선형 회귀 모델을 이용한 실습_2
이제 ai 모델 구축 및 결과를 확인해 보자
선형 회귀 모델 학습 진행
w0 값을 위해 bias를 추가해줌
• 이전에도 결과를 봤지만 내장 함수를 이용하면
• 자동으로 추가해서 결과를 보여줌
• LinearRegression() 객체를 생성 후 학습 진행
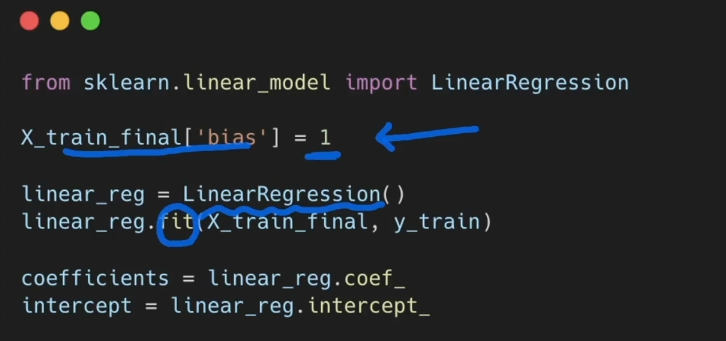
# w0에 해당하는 편향(bias) 부분을 추가
# 이론 과정에서는 식의 형태로 인해 맨 앞쪽에 넣었지만
# 위치는 크게 상관이 없음 (여기서는 맨 뒤로 들어감)
X_train_final['bias'] = 1
X_test_final['bias'] = 1
X_train_final
# 만약 맨 앞에 넣겠다면 아래와 같이 적을 수 있음
# X_train_final.insert(0, 'bias', 1)
# X_train_finalfrom sklearn.linear_model import LinearRegression
# 선형 회귀 모델 초기화 및 학습
linear_reg = LinearRegression()
linear_reg.fit(X_train_final, y_train)
# 학습된 모델의 계수(coefficients) 및 절편(intercept) 출력
coefficients = linear_reg.coef_
intercept = linear_reg.intercept_
print('#'*20, '학습된 파라미터 값', '#'*20)
print(coefficients)
print('#'*20, '학습된 절편 값', '#'*20)
print(intercept)
총 8개의 범주를 가지고 학습.
평가 진행
MSE 값을 이용해 평균적인 예측 실패 정도를 판단할 수 있음
from sklearn.metrics import mean_squared_error
# 예측 수행
y_train_pred = linear_reg.predict(X_train_final)
y_test_pred = linear_reg.predict(X_test_final)
# 평가 지표 계산: MSE
mse_train = mean_squared_error(y_train, y_train_pred)
mse_test = mean_squared_error(y_test, y_test_pred)
print('학습 데이터를 이용한 MSE 값 :', mse_train)
print('평가 데이터를 이용한 MSE 값 :', mse_test)
MSE 값을 보고는 잘했는지 못했는지 파악하기가 어렵다.
이번에는 시각화를 통해 진행해보자
# 테스트 데이터셋에 대한 실제 값과 예측 값을 산점도로 시각화
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_test_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--') # 완벽한 예측을 나타내는 대각선
plt.xlabel('Real Values')
plt.ylabel('Predict Values')
plt.title('Real vs Predict')
plt.show()X축은 실제값
Y축은 예측값으로 Y = X 그래프와 가까울수록 좋은 예측
점선 위에 있으면 잘 나온 것으로 볼 수 있다.
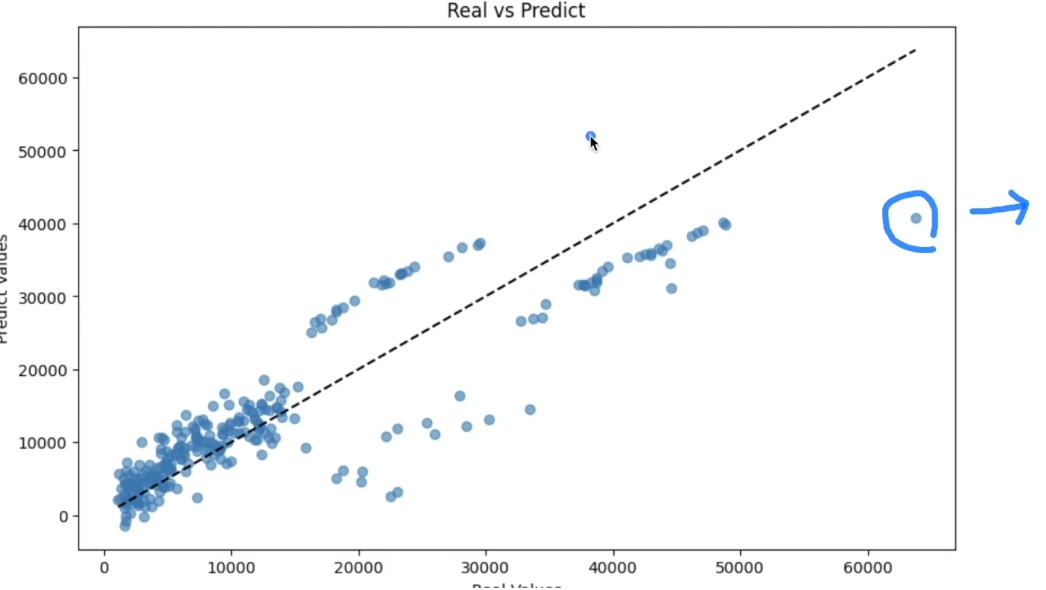
이때 툭 튀어나온 부분은 이상치로 간주하여 다시 처음으로 가서 모델을 조절해주면서 맞추면 된다.
결과 해석 - 변수의 중요도
학습을 잘 했다고 판단 되었을 때
각각의 변수의 중요도를 측정해본다.
각각의 변수들이 모델을 예측하는데 어느정도의 영향을 주는지 파악.
음수로 나오는 경우도 있기 때문에 절대값으로 한번 더 바꿔줌.
coeff_df = pd.DataFrame({'feature': X_train_final.columns, 'coefficient': linear_reg.coef_.flatten()})
# 계수의 절대값을 기준으로 내림차순 정렬
coeff_df['abs_coefficient'] = coeff_df['coefficient'].abs()
coeff_df_sorted = coeff_df.sort_values(by='abs_coefficient', ascending=False)
# 변수의 영향력을 확인
coeff_df_sorted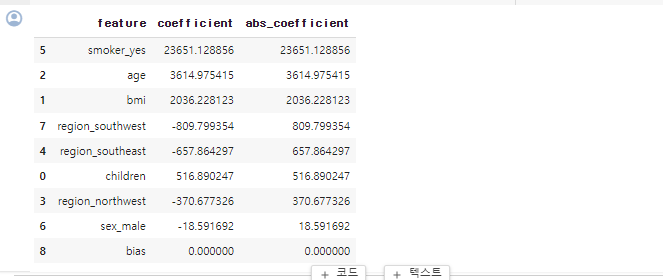
이를 시각화 해주면 아래와 같다.
# 변수 영향력 시각화
plt.figure(figsize=(10, 6))
plt.barh(X_train_final.columns, linear_reg.coef_.flatten())
plt.xlabel('Coefficient')
plt.ylabel('Features')
plt.title('Features Importance')
plt.show()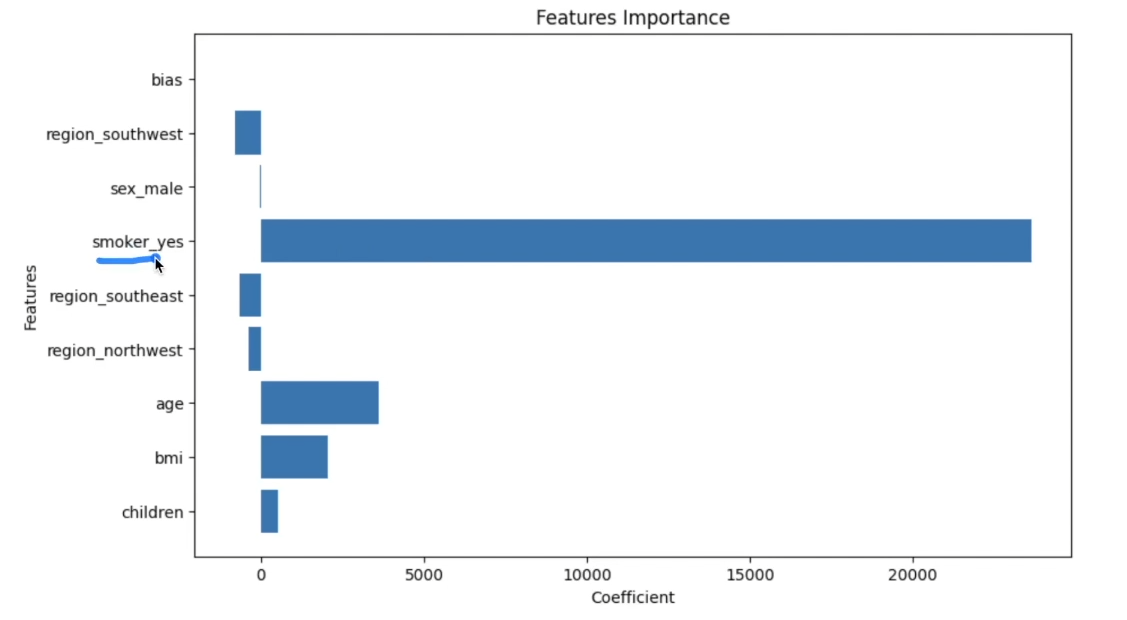
담배, 나이, bmi 가 의료비에 많은 영향을 미치는 것으로 알 수 있다.
숙제

이건 주말에 진행해보자..

LV. 1