데이터 프레임에서도 이전에 Series에서 배웠던 sort_values를 사용할 수 있다.
이번에는 추가적으로 **nlargest, nsmallest 를 배워보도록 하겠다.
실습 환경 구축
import pandas as pd가지고 오고자 하는 컬럼
cols = ['Released_Year', 'Genre','Series_Title','Director','Meta_score', 'IMDB_Rating','No_of_Votes','Certificate','Gross']파일 읽기+컬럼 조정
movie_df = pd.read_csv('imdb_top_1000.csv')
movie_df = movie_df[cols]
movie_df.nlargest()
기준 컬럼을 정해서 내림차순 정렬
문법 : df.**nlargest(n, columns, keep = ‘first’)**
n : 몇개를 리턴할 것이냐.
columns : 어떤 컬럼을 통해서 정렬 할 것이냐.
keep : 중복값이 있을때 어떤 값을 보여줄 것이냐.
first : 첫번째 / default
last : 마지막
all : 중복값이 발생 하더라도 삭제 없이 진행.
- IMDB_Rating 컬럼을 기준으로 정렬을 해보자. 5개만 보이도록!
movie_df.nlargest(n=5, columns=['IMDB_Rating'])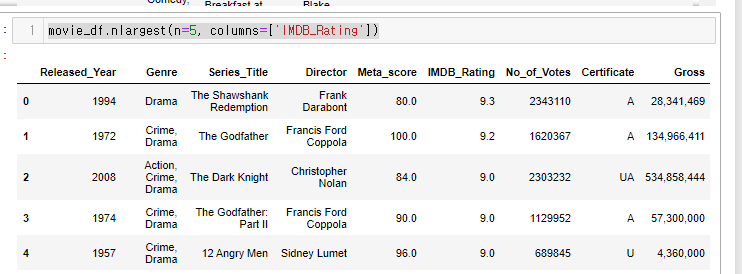
sort_values() 사용
물론 sort_values()와 head()를 이용해서도 위와 같이 정렬할 수 있다.
movie_df.sort_values(by='IMDB_Rating', ascending=False).head()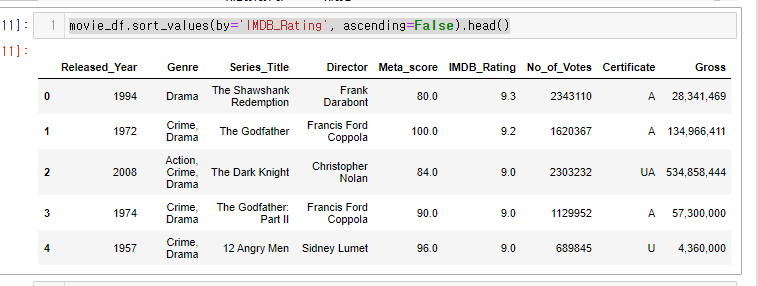
DataFrame은 컬럼이 여러개이기 때문에 by= 인자로 정렬 기준을 잡아줘야 된다.
성능은 nlargest 가 더 우수하다!
.nsmallest()
.nlargest()와 반대로 오름차순으로 정렬
movie_df.nsmallest(n=5,columns=['IMDB_Rating'])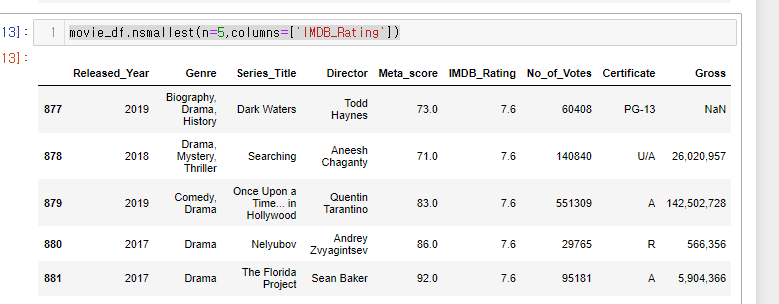
이때 IMDB_Rating 컬럼의 값이 다 동일하기 때문에 추가적인 기준을 넣어 줄 수있다.
IMDB_Rating 값이 동일하면 Meta_score 컬럼을 기준으로 정렬해보자.
movie_df.nsmallest(n=5,columns=['IMDB_Rating','Meta_score'])columns= 리스트에 컬럼을 추가해주면 됨.
keep= 인자
keep : 중복값이 있을때 어떤 값을 보여줄 것이냐.
first : 첫번째(default)
last : 마지막에 등장하는
all : 중복값이 발생 하더라도 삭제 없이 진행.
설명만 듣고서는 이해가 잘 안된다.
예제를 통해 이해를 해보자!
먼저 .nlargest 를 사용하여 7개의 값을 가져와보자
movie_df.nlargest(n=7, columns=['IMDB_Rating'])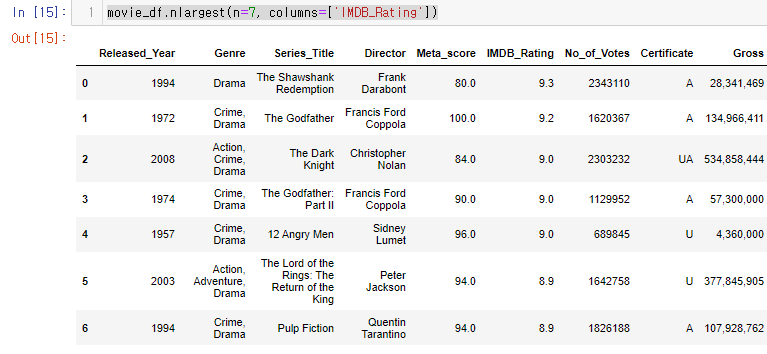
IMDB_Rating 컬럼 기준이기 때문에 8.9에서 짤려있다.
하지만 8.9점이 그 밑에 더 있을 수 도 있다!
이때 가져오는 값의 기준을 정해주는 인자가 keep= 이다.
keep=last라고 지정해보자.
movie_df.nlargest(n=7, columns=['IMDB_Rating'],keep = 'last')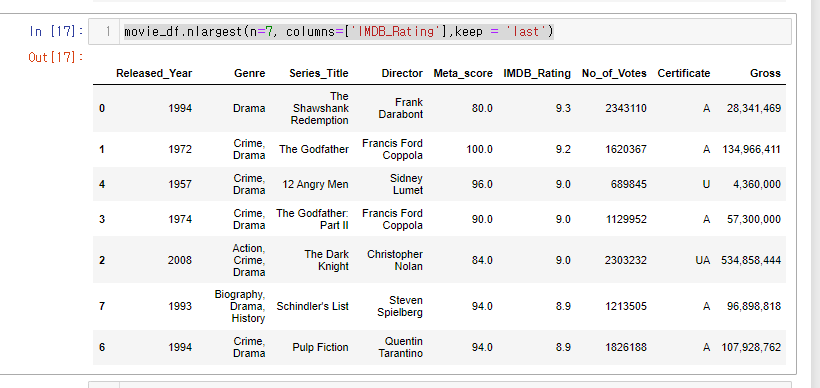
기준 컬럼 IMDB_Rating 에서 가장 아래에 있던 점수 8.9를 먼저 보여주는 것을 볼 수 있다.
인덱스 레이블을 한번 보면
각 데이터들의 아래 부터 나오는 것을 확인 할 수 있다.
keep=all
정렬시 중복되는 값이 있을 때 잘리지 않도록 하기 위해서는 keep=all 인자를 사용해주면 된다.
movie_df.nlargest(n=7, columns=['IMDB_Rating'],keep = 'all')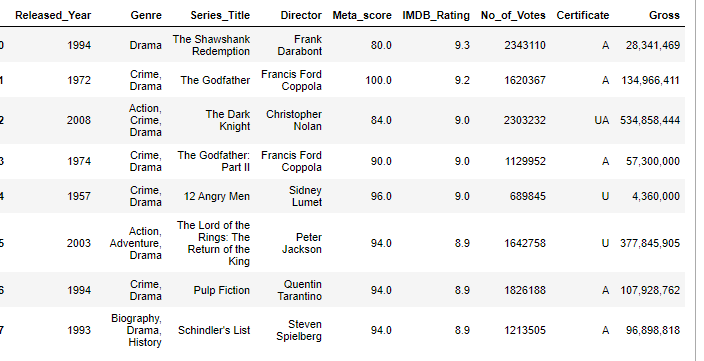
IMDB_Rating 컬럼의 8.9 중복값이 3개였으므로 n=7 이 더라도 컬럼의 갯수는 8개가 됨을 확인할 수 있다.
