이번 글에서는 파이썬을 통해 기술통계를 진행하는 방법을 알아볼 것 이다.
정량적 데이터 분석이란?
- 정량적 데이터 분석은 숫자로 표현되는 수치 데이터를 이용하여
주어진 데이터를 분석하는 과정 - 통계 수치를 구하여 이 값으로부터 여러 정보를 발견해내며,
다음과 같은 통계 수치를 주로 활용한다.
- 평균, 중앙값, 최빈값 을 통해
데이터가 어느 값을 중심으로 뭉쳐있는지를 확인
- 분산, 표준편차, 분위수, Q1(25분위수), Q3(75분위수)를 통해
데이터가 어떤 형태로 퍼져있는지를 확인
정량적 데이터 분석(통계수치)
describe() - 요약통계
전반적인 주요 통계를 확인할 수 있다.
기본 값으로 수치형(Numerical) 칼럼에 대한 통계표를 보여준다.
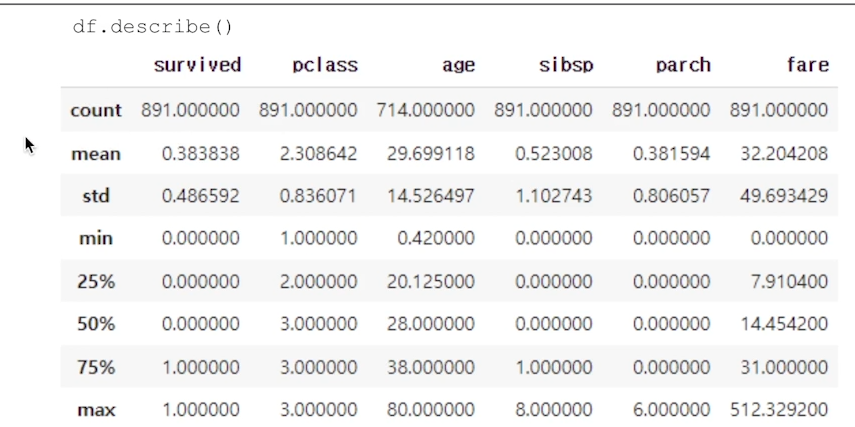
- count: 데이터 개수
- mean: 평균
- std: 표준편차
- 25%, 50%, 75%:
25분위(Q1), 50분위(median), 75분위(Q3)
크기 순서로 나열했을때의
‘25%번째’, … 값 - 문자열 컬럼에 대한 통계표도 확인할 수 있다.
.describe(include = ‘O’)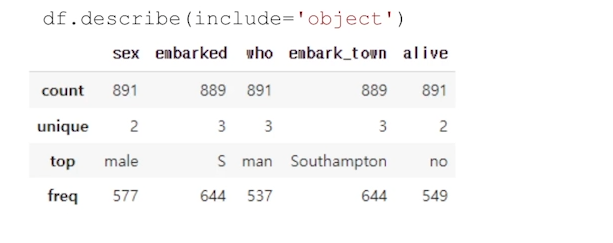
- unique: 고유 데이터의 값 개수 - top: 가장 많이 출현한 데이터 개수 - freq: 가장 많이 출현한 데이터의 빈도수
df.count()
컬럼별 데이터 개수를 확인할 수 있다.
df.count() 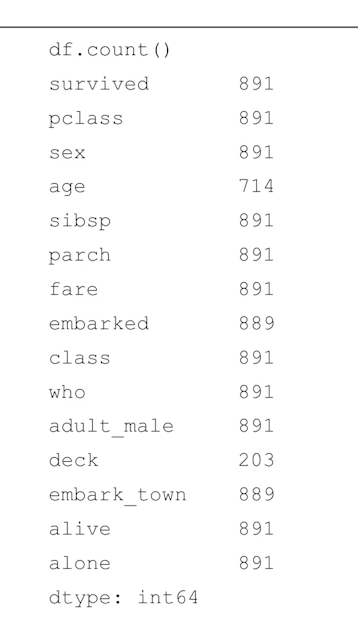
특정 컬럼의 데이터를 구하는 경우 아래처럼 코드 작성
df['age'].count()df.mean()
- 데이터의 평균을 구해줌.
.count()와 마찬가지로 사용하면 됨.
- 기술통계 함수들은 조건별로 구할 수 있다.(mask 때를 복습!)
-
남자(1)의 나이를 구하는 경우
condition = (df['adult_male'] == True) #남자는 1 여자는 0 df.loc[condition, 'age'].mean() 남자중에서 나이 컬럼의 평
-
df.median()
-
데이터를 오름차순 정렬하여 중앙에 위치한 값이다.
-
이상치(outlier)가 존재하는 경우, mean()보다 median()을 대표값으로 더 선호한다.(당연!) 아래와 같을때 평균은 너무 커진다;;;

-
중앙값이 짝수개면 2개의 중앙 데이터의 평균값을 출력한다.
df.sum
-
합계를 구한다.
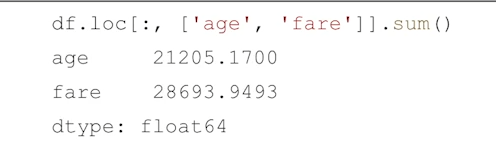
-
문자열 컬럼은 모든 데이터가 붙어서 출력될 수 있으니 조심하기!

분산(df.var())과 표준편차(df.std())
- df.var() - 분산
 위의 식을아래와 같이 함수로 만든것!
위의 식을아래와 같이 함수로 만든것!
- df.std() - 표준편차
 분산에 루트를 취하면 표준편차가 된다. 위의 식을 아래와 같이 함수로 만든것.
분산에 루트를 취하면 표준편차가 된다. 위의 식을 아래와 같이 함수로 만든것.
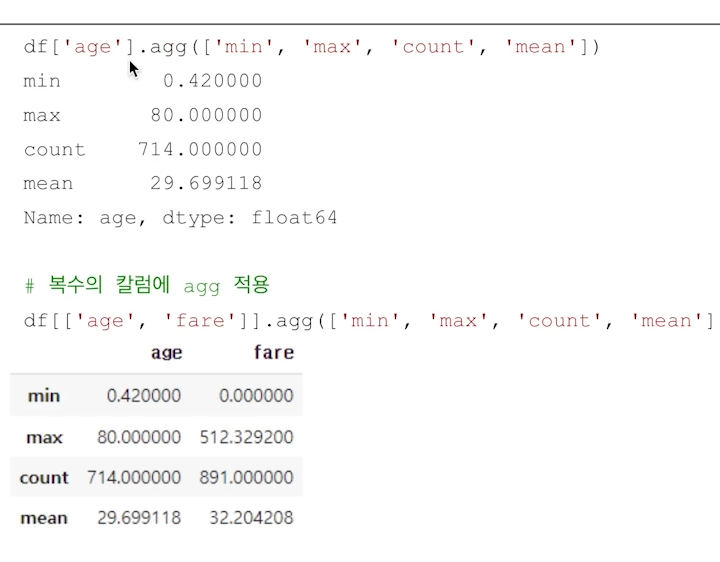
df.agg([통계함수1,..])
여러 통계함수를 쓸 때 사용!
df.quantile()
Quantile 이란?
분위수를 의미함.
주어진 데이터를 동등한 확률구간으로 분할하는 지점.
a.g. 나이가 10%대인 값 = 14

df[’컬럼명’].unique()
컬럼의 유니크한 값을 보여줌.
df.mode - 최빈값
최빈값은 가장 많이 출현한 데이터를 의미
df.corr() - 상관관계
corr()로 컬럼별 상관관계를 확인할 수 있다.
- -1~1 사이의 범위를 갖는다.
- -1에 가까울 수록 반비례 관계, 1에 가까울 수록 정비례 관계를 갖는다.
df.corr() 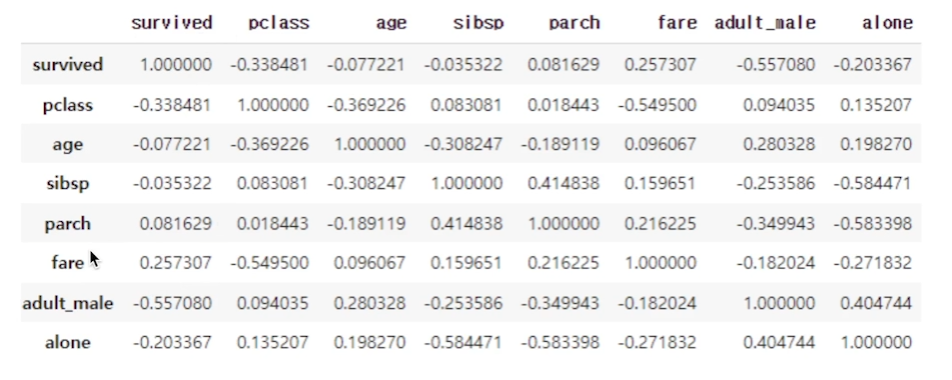
survived 컬럼을 예로 -1,1에 가까울 수록 상관관계가 높다고 볼 수 있다.

LV. 1