Faster RCNN 개요
- 이전에는 Selective Search와 ROI를 사용했다면, Faster RCNN에서는 RPN이라는 딥러닝 network로 이를 구성한다.
- Object Detection을 구성하는 모든 요소들을 deep learning만으로 구성한 철 object detection 알고리즘이다.
Faster RCNN 구조
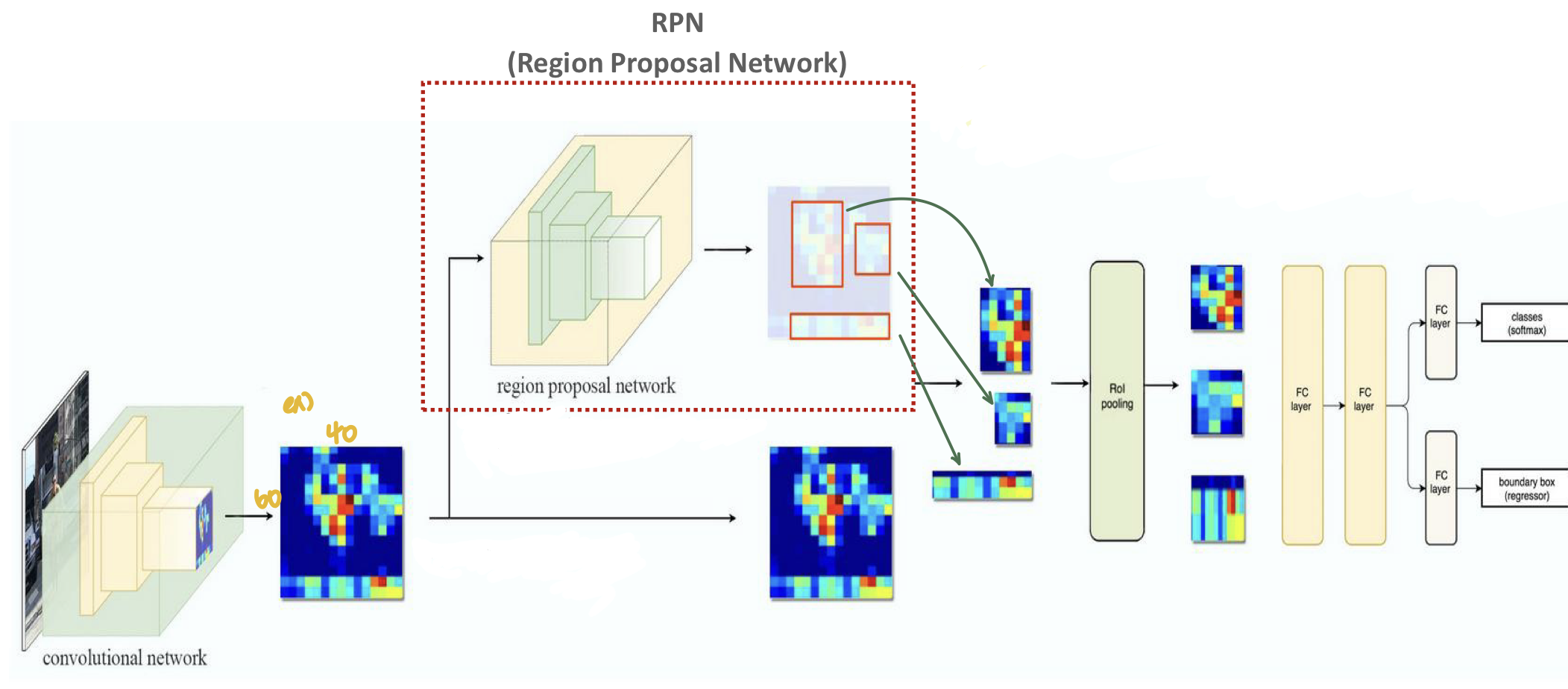
CNN을 통해 추출된 Feature Map은 RPN(Region Proposal Network)로 전달되고, RPN을 통해 해당 Feature Map의 Object가 있을만한 위치를 찾아낸다.
Selective Search를 Neural Network 구조로 변경하여 얻는 이점:
- GPU 사용으로 빠른 학습/Inference
- End to End Network 학습.
원래는 여러 단계를 걸쳐 학습을 진행했다. 그러나 이제 하나의 신경망 네트워크로 한번에 처리한다.
Region Proposal Network 구현 이슈
데이터로 주어지는 Feature은 pixel 값이며, target은 ground truth bounding box인데, 이를 이용해 어떻게 selective search 수준의 region proposal을 할 수 있을 것인가?
--> Anchor Box 사용. (Object가 있는지 없는지의 후보 box)
Selective Search는 Ojbject가 있을만한 위치들을 다 뽑아내준다.
Anchor Box를 사용하면 학습 중 도드라지는 anchor box를 가지고 Loss 기반으로 조금 더 학습을 시켜서 anchor box를 기반으로 위치를 찾아낸다.
Ground Truth기반으로 데이터를 넣어주면, 이것을 가지고 학습을 진행할 수 있다. 즉, RPM은 anchor box를 학습시킬 수 있는 network인 것이다.
Anchor Box 구성
총 9개의 Anchor Box, 3개의 서로 다른 크기, 3개의 서로 다른 ratio로 구성된다. anchor box의 중심을 기반으로 여러 형태와 scale의 anchor box를 촘촘하게 가지게 되면, 이것을 기반으로 학습을 하면서 selective search에서 했던 것과 유사한 방식으로 RPN 구성이 가능하다.
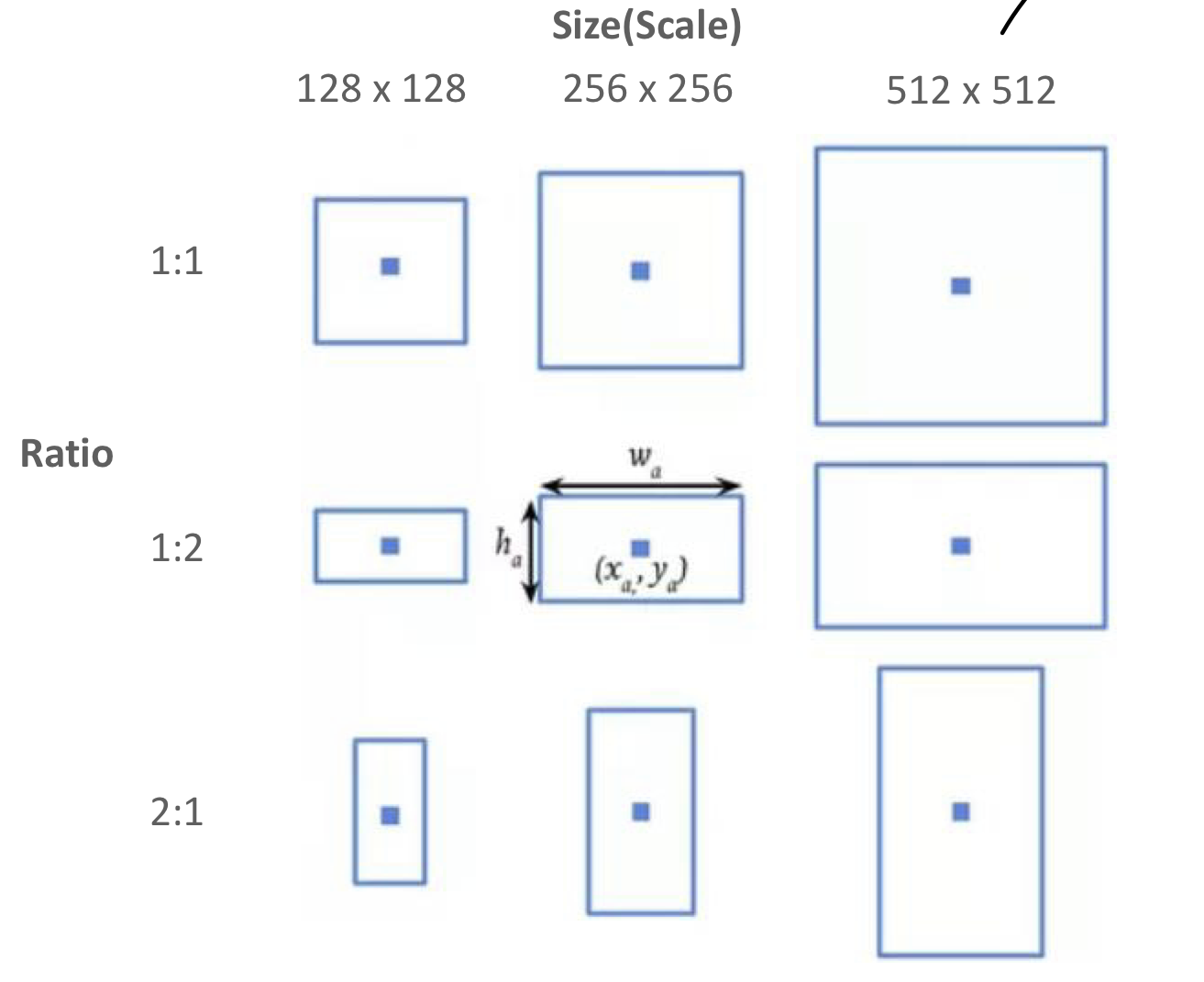
Ratio가 여러개인 이유

이미지 내에서 object가 어떤 형태로 위치해있을지 모르기 때문에.
이미지와 Feature Map에서 Anchor Box 매핑

원본 이미지가 16분의 1 크기의 feature map으로 downsampling되면 feature map height는 38이 되고, feature map width는 50이 된다.
모든 점에서 anchor box가 9개씩 그려진다. 그러면 anchor box끼리 겹쳐서 아래와 같이 된다.

RPN 네트워크 구성
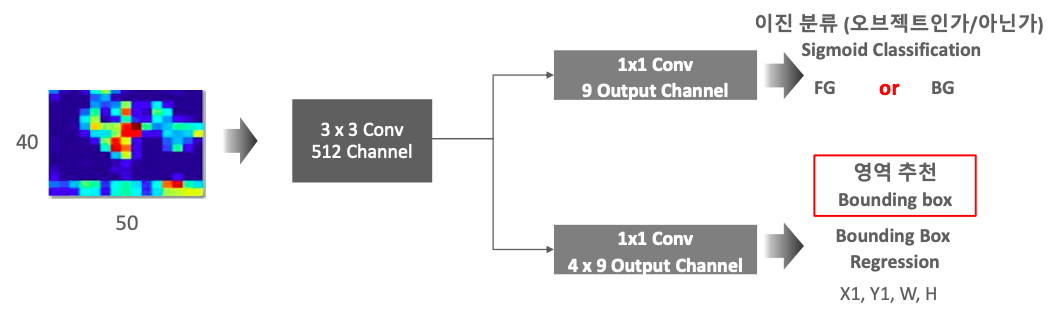
- 1x1 conv를 사용해서 feature 뽑아낸다.
feature map의 파라미터 수를 대폭 줄인다.
이진 분류
9개의 output Channel인 이유는 ancher이 9개이기 때문이다.
위의 이미지에서 40*50 이미지가 input되는데, 이의 경우 40 x 50 x 9 = 18000이다. 18000개의 anchor box를 개별적으로 FG, BG 판단해야한다.
FG란, Object로 판단한 것이고, BG는 배경으로 판단한 것이다.
Bounding Box Regression
40 x 50 x 9 x 4개의 정보를 가지게 된다. 4 x 9인 이유는 x1, y1, w, h(4개)와 anchor box가 9개이기 때문이다. Bounding Box regression을 통해 x1, y1, w, h를 얻을 수 있다.
RPN Loss 함수

RPN Bounding Box Regression

RPN Bounding Box Regression은 Anchor Box를 reference로 이용하여 ground truth와 예측 bounding box의 중심 좌표 x, y 그리고 w, h의 차이가 anchor box와 ground truth 간의 중심좌표 x, y, w, h의 차이와 최대한 동일하게 예측될 수 있어야 한다.
즉, anchor box와 ground truth간의 차이만큼, ground truth와 predicted 간의 차이를 최대한 동일하게 하는 것이 모델의 목표인 것이다.
차이가 동일해야하는 이유는, anchor box를 reference 삼아서 연산하기 때문이다. 즉, anchor box가 기준점이 된다. 차이가 동일해지면, Ground Truth Box와 predicted bounding box가 매우 유사해진다.
Positive Anchor Box, Negative Anchor Box
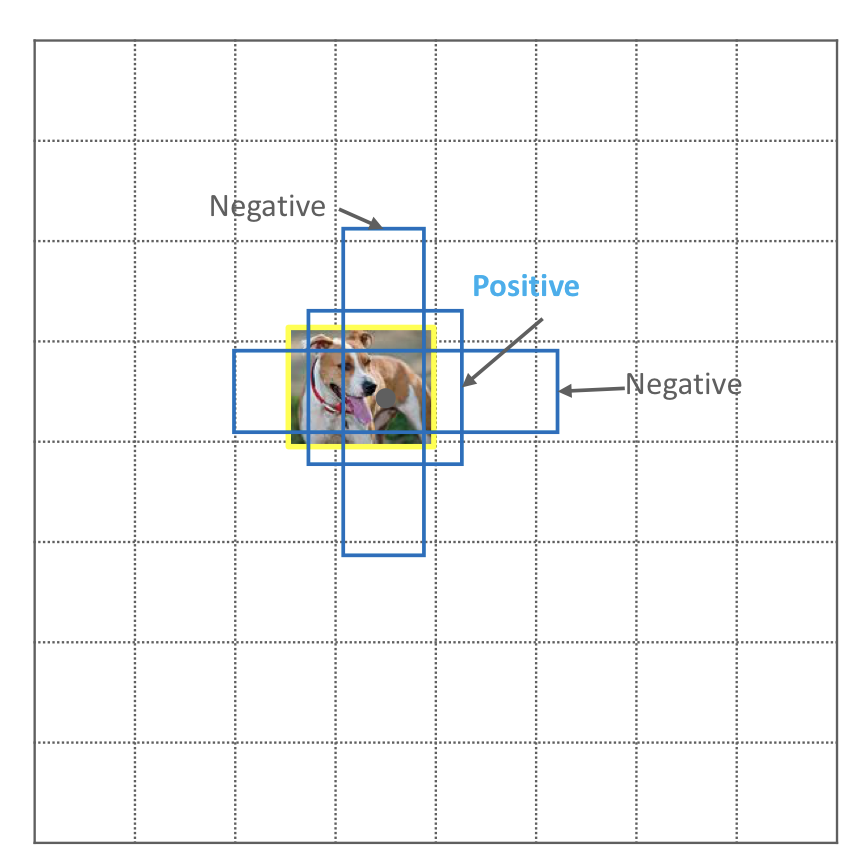
Ground Truth Bounding Box와 겹치는 IOU 값에 따라 anchor box를 Positive anchor box, Negative anchor box로 분류한다.
- IOU가 가장 높은 Anchor은 Positive
- IOU가 0.7 이상이면 Positive
- IOU가 0.3보다 낮으면 Negative
- IOU가 0.3과 0.7 사이인 경우, 애매하기 때문에 학습 데이터에서 아예 제외시킨다.
Faster RCNN Training

1) RPN을 먼저 학습한다.
2) Fast RCNN Classification과 Regression을 학습한다.
3) RPN을 Fine Tuning한다.
4) Fast RCNN을 Fine Tuning한다.
논문의 저자는 Faster R-CNN 모델을 학습시키기 위해 RPN과 Fast R-CNN을 번갈아가며 학습시키는 Alternating Training을 진행한다. 따라서 위의 단계들을 여러번 반복하며 학습을 진행한다.
