7.2.5 이산화
종종 연속되는 데이터들을 개별로 분할하거나
분석을 위해 그룹으로 나누기도 한다.
아래와 같이 수업에 참여하는 학생 그룹 데이터가 있고,
나잇대에 따라 분류하는 상황이라고 가정해 보자.

이 때, 판다스의 cut 함수를 써서
원하는 나잇대별로 나눌 수 있다.


여기서 반환된 categories라는 객체는
범주형(Categorical)이라는 특수한 객체다.
이 결과는 pandas.cut으로 계산된 그룹이고,
각 그룹은 개별 그룹의 상한과 하한값을 담은 특수한 간격 값으로 구분한다.

여기서 0~3은 각 그룹에 대응하는 숫자로,
- 18~25가 0
- 25~35가 1
- 35~60이 2
- 60~100이 3에 각각 대응한다.
그룹을 표시할 때 (18~25] 처럼 25 뒤에 대괄호가 닫혀있는 것을
볼 수 있는데, 이는 25가 경계값에 포함된다는 것을 의미한다.
즉, 25는 첫 번째 그룹(0)에 포함되고,
같은 원리로 35는 두 번째 그룹(1)에 포함된다.

구간에 대한 정보는 이렇게 확인할 수도 있다.
제일 마지막에 right라고 되어 있는 것은 right가 경계값에 포함된다는 의미다.
소괄호로 감싸져 있는 쪽은 경계값에 포함되지 않는다.
즉, (25, 35]는 26에서 35까지, (35,60]은 36에서 60까지를 의미한다.
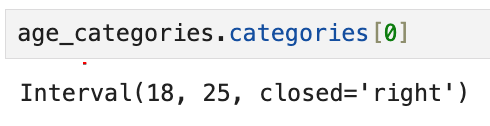
파이썬 리스트처럼 categories에서도
[0]을 통해 정수 위치로 바로 접근할 수 있다.
첫 번째 그룹인 18에서 25가 나오고, closed = 'right'이 보인다.
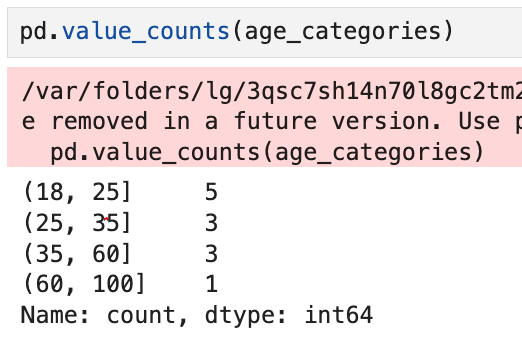
value_counts를 써서
각 그룹별로 갯수가 몇 개 있는지를 알 수 있는데,
경고창에서 보듯 미래에는 이 문법이 더 이상 지원되지 않는다.
따라서,
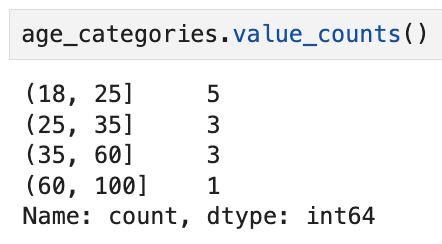
이렇게 쓰면 아무 문제없이 뽑아낼 수 있다.
위에서 소괄호와 대괄호의 위치를 통해
경계값의 포함 여부를 파악할 수 있다고 했는데,
cut 함수에서 괄호의 위치를 변경할 수 있다.

이렇게 right = False로 넣으면 왼쪽 값이 경계에 포함되고
오른쪽 값이 소괄호로 처리되며 경계에 포함되지 않게 된다.
cut에 들어갈 수 있는 또다른 인자로 labels가 있다.
그룹의 이름을 리스트나 배열 형태로 직접 전달할 수 있다. 즉,

4개 그룹에 맞게 각각 이름이 지정된 것을 볼 수 있다.
만약 cut에 명시적으로 bins를 통해
그룹의 경계값을 넘기지 않고 그룹의 갯수만 넘겨주면
데이터의 최소값과 최대값을 기준으로 균등한 그룹의 길이를 자동으로 계산한다.
예를 들어,
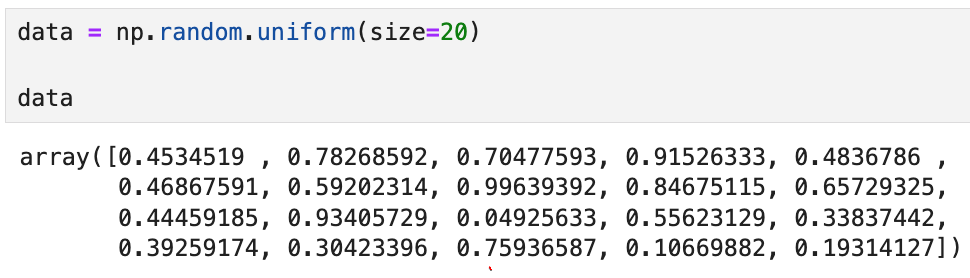
이렇게 생긴 데이터가 있다고 가정해 보자.
(uniform은 0과 1 사이에서 균등 분포로 난수를 생성하게 해 준다.
standard_normal은 표준정규분포에서 난수를 생성한다)

여기서 4개의 구간으로 나눠달라고 하면 위와 같은 결과가 나온다.
- 0.048 ~ 0.29
- 0.29 ~ 0.52
- 0.52 ~ 0.76
- 0.76 ~ 1.0
이렇게 자동으로 4개 구간으로 나눠준 것이고,
각각의 구간에 대해 데이터가 대응되어 표시되는 것.
precision = 2는 소수점 아래 둘째자리까지만 표시하겠다는 의미다.
표준 사분위수quartile를 기반으로 데이터를 나누려면
그냥 cut 말고 qcut을 써야 한다.
cut 함수를 사용하면 데이터의 분산에 따라
각 그룹의 데이터 갯수가 다르게 나뉘는 경우가 많다.
qcut은 표준 사분위수를 사용하므로 적당히 비슷한 크기의 그룹으로 나눌 수 있다.
아래 두 가지 예를 비교해 보자.
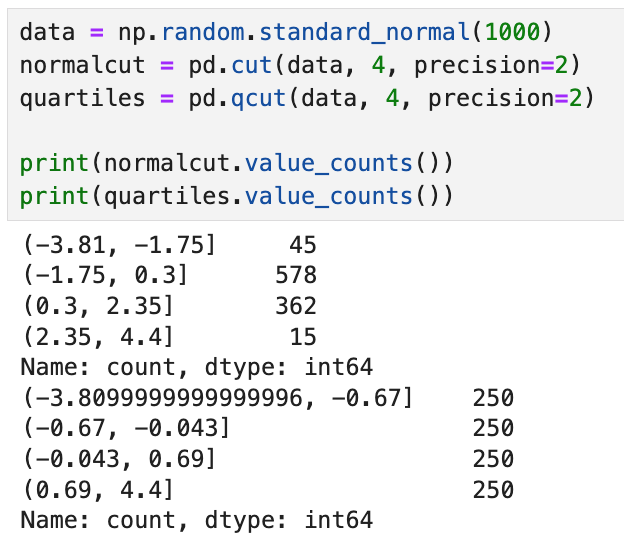
단순히 cut을 써서 그룹을 나눌 때에는
중간 구간에 데이터가 몰리는 현상이 생기는데,
qcut을 써서 그룹을 나누었더니 정확히 250개씩 4개 그룹으로 분리되었다.
한 마디로 cut은 데이터의 구간을 균등하게 나누고,
qcut은 데이터의 갯수가 균등해지도록 구간을 나누는 거라고 이해하면 될 듯.
qcut도 cut처럼 사분위수를 직접 지정할 수도 있다.
(사분위수는 0부터 1 사이의 값)
예를 들어,
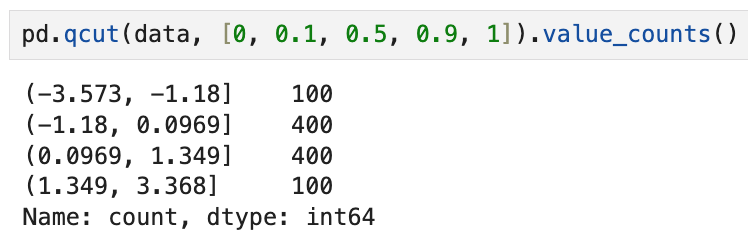
표준정규분포 하에서 10%, 50%, 90%, 100%까지를 구간으로 끊으면
자동으로 데이터가 100, 400, 400, 100개 단위로 분류된다.
qcut은 지정된 백분위수에 따라 데이터를 균등하게 나누기 때문에,
구간별 데이터 갯수가 설정한 비율에 딱 맞게 나오는 셈.
위에서는 qcut을 쓸 때 그냥 4개로만 나눴기 때문에
250개씩 균등하게 들어갔지만, 지금은 비율을 그렇게 맞춰놨기 때문에
100, 400, 400, 100개씩 나뉘었다고 보면 된다.
그룹 분석과 사분위수를 다룰 때는
cut과 qcut 함수가 특히 유용하다.
