7.5.3 Categorical 연산
판다스에서 Categorical 연산은
문자열 배열처럼 인코딩되지 않은 자료형을 사용하는 것과 유사하게 사용된다.
groupby 같은 일부 판다스 함수는
범주형 데이터에 사용할 때 더 나은 성능을 보여준다.
ordered 플래그를 활용하는 함수도 마찬가지다.
임의의 숫자 데이터를
pandas.qcut 함수로 구분하면 Categorical 객체를 반환한다.
이 내용은 앞선 포스팅에서도 살펴본 적이 있는데,
범주형 데이터를 다루는 법을 조금 더 자세히 살펴보자.
예를 들어,
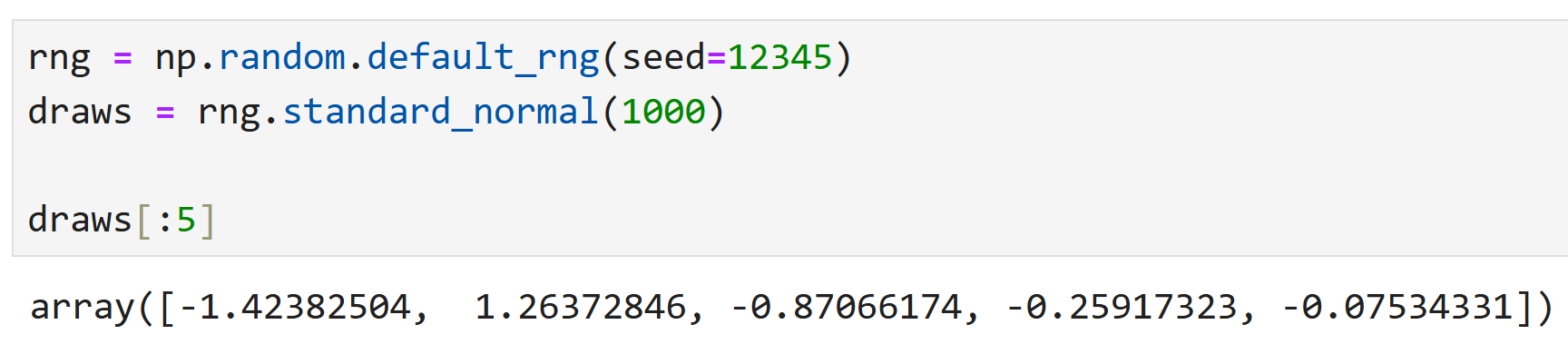
넘파이에서 난수생성기(rng)를 만들어서
임의로 1,000개를 뽑아서 draws라고 이름붙였다고 해 보자.
draws의 제일 첫 5개 값을 뽑아보면 위와 같다.
이제 이 데이터를 사분위수로 나누고 통계를 내 보자.

결과는 위와 같은데,
사분위수의 이름이 실제 데이터(숫자)로 지정되어 있어서
보기에 직관적이지 않다. 이럴 때 qcut 함수의 labels 인수를 써서
직접 이름을 지정해 줄 수가 있다. 즉,

bins에 labels를 지정해 줌으로써
숫자들이 Q1, Q2와 같은 범주형 데이터로 인식되고,
여기서 다시 bins.codes를 적용해 처음 10개 값을 뽑아보면
그보다 더 단순화된 0,1,2,3 등으로 나타나는 것을 확인할 수 있다.
예를 들어
- draws의 첫 번째 값인 -1.42는 -3.12와 -0.67 사이에 있으므로 첫 번째 그룹(0)
- 두 번째 값인 1.26은 0.68과 3.21 사이에 있으므로 네 번째 그룹(3)
이 되는 식이다.
여기서 이름을 붙인 bins는 데이터의 시작과 끝값에 대한
정보를 포함하지 않으므로 (괄호가 있어야만 알아볼 수 있다)
groupby를 이용해 요약 통계를 추출해 보자.
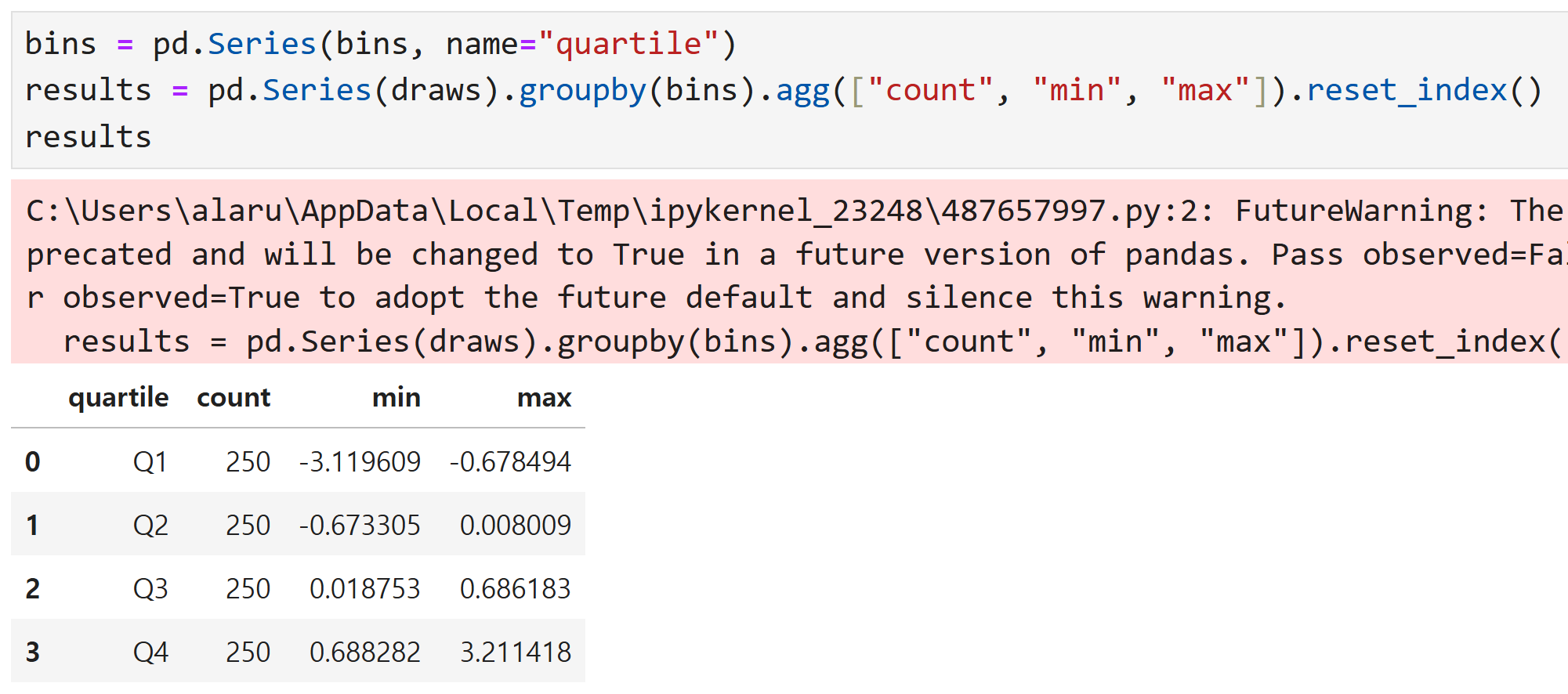
결과는 이렇게 나온다.
results는 draws를 groupby한 결과이므로 데이터프레임이 되는데,
이 때 agg(집계함수) 인수로 count, min, max를 주면
각 그룹별 갯수와 최대, 최솟값을 구할 수 있다.
※ 경고창이 뜨는 이유는 groupby에서 사용하는 observed 옵션값이
앞으로 바뀔 예정이기 때문인데,
- 현재는 observed = False가 기본값이다. 즉, 범주형 데이터의 모든 범주를 출력하고 비어 있는 그룹도 포함한다.
- 앞으로는 observed = True가 기본값이 될 예정이다. 즉, 실제로 관찰된 범주만 출력하고 비어 있는 그룹은 출력되지 않는다. 이 예에서는 비어 있는 범주가 없기 때문에 observed를 True로 하든 False로 하든 출력되는 결과에 차이가 없다.
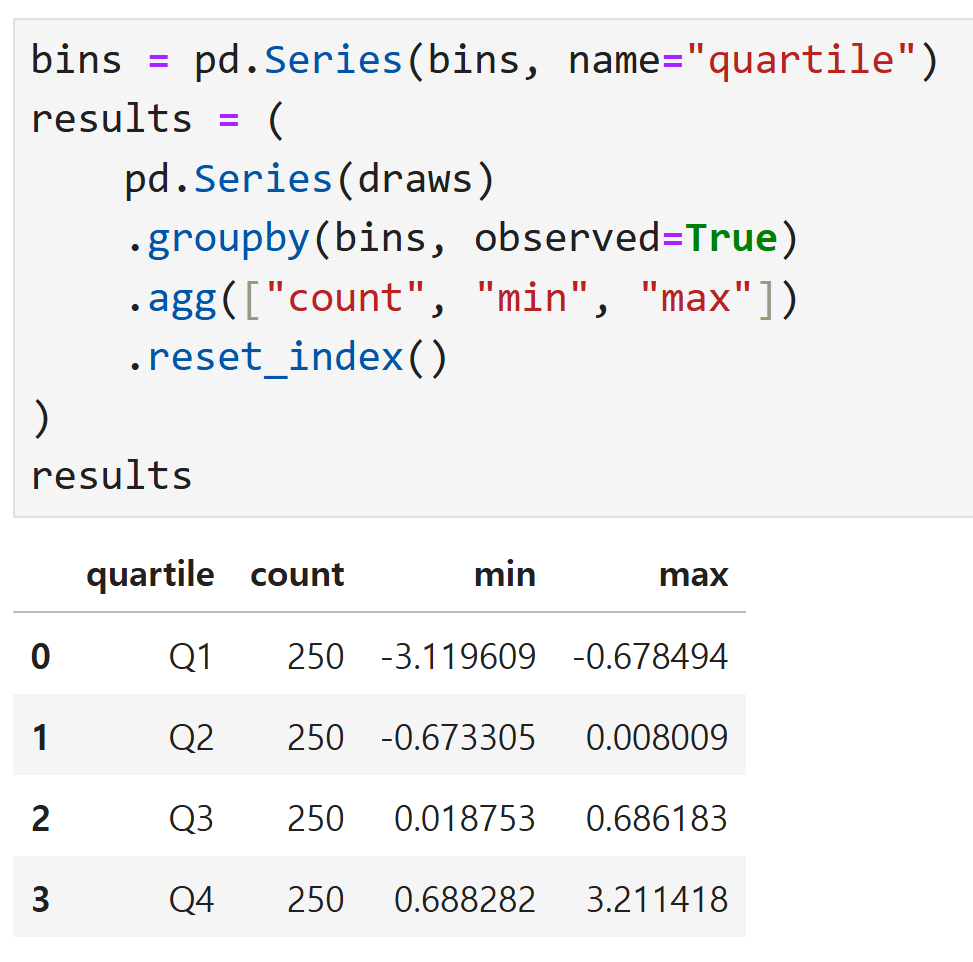
다만 이 경고는 bins가 Categorical일 경우만 나타나고,
일반적인 숫자나 문자열에서는 observed 옵션이 무의미하므로 신경쓸 필요 없음.
이렇게 출력된 결과(results)의 quartile 열은
bins 순서를 포함하여, 원래 범주의 정보를 유지한다.

범주형을 활용한 성능 개선
범주형을 사용하면 성능 향상과
메모리 사용률 개선을 기대할 수 있다고 했는데,
좀 더 극단적인 예로 1,000만개의 값을 가진 Series를 살펴보자.
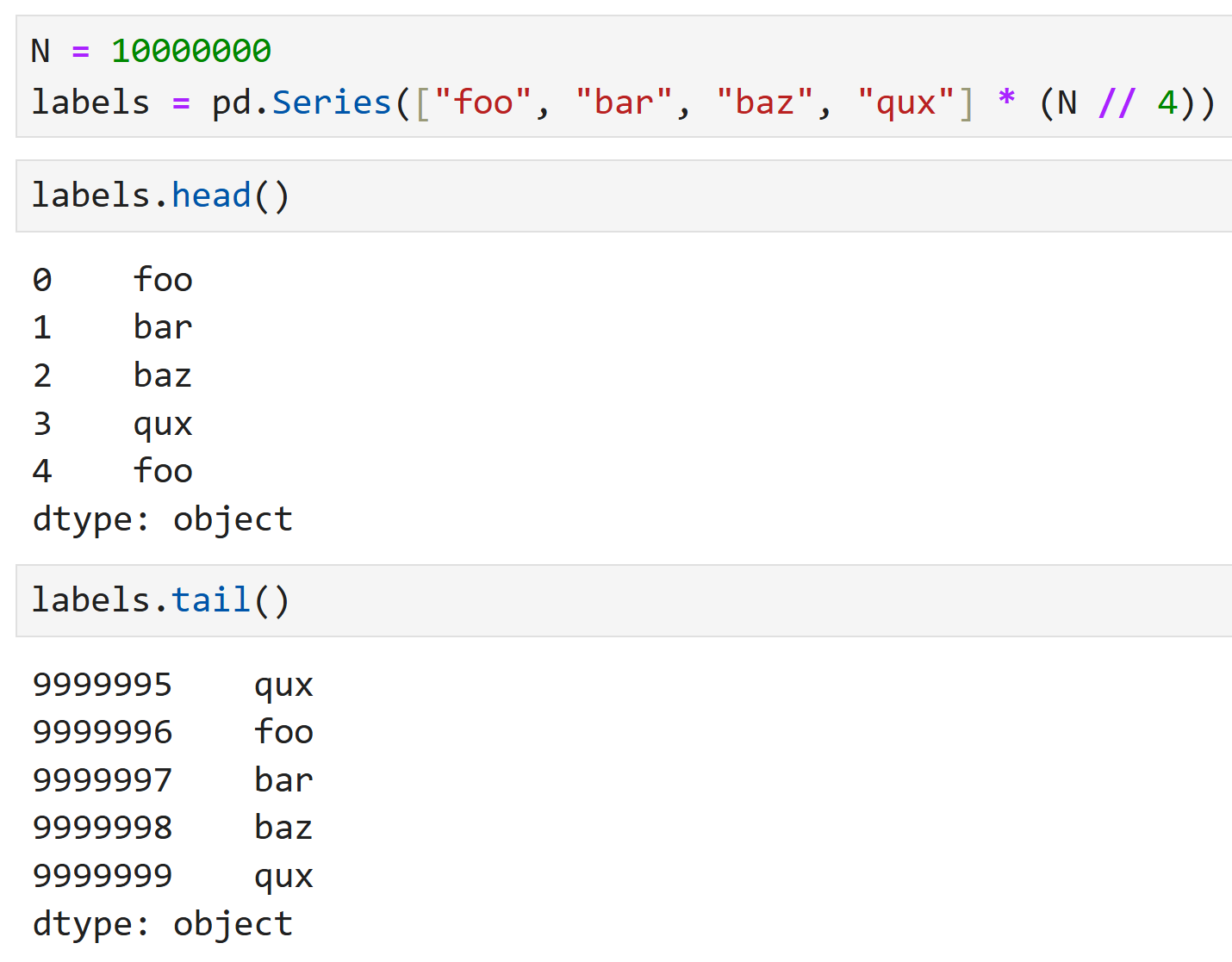
foo, bar, baz, qux가 반복되는 1천만개의 Series가 만들어졌다.
이제 labels를 범주형으로 변경해 보자.
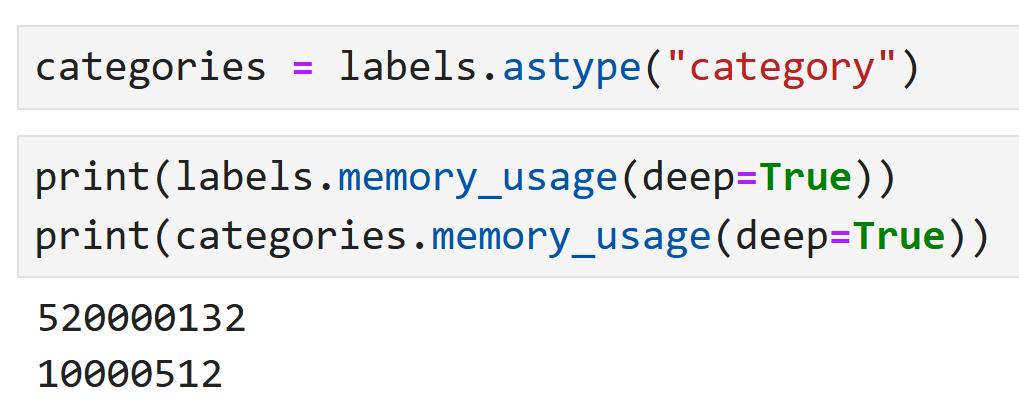
원본 데이터인 labels와 범주형으로 바뀐 categories의
메모리 사용량(memory_usage)을 비교해 보면
categories 쪽이 훨씬 더 적은 메모리를 쓰고 있음을 알 수 있다.
물론 범주형으로 변환하는 데에도 일정 정도의 비용이 들긴 하지만,
일회성 지출로 그 뒤의 연산에서 쭉 메모리 부담을 덜 수 있는 것은
큰 메리트이기도 하다.
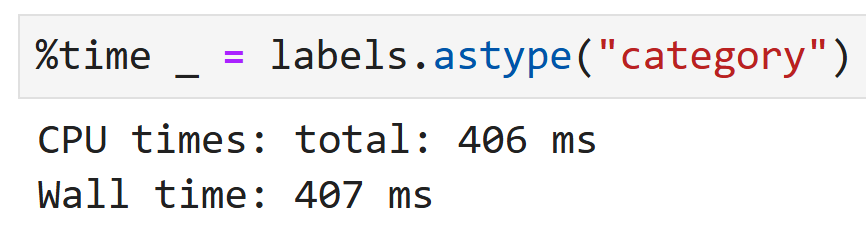
↑ 이렇게 %time을 쓰면 이 연산을 수행하는 데 걸린 시간을 확인할 수 있다.
categories에 대한 그룹 연산은
문자열 배열을 사용하는 대신 정수 기반의 코드 배열을 사용하는
알고리즘으로 작동하므로 훨씬 빠르게 동작한다.
groupby를 value_counts()의 예시로 성능을 비교해 보면,

마찬가지로 categories 객체에 대해 value_counts를 수행하는 것이
그냥 원본 데이터인 labels에 대해 바로 value_counts를 수행하는 것보다
시간 측면에서 훨씬 빠름을 알 수 있다.
결론 : 귀찮다고 원본 데이터(특히 사이즈가 큰 데이터일수록 더욱)에 바로 연산 때리지 말고 categorical로 바꿀 수 있는 것들은 바꿔서 계산하자.
