**DataFrame기초 - 행렬삭제**
실습 환경 구축
이번 실습은 행렬 삭제이기 때문에 전체 데이터를 가져오겠다.
import pandas as pd
movie_df = pd.read_csv('imdb_top_1000.csv')
movie_df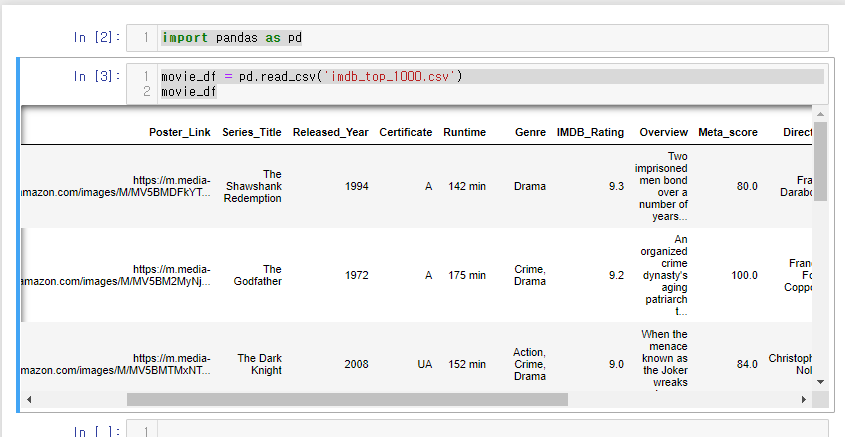
.drop() - 열 삭제(columns = )
불필요한 컬럼을 삭제해 보자.
movie_df.drop(columns=['Poster_Link','Overview'])요렇게 사용하면 'Poster_Link','Overview' 컬럼이 삭제된다.
단 .drop은 기본적으로 비파괴적이기 때문에 inplace = True 인자값으로 데이터를 저장할 수 있다.
movie_df.drop(columns=['Poster_Link','Overview'],inplace=True)
movie_df.drop() - 행 삭제 (인덱스 레이블)
특정 행을 삭제해 보자! 인덱스 레이블을 기준으로.
movie_df.drop(labels = 1, inplace=True)
movie_df사용 법은 drop 메소드에서 지우고싶은 lable을 labels= 인자값으로 반영해주면 된다.
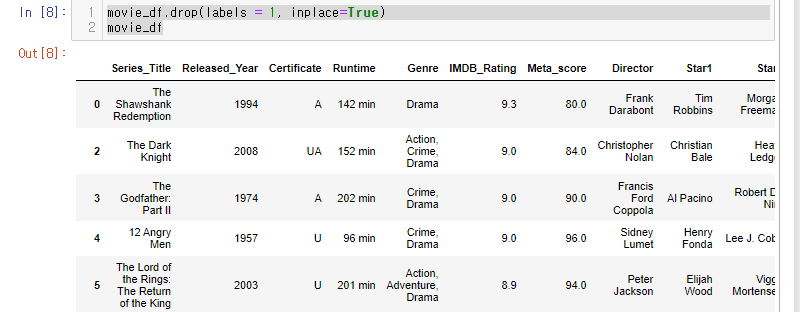
인덱스 레이블 1이 삭제 된 것을 확인 할 수 있다.
여러 인덱스 레이블 삭제시
여러개를 지우고자 할때는 리스트형태로 인자값에 넣어주면 된다.
movie_df.drop(labels = [5,7,9])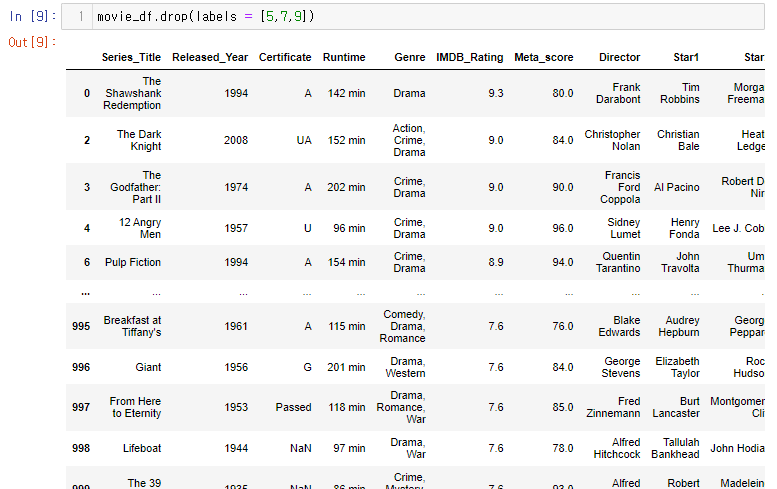
drop시 에러발생을 없애는 방법! errors=
이미 지운 데이터를 또 지우는 코드를 작성하면 에러가 발생한다.
movie_df.drop(columns=['Star1','Star2','Star3','Star4'],inplace = True)
movie_df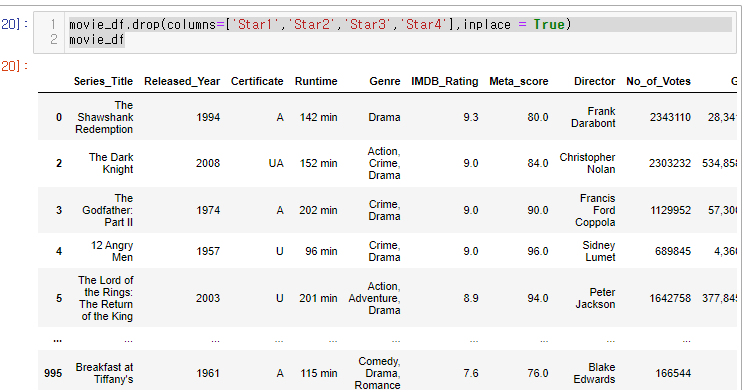
'Star1','Star2','Star3','Star4' 컬럼을 지우고 한번 더 코드를 실행하면!
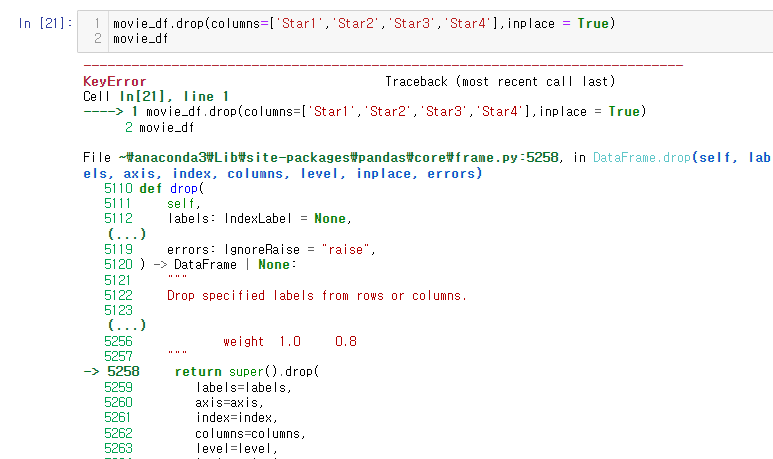
KeyError 가 발생한다.
만약 이미 지운 값이 있더라도 추가로 코드를 작성하면 에러가 안발생하게 해주는 인자가 있다.
바로 errors='ignore'(무시하다) 이다.
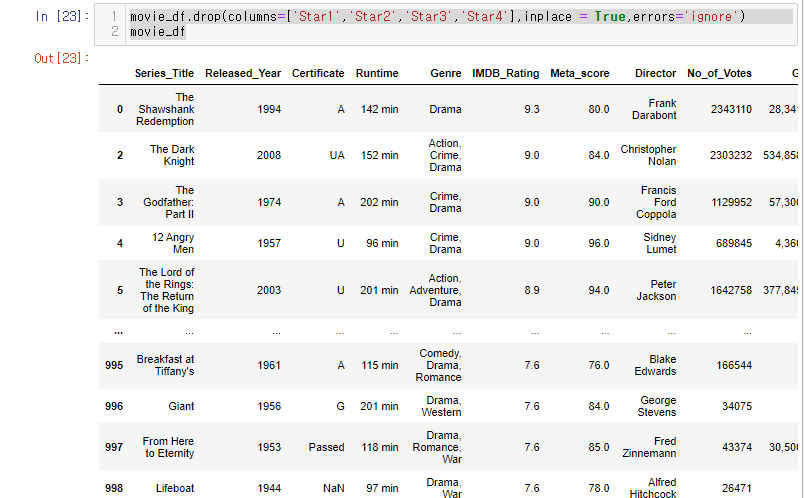
movie_df.drop(columns=['Star1','Star2','Star3','Star4'],inplace = True,errors='ignore')
movie_df이렇게 하면 해당 코드를 다시한번 실행해도 오류 없이 결과값이 나온다.
del을 이용한 열 삭제
del은 파괴적인 코드이다!
del movie_df['Runtime']
movie_df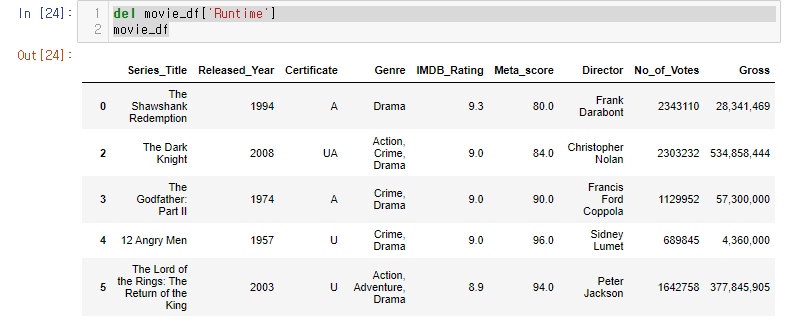
코드를 보면 알 수 있듯.
del은 리스트를 기준으로 삭제한다.
딕셔너리 전용 삭제 키워드가 아니다.

LV. 1