선형 회귀 모델을 이용한 실습_1
실습 데이터셋 설명
실습에 사용할 데이터 셋은 ‘의료비 개인 데이터셋’이다.

1.문제 정의
데이터를 받으면 항상 문제부터 정의해야 된다!
- 풀어야 되는 문제
- 주어진 건강 및 인구통계학적 정보를 바탕으로 개인의 연간 의료 보험료를 예측
- 머신 러닝 모델의 입, 출력 정의
• 입력 : 앞선 독립 변수들
• 출력 : 개인 의료비 (종속 변수)
2. 실습 데이터 EDA, 탐색적 데이터 분석
먼저 EDA를 진행해보자.
- 데이터 로드
import pandas as pd
# 데이터 경로 지정 및 읽어오기
data_path = '/content/insurance.csv'
insurance_data = pd.read_csv(data_path)
# 데이터 꼴 확인
insurance_data.head()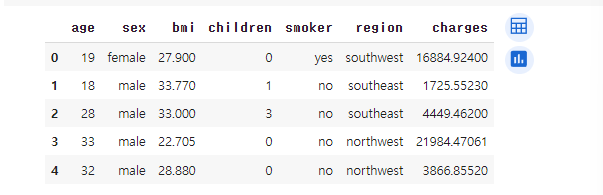
2.기본 정보 및 기초 통계
# 기본 정보
print('#'*20, '기본 정보', '#'*20)
insurance_data.info() # info() 안에서 자동으로 print를 진행
# 기초 통계량
summary_statistics = insurance_data.describe(include='all')
print('#'*20, '기초 통계량', '#'*20)
print(summary_statistics)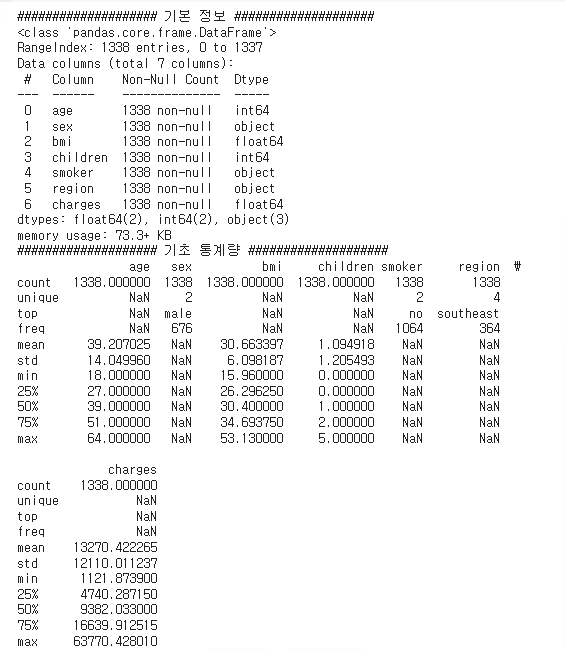
- 전체 데이터셋 크기
• 총 1338개의 개별 데이터
• 총 7개 특성 - 데이터 타입
• 정수형 (int) : ʻageʼ, ʻchildrenʼ
• 실수형 (float) : ʻbmiʼ, ʻchargesʼ
• 문자열 (object) : ʻsexʼ, ʻsmokerʼ, ʻregionʼ - 누락 : 없음
3. 시각화 진행
시각화는 범주형 데이터(남자/여자, 흡연여부 등)와 수치형 데이터(BMI, age 등)으로 나눠서 볼 예정이다.
시각화 - 수치형 데이터
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 10))
# 나이 분포
plt.subplot(2, 2, 1) #2*2중 1번째에 들어가
plt.hist(insurance_data['age'], color='skyblue', edgecolor='black')
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
# BMI 분포
plt.subplot(2, 2, 2)
plt.hist(insurance_data['bmi'], bins=30, color='olive', edgecolor='black')
plt.title('BMI Distribution')
plt.xlabel('BMI')
plt.ylabel('Frequency')
# 부양가족 분포
plt.subplot(2, 2, 3)
plt.hist(insurance_data['children'], color='gold', edgecolor='black')
plt.title('Number of Children Distribution')
plt.xlabel('Number of Children')
plt.ylabel('Frequency')
# 의료비 분포
plt.subplot(2, 2, 4)
plt.hist(insurance_data['charges'], bins=30, color='teal', edgecolor='black')
plt.title('Charges Distribution')
plt.xlabel('Charges')
plt.ylabel('Frequency')
plt.tight_layout()
plt.show()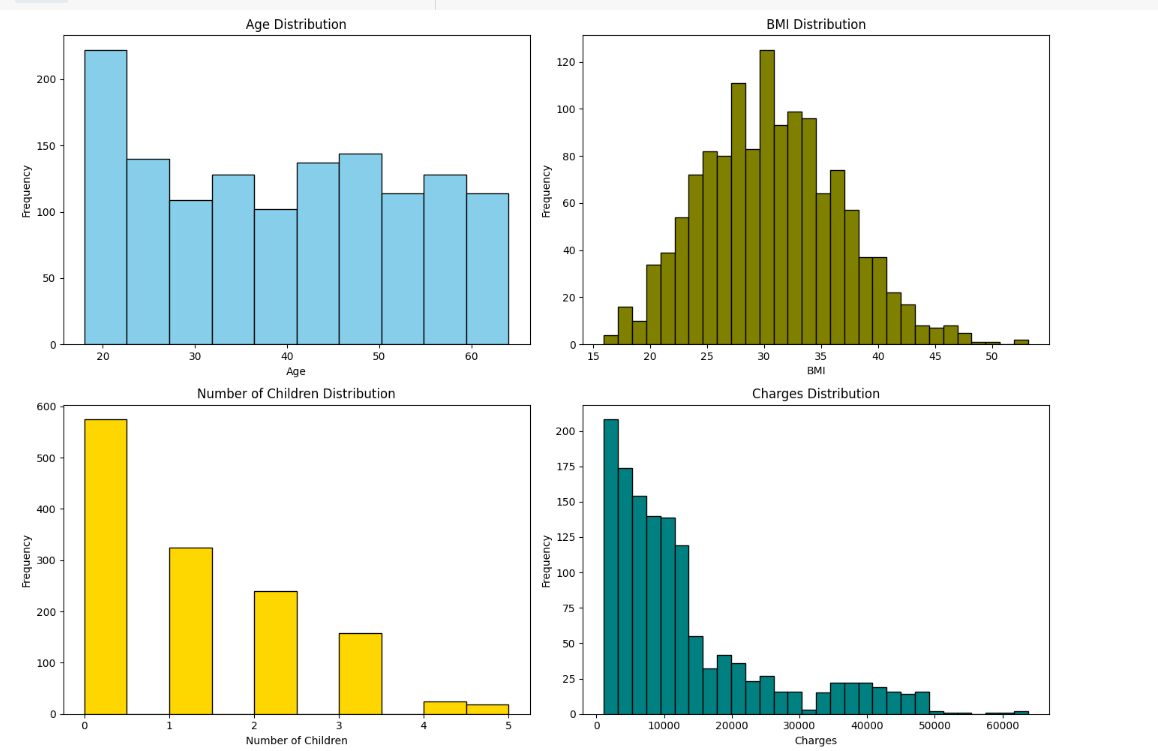
- 시각화를 통해 전체 데이터의 분포를 볼 수 있음
• 나이 분포 : 상대적으로 균일하게 분포로 큰 편중이 없음
• BMI 분포 : 정규분포와 유사한 형태를 보임
• 부양 가족 수 분포 : 대부분 0~2명의 자녀를 갖고 있음
• 의료비 분포 : 오른쪽으로 꼬리가 긴 분포 - • 각 특성 간 상관관계 분석도 수행할 수 있음
• Pandas.corr()객체에서 바로 상관관계 분석 가능
correlation_matrix = insurance_data.corr()
# 상관관계 메트릭스 시각화
plt.figure(figsize=(5, 4))
plt.matshow(correlation_matrix, fignum=1)
plt.colorbar()
plt.xticks(range(len(correlation_matrix.columns)), correlation_matrix.columns, rotation=90)
plt.yticks(range(len(correlation_matrix.columns)), correlation_matrix.columns)
plt.title('Correlation Matrix of Medical Cost Datasets', y=1.15)
plt.show()
# 상관관계 값 프린트
print('#'*20, '상관관계 값 확인', '#'*20)
print(correlation_matrix)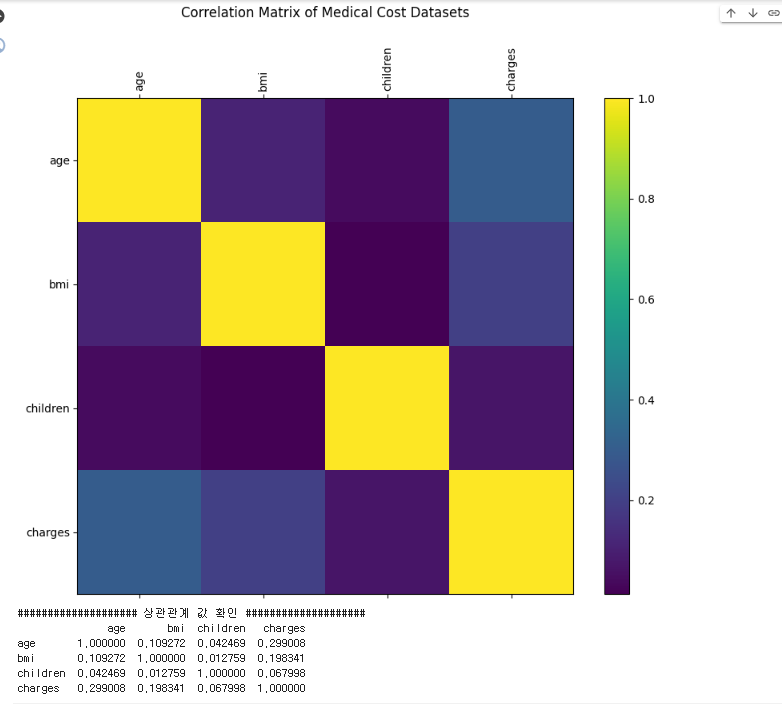
시각화 - 카테고리 데이터
plt.figure(figsize=(18, 5))
# 성별에 따른 의료비용
plt.subplot(1, 3, 1)
plt.boxplot([insurance_data[insurance_data['sex']=='male']['charges'],
insurance_data[insurance_data['sex']=='female']['charges']],
labels=['Male', 'Female'])
plt.title('Charges by Sex')
plt.ylabel('Charges')
# 흡연 유무에 따른 의료비용
plt.subplot(1, 3, 2)
plt.boxplot([insurance_data[insurance_data['smoker']=='yes']['charges'],
insurance_data[insurance_data['smoker']=='no']['charges']],
labels=['Smoker', 'Non-smoker'])
plt.title('Charges by Smoker')
plt.ylabel('Charges')
# 거주 지역에 따른 의료비용
plt.subplot(1, 3, 3)
regions = insurance_data['region'].unique()
region_charges = [insurance_data[insurance_data['region']==region]['charges'] for region in regions]
plt.boxplot(region_charges, labels=regions)
plt.title('Charges by Region')
plt.ylabel('Charges')
plt.tight_layout()
plt.show()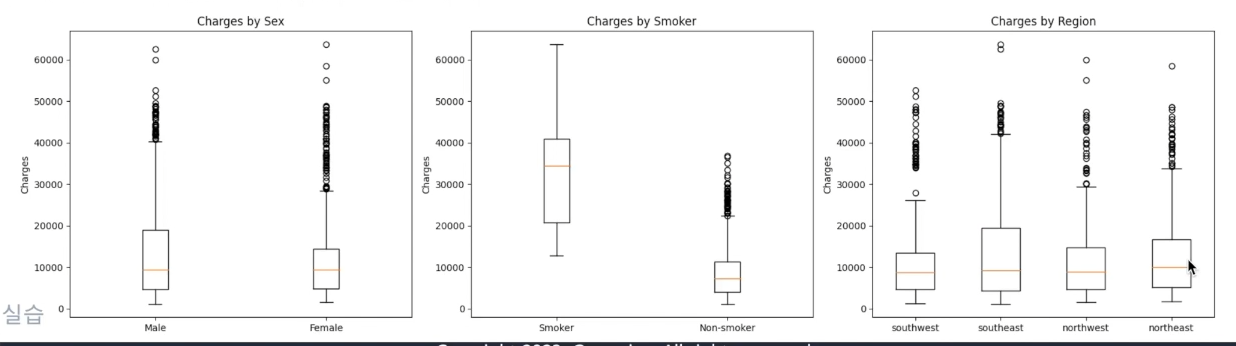
- 성별
• 성별에 따른 의료비용 분포에 약간의 차이가 있음
• 남성의 경우 여성보다 의료비용을 좀 더 많이 냄 - 흡연 여부
• 흡연 유무는 매우 두드러지는 차이를 보임
• 종속 변수에 영향을 미치는 큰 요인으로 보임 - 지역별
• 차이는 보이지만 흡연 유무만큼은 아님
4. 데이터 전처리
카테고리형 변수 인코딩
카테고리형(범주형) 변수는 선형 모델에 입력으로 사용하기 위해 수치형으로 변경해야 함
이번 데이터에서는 성별, 흡연 유무, 지역이 이에 해당
일반적으로 원-핫 인코딩(one-hot encoding)방식을 사용
• 예를 들어, 성별이라면
• 성별남성과 성별여성 이라는 별도의 열을 만들고
• 각각을 0과 1의 값으로 표현
- Pandas의 get_dummies 함수를 사용
- 성별을 기준으로 했을 때 여자 컬럼, 남자 컬럼이 각 각 생겨남
- drop_first 옵션은 첫 카테고리를 제거하는 역할
- 남자 컬럼을 제거해도 누가 남자인지 여자인지 판별가능. 0 또는 1이기 때
- 새롭게 생겨난 변수들의 강한 상관관계가 나타나서(다중공선성) 보통은 제거하는 것이 좋음
insurance_encoded = pd.get_dummies(insurance_data, drop_first=True)
insurance_encoded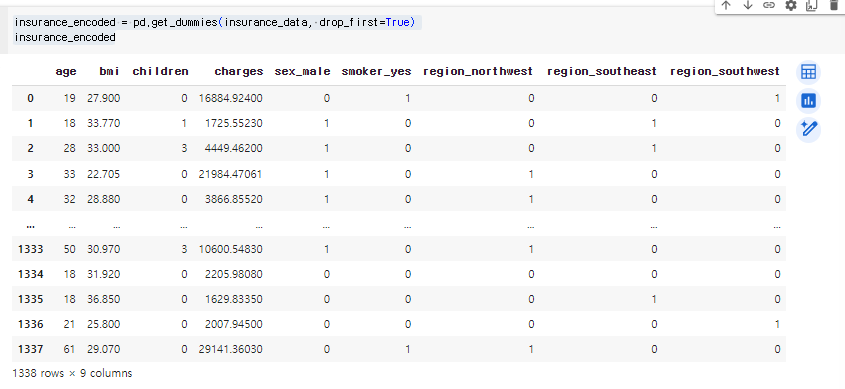
각 문자열 데이터가 0(TRUE)과 1(FALSE)로 바뀐 것을 볼 수 있다.
만약 drop_first= 를 False로 둔다면 아래와 같이 나옴
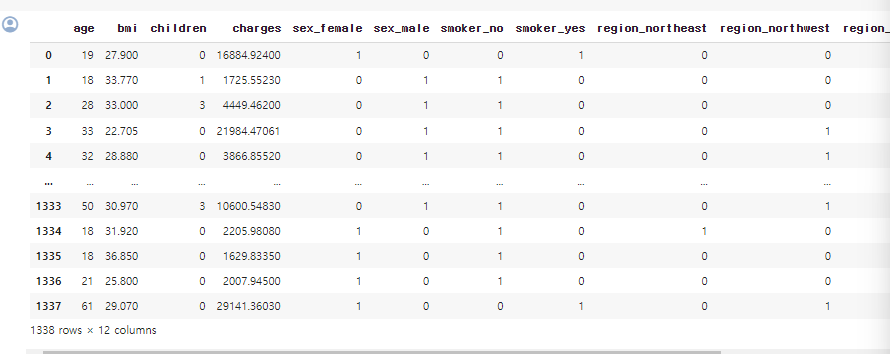
5. 학습 및 평가 데이터 분리
사용할 데이터를 확정했다면 학습 및 평가 데이터로 분리
원래는 학습 / 검증 / 평가 과정으로 나누어야 하지만
실제 서비스 모델을 개발하는 과정이 아니므로 학습과 평가 데이터로만 분리하자.
- 먼저, 독립 변수와 종속 변수를 분리
- 이후, 학습과 평가 데이터로 분리하기 위해
- sklearn 의 내장 함수인 train_test_split이라는 함수를 사용
• test_size 변수는 학습과 평가 데이터 사이의 비율을 의미
- sklearn 의 내장 함수인 train_test_split이라는 함수를 사용
from sklearn.model_selection import train_test_split
y_column = ['charges']
X = insurance_encoded.drop(y_column, axis=1)
y = insurance_encoded[y_column]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42)- 결과적으로 학습 데이터 1070개, 평가 데이터 268개 구성
print('#'*20, 'X_train', '#'*20)
print(X_train.head, end='\n')
print('#'*20, 'Y_train', '#'*20)
print(y_train.head, end='\n\n')
print('#'*20, 'X_test', '#'*20)
print(X_test.head, end='\n')
print('#'*20, 'Y_test', '#'*20)
print(y_test.head, end='\n')
6. 특성 스케일링
서로 다른 수치형 데이터 특성 사이의 값 범위를 비슷하게 맞춰주는 과정
필수 단계는 아니지만 매우 권장되는 과정이다!
효과
• 특히 경사 하강법을 사용하는 과정에서 수렴 속도를 높일 수 있음
• 규제 모델을 사용한다면 일부 특성에 강하게 규제가 걸리는 과정을 회피할 수 있음
- 방법은 두가지이다.
- StandardScaler
- 평균 0, 표준편차 1로 조정
- 데이터의 분포가 정규분포일 경우 사용하면 best!
- 일반적으로 많이 사용
- MinMaxScaler
- 최댓값 1, 최솟값 0이 되도록 조정
- 이상치가 큰 영향을 미치는 경우 사용
- StandardScaler
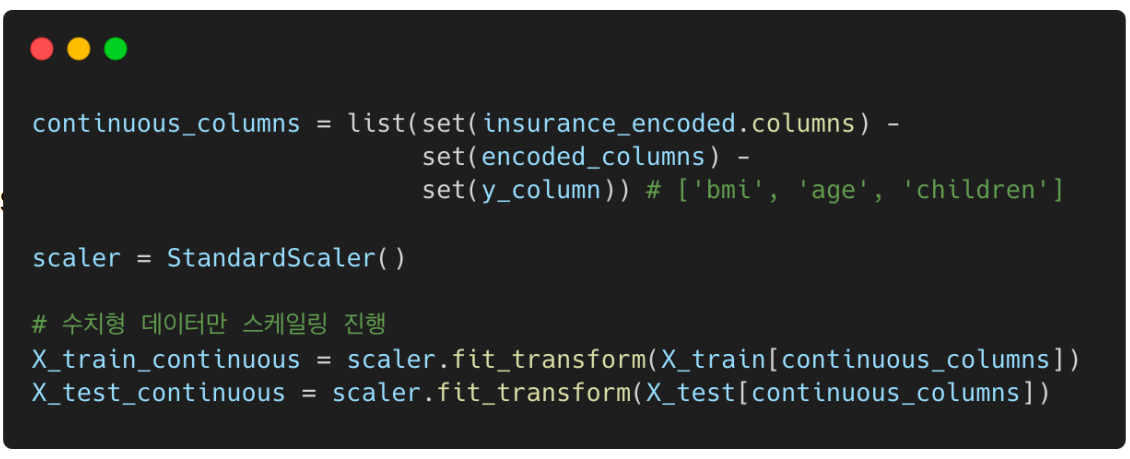
이번에는 StandardScaler를 이용하여 bmi, age, children 스케일링 진행!
charges의 경우 출력값이어야 되기 때문에 스케일링 하지 않는다.
from sklearn.preprocessing import StandardScaler
encoded_columns = list(set(insurance_encoded.columns) - set(insurance_data.columns)) # ['region_southwest', 'region_southeast', 'region_northwest', 'smoker_yes', 'sex_male']
continuous_columns = list(set(insurance_encoded.columns) - set(encoded_columns) - set(y_column)) # ['bmi', 'age', 'children']
scaler = StandardScaler()
# 수치형 데이터만 스케일링 진행
X_train_continuous = scaler.fit_transform(X_train[continuous_columns])
X_test_continuous = scaler.fit_transform(X_test[continuous_columns])
# 스케일 된 데이터와 스케일에 사용되지 않은 데이터 조합
X_train_continuous_df = pd.DataFrame(X_train_continuous, columns=continuous_columns)
X_test_continuous_df = pd.DataFrame(X_test_continuous, columns=continuous_columns)
X_train_categorical_df = X_train[encoded_columns].reset_index(drop=True)
X_test_categorical_df = X_test[encoded_columns].reset_index(drop=True)
X_train_final = pd.concat([X_train_continuous_df, X_train_categorical_df], axis=1)
X_test_final = pd.concat([X_test_continuous_df, X_test_categorical_df], axis=1)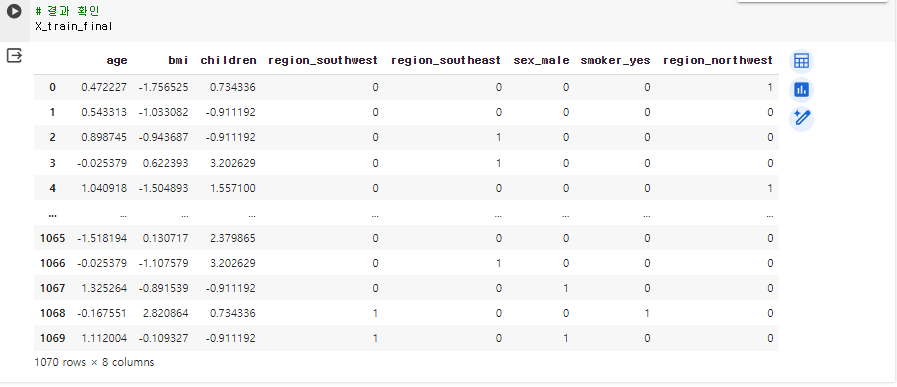
각자 다른 범주의 값이 비슷한 분포로 바뀌게 된다
