오늘은 Object Detection과 Segmentation에서 사용되는 데이터셋들과 해당 분야에서의 OpenCV에 대해서 정리해보고자 한다.
주요 데이터셋 간략소개
여러 Object Detection과 Segmentation 딥러닝 패키지가 아래 3개의 데이터셋들을 기반으로 pretrained되어 배포되어져 있다.
1) Pascal VOC
Pascal VOC는 XML Format으로 annotation이 저장되어져 있으며, 20개의 object 카테고리로 이루어져 있다.
2) MS COCO
MS COCO는 json Format으로 annotation이 저장되어져 있으며, 80개의 object 카테고리로 이루어져 있다.
3) Google Open Images
Google Open Images는 csv Format으로 annotation이 저장되어져 있으며, 600개의 object 카테고리로 이루어져 있다.
Annotation이란?
이미지의 detection 파일을 별도의 설명 파일로 제공하는 것.
Annotation은 object의 bounding box의 위치나 object의 이름 등을 특정 format으로 제공한다.
만약 원본 이미지에 bounding box를 시각화한다면, 너무 많은 노력이 들어간다. 그래서 image와 annotation을 함께 사용한다.
Pascal VOC
Pascal VOC 데이터셋 구조(VOC 2012)
VOCdevkit
|
VOC 2012
|
Annotations - ImageSet - JPEGImages - SegmentationClass - SegmentationObject
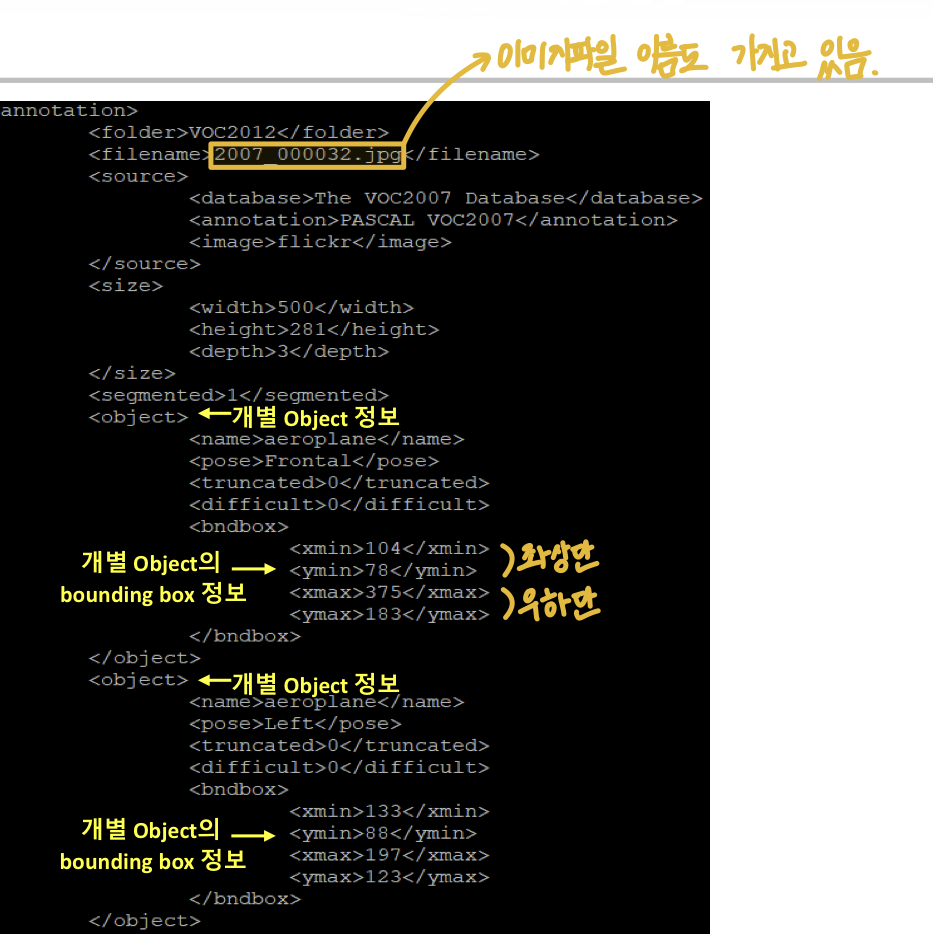
Annotations : XML Format. 하나의 XML 파일 당 한 개 이미지에 대한 annotation 정보를 가지고 있음. 파일명은 이미지 파일명과 동일하게 매핑되어져 있다.
ImageSet : 어떤 이미지를 train, test, trainval에 사용할 것인지에 대한 매핑 정보를 개별 object별로 파일로 가지고 있다. 파일 리스트가 저장되어져 있다.
JPEGImages : Object Detection과 Segmentation에 사용될 원본 이미지가 jpg Format으로 저장되어져 있다.
SegmentationClass : Semantic Segmentation에 사용될 masking image가 저장되어져 있다.
SegmentationObject : Instance Segmentation에 사용될 masking image가 저장되어져 있다.
Annotation XML 파일에 있는 요소들을 파싱하여 접근
Element Tree를 이용하여 XML을 파싱한다.
import os
import random
VOC_ROOT_DIR = '/content/data/VOCdevkit/VOC2012/"
ANNO_DIR = os.path.join(VOC_ROOT_DIR, "Annotations")
IMAGE_DIR = os.path.join(VOC_ROOT_DIR, "JPEGImages")
xml_files = os.listdir(ANNO_DIR) #XML file list 가져오기import os
import xml.etree.ElementTree as ET
#xml파일 하나 불러오기
xml_file = os.path.join(ANNO_DIR, '2007_000032.xml')
#XML 파일을 parsing하여 Element 생성
tree = ET.parse(xml_file) #tree가 만들어짐
root = tree.getroot() #root node를 찾는다
#image 관련 정보는 root의 자식으로 존재
image_name = root.find('filename').text #filename이라는 node를 찾고, 그 node의 text 구하기.
full_image_name = os.path.join(IMAGE_DIR, image_name)
image_size = root.find('size')
image_width = int(image_size.find('width').text)
image_height = int(image_size.find('height').text)
#파일내에 있는 모든 object Element를 찾음.
objects_list = []
for obj in root.findall('object'):
#object element의 자식 element에서 bndbox를 찾음.
xmlbox = obj.find('bndbox')
#bndbox element의 자식 element에서 xmin, ymin, xmax, ymax를 찾고, 이의 값(test)를 추출
x1 = int(xmlbox.find('xmin').text)
y1 = int(xmlbox.find('ymin').text)
x2 = int(xmlbox.find('xmax').text)
y2 = int(xmlbox.find('ymax').text)
bndbox_pos = (x1, y1, x2, y2)
class_name = obj.find('name').text
object_dict = {'class_name': class_name, 'bndbox_pos': bndbox_pos}
objects_list.append(object_dict)
Annotation내의 oject들의 bounding box 정보를 이용해 bounding box 시각화
import cv2
import os
import xml.etree.ElementTree as ET
xml_file = os.path.join(ANNO_DIR, '2007_000032.xml')
tree = ET.parse(xml_file)
root = tree.getroot()
image_name = root.find('filename').text
full_image_name = os.path.join(IMAGE_DIR, image_name)
img = cv2.imread(full_image_name)
#opencv의 rectangle()는 인자로 들어온 이미지 배열에 그대로 사각형을 그려주므로 별도의 이미지 배열에 그림 작업 수행.
draw_img = img.copy()
#opencv는 RGB가 아니라 BGR이므로 빨간색은 (0, 0, 255)
green_color = (0, 255, 0)
red_color = (0, 0, 255)
#파일내에 있는 모든 object Element를 찾음.
objects_list = []
for obj in root.findall('object'):
xmlbox = obj.find('bndbox')
left = int(xmlbox.find('xmin').text
top = int(xmlbox.find('ymin').text
right = int(xmlbox.find('xmax').text
bottom = int(xmlbox.find('ymax').text
class_name = obj.find('name').text
#draw_img 배열의 좌상단 우하단 좌표에 녹색 box로 표시
cv2.rectangle(draw_img, (left, top), (right, bottom), color = green_color, thickness = 1)
#draw_img 배열의 좌상단 좌표에 빨간색으로 class 표시
cv2.putText(draw_img, class_name, (left, top - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, thickness = 1)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 10))
plt.imshow(img_rgb)MS COCO Dataset
-
Object Detection에서 굉장히 일반화된 Dataset
-
80개의 Object Category
-
300k Image들과 1.5 Million개의 object들, 하나의 image에 평균 5개의 object들로 구성
-
Tensorflow object detection API 및 많은 오픈 소스 계열의 주요 패키지들은 COCO Dataset으로 Pretrained된 모델을 제공함
-
COCO Datasetdms 이미지 한 개에 여러 오브젝트들을 가지고 있으며, 타 데이터 세트에 비해 난이도가 높은 데이터를 제공한다.
MS COCO Dataset 구성
이미지 파일들
-
학습용 파일, 검증용 파일, 테스트용 파일이 따로 존재.
-
이미지들은 모두 jpg format.
JSON Annotation 파일
-
JSON Format인 한 개의 파일로 구성됨
-
JSON 파일은 아래와 같은 대분류로 구성됨
info : COCO Dataset 생성 일자 등을 가지는 헤더 정보
license : 이미지 파일들의 라이선스에 대한 정보
images : 모든 이미지들의 id, 파일명, 이미지 너비와 높이 정보
annotations : 대상 image 밒 object id. Segmentation, bounding box, 픽셀 영역 등의 상세 정보.
categories : 80개 오브젝트 카테고리에 대한 id, 이름, group등을 가짐.

OpenCV 개요
Python 기반 주요 이미지 라이브러리
PIL (Python Image Library)
- 주로 이미지 처리만을 위해 사용
- 처리 성능이 상대적으로 느림
Scikit Image
- 파이썬 기반의 전반적인 컴퓨터 비전 기능 제공
- Scipy 기반
OpenCV

- 오픈소스 기반의 최고 인기 컴퓨터 비전 라이브러리
- 컴퓨터 비전 기능 일반화에 크게 기여(어려운 기능도 API 몇 줄로 간단하게 구현)
- c++ 기반이나 python도 지원(java, c# 등 다양한 언어 지원)
- 인텔이 초기 개발 주도
- Windows, 리눅스, Mac OS X, 안드로이드, IOS 등 다양한 플랫폼에서 사용 가능
- 방대한 컴퓨터 비전 관련 라이브러리와 손쉬운 인터페이스 제공
OpenCV 이미지 로딩
imread()를 이용한 이미지 로딩
OpenCV에서 이미지를 로딩할 때 imread 함수를 사용한다. imread 함수는 파일을 읽어 Numpy Array로 변환한다.
OpenCV에서 imread를 이용할 때 주의할 점은 이미지를 RGB 형태가 아닌 GBR 형태로 읽는다는 것이다.
import cv2
import matplotlib.pyplot as plt
img_array = cv2.imread('파일명')
plt.imshow(img_array)
cvtColor()를 이용하여 BGR을 RGB로 변환
OpenCV에서 imread함수를 이용하여 로딩된 이미지 배열은 BGR 배열이기 때문에 cvtColor 함수를 이용하여 RGB로 변환해주어야 한다.
import cv2
import matplotlib.pyplot as plt
img_array = cv2.imread('파일명')
rgb_img_array = cv2.cvtColor(img_array, cv2.COLOR_BGR2RGB)
plt.imshow(rgb_img_array)
imwrite()를 이용하여 파일에 쓰기
OpenCV에서 메모리에 있는 이미지 배열을 파일에 저장하려면 imwrite 함수를 이용한다. imwrite함수는 이미지 배열을 RGB 형태로 저장한다.
import cv2
import matplotlib.pyplot as plt
img_array = cv2.imread('파일명')
cv2.imwrite('출력파일명', img_array)
OpenCV 영상처리
- OpenCV는 간편하게 비디오 영상처리를 할 수 있는 API를 제공한다.
- VideoCapture 객체는 video streaming을 frame별로 capture하여 처리할 수 있는 기능을 제공한다.
- videowriter 객체는 videocapture로 읽어들인 frame을 동영상으로 write하는 기능을 제공한다.
OpenCV 영상 처리 개요
OpenCV의 VideoCapture 클래스는 동영상을 개별 Frame으로 하나씩 읽어들이는 기능을 제공한다.
VideoWriter은 Videocapture으로 읽어들인 개별 Frame을 동영상 파일로 Write를 수행한다.
VideoCapture 개요
- VideoCapture 객체는 생성 인자로 입력 video파일 위치를 받아 생성
cap = cv2.VideoCapture(video_input_path)- VideoCapture 객체는 입력 video 파일의 다양한 속성을 가져올 수 있음
#영상 frame 너비
cap.get(cv2.CAP_PROP_FRAME_WIDTH)
#영상 frame 높이
cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
#영상 FPS
cap.get(cv2.CAP_PROP_FPS)- VideoCapture 객체의 read()는 마지막 Frame까지 차례로 Frame을 읽음
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
breakVideoWriter 개요
- VideoWriter 객체는 write할 동영상 파일 위치, Encoding 코덱 유형, write fps 수치, frame 크기를 생성자로 입력 받아 이들의 값에 따른 동영상을 write한다.
- VideoWriter은 write시 특정 포맷으로 동영상을 encoding할 수 있다.
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)import cv2
video_input_path = 불러올 영상 경로
video_output_path = 영상 저장 경로
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID') #codec은 *'XVID'로 설정
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
OpenCV 영상처리 실습코드
import time
green_color = (0, 255, 0)
red_color = (0, 0, 255)
start = time.time()
index = 0
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
index += 1
print('frame :', index, '처리 완료')
cv2.rectangle(img_frame, (사각형의 좌표), color = green_color, thickness = 2)
caption = 'frame:{}'.format(index)
cv2.putText(img_frame, caption, (글자 위치 좌표), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 1)
vid_writer.write(img_frame)
print('write 완료 시간:', round(time.time()-start, 4))
vid_writer.release()
cap.release()