아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
WITH rare
AS (SELECT item_id
FROM item_info
WHERE rarity = 'RARE'),
upgraded
AS (SELECT it.item_id
FROM item_tree it
INNER JOIN rare
ON it.parent_item_id = rare.item_id)
SELECT upgraded.item_id,
ii.item_name,
ii.rarity
FROM upgraded
INNER JOIN item_info ii
ON upgraded.item_id = ii.item_id
ORDER BY 1 DESC문제 링크
lv4라고 되어있는 것 치고는 그렇게 어렵지는 않은 문제.
1세대, 2세대에 해당하는 id만 CTE로 정의해두면 3세대 id를 구하는 것도 간단하다.
다만 부모자식 관계를 한번에 쿼리로 나타내려고 하면
쿼리가 복잡하고 길어질 수도 있을 것 같은데,
(예를 들어 9세대, 10세대의 id를 뽑으라고 하면?)
이 문제는 나중에 다른 방법으로도 해결해 봐야겠다.
세대 수가 늘어나더라도 쿼리 한 번으로 예쁘게 끝낼 수 있을지.
WITH gen1
AS (SELECT id
FROM ecoli_data
WHERE parent_id IS NULL),
gen2
AS (SELECT e1.id
FROM ecoli_data e1
INNER JOIN gen1
ON e1.parent_id = gen1.id)
SELECT e2.id
FROM ecoli_data e2
INNER JOIN gen2
ON e2.parent_id = gen2.id 문제 링크
처음에 이렇게 풀었는데
테스트 케이스는 통과하고 제출 결과 오답이 떴다.
WITH result
AS (SELECT id,
size_of_colony,
100.0 * Percent_rank()
OVER (
ORDER BY size_of_colony DESC) AS PERCENT
FROM ecoli_data)
SELECT id,
CASE
WHEN percent BETWEEN 0 AND 25 THEN 'CRITICAL'
WHEN percent BETWEEN 26 AND 50 THEN 'HIGH'
WHEN percent BETWEEN 51 AND 75 THEN 'MEDIUM'
WHEN percent BETWEEN 76 AND 100 THEN 'LOW'
END AS COLONY_NAME
FROM result
ORDER BY 1 알고보니 25와 26 사이에 25.34 등의 값이 있을 수 있기 때문.
between이 직관적으로 이해하기 편해서
습관처럼 써 왔는데, 저런 케이스를 조심해야 할 것 같다.
아래는 수정한 정답 쿼리.
WITH result
AS (SELECT id,
size_of_colony,
100.0 * Percent_rank()
OVER (
ORDER BY size_of_colony DESC) AS PERCENT
FROM ecoli_data)
SELECT id,
CASE
WHEN percent < 25 THEN 'CRITICAL'
WHEN percent < 50 THEN 'HIGH'
WHEN percent < 75 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM result
ORDER BY 1;between을 쓸 때 조건이 촘촘하게 걸려있는지,
처리하지 못하는 예외 케이스가 발생할 수 있는지 다시 한 번 생각할 것.
SELECT id,
email,
first_name,
last_name
FROM developers
WHERE skill_code & (SELECT code
FROM skillcodes
WHERE name = 'Python')
OR skill_code & (SELECT code
FROM skillcodes
WHERE name = 'C#')
ORDER BY 1 lv2였지만 체감 난이도는 오히려 이 쪽이 더 높았다ㅎㅎ
이 문제를 푸느라 & 연산자를 처음으로 써 보게 됐는데,
2진수 기준으로 포함 여부를 확인해 주는 연산자라고 한다.
이 문제에서 where 절 이하는
developers 테이블의 skill_code와 skillcodes 테이블의 code(파이썬,C#)를
2진수 기준으로 비교한다는 뜻이다.
예를 들어, skillcodes 테이블에서 파이썬의 코드가 256이면
2진수 기준으로는 100000000이고
어떤 개발자의 skill_code가 400이면
2진수 기준으로는 110010000이므로,
& 연산자를 쓰면 100000000이 110010000안에 포함된다는 계산을 할 수 있는 것.
(110010000 = 100000000 + 10000000 + 10000이니까)
신기한 개념이긴 했는데 이 연산자를 또 마주칠 일이 있을까 싶긴 하다.
그래도 몰랐던 거니까 한 번은 정리하고 넘어가기로.
WITH max_size
AS (SELECT Max(size_of_colony) AS max,
Year(differentiation_date) AS year
FROM ecoli_data
GROUP BY 2)
SELECT Year(e.differentiation_date) AS YEAR,
max - size_of_colony AS YEAR_DEV,
e.id
FROM ecoli_data e
INNER JOIN max_size
ON Year(e.differentiation_date) = max_size.year
ORDER BY 1,
2 이걸로 프로그래머스도 5문제 남았다.
내일이면 끝날 듯!
클러스터링 프로젝트
🌺 데이터셋은 총 5개의 CSV 파일로 구성되어 있습니다.
- Retail_dataset.csv 파일에 ERD(테이블 구조도) 및 컬럼 설명이 기재되어 있습니다.
🌺 각 테이블을 결합하여, 클러스터링을 위한 하나의 데이터셋으로 만들어주세요.
- 모든 테이블을 결합하지 않아도 좋습니다.
- 다만, 테이블 결합 시 알맞은 결합 방식을 사용해주세요.
🌺 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🌺 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 으로 리포트를 구현해주세요.
2. EDA
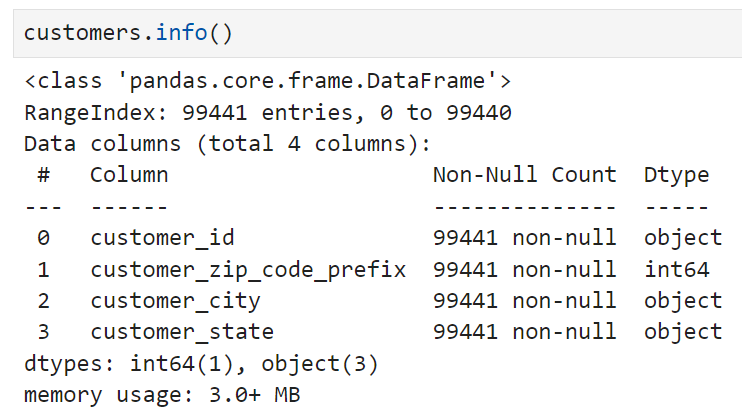
오늘은 어제 완성했던 merge2와 customers 테이블을 합치는 작업을 이어서 진행했다. merge2와 customers 테이블의 상태를 다시 체크해 보면,
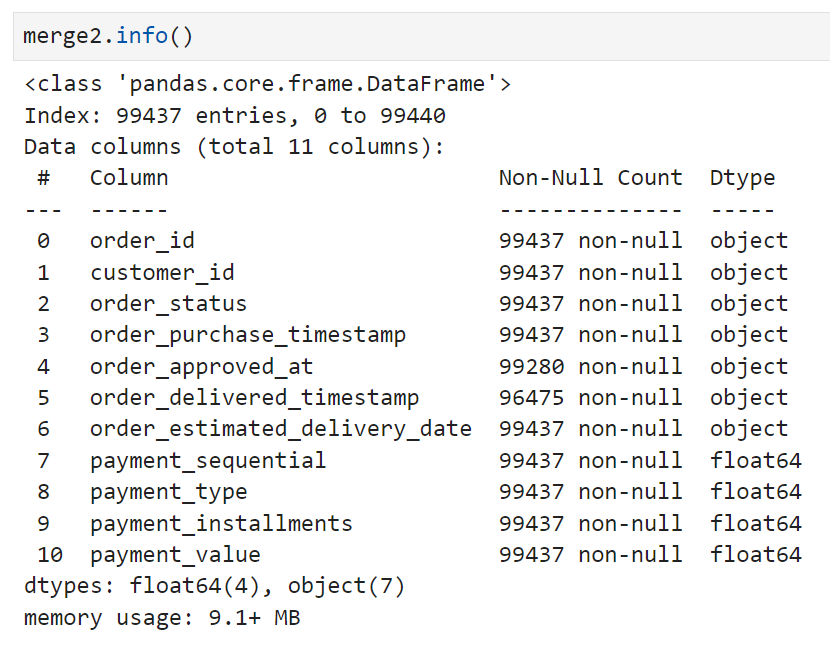
merge2에는 어제 확인했던 대로 결측치가 일부 존재하고,
customers 테이블에는 결측치가 없다. customers 테이블의 row 수가 99,441로 merge2보다 4개 더 많은 것을 보면 어제 삭제했던 취소주문 건수에 딸린 것일 가능성이 높아 보인다.
이 두 테이블의 공통 키는 customer_id이고, 이번에는 바로 inner join을 수행하기로 했다.

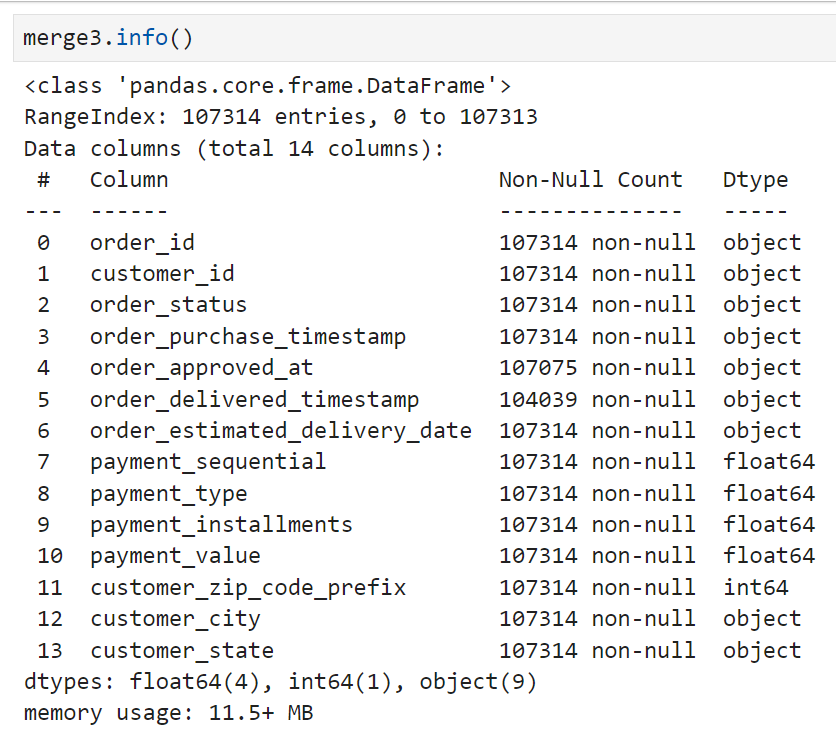
완료된 merge3의 row수는 107,314개.
기준이 됐던 테이블인 merge2보다 약 8,000개 정도가 더 늘어났다. inner join의 결과가 원래의 데이터프레임보다 커지는 것이 이해하기 어려워서 customers 테이블의 상태부터 확인해 보기로 했다.
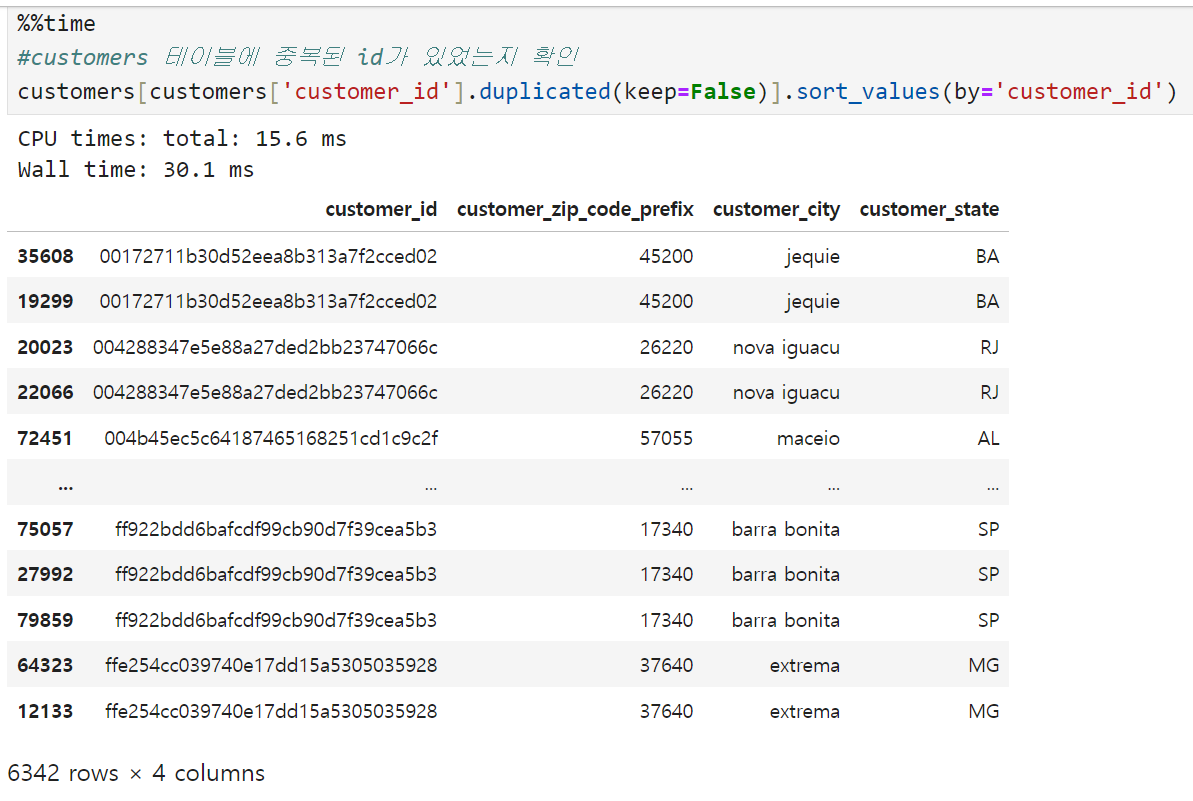
확인 결과 customers 테이블에 동일한 customer_id를 가진 고객이 여러 건 들어가 있는 것으로 나타났다. 이미지상으로는 한 id당 2번~3번 정도 중복되는 경우가 있는 것 같은데, 좀 더 자세히 뜯어보자.
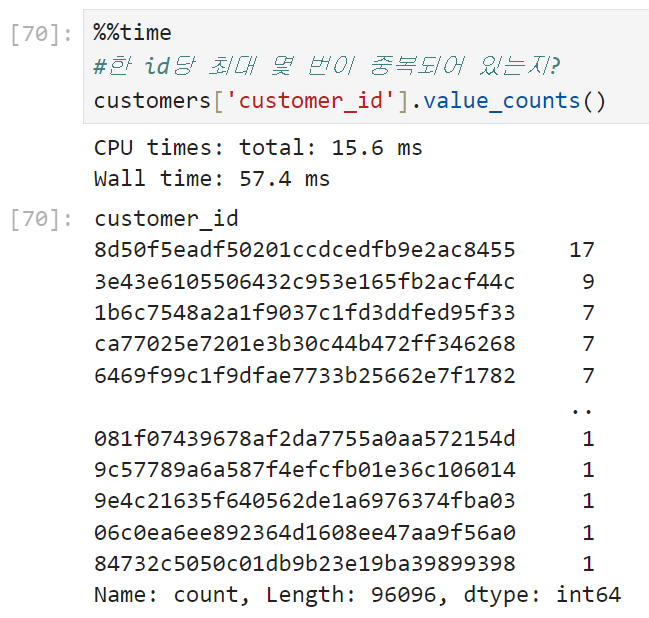
하나의 customer_id당 최대 17개의 중복된 값들이 customers 테이블에 들어가 있다. 우선 같은 customer_id를 가진 고객이 도중에 이사를 하거나 해서 주소지가 변경되는 경우도 있을 수 있으므로,
- 같은 customer_id가 2건 이상 customers 테이블에 존재하는 경우에 한하여
- customer_id를 제외한 나머지 컬럼들이 변경되는 경우가 있는지
를 알아보기로 했다.
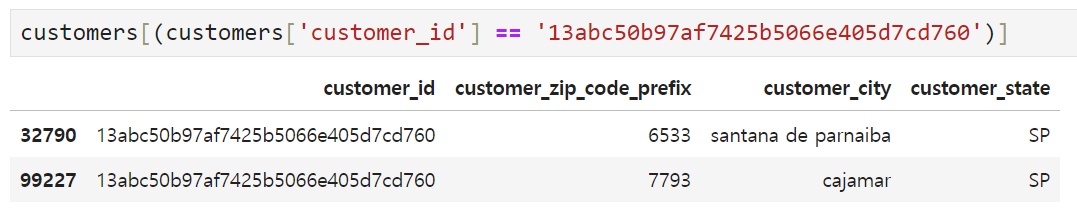
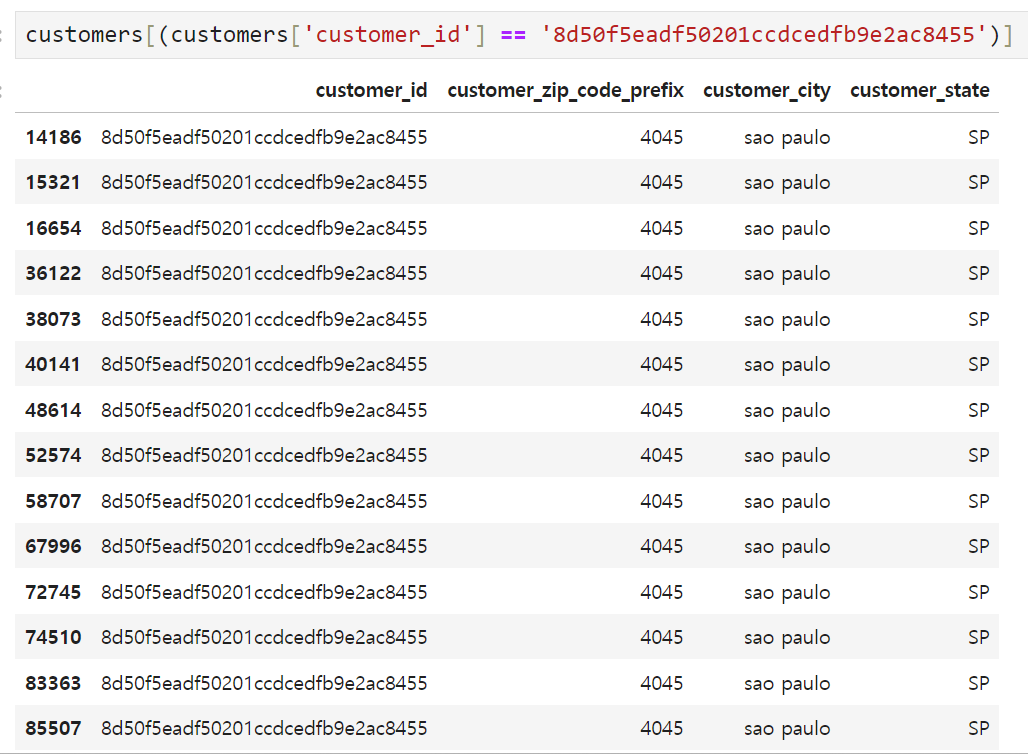
위의 사례처럼 동일한 customer_id를 갖고 있으나 주소지가 변경되어 customer_zip_code_prefix와 customer_city가 달라지는 경우가 있는가 하면(이미지 위), 아무런 변동사항이 없는데도 17건이나 동일한 고객정보가 중복되는 경우도 있었다(이미지 아래). 따라서, 우선 합치기 전에 customers 테이블을 아래와 같이 정리해 보기로 했다.
- customer_id, customer_zip_code_prefix, customer_city, customer_state가 모두 같은 경우는 대표로 한 개의 row만 남기고 모두 정리한다.
- 위의 4개 컬럼 중 어느 하나라도 달라지는 경우는 (군집화의 feature 중 하나로 쓰일 수도 있으므로) 고유값을 유지시킨다.
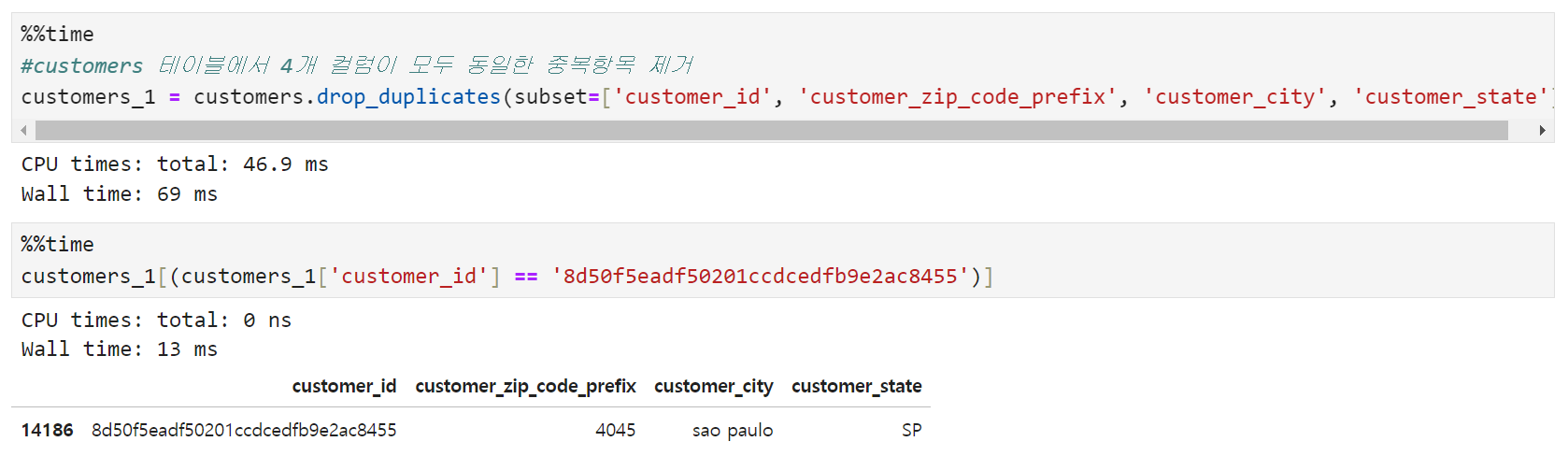
실행 결과 위에서 17건 중복되어 있던 customer_id 8d50f5eadf50201ccdcedfb9e2ac8455 는 1개 행만 남기고 정리되었다.
다만 이 조건을 적용해서 customers 테이블을 정리한다 해도, 동일한 customer_id를 쓰더라도 주소지가 바뀌게 되면 살려두기로 했으므로 어느 정도 중복된 customer_id가 살아있게 되는 것은 불가피하다.
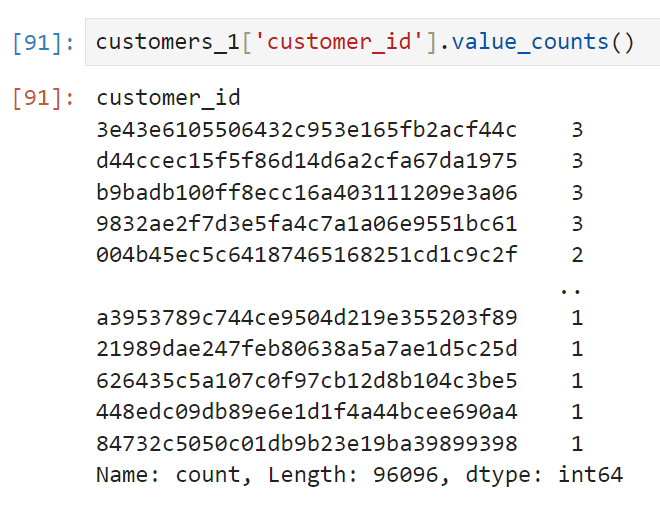
그래도 customers 테이블에 중복된 customer_id가 8~9개, 많게는 17건씩 들어가 있던 상황에 비하면 많이 정리되었다.
정리한 customer_1을 merge2와 다시 join시켜 보았다.
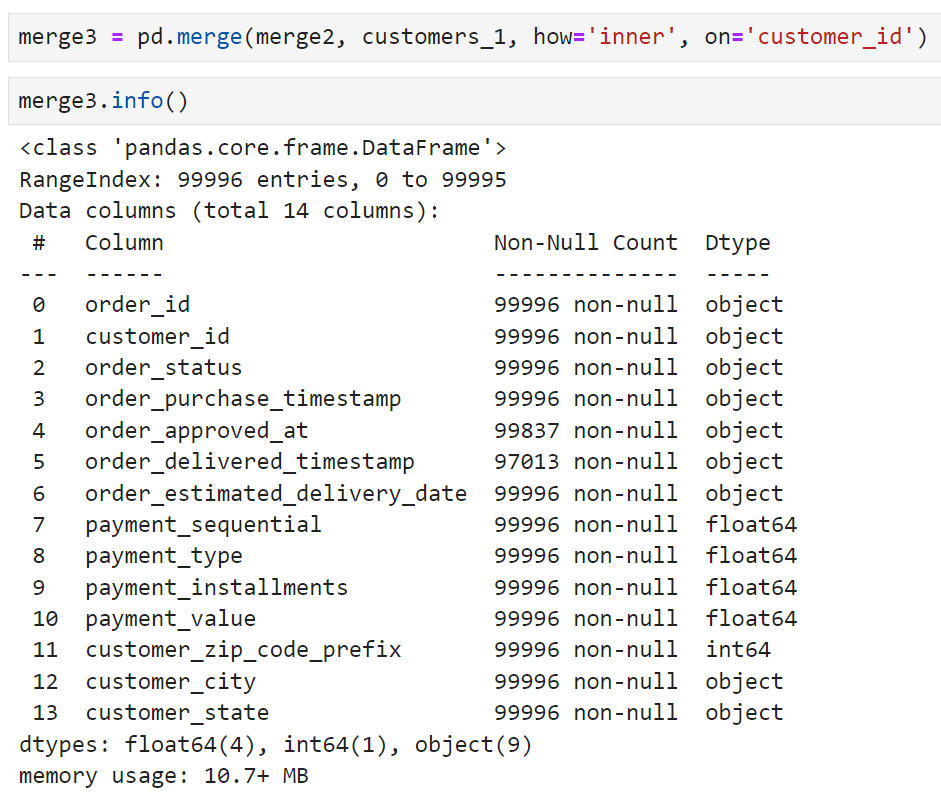
처음 join시켰을 때 107,314개가 나왔던 상황과 비교하면
그래도 어느 정도 정리가 된 것 같다. merge3에도 중복값들이 많이 들어가있을 것 같아서 order_id, customer_id 기준으로 확인해 보기로 했다.
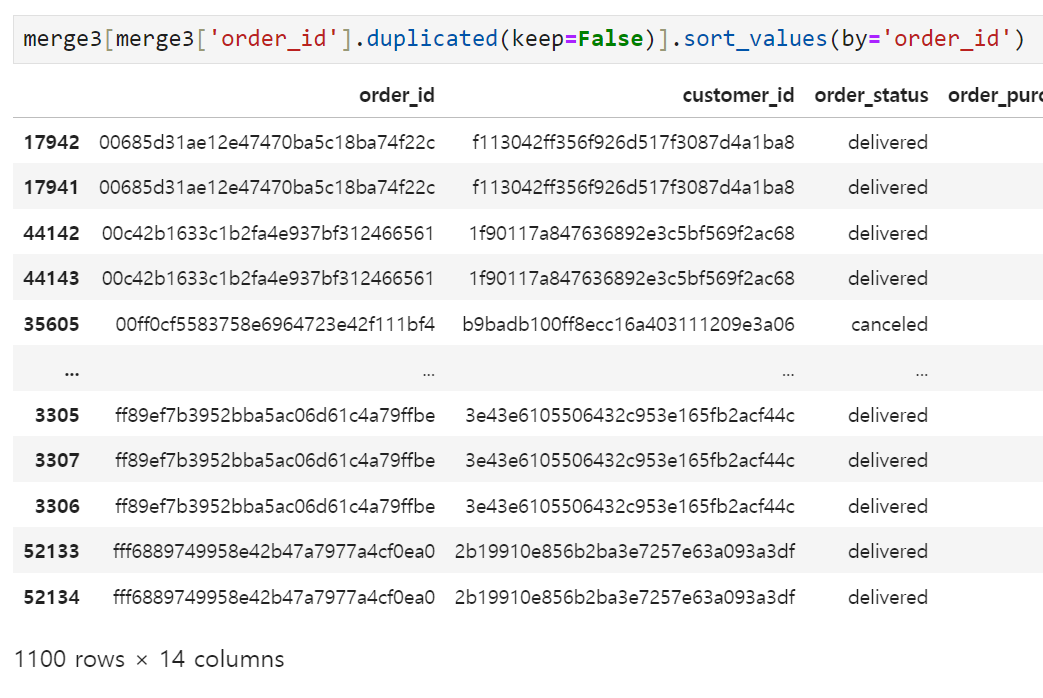
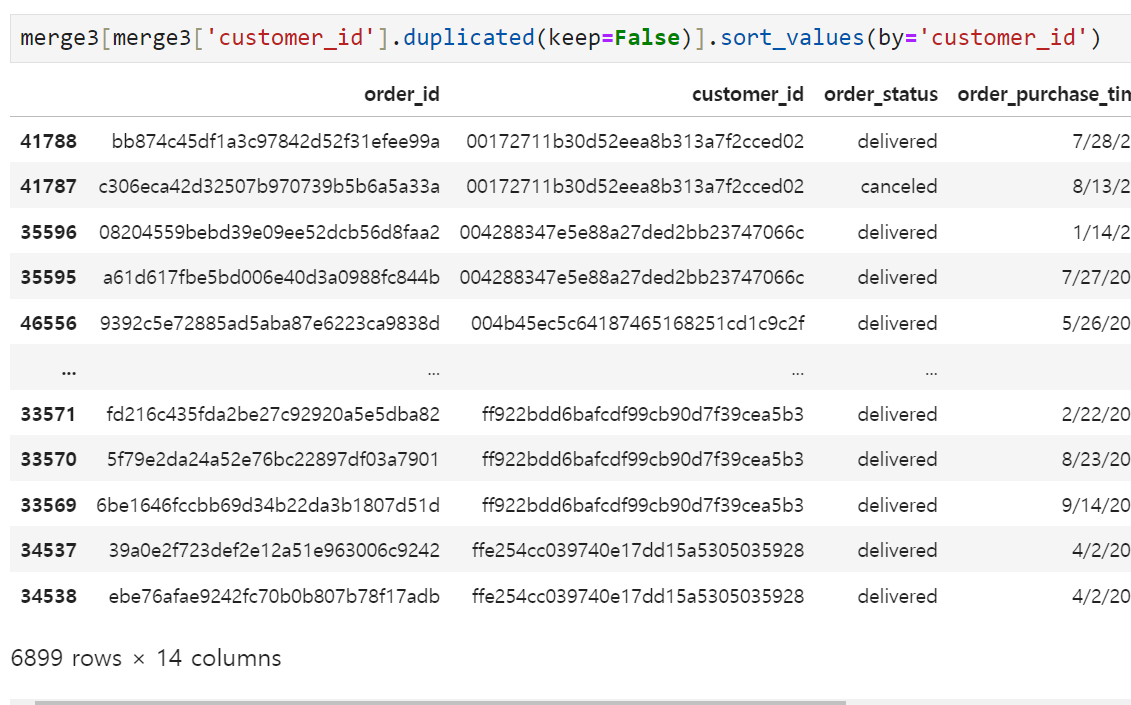
여기서 고민해봐야 할 지점은
- 하나의 customer_id를 가진 사람이 여러 번을 구매하는(재구매) 경우가 있을 수 있음 → 중요한 구매지표라 버리지 말고 가져가야 함
- payment 테이블을 합치는 과정에서 payment_value를 order_id 기준으로 합쳤는데, 이게 다시 고객 데이터와 합쳐지면서 값이 중복으로 들어가는 경우가 생겼다는 점. 매출액이 뻥튀기 될 위험이 있어서 이걸 어떻게 처리할지도 생각해 봐야 한다.
ERD 기준으로
- products와 order_items 합치기(merge1)
- orders와 payments 합치기(merge2)
- merge2와 customers 합치기(merge3)
까지 완료되었으므로, 이제 merge1과 merge3를 합칠 차례다. 합치기 전에 두 테이블의 컨디션부터 확인해 보기로 했다.
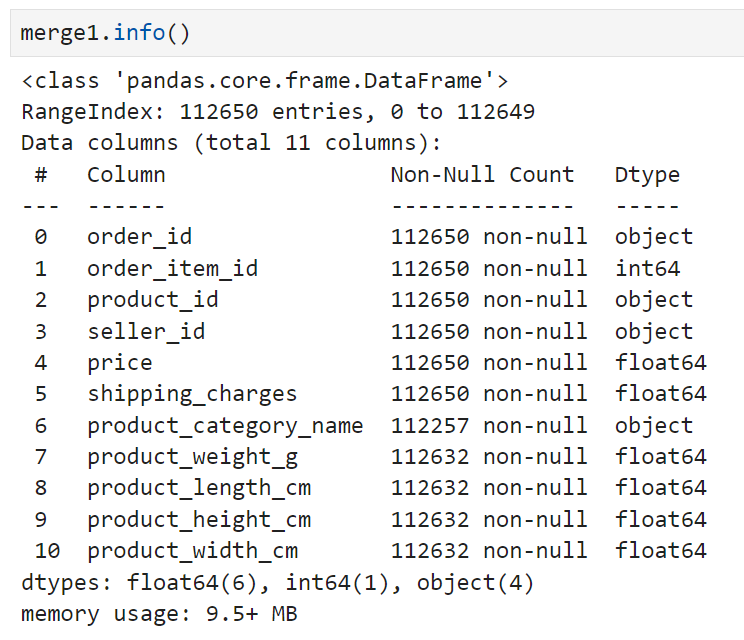
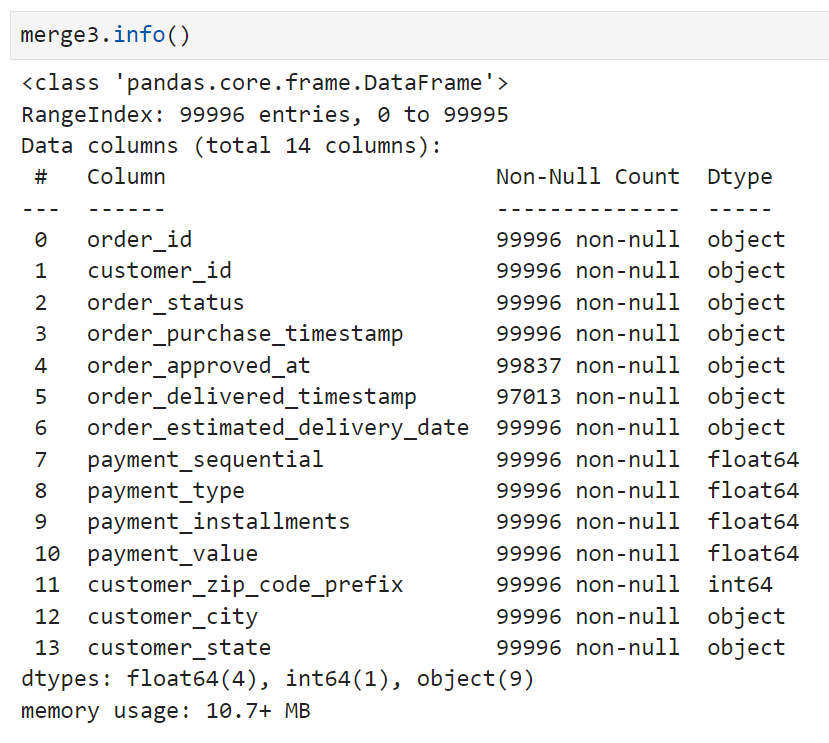
확인 결과 merge1의 row 수가 더 많았다. 우선 이렇게 차이가 크게 나는 이유를 확인해 봐야 하므로, merge1을 기준으로 merge3을 left join하되 key값은 order_id로 설정하도록 했다.
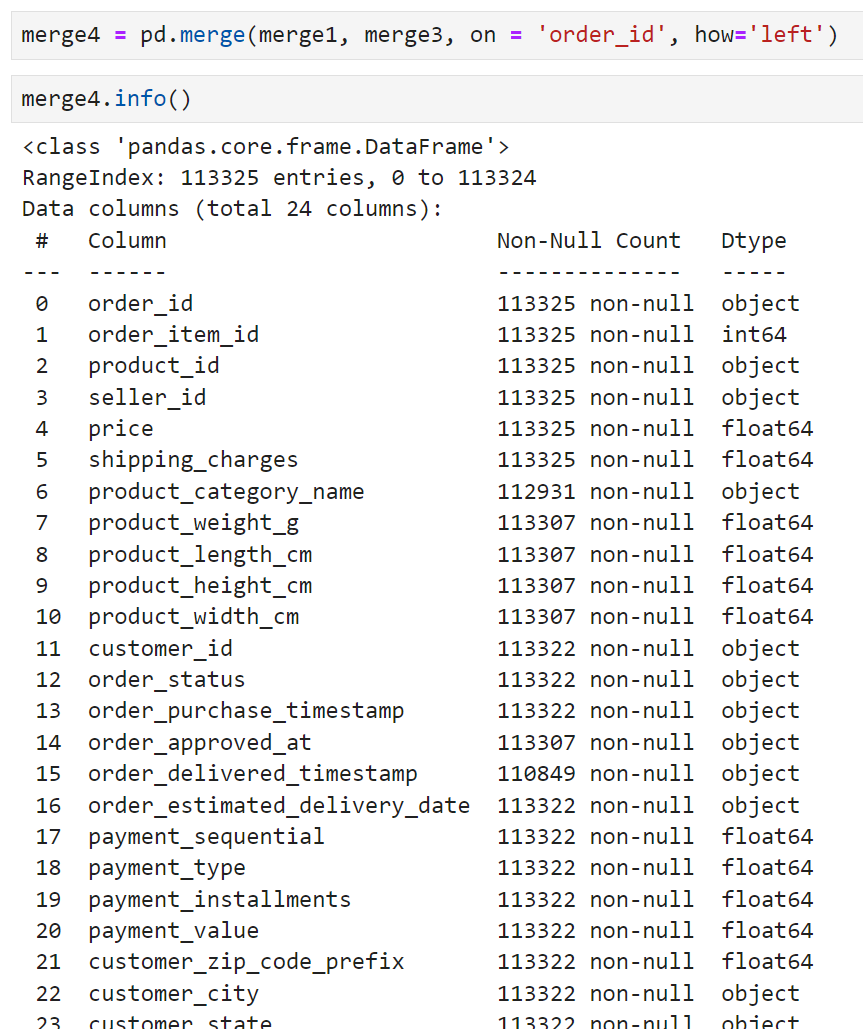
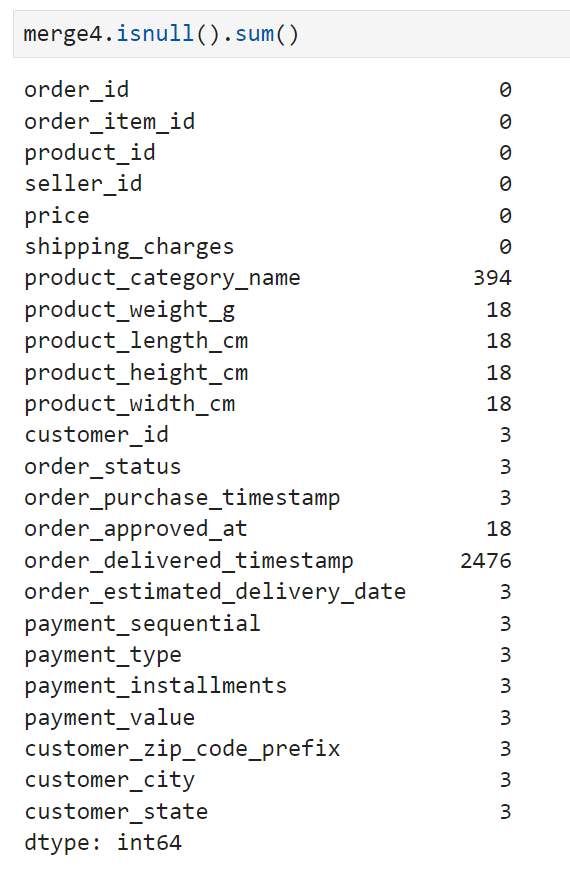
113,325의 row를 가진 merge4가 완성되었고, customer_id와 매칭되지 않는 값들이 있는 건지 customer_id를 붙인 쪽으로 3개의 null값이 확인되었다.
내일은 이 테이블이 만들어지기까지의 과정을 복기하면서
이상한 부분이 없었는지 점검하고(SQL로 할 예정)
각 변수들간의 상관관계 확인을 포함한 EDA와 시각화를 마무리해 볼 생각이다.
