
CNN은 Convolutional Neural Network의 약자로, 필터링 기법을 인공 신경망에 적용하여 이미지를 분류하는 기법이다.
흑백 이미지는 2차원의 데이터로 되어있고, 0~255 사이의 값으로 되어있다.
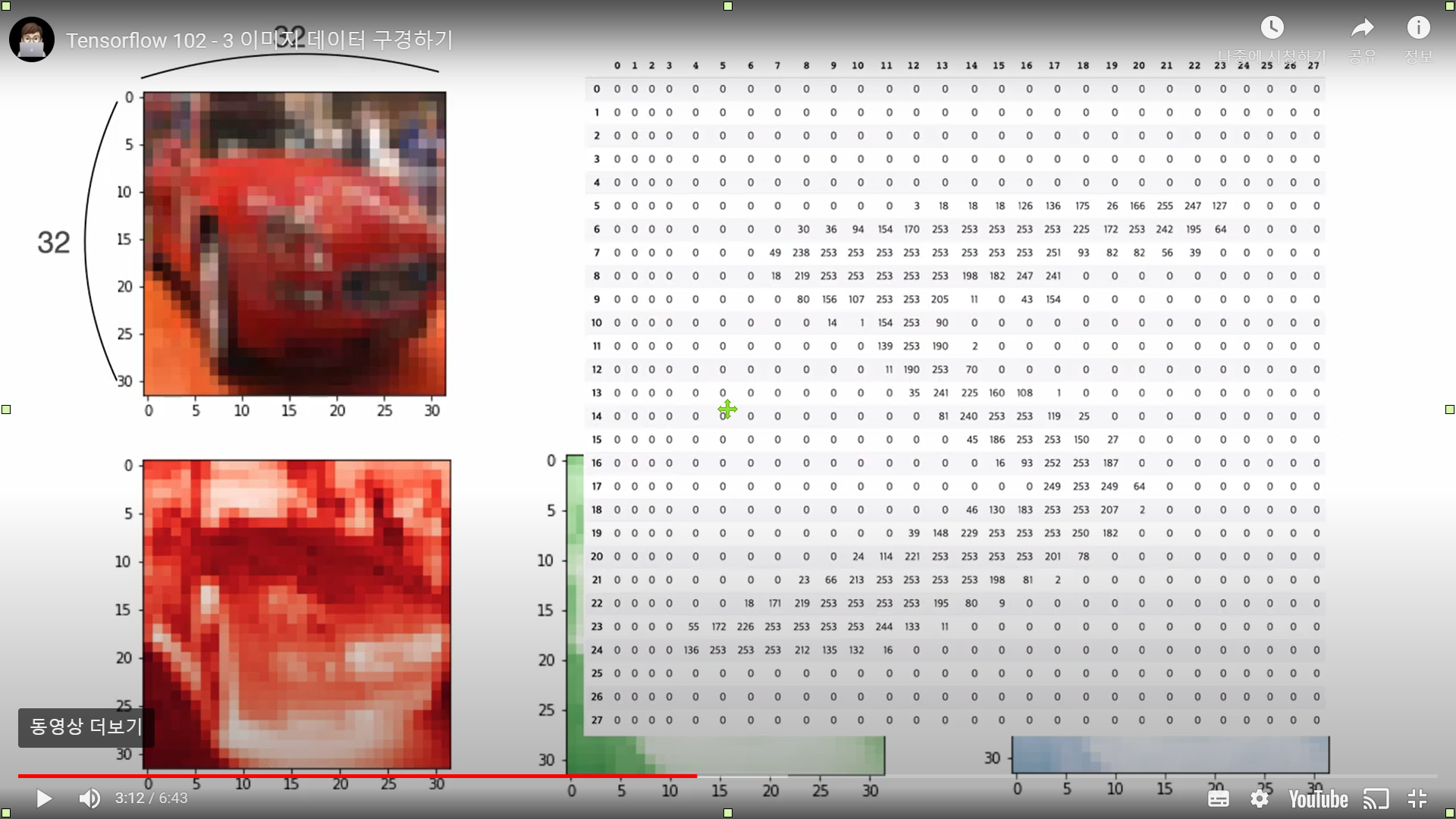
칼라 이미지는 (32, 32) 2차원 숫자 집합이 총 3개 존재한다. 각각 빨간색, 초록색, 파란색에 대한 숫자 집합이다.

MNIST이미지는 (28, 28) 이미지가 총 60000장 있고, CIFAR10 이미지는
(32, 32, 3)인 이미지가 총 50000장이 있다. 그리고 CIFAR10 이미지는 MNIST이미지와 달리 종속변수가 2차원으로 되어있다.
실습
라이브러리 import
import tensorflow as tf
(mnist_x, mnist_y), _ = tf.keras.datasets.mnist.load_data()
print(mnist_x.shape, mnist_y.shape)
(cifar_x, cifar_y), _ = tf.keras.datasets.cifar10.load_data()
print(cifar_x.shape, cifar_y.shape)
먼저, 라이브러리를 import 하고, mnist 이미지와 cifar10 이미지를 불러온다.
.shape를 통해 이미지의 구조를 파악한다.

화면 출력
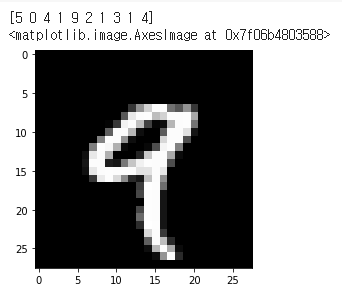
print(mnist_y[0:10])
import matplotlib.pyplot as plt
plt.imshow(mnist_x[4], cmap='gray')
mnist 이미지의 종속변수를 확인하고, matplotlib 라이브러리를 통해 mnist의 이미지가 어떻게 생겼는지 확인해본다.
print(cifar_y[0:10])
import matplotlib.pyplot as plt
plt.imshow(cifar_x[0])마찬가지로 cifar10 이미지도 확인해본다.
차원 확인

print(mnist_y.shape)
print(cifar_y.shape)
mnist 이미지는 (60000, ), cifar10 이미지는 (50000, 1)의 구조로 되어있다.
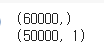
x1 = np.array([1, 2, 3, 4, 5])
print(x1.shape)
print(mnist_y[0:5])
print(mnist_y[0:5].shape)
x2 = np.array([[1, 2, 3, 4, 5]])
print(x2.shape)
x3 = np.array([[1], [2], [3], [4], [5]])
print(x3.shape)
print(cifar_y[0:5])
print(cifar_y[0:5].shape)
차원 개념에 대한 공부를 좀 더 해보면, mnist의 독립변수 5개를 보면 1차원 데이터 5개가 있는 걸 알 수 있다. x2 처럼 괄호 안에 괄호가 있는 형태이면 2차원 데이터로, 큰 덩어리가 하나 있고 그 안에 5개의 요소가 있는 것을 알 수 있다. x3은 (5, 1) 인것을 알 수 있다.

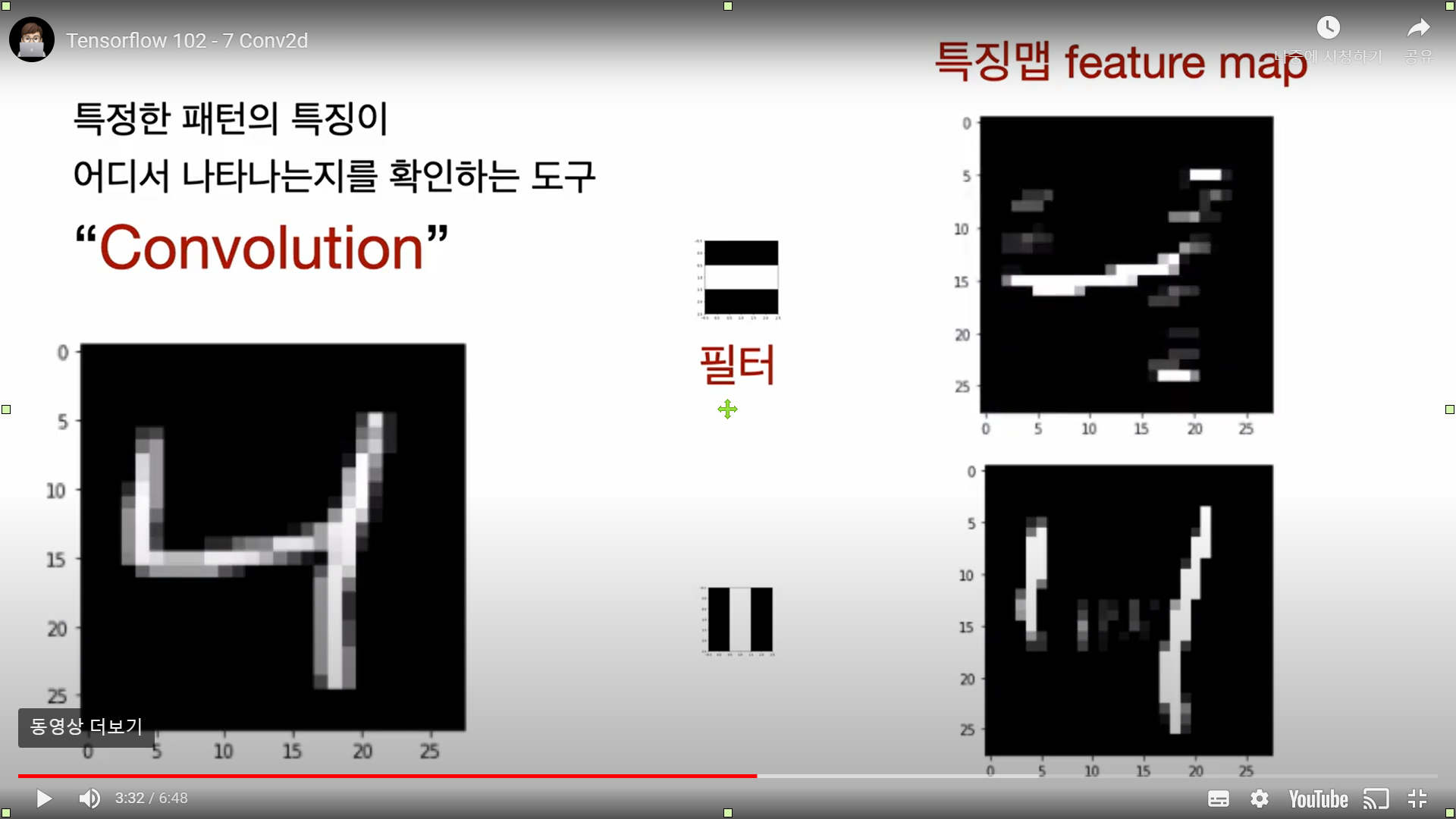
CNN의 주요한 성질 중 하나는 특징표현 학습이다. 특징 추출 기법인 컨볼루션(Convolution, 합성곱) 연산을 이용하여 이미지의 픽셀을 주변의 픽셀의 조합으로 대체하는 방식이다.
합성곱은 특정 크기를 가진 필터(Filter, Kernel)를 일정 간격(Stride)으로 이동하면서 입력 데이터에 연산을 적용한다. 어떠한 핉터를 사용하냐에 따라 찾을 수 있는 이미지의 특징이 달라진다. 필터 하나 당 하나의 특징맵이 형성된다. 컨볼루션 레이어에서는 생성된 특징맵을 스택처럼 쌓아둔다.

위의 코드에서 3, 6은 필터셋의 개수, kerner_size는 필터셋의 사이즈로 (5, 5) 사이즈의 필터셋을 사용한다는 의미이다.

만약 이미지가 흑백이미지라면 필터셋 하나의 shape는 (5, 5, 1)이 되고, 컬러 이미지라면 (5, 5, 3)이 된다.
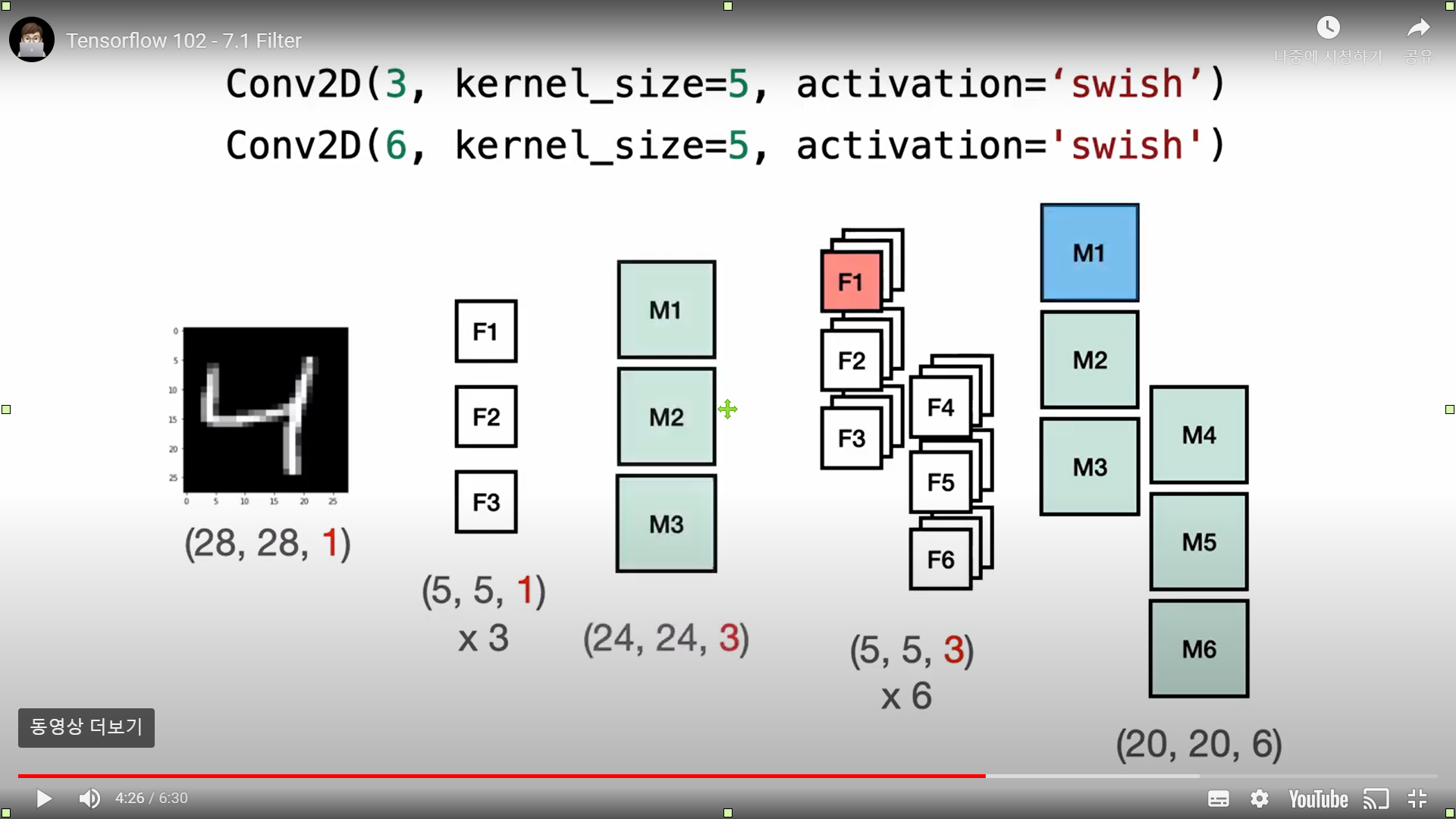
(28, 28, 1)의 이미지 한 장에서는 (5, 5, 1)의 필터셋 3장을 생성하고, 특징맵의 사이즈가 (5, 5)이므로 28에서 4(5-1)를 뺀 (24, 24)사이즈의 특징맵 3개가 생성된다.
실습
라이브러리 import
import tensorflow as tf
import pandas as pd데이터 준비
# 데이터를 준비하고
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
print(독립.shape, 종속.shape)
독립 = 독립.reshape(60000, 28, 28, 1) #3차원으로 reshape
종속 = pd.get_dummies(종속) # 원핫인코딩
print(독립.shape, 종속.shape)
Convolution Layer는 이미지 한장의 shape가 3차원이어야한다.

모델을 만든다.
# 모델을 만들고
X = tf.keras.layers.Input(shape=[28, 28, 1])
H = tf.keras.layers.Conv2D(3, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.Flatten()(H) # Flatten을 이용하여 1차원으로 변경
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')CNN에서 컨볼루션 레이어와 풀링 레이어를 반복적으로 거치면 주요 특징만 추출된다. 추출된 주요 특징은 2차원 데이터로 이루어져 있지만, Dense와 같이 분류를 위한 학습 레이어에서는 1차원 데이터로 바꾸어서 학습이 되어야 한다.
모델을 학습한다.
# 모델을 학습하고
model.fit(독립, 종속, epochs=100)
모델을 이용한다.
# 모델을 이용합니다.
pred = model.predict(독립[0:5])
pd.DataFrame(pred).round(2)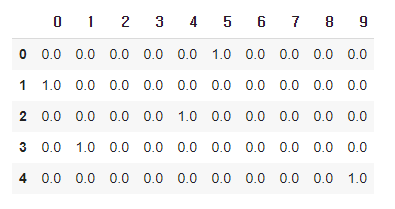
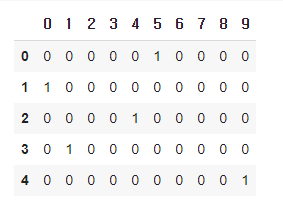
정답 확인
종속[0:5]
위의 예측값과 비교해보면 정확히 예측한 것을 볼 수 있다.
MaxPool2D
MaxPooling layer는 이미지 데이터셋에서 가장 특징이 큰 값만 남겨 과적합을 방지해준다.
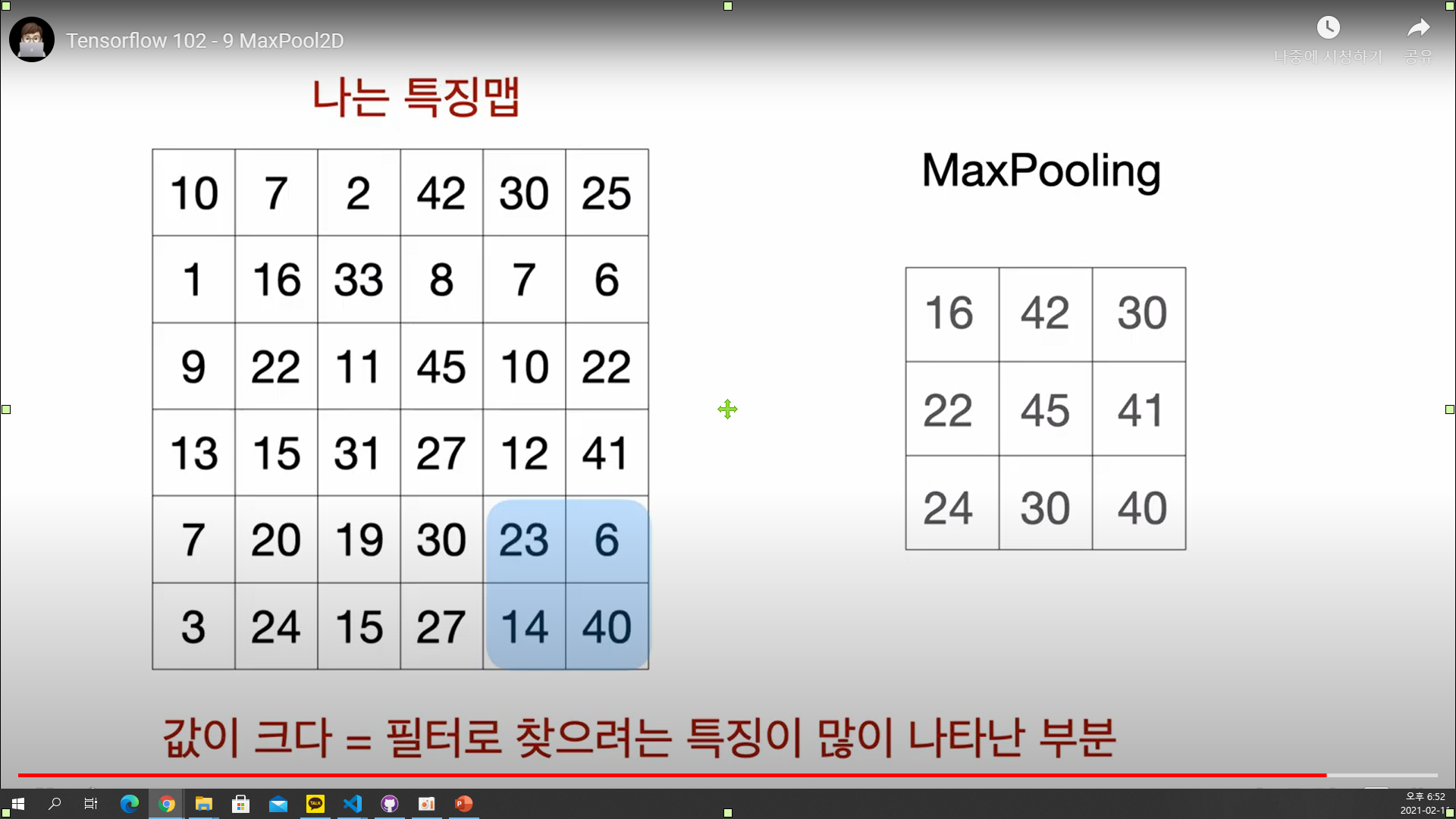
유의미한 결과를 남기면서 사이즈를 줄일 수 있는 것이다.
실습 코드
import tensorflow as tf
import pandas as pd
# 데이터를 준비하고
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
독립 = 독립.reshape(60000, 28, 28, 1)
종속 = pd.get_dummies(종속)
print(독립.shape, 종속.shape)
# 모델을 만들고
X = tf.keras.layers.Input(shape=[28, 28, 1])
H = tf.keras.layers.Conv2D(3, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
# 모델을 만들고, CNN
X = tf.keras.layers.Input(shape=[28, 28, 1])
H = tf.keras.layers.Conv2D(3, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
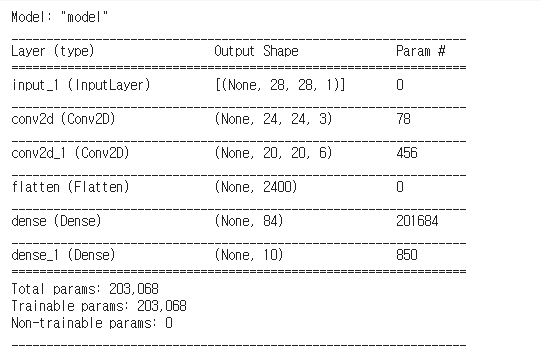
model.summary()
model.fit(독립, 종속, epochs=10)
MaxPooling 을 하기전 가중치의 수와 Maxpooling 한 후 가중치의 수를 살펴보면 훨씬 줄어든 것을 볼 수 있다.

LeNet5
LeNet은 CNN을 처음으로 개발한 얀 르쿤(Yann Lecun) 연구팀이 1998년에 개발한 CNN 알고리즘의 이름이다. original 논문 제목은 "Gradient-based learning applied to document recognition"이다. 우선 LeNet-5의 구조를 살펴보자.
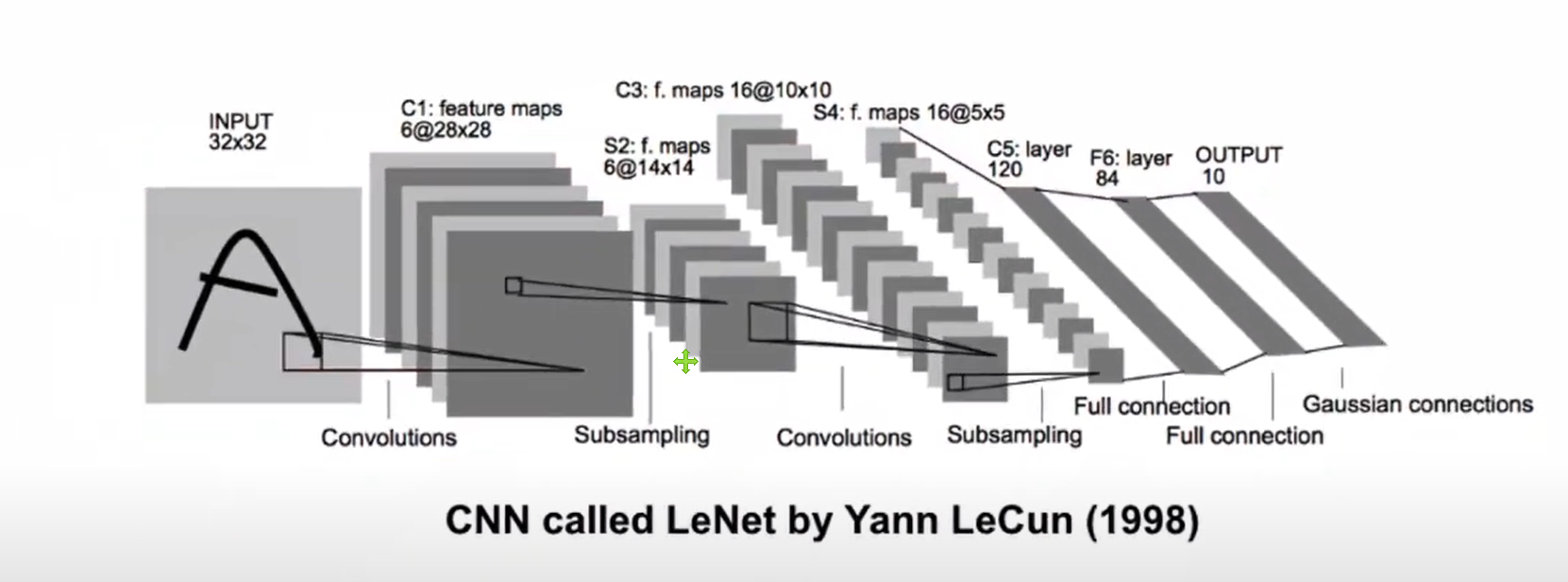
우선 입력으로 (32, 32) 이미지가 사용되었다. 첫번째 convolution layer는 6개의 특징맵을 만들었고 각 맵은 (28, 28)사이즈로 되어있다. 사이즈가 4 줄었으니 (5, 5)의 필터셋을 사용한 것을 알 수 있다.
S2에서는 Maxpooling을 한 것을 알 수 있다.
두번째 convolution layer에서는 16개의 특징맵을 만들었고, 이미지의 사이즈는 (10, 10)이다.
이 후 Maxpooling을 한번 더 하고 Flatten layer를 이용하여 16 5 5 = 400개의 변수로 펼친 후 120개의 노드와 84개의 노드를 가진 hidden layer를 추가한다. 그리고 마지막으로 10개의 출력이 만들어진 것을 알 수 있다.
실습 코드
import tensorflow as tf
import pandas as pd
# 데이터를 준비합니다.
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
독립 = 독립.reshape(60000, 28, 28, 1)
종속 = pd.get_dummies(종속)
print(독립.shape, 종속.shape)
# 모델을 완성합니다.
X = tf.keras.layers.Input(shape=[28, 28, 1])
#padding = 'same'은 특징맵의 사이즈를 입력 사이즈와 똑같게 출력하도록 해준다.
H = tf.keras.layers.Conv2D(6, kernel_size=5, padding='same', activation='swish')(X)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(16, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(120, activation='swish')(H)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
model.fit(독립, 종속, epochs=10)
model.summary()
# cifar 10
# 데이터를 준비합니다.
(독립, 종속), _ = tf.keras.datasets.cifar10.load_data()
print(독립.shape, 종속.shape)
종속 = pd.get_dummies(종속.reshape(50000))
print(독립.shape, 종속.shape)
# 모델을 완성합니다.
X = tf.keras.layers.Input(shape=[32, 32, 3])
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(16, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(120, activation='swish')(H)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
model.fit(독립, 종속, epochs=10)
#BatchNormalization 적용
# 모델을 완성합니다.
X = tf.keras.layers.Input(shape=[32, 32, 3])
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(16, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(120)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(84)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
model.fit(독립, 종속, epochs=50)
pred = model.predict(독립[0:5])
pd.DataFrame(pred).round(2)
plt.imshow(독립[1].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.show
종속[0:5]BatchNormalization Layer를 이용하여 모델의 정확도를 높일 수 있다. BatchNormalization을 Dense Layer와 activation layer 사이에 적어주면 효과가 좋다.
