아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
오늘은 비트 연산과 대장균 파티🧬
문제 링크
어제에 이어 오늘도 비트 연산.
비트 연산이 중요한가?🤔
SELECT Count(id) AS COUNT
FROM ecoli_data
WHERE genotype & 2 = 0
AND ( genotype & 1 > 0
OR genotype & 4 > 0 ) 문제 링크
이것도 대장균 & 비트 연산;;
얘네들 비트 연산에 진심이네..
SELECT ED.id,
ED.genotype,
ED2.genotype AS PARENT_GENOTYPE
FROM ecoli_data ED
INNER JOIN ecoli_data ED2
ON ED2.id = ED.parent_id
WHERE ED.genotype & ED2.genotype = ED2.genotype
ORDER BY ED.id ASCSELECT ( CASE
WHEN ( skill_code & (SELECT Sum(code)
FROM skillcodes
WHERE category LIKE 'FRONT%') )
AND skill_code & (SELECT code
FROM skillcodes
WHERE name = 'PYTHON') THEN 'A'
WHEN skill_code & (SELECT code
FROM skillcodes
WHERE name = 'C#') THEN 'B'
WHEN skill_code & (SELECT Sum(code)
FROM skillcodes
WHERE category LIKE 'FRONT%') THEN 'C'
ELSE NULL
end ) AS GRADE,
id,
email
FROM developers
GROUP BY grade,
id,
email
HAVING grade IS NOT NULL
ORDER BY grade,
idSELECT id,
email,
first_name,
last_name
FROM developers d
WHERE skill_code & (SELECT Sum(code)
FROM skillcodes
WHERE category = 'Front End'
GROUP BY category)
ORDER BY 1문제 링크
멸종 위기(!)의 대장균을 찾는 문제.
각 세대별로 자식이 없는 대장균을 찾아야 한다.
모든 세대에 자식이 없는 대장균이 적어도 한 개체는 존재한다는 것이 힌트.
아래는 결과는 맞게 나왔지만 제출 결과 오답이 떴던 쿼리.
WITH gen1
AS (SELECT id
FROM ecoli_data
WHERE parent_id IS NULL),
gen2
AS (SELECT e1.id
FROM ecoli_data e1
INNER JOIN gen1
ON e1.parent_id = gen1.id),
gen3
AS (SELECT e2.id
FROM ecoli_data e2
INNER JOIN gen2
ON e2.parent_id = gen2.id),
result
AS (SELECT e1.id
FROM ecoli_data e1
LEFT JOIN ecoli_data e2
ON e1.id = e2.parent_id
WHERE e2.id IS NULL)
SELECT Count(result.id) AS COUNT,
CASE
WHEN gen1.id IS NOT NULL THEN '1'
WHEN gen1.id IS NULL
AND gen2.id IS NOT NULL THEN '2'
WHEN gen1.id IS NULL
AND gen2.id IS NULL
AND gen3.id IS NOT NULL THEN '3'
ELSE '4'
END AS GENERATION
FROM result
LEFT JOIN gen1
ON result.id = gen1.id
LEFT JOIN gen2
ON result.id = gen2.id
LEFT JOIN gen3
ON result.id = gen3.id
GROUP BY 2
ORDER BY 2 어제 문제를 풀며 들었던 우려가 오늘 곧바로 현실이 됐다ㅎㅎ
모든 테스트 케이스에 3세대까지만 있는 게 아니라서,
저런 식으로 CTE를 하나씩 만들다가는 한이 없게 되는 문제가 생긴다.
결국 이 문제를 풀려면 재귀쿼리를 써서
세대를 연속해서 생성하는 CTE를 정의하고
그 CTE를 갖고 본 쿼리를 써서 풀어야 한다.
아래는 정답 쿼리.
WITH recursive gen
AS
(
SELECT d.id ,
parent_id ,
1 AS generation
FROM ecoli_data d
WHERE parent_id IS NULL
UNION ALL
SELECT d.id ,
d.parent_id ,
generation + 1
FROM ecoli_data d
INNER JOIN gen
ON gen.id = d.parent_id )
SELECT count(*) AS count ,
g1.generation
FROM gen g1
LEFT JOIN gen g2
ON g1.id = g2.parent_id
WHERE g2.id IS NULL
GROUP BY 2
ORDER BY 2;이 문제는 나중에 꼭 다시 풀어봐야겠다.
재귀쿼리를 써서 CTE를 생성할 때 참고하면 좋을 예전 문제풀이 (WITH RECURSIVE)
링크 1
링크 2
오늘을 끝으로 프로그래머스에는 더 이상 안 푼 SQL 문제가 없게 됐다.
내일부터는 다른 사이트로 옮겨가야지.
클러스터링 프로젝트
🌺 데이터셋은 총 5개의 CSV 파일로 구성되어 있습니다.
- Retail_dataset.csv 파일에 ERD(테이블 구조도) 및 컬럼 설명이 기재되어 있습니다.
🌺 각 테이블을 결합하여, 클러스터링을 위한 하나의 데이터셋으로 만들어주세요.
- 모든 테이블을 결합하지 않아도 좋습니다.
- 다만, 테이블 결합 시 알맞은 결합 방식을 사용해주세요.
🌺 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🌺 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 으로 리포트를 구현해주세요.
2. EDA
오늘은 어제까지 판다스를 써서 수행했던 EDA를 SQL로 간단히 복기만 해 볼 예정이다.
원래 merge4의 상관관계 확인까지 진행해 보려 했는데,
태블로 강의 수강과 컨디션 저하가 맞물려서 거기까진 진도를 못 나갈 듯.
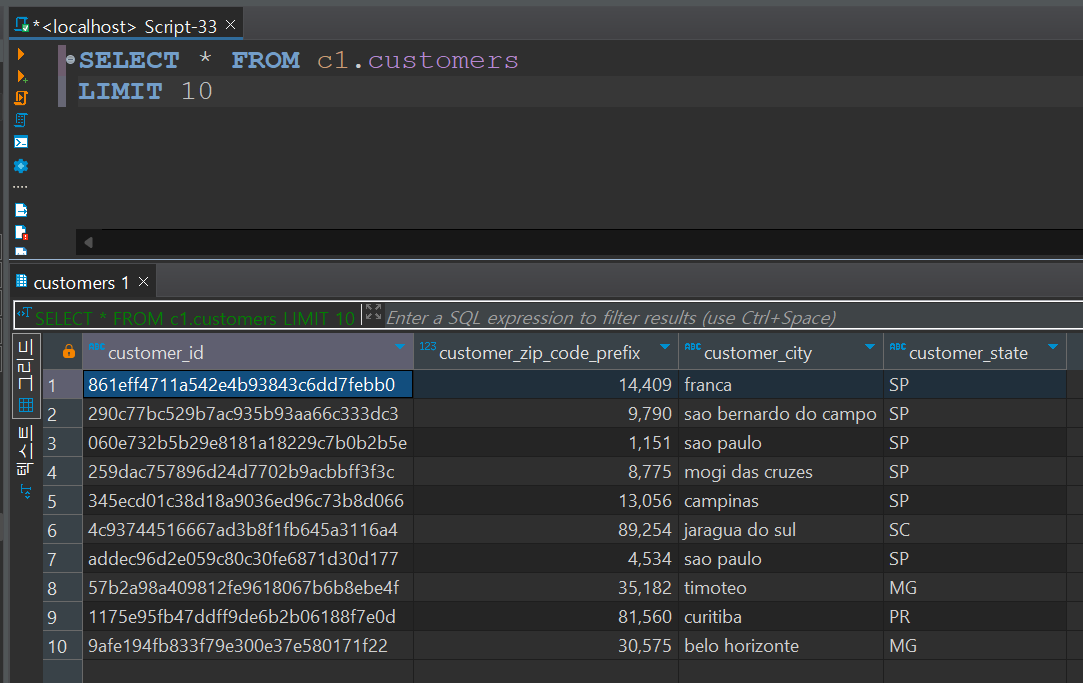
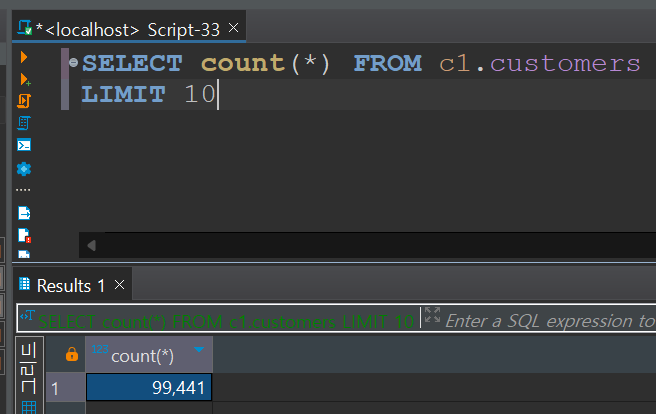
먼저 customers 테이블. 99,441개의 row와 데이터가 잘 들어와 있다.
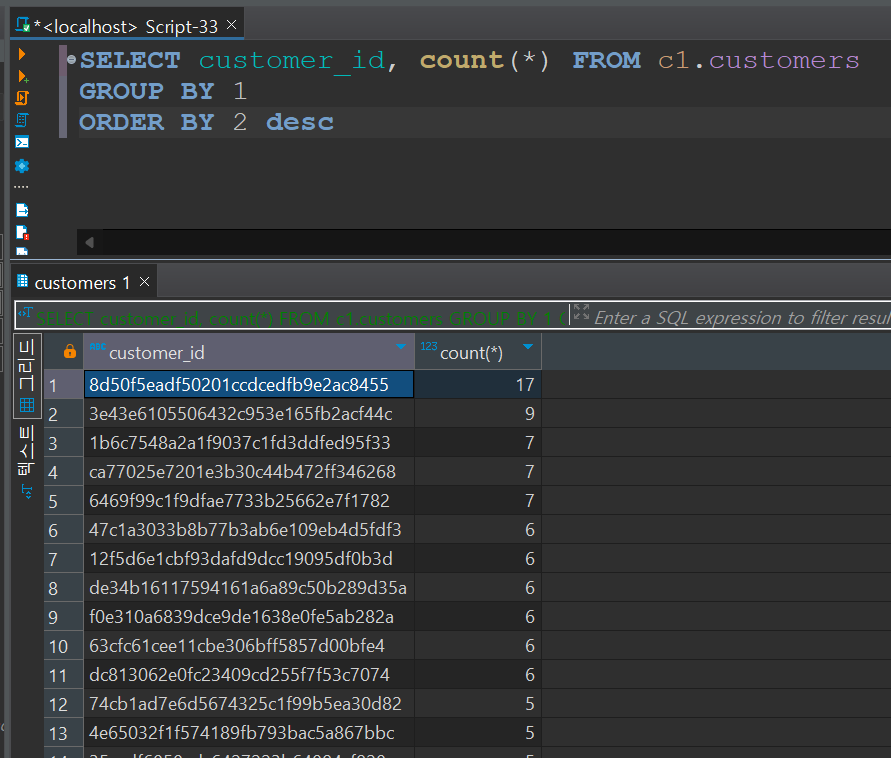
id에 중복이 허용된 갯수.
17건, 9건, 7건 등 판다스로 조회했을 때도 문제가 될 것 같은 것들이 있다.
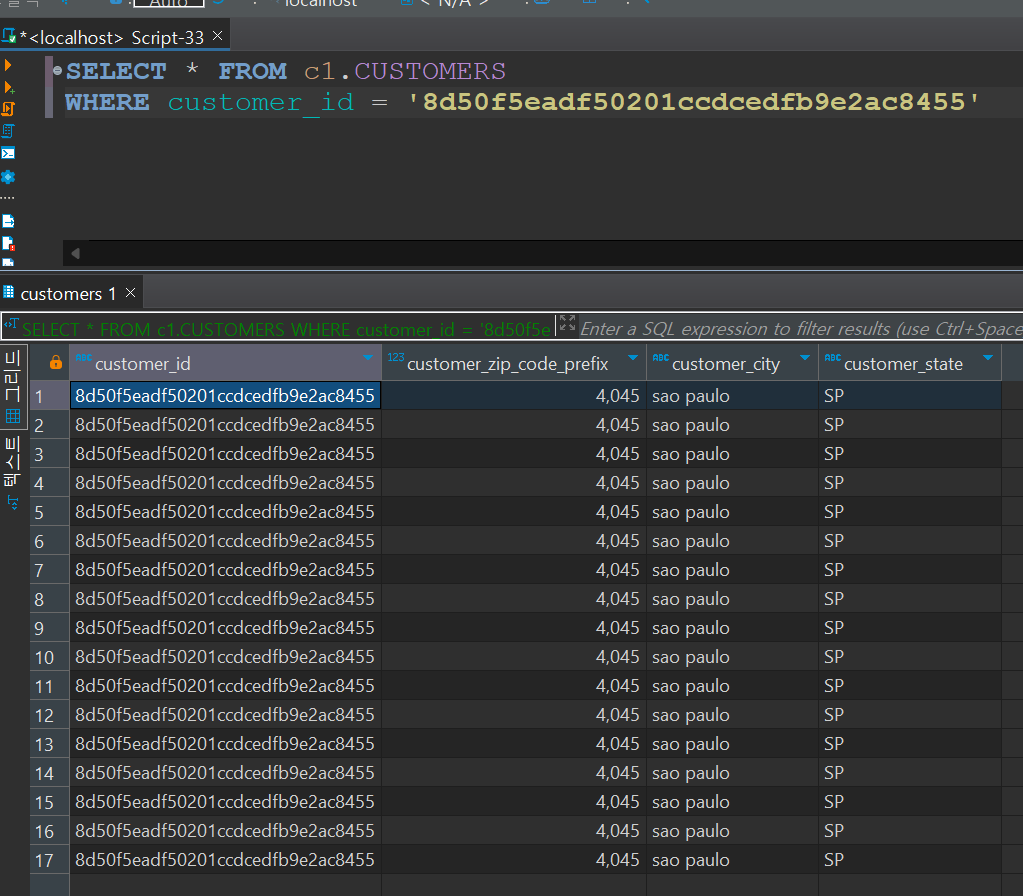
이런 케이스는 하나만 남기고 전부 버려줄 예정.
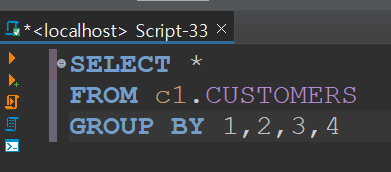
중복되는 케이스들도 sql에서는 좀 더 간단히 조회할 수 있는 것 같다.
이제 판다스를 써서 데이터셋을 만들었던 것과 동일한 순서로 진행해 봤다.
- payments 테이블 정리
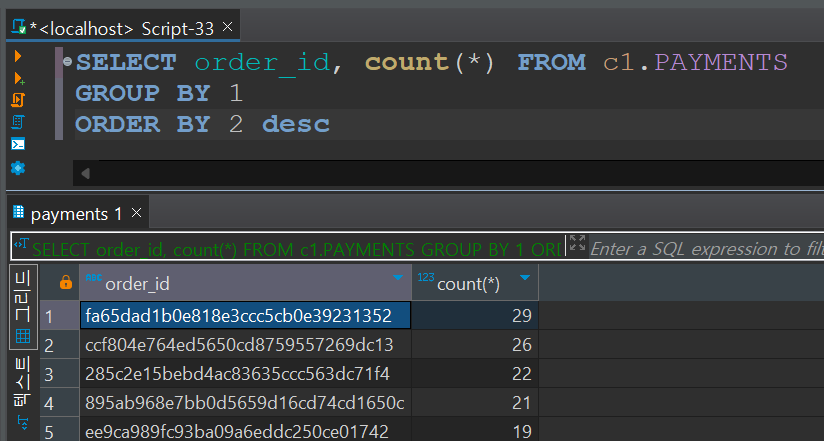
한 order_id에 중복되는 행들이 많다.
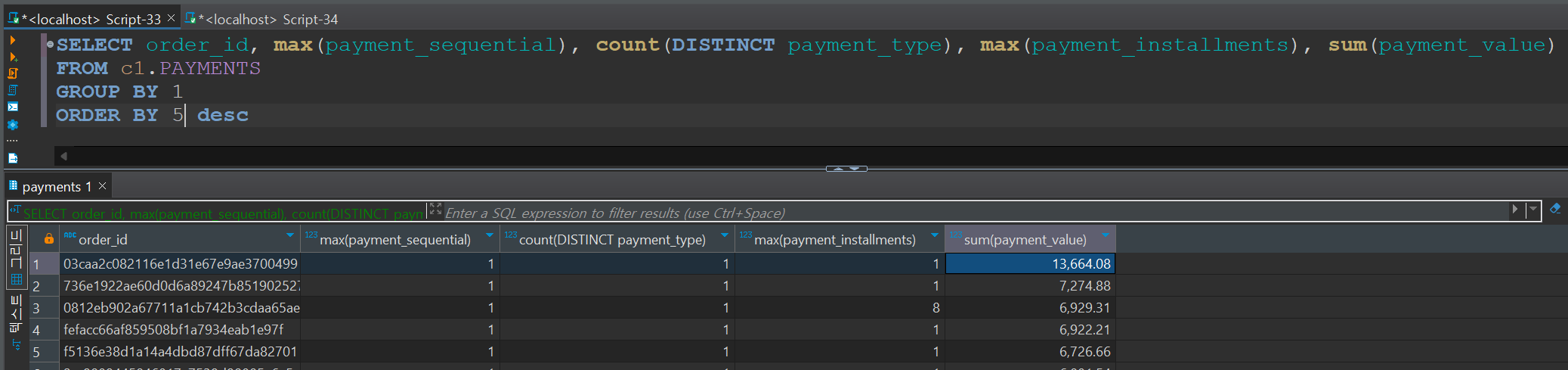
order_id별로 정리해 주었다. - 정리한 payments 테이블과 orders 테이블 합치기
- payments와 orders를 합친 결과(merge2)와 customers 정리해서 합치기(merge3)
WITH payments_grouped AS (
SELECT
order_id,
MAX(payment_sequential) AS max_payment_sequential,
COUNT(DISTINCT payment_type) AS payment_type_count,
MAX(payment_installments) AS max_payment_installments,
SUM(payment_value) AS total_payment_value
FROM
c1.PAYMENTS
WHERE
payment_type <> 'not_defined'
GROUP BY
order_id
),
merge2 AS (
SELECT
o.order_id,
o.customer_id,
o.order_status,
o.order_purchase_timestamp,
o.order_approved_at,
o.order_delivered_timestamp,
o.order_estimated_delivery_date,
pg.max_payment_sequential,
pg.payment_type_count,
pg.max_payment_installments,
pg.total_payment_value
FROM
c1.orders o
INNER JOIN payments_grouped pg ON
o.ORDER_ID = pg.order_id
),
customers_1 AS (
SELECT
customer_id,
customer_zip_code_prefix,
customer_city,
customer_state
FROM
c1.customers
GROUP BY
customer_id,
customer_zip_code_prefix,
customer_city,
customer_state
)
SELECT
m.order_id,
m.customer_id,
m.order_status,
m.order_purchase_timestamp,
m.order_approved_at,
m.order_delivered_timestamp,
m.order_estimated_delivery_date,
m.max_payment_sequential AS payment_sequential,
m.payment_type_count AS payment_type,
m.max_payment_installments AS payment_installments,
m.total_payment_value AS payment_value,
c.customer_zip_code_prefix,
c.customer_city,
c.customer_state
FROM
merge2 m
INNER JOIN customers_1 c ON
m.customer_id = c.customer_id;99,996개의 row를 가진 merge3까지 정상적으로 출력되었다.
내일 이어서 나머지 order_item과 products를 합친 결과(merge1)가 정상적으로 만들어지는지 체크해 보고 merge3와 합쳐서 merge4까지의 결과를 만들어보기로 했다.
