아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
오늘부터는 leetcode에서 아직 안 풀었던 문제 풀기
5문제 풀이 완료 / 난이도 medium에서도 10분 이상 걸린 경우는 없었음
SELECT p.firstname,
p.lastname,
a.city,
a.state
FROM person p
LEFT JOIN address a
ON p.personid = a.personid;WITH result
AS (SELECT score,
Dense_rank()
OVER (
ORDER BY score DESC) AS ranking
FROM scores)
SELECT score,
ranking AS 'rank'
FROM result
ORDER BY 1 DESC;SELECT e1.name AS Employee
FROM employee e1
INNER JOIN employee e2
ON e1.managerid = e2.id
WHERE e1.salary > e2.salary;WITH result
AS (SELECT d.NAME Department,
e.NAME Employee,
e.salary,
Dense_rank()
OVER(
partition BY d.NAME
ORDER BY salary DESC) AS ranking
FROM employee e
INNER JOIN department d
ON e.departmentid = d.id)
SELECT department,
employee,
salary
FROM result
WHERE ranking = '1';WITH result
AS (SELECT email,
Count(*) AS cnt
FROM person
GROUP BY 1)
SELECT email
FROM result
WHERE cnt >= '2';클러스터링 프로젝트
🌺 데이터셋은 총 5개의 CSV 파일로 구성되어 있습니다.
- Retail_dataset.csv 파일에 ERD(테이블 구조도) 및 컬럼 설명이 기재되어 있습니다.
🌺 각 테이블을 결합하여, 클러스터링을 위한 하나의 데이터셋으로 만들어주세요.
- 모든 테이블을 결합하지 않아도 좋습니다.
- 다만, 테이블 결합 시 알맞은 결합 방식을 사용해주세요.
🌺 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🌺 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 으로 리포트를 구현해주세요.
2. EDA
어제에 이어 추가로 merge4까지 만들었는데,
sql 환경에서는 10만행을 넘어가는 연산을 하려니 느려서 안 되는 문제가 있었다.
아쉽지만 sql은 1만 row 내외의 작은 데이터를 다룰 때만 쓰기로 하고ㅠㅜ
추가적인 EDA와 전처리는 판다스에서 마저 이어서 진행하기로 했다.
merge4를 만들기까지의 과정을 복기하면서 발견한
전처리 과정에서 생각해야 할 포인트
- order_items 테이블에도 중복되는 order_id가 다수 있다.
- 2 이상의 order_item_id를 갖고 있는 order_id의 경우에서, 모든 컬럼의 값이 동일한 케이스가 있음
- 그런데 payments의 payment_value와 대조해 보면, 모든 price와 shipping_charges를 합친 값이 payment_value임을 알 수 있음
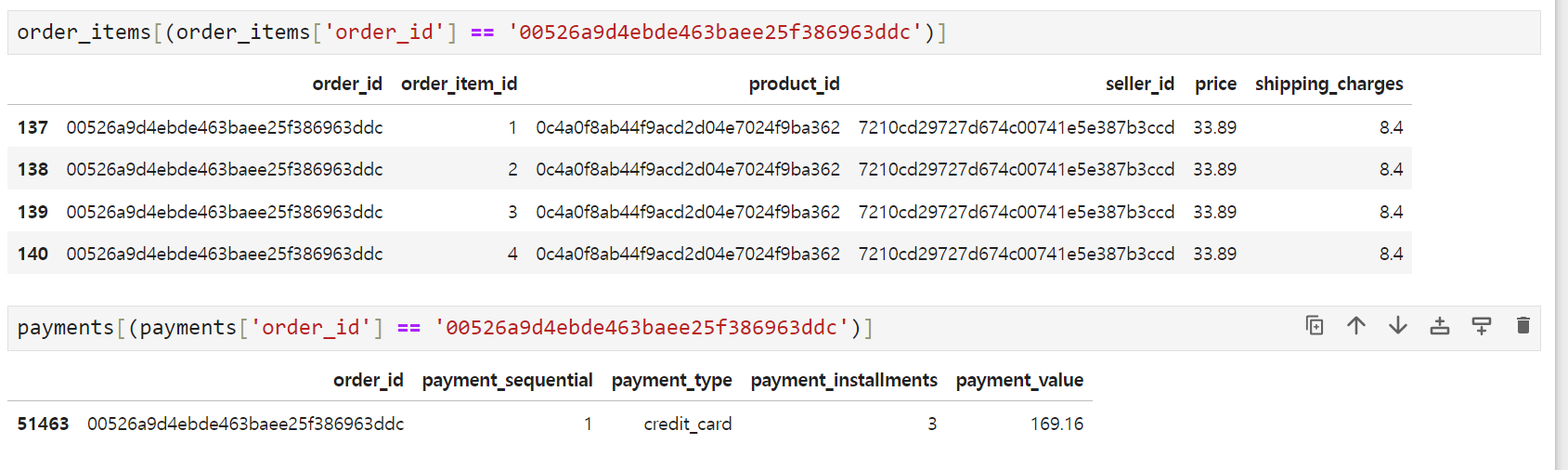
- 즉, order_item_id는 총 구매 갯수라고 볼 수 있음 (상품가격 33.89, 배송비 8.4짜리 상품을 4개 주문함 → 169.16 청구)
- 그런데 하나의 seller_id로부터 2개 이상의 서로 다른 product_id를 주문하는 경우도 있을 수 있음
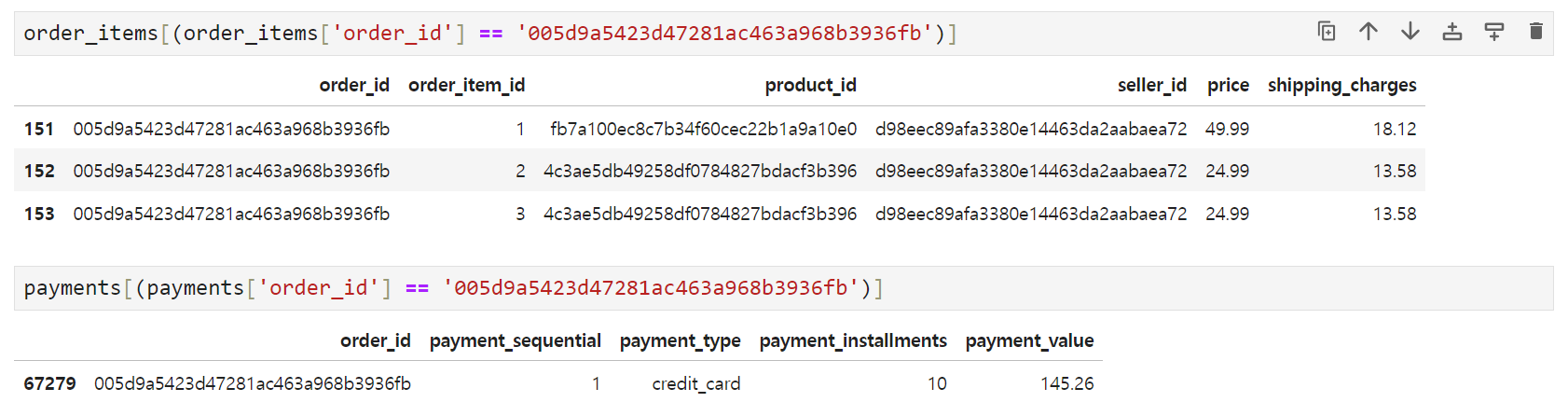
- 우선 merge4에는 빠진 값들이 없긴 함
- 한번에 깔끔하게 합칠 방법은 없을 것 같아 merge4 상태에서 전처리를 어떻게 할지를 고민해야 할 듯
오늘은 여기까지만..!

기본기를 소홀히 하지 말자