[31일차]스케일링 실습
스케일링 실습은
데이터 시각화 부분은 numpy, pandas, seaborn 라이브러리를 사용할 것 이다.
import numpy as np
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')- numpy :
- 파이썬의 기본 데이터 구조인 리스트와 배열과는 다르게, 고성능의 다차원 배열 객체와 이를 처리하기 위한 도구를 제공
- pandas :
- 데이터 조작 및 분석을 위한 파이썬 라이브러리로, 데이터 구조인 Series와 DataFrame을 제공한다. 이를 통해 데이터의 라벨링, 인덱싱, 조작, 병합 등 다양한 작업을 효과적으로 수행할 수 있다.
- **Seaborn:**
- 데이터 시각화 라이브러리로, Matplotlib 기반 위에 구축되었다. 더 간결하고 세련된 시각화를 위한 고수준 인터페이스를 제공하며, 통계 데이터를 쉽게 시각화할 수 있도록 도와준다.
- 시각화의 세부 설정 및 테마 지원한다.
- 데이터 시각화 라이브러리로, Matplotlib 기반 위에 구축되었다. 더 간결하고 세련된 시각화를 위한 고수준 인터페이스를 제공하며, 통계 데이터를 쉽게 시각화할 수 있도록 도와준다.
import warnings : 파이썬에서 경고 메시지를 제어하기 위한 모듈로 아래와 같이 작성하면 모든 경고 메시지가 무시된다.
warnings.filterwarnings('ignore')스케일링 부분은 sklearn.preprocessing의 MinMaxScaler, StandardScaler를 사용할 것 이다.
from sklearn.preprocessing import MinMaxScaler, StandardScalerMinMaxScaler - minmax스케일링을 제공
StandardScaler - 스탠다드 스케일링을 제공
실습
seaborn에서 제공하는 titanic 데이터셋을 로드해보자
# titanic 데이터셋 로드
df = sns.load_dataset('titanic')
df = df.loc[df['age'].isna()==False].reset_index(drop=True) 
여기서 age,와 fare 위주로 한번 살펴보자
age의 히스토그램
hist() 메소드를 사용하면 히스토그램을 만들 수 있다.
bins= 인자는 구간의 갯수를 의미한다.
df['age'].hist(bins=30) 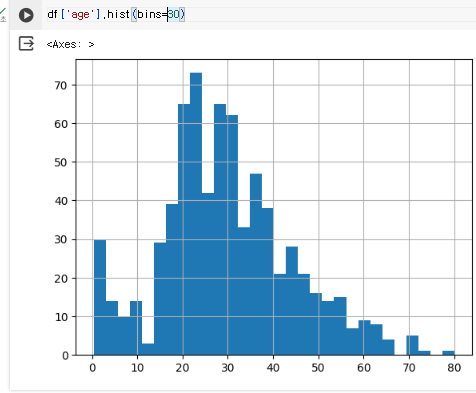
20~30대에 많이 분포된 것을 알 수 있다.
fare의 히스토그램
df['fare'].hist(bins=30) 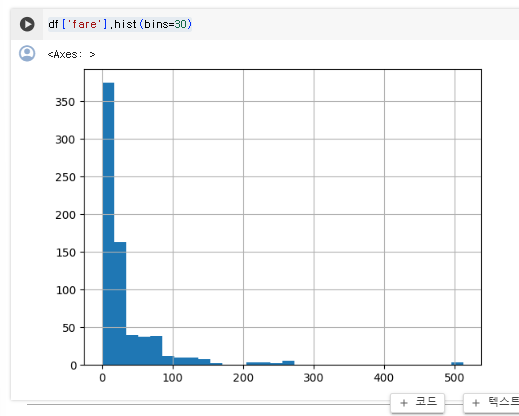
MinMaxScaler()
MinMaxScaler() : MinMax 스케일을 진행하고자 할 때 선언
minmax 스케일은 feature가 0~1사이에 위치하도록 하는 것이다.
df['fare_minmax'] = MinMaxScaler().fit_transform(df['fare'].values.reshape(-1, 1))
df['age_minmax'] = MinMaxScaler().fit_transform(df['age'].values.reshape(-1, 1)).fit_transform():fit부분에서 MinMaxScaler() 객체를 데이터에 적합시킨다. 이 과정에서 각 컬럼에 대해 최소값(min), 최대값(max) 을 계산한다.transform부분에서 fit의 데이터를 [0,1] 범위로 스케일 후 데이터를 원본에 매핑시킨다.
(df['fare'].values: 'fare' 열의 데이터를 NumPy 배열로 가져온다..reshape(-1, 1)): 1차원 배열을 2차원 배열로 변환.
여기서-1은 배열의 원래 형태를 유지하면서 1개의 열로 구성된 2차원 배열을 만들라는 의미
값이 어떻게 나오나 조회해보자.
fare 데이터
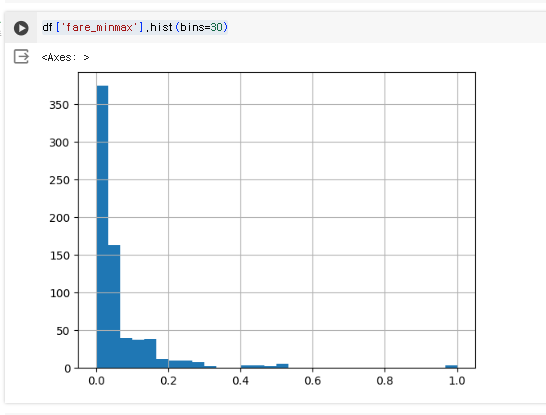
age 데이터
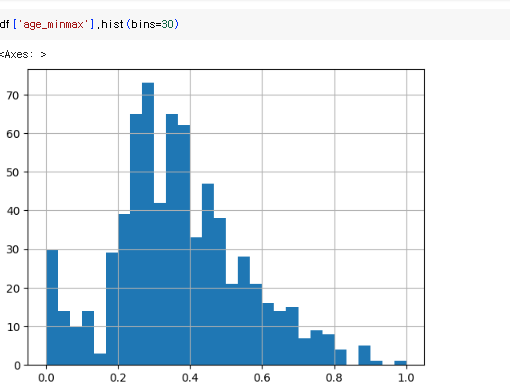
x축 값은 0~1사이이지만 feature 비율은 이전과 동일한 것을 알 수 있다.
Standardization(z-score scaling)
StandardScaler() : Standardization를 진행하고자 할 때 사용
위와 동일한 방식으로 사용.
scaler = StandardScaler()
df['fare_standard'] = scaler.fit_transform(df['fare'].values.reshape(-1, 1))
df['age_standard'] = scaler.fit_transform(df['age'].values.reshape(-1, 1))fare 데이터
df['fare_standard'].hist(bins=30) 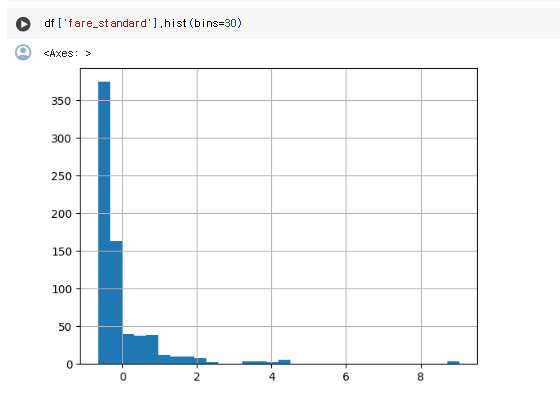
-의 값도 존재하는 것을 볼 수 있다.
z-score(출력값)가 ±1.5𝝈, ±2𝝈를 벗어나는 경우 해당 데이터를 이상치로 간주하면 된다.
age 데이터
df['age_standard'].hist(bins=30) 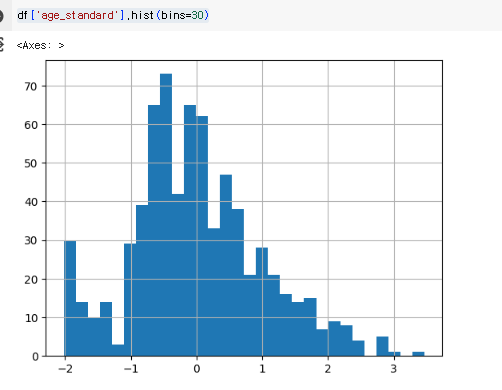
0이라는 값을 기준으로 잘 분포되어 있다.
Log/power scale
1. np random 함수를 통해 난수 생성
exp_scale_data = np.random.exponential(1,300)
df_exp = pd.DataFrame(columns=['x'])
df_exp['x'] = exp_scale_datanp.random.exponential(1,300)- Numpy 라이브러리에는 난수를 만드는 ramdom 모듈이 있다. 이를 통해 난수를 만들어 볼 것이다.
.exponential함수는 평균이 1인 지수 분포에서 300개의 무작위 샘플을 생성한다.
df_exp = pd.DataFrame(columns=['x'])- x컬럼을 가진 데이터 프레임을 생성!
df_exp['x'] = exp_scale_data- 생성된 x컬럼에
exp_scale_data를 value값으로 넣는다.
- 생성된 x컬럼에
조회를 해보자
df_exp['x'].hist(bins=30) 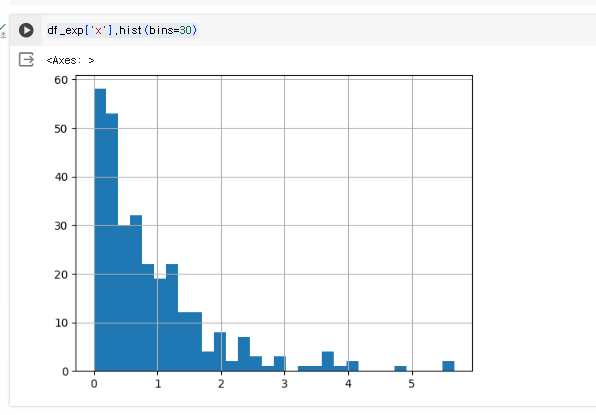
이런식의 히스토그램이 만들어졌다.
이제 이 히스토그램을 Log scaling 해보자
# Log scaling
df_exp['log_x'] = np.log(df_exp['x'])numpy에서 지원하는 .log() 메소드를 이용해 Log scaling 후 log_x라는 컬럼에 저장
이후 히스토그램을 만들어보면
df_exp['log_x'].hist(bins=30) 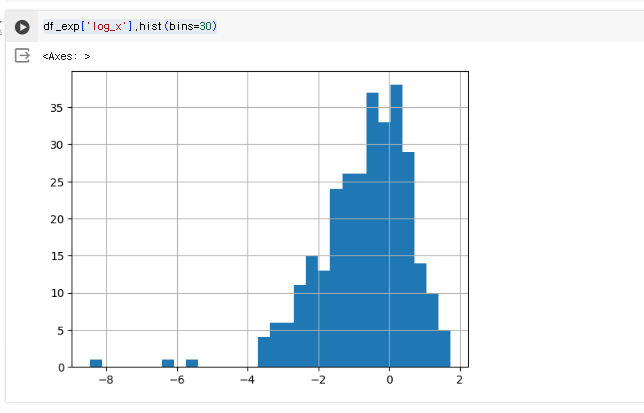
종모양으로 잘 나오는 것을 볼 수 있다.
titanic 데이터셋에서 fare 항목에 추가적인 scaling을 해보자
fare 컬럼을 확인해 보면 아예 0인 값도 존재한다.
하지만 스케일링시 이런 데이터는 문제가 될 수 있다.
바로, log(0) = - inf(무한) 이기 때문이다. 때문에 log를 사용하기 어렵기 때문에
square root(제곱근)로 scaling을 해보자
sqrt() : 제곱근을 해주는 함수
df['fare_sqrt'] = np.sqrt(df['fare'])제곱근 후 히스토그램을 확인해 보자
df['fare_sqrt'].hist(bins=30) 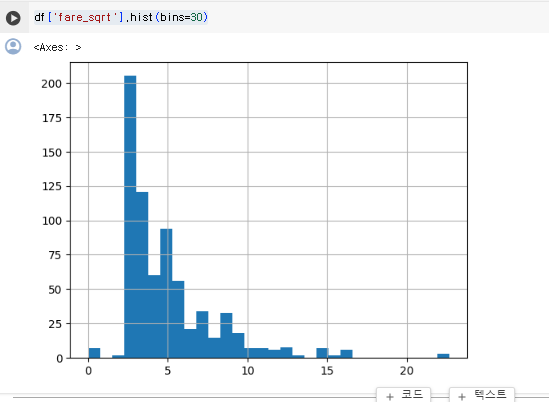
처음 fare값보다는 잘 분포된 것을 확인할 수 있다.
