K-means Clustering 이란?
K-means Clustering
ʻK-평균 군집화ʼ라고 부르며
전체 데이터를 K개의 덩어리(클러스터)로 나누는 비지도 학습법
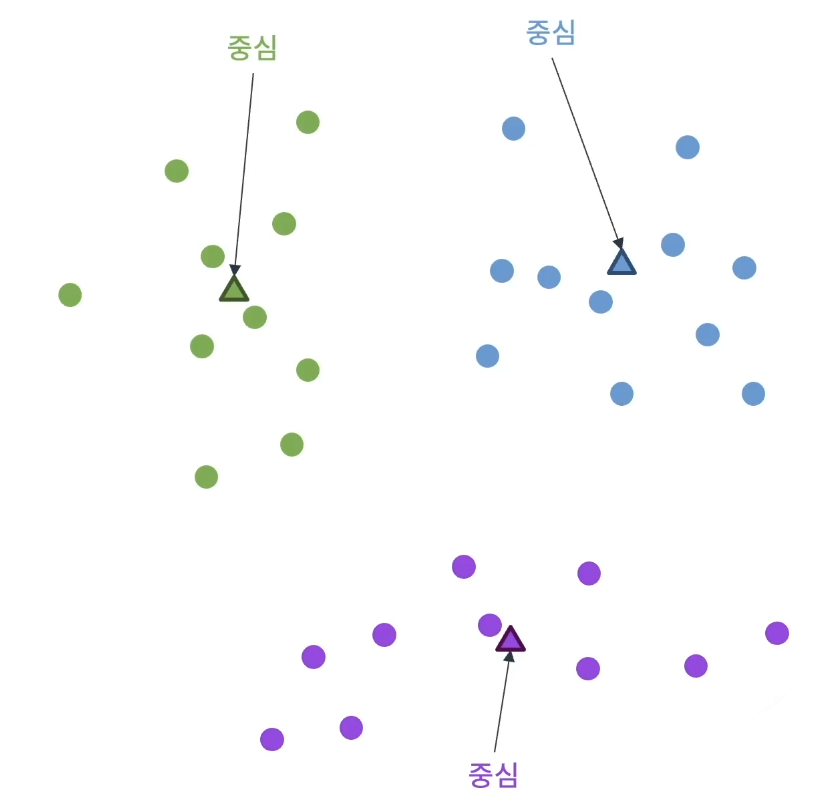
위쪽 그림은 K=3인 경우의 클러스터링 그럼 3개로 나뉘겠쥐?
• 삼각형(△)은 클러스터의 중심점을 표시
• 중심점은 클러스터 안에 포함된 데이터의 평균값
- 방법이 간단하며 효과적이고
• 결과 해석이 쉬워
• 많은 분야에서 사용됨!
K-means Clustering 과정
K-means 알고리즘의 4 단계
K-means 군집화 기법을 푸는 유명한 두 알고리즘은 아래와 같음
• 로이드 (Lloyd) 알고리즘
• 엘칸 (Elkan) 알고리즘
- 로이드 알고리즘이 가장 기본적인 방법
- 로이드 알고리즘은 아래 4가지 단계로 구성됨
• 초기화
• 할당
• 업데이트
• 반복 - 엘칸 알고리즘의 경우
• 데이터 포인트와 클러스터 중심 거리를 계산하는 과정에 삼각 부등식을 사용
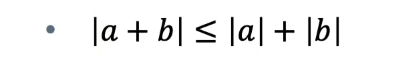
1. 초기화
K개의 클러스터 중심점을 임의로 선택(랜덤으로 선택!)
- 초기 위치는 최종 결과에 큰 영향을 미칠 수 있음
- 이때 클러스터 중심점이 몰려있지 않게 하기위해
k-means++ 초기화 방법을 많이 사용
• 초기 중심점의 위치를 멀리 떨어지게 설정
• 임의의 랜덤 위치보다 좋은 결과를 보여줌

2. 할당
각 데이터 포인트를 가장 가까운 클러스터 중심에 할당
일반적으로 유클리드 거리(Euclidean Distance)를 기반으로 거리 계산을 진행
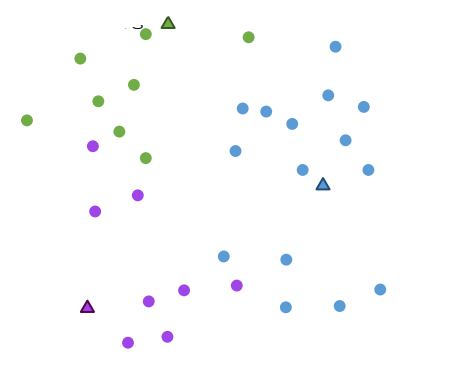
거리를 기준으로 군집화 된 모습!
3. 업데이트
클러스터에 속한 데이터들의 평균점 위치로 클러스터 중심의 위치를 업데이트
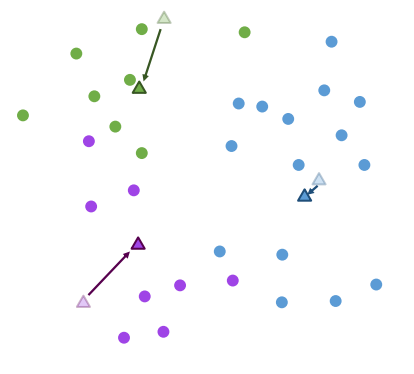
4.반복
클러스터 중심의 변화가 미미할 때까지 할당 과정과 업데이트 단계를 반복
업데이트를 반복하다보면 데이터 포인트들은 각 클러스터에 맞게 변화한다.
- 변화가 미미함의 정의는
• 정말 위치의 변화가 없거나
• 클러스터에 할당되는 데이터 포인트의 변화가 없거나
• 동일한 데이터 포인트 할당 과정이 반복되거나
• 지정된 횟수에 도달하거나
• 등등
k-means 클러스터링 실습
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
seed = 1234
np.random.seed(seed)아래의 가상 데이터를 생성하도록 하겠다.
# 가상 데이터 생성
X, y_true = make_blobs(n_samples=300,
centers=4, # Cluster의 수 혹은 Cluster의 중심 위치 좌표
cluster_std=0.60, # 각 클러스터가 얼마나 퍼져있게 할건지
n_features=2, # 사용할 feature의 수, 시각화를 위해 2차원 사용
random_state=0)
# 데이터 시각화
plt.scatter(X[:, 0], X[:, 1], s=20)
plt.title("Generated Data")
plt.show()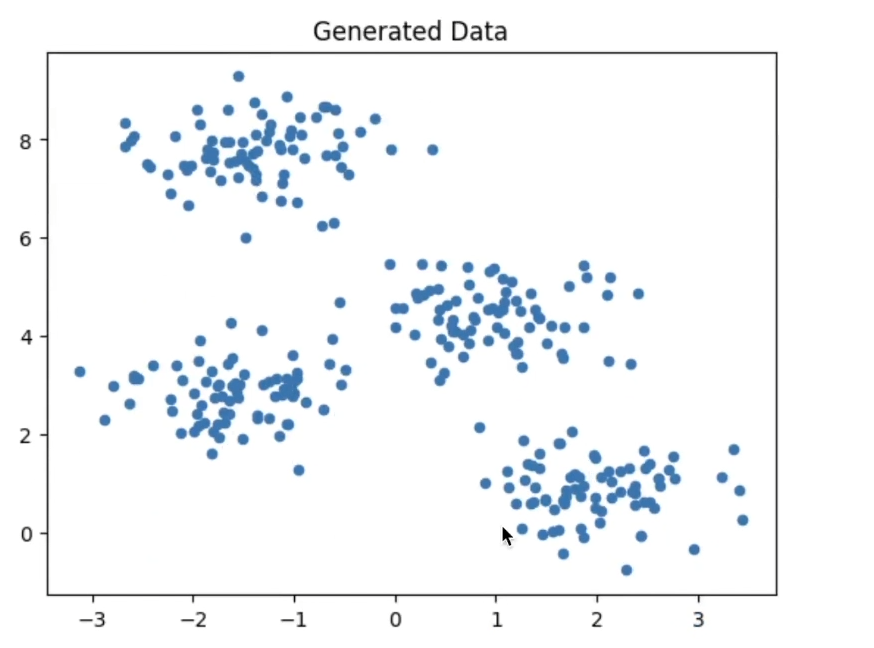
K-means 클러스터링 진행
K-means 클러스터는 sklearn의 KMeans에서 할당할 수 있다.
from sklearn.cluster import KMeans
# K-Means 클러스터링 수행 (k=4)
kmeans = KMeans(n_clusters=4, #클러스터를 4개로 잡게함.
init='k-means++', # 초기 클러스터 중심 위치를 잡는 초기화 방법
n_init=10, # 초기 중심점 잡기를 얼마나 많은 다른 방법으로 설정할지를 결정 / 10번의 시도를 하겠다는 것이고, 10번 중 최고의 SSE 성능을 보이는 모델을 최종 모델로 사용
random_state=0)means.fit(X)
y_kmeans = kmeans.predict(X)n_init=10 : 반복의 횟수를 지정.
여기서 최고의 결과를 return하게 함.
이를 시각화하면 아래와 같이 클러스터링 된 모습을 볼 수 있다.
# 클러스터링 결과 시각화
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=20, cmap=plt.cm.Paired)
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5, marker='^')#센터에 삼각형 그리기.
plt.title("KMeans Clustering (k=4)")
plt.show()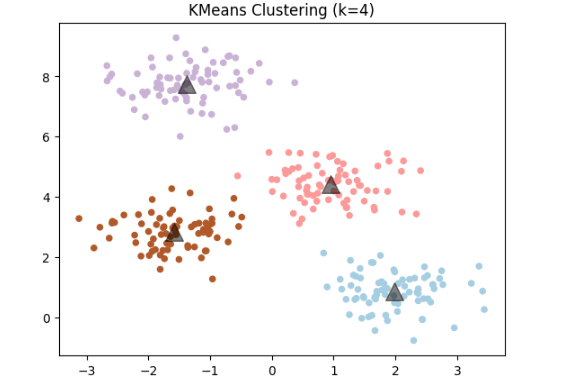
이번 데이터에서는 k값이 4개임이 확실히 보이기 때문에 k=4 로 지정해주었다.
하지만, 실제 데이터에서는 k값이 무분별하기 때문에 이를 따로 결정해줘야 되는데
이런 결정 방법 중 엘보우 메소드 라는 것이 있다.
엘보우 방법 (Elbow Method)
적절한 k를 논리적으로 결정할 수 있는 방법
앞서 예시에서 데이터가 잘 나뉘게 된 이유는 적절한 K를 선택했기때문이다.
- 만약 K가 너무 작다면
• 중요한 하위 그룹을 잘 포착하지 못할 수 있음
• 같은 클러스터 안에 서로 상당히 다른 데이터가 공존할 수 있음
• 유의미한 인사이트를 얻기 어려움 - 혹은 K가 너무 크다면
• 과적합 문제
• 해석의 어려움
• 효율성 저하
엘보우 방법 (Elbow Method) 실행 이론
클러스터 수를 늘려가며 각각에 대한 클러스터링 성능을 측정해, 클러스터 수에 따른 성능 변화를 분석
- 클러스터 수(K)는 일반적으로 극히 작은 값(1)에서부터 매우 큰 값까지 사용
• 사용하는 데이터의 수에 따라 매우 큰 K 값은 상이할 수 있음 - 클러스터링 성능은 비지도 학습이기 때문에 SSE(Sum of Squared Errors) 값을 활용
• SSE : 각 클러스터 내의 데이터 포인트와 클러스터 중심 간의 거리의 제곱 합
• 즉, 데이터 포인트가 클러스터 중심에 얼마나 가까운지를 나타냄 - 그래프 상 SSE의 감소율이 급격히 줄어드는 지점이 최적 클러스터 수(K)로 간주
• 이런 지점이 마치 팔꿈치 같다고 해서 엘보우(Elbow)라는 이름이 되었다고 한다!
바로 이지점!
SSE가 너무 낮다는 것은 모든 데이터 포인트가 클러스터링 된 것일 수 도 있기에 위의 지점을 사용하는 것이 바람직하다.
엘보우 방법 (Elbow Method) 실습
엘보우 방법으로 K 값을 구해보자
# 1~10 까지의 K를 설정하고 각 경우에 맞춰 학습을 진행
inertia = []
K_range = range(1, 10)
for k in K_range:
kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=0)
kmeans.fit(X)
inertia.append(kmeans.inertia_) # SSE 값을 저장이를 시각화하면 3~4에서 급격한 변화를 볼 수 있다.
plt.figure(figsize=(8, 4))
plt.plot(K_range, inertia, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method')
plt.show()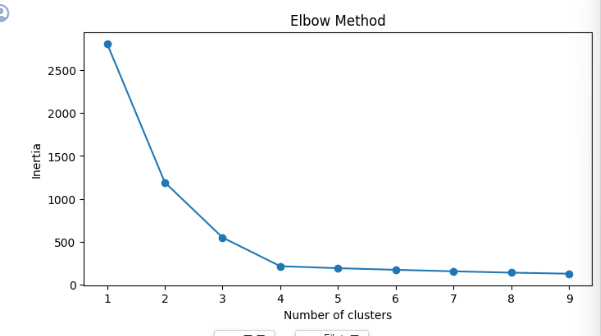
실루엣 계수(Silhouette Coefficient)
클러스터링은 비지도 학습으로 정답이 존재하지 않는 경우가 많아 성능을 측정하기 쉽지 않다.
하지만 이를 평가 할 수 있는 방법이 바로 실수엣 계수!
실루엣 계수란!
클러스터 안의 응집도와 서로 다른 클러스터 간의 분리도를 동시에 고려해 군집화의 품질을 평가하는 방법
• 이 값은 -1에서 +1 사이의 값을 가지며, 높은 값은 좋은 클러스터링을 의미함
- 응집도 (Cohesion) : a(i)
• 특정 데이터 i에 대해, 동일한 클러스터 안에 들어있는 다른 데이터들과의 평균 거리
• 클러스터 내부의 데이터가 얼마나 모여있는지를 나타냄
응집도는 작아야 좋다.(잘 모였다는 의미) - 분리도 (Separation) : b(i)
• 특정 데이터 i에 대해, i 가 들어있는 클러스터 말고, 다른 클러스터 중 가장 가까운 클러스터 중심까지 거리
• 다른 클러스터와 얼마나 떨어져 있는지를 나타냄
분리도는 커야 좋다.(잘 벌어졌다는 의미)

엘보우 방법에서 사용했던 데이터를 실루엣 계수로 나타내보면
from sklearn.metrics import silhouette_score
silhouette_avg = silhouette_score(X, y_kmeans)
print("Silhouette Score: {:.2f}".format(silhouette_avg))출력값 : Silhouette Score: 0.68
1과 가까우면 좋기에 0.7~0.8이면 아주 좋다고 함!
보통은 음수냐 양수냐로 판단한다고 한다.
숙제!

정답 :
