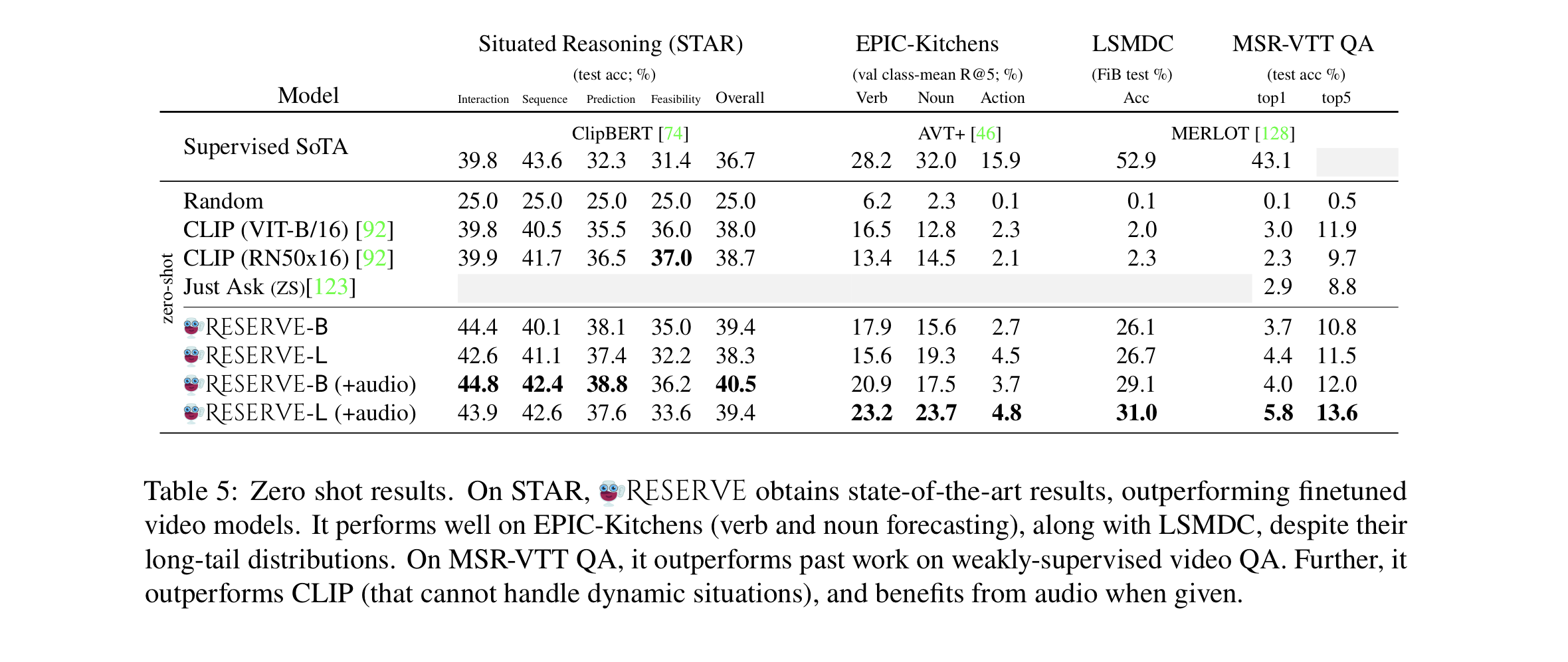
- i. On STAR
- RESERVE obtains state-of-the-art results, with performance gain when audio is included.
- RESERVE-B outperforms RESERVE-L: might be because of limited prompt searching around question templates(RESERVE-L sometimes excludes topically correct option when sounds grammatically stange).
- ii. On EPIC-Kitchens
- RESERVE obtains strong results at correctly anticipating the verb and noun.
- iii. On LSMDC
- RESERVE obtains strong results at filling-in-the-blank, despite a heavy(unseen) frequency bias.
- significantly outperforms CLIP
- iv. MSR-VTT QA
- RESERVE performs well, outperforming past work.
5. Qualitative Analysis: Why does audio help?

- In Figure 5, the model is given the displayed text and video frames, and must match the MASK to the correct missing text and audio span.
Audio's supervisory signal
In the first two rows of Figure 5, audio provides orthogonal(독립적인, 특성이 전혀 달라 서로 전혀 커버쳐주지 못하는) supervision to text:
- 1. In the first row, the MASKed audio contains the sound of popcorn pops slowing. The sound provides signal for joint vision-text understanding of the situation, as evidenced by its greater match probability.
- 2. In the second row, only the text 'why' is contained with audio providing greatly more informations.
- 3. In the third row, matching performance is similar between modalities.
Role of text
Text is still a crucial complement to audio, in terms of the supervision it provides.
Consider second row:
- RESERVE learns to match audio almost perfectly, and in later epochs its text-match probability increases. (오히려 audio is complement to text라고 생각했는데, 뭐지..?)
Learning through multimodal reentry
human children learn by reentry : learning connections between all senses as they interact with the world.
- using a held-out(계속해서 존재하는) modality(like audio) might support learning a better worl representation(e.g. vision and text), by forcing models to abstract away from raw perceptual input(raw perceptual input을 사용하지 못하게 하는 것).
