실습 환경 구축
import pandas as pd
cols = ['Series_Title','Released_Year','Meta_score', 'IMDB_Rating','Overview']
movie_df = pd.read_csv('imdb_top_1000.csv',usecols=cols)
movie_df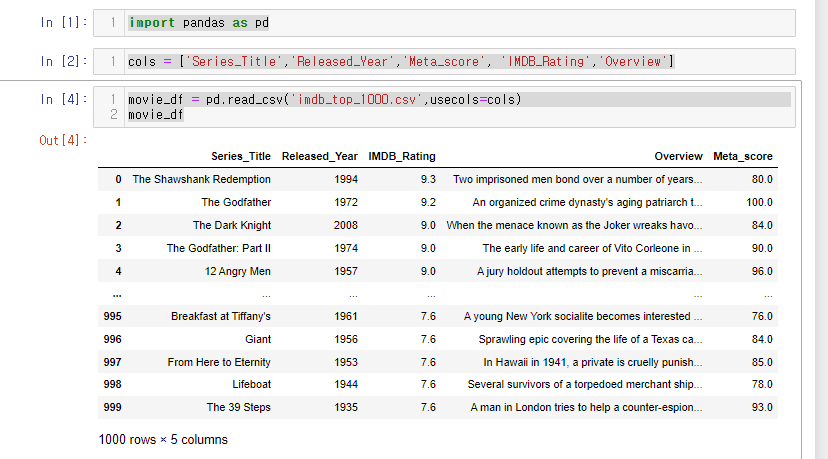
열 조회 방법
지금까지 컬럼 조회는 아래의 방법들로 구성했다.
- 단일열 (Series)
movie_df['Series_Title']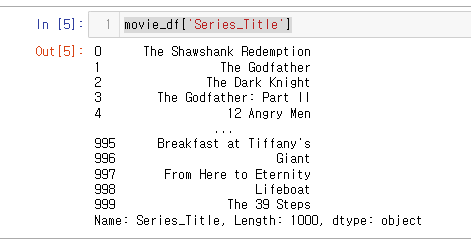
- 다중열(Df)
movie_df[['Series_Title','Released_Year']]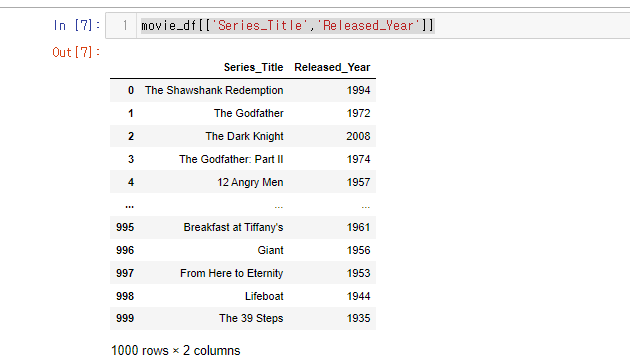
- 없는열을 조회하면 오류가 발생
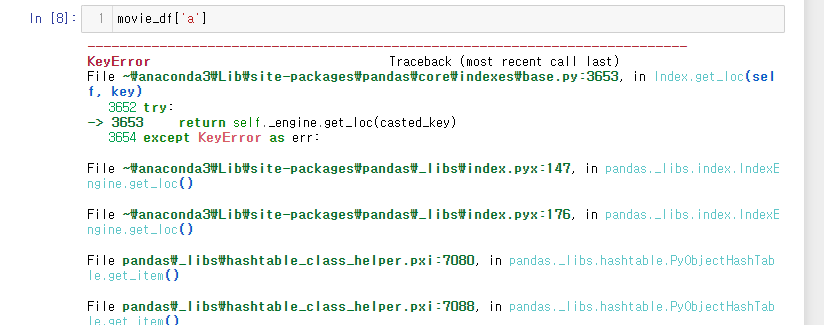
이때 get() 함수를 사용해서 조회하면 오류가 뜨지 않도록 할 수 있다.
사용방법은 조회하고자 하는 컬럼을 인자에 넣어주면 된다.
movie_df.get(['Series_Title','Released_Year'])이때 없는 컬럼을 넣어도 오류가 뜨지 않는다.
movie_df.get('aa')
열 추가 -
이번에는 열을 추가해 보자.
1. 일련화 된 값
- 내가 본 영화를 체크하는 란을 만들자.
- 리스트의 ,append() 처럼 위치는 지정할 수 없다.(맨 뒤에 붙음)
[추가 하려는 컬럼]을 대괄호에 넣어준 뒤, = 을 붙여 값을 넣어준다.
movie_df['Watched'] = False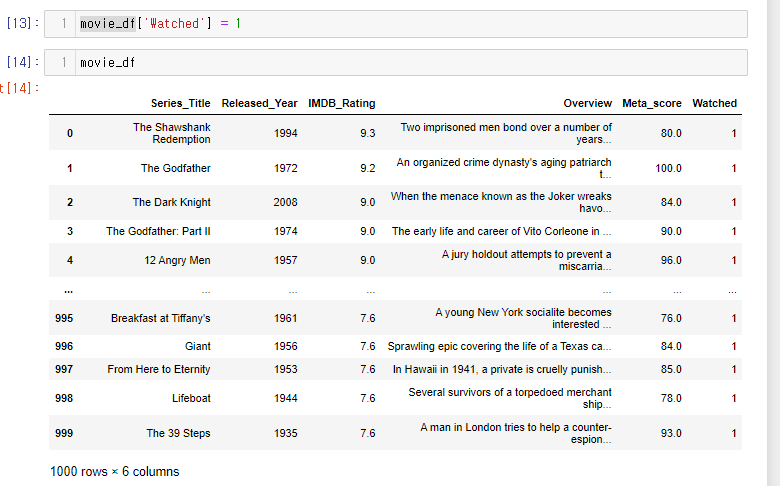
Watched 컬럼이 추가 되고
1이라고 넣어주면 값이 1로 넣어짐.
2. insert()를 이용한 일련화 된 값
위의 방법과는 다르게 컬럼 추가 위치를 지정할 수 있다.
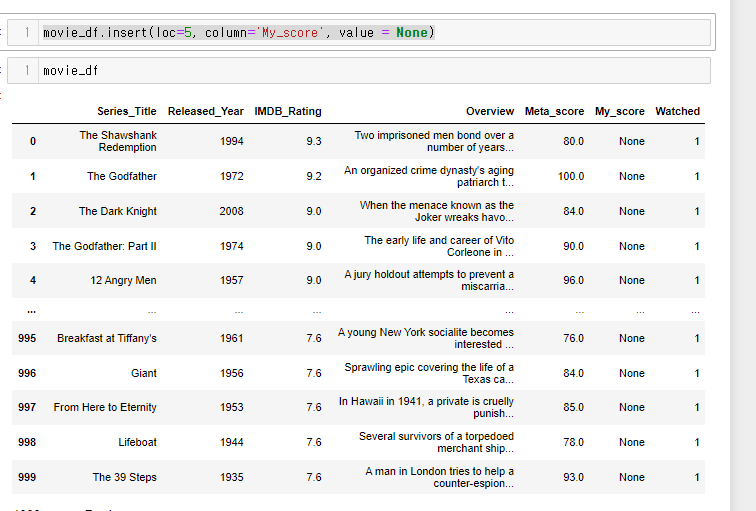
- 나의 점수 컬럼을 추가해보자.
movie_df.insert(loc=5, column='My_score', value = None)loc = : 위치를 지정 0부터 시작해서 5번째 위치
column = 컬럼명 지정
value = 초기 값 지정
allow_duplicates
insert()인자 중 allow_duplicates가 있다.
이는 중복되는 컬럼명은 받지 않는다는 의미로 기본값은 False 이다.
True로 지정한다면 중복되는 컬럼을 계속해서 생성할 수 있으니 주의하자.
3. 컬럼 추가 후 값 추가(Series 또는 배열 형태)
값을 Series 형태 또는 배열의 형태로 넣어줄 수 도 있다!
- array 형태
먼저 True와 False가 연속되는 값을 넣어보자
watched = [True, False] * 500
watched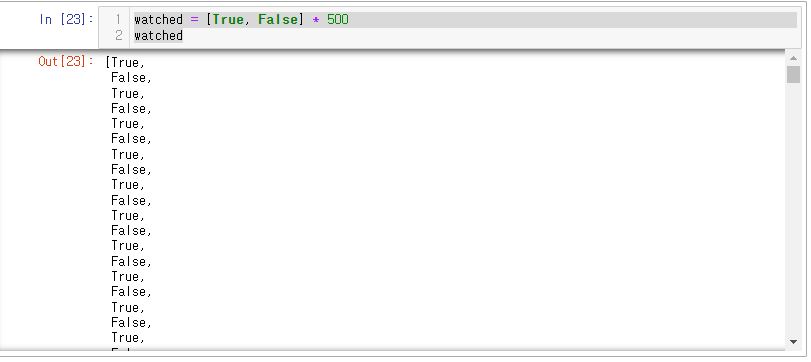
이 데이터를 컬럼 값으로 추가할 것 이다.
🚫주의사항🚫
컬럼에 넣을 값은 행 수와 동일해야 된다.
현재 movie_df 의 행 수는 1000개이기 때문에 데이터를 1000개 만든것이다.
이제 컬럼을 추가시 watched 데이터를 넣어주자.
movie_df['Watched'] = watched
movie_df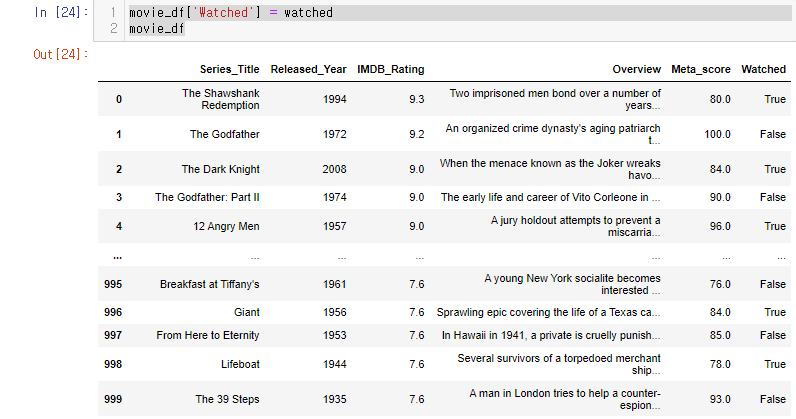
딕셔너리 방식과 비슷하다.
- Series 형태
1.먼저 랜덤하게 점수를 만드는 코드를 짜준다.
import random
my_score = [random.randint(0,10) for i in range(1000)]
my_score
2.이제 해당 데이터를 Series화 한다.
my_score_series = pd.Series(my_score)
3.해당 데이터를 insert() 를 이용해서 컬럼과 값을 추가해준다.
movie_df.insert(loc = 2, column = 'My_score', value=my_score_series)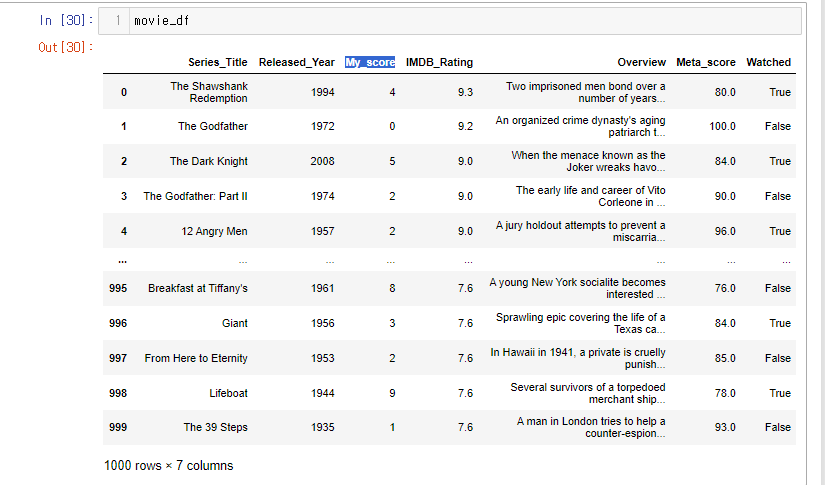
시리즈를 컬럼 값으로 추가할 때는 insert 메소드!
리스트를 컬럼 값으로 추가할 때는 딕셔너리와 비슷한 df.['컬럼'] = 컬럼값 형태!
컬럼 추가시 데이터 갯수가 다를때 오류
컬럼 추가시 데이터 갯수가 다르면 컬럼이 추가되지 않는다고 했다.
하지만 Series를 컬럼에 추가할 때는 오류가 발생하지 않고 인덱스 레이블을 매칭해 없는 데이터는 결측치로 처리하게 된다.
이 원리는 **Broadcasting** 이라고 하며 이후 글에서 설명해주겠다.
쉽게 말하자면 크기 또는 차원(시리즈, 데이터프레임)이 다른 데이터의 연산을 가능하게 하는 기본 탑재 능력이다.
999개만 있는 시리즈를 만들어보자
test = [0]*999
test_series = pd.Series(test)
test_seriesarray() 함수 이용
이후 array() 함수를 이용해 컬럼을 추가해주면
movie_df.insert(loc=1, column= "test",value=test_series)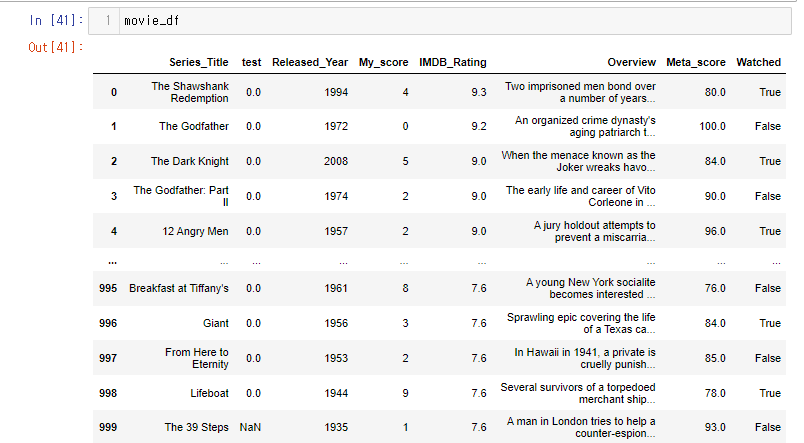
999 인덱스 레이블의 값은 없기 때문에 에러 대신 결측치 처리를 해준다.
컬럼을 대괄호로 추가하는 경우
movie_df['test_test'] = test_series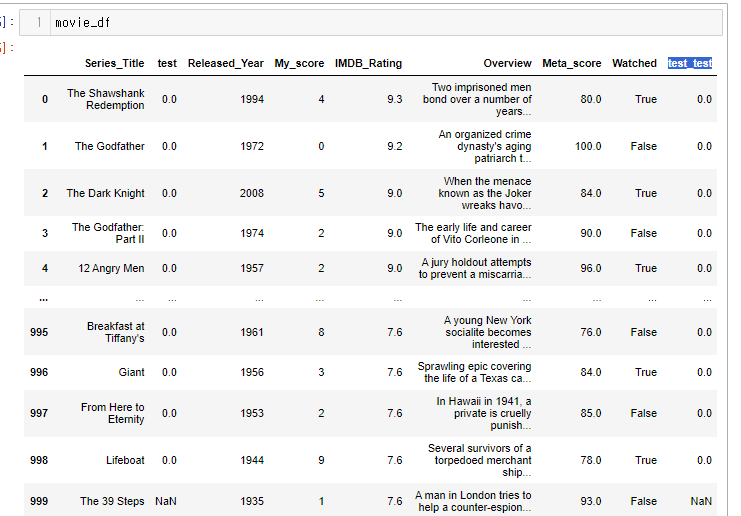
이미 시리즈로 만들어 뒀기 때문에 두 경우 다 잘들어가게 된다.
