7.2.8 표시자, 더미 변수 계산하기
통계 모델이나 머신러닝을 위한 또 다른 데이터 변환은
분류값을 더미dummy나 표시자indicator 행렬로 전환하는 것이다.
만약 DataFrame의 한 열에 고유값이 k개 있다면,
k개의 열이 있는 DataFrame이나 행렬을 만들고
값으로 0과 1을 채워넣는 식이다.
판다스에서는 이런 작업을 위해 get_dummies 함수를 제공한다.
예를 들어,

이런 데이터프레임이 있다고 했을 때,

df["key"]에 대해 get_dummies 함수를 실행하면
key열에 대해 원-핫 인코딩(one-hot encoding)을 수행한다. 즉,
- df에서 0번째 행의 값은 b이므로 a와 c는 0으로, b는 1로 표시된다.
- 1번째 행도 동일하다.
- 2번째 행의 값은 a이므로 a는 1로, b와 c는 0으로 표시된다.
- 이하 동일
a, b, c같은 범주형 데이터는
통계나 머신러닝 모델에서 제대로 학습시키기 어렵다.
(이런 모델들은 거리 계산, 기울기 계산 등이 포함되므로
입력되는 데이터가 수치형이어야 제대로 작동함)
원-핫 인코딩을 수행하면
- 각 범주를 별도의 열로 나눠서 표기하므로 데이터의 구조적 의미가 보존되고
- 범주 간의 크기나 순서를 부여하지 않기 때문에 '순서가 없다'는 특징을 갖는 범주형 데이터를 정확히 처리하기에 적합하다.
다만 a,b,c와 같은 범주의 숫자가 많아지면
원-핫 인코딩을 수행한 데이터의 차원(dimension)이 매우 커질 수 있다.
예컨대 범주가 1,000개인 데이터를 원-핫 인코딩하면 열이 1,000개 늘어나는 셈인데,
이런 현상을 차원의 저주라고 부른다고 한다.
DataFrame의 열에 접두어(prefix)를 추가한 후
다른 데이터와 병합하려면 get_dummies 함수의 prefix 인수를 이용한다.
즉,
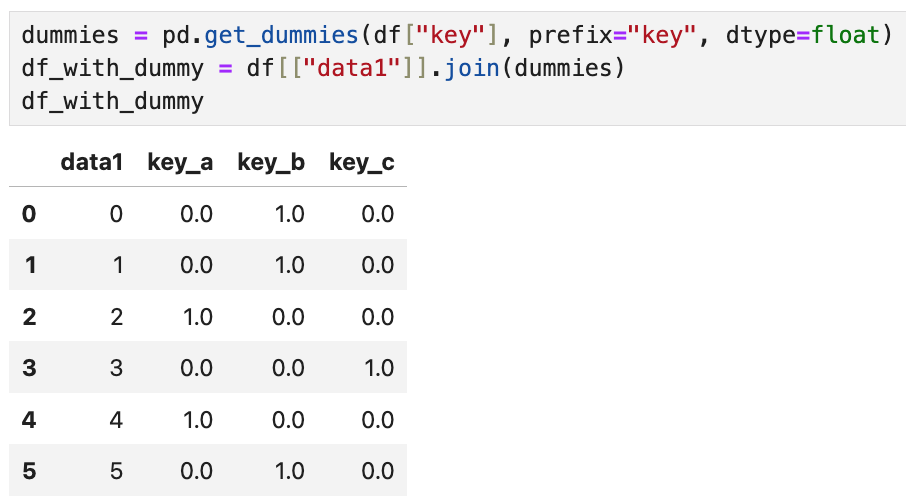
dummies를 만들 때 prefix를 설정하면
key라는 단어가 a,b,c 앞에 자동으로 언더바와 함께 붙게 된다.
이런 접두어를 붙이는 이유는 이미 데이터프레임에
같은 이름의 컬럼이 있을 경우 충돌이 발생할 수 있기 때문.
그리고 df_with_dummy는 원래 df에서 data1 컬럼만 고른 후
방금 만든 dummies를 조인한 결과인데,
조인에 대해서는 별도 포스팅에서 자세히 정리할 예정.
DataFrame의 한 행이 여러 범주에 속한다면
다른 접근법을 써서 원-핫 인코딩을 해 줘야 하기 때문에 조금 더 복잡해진다.
예를 들어,
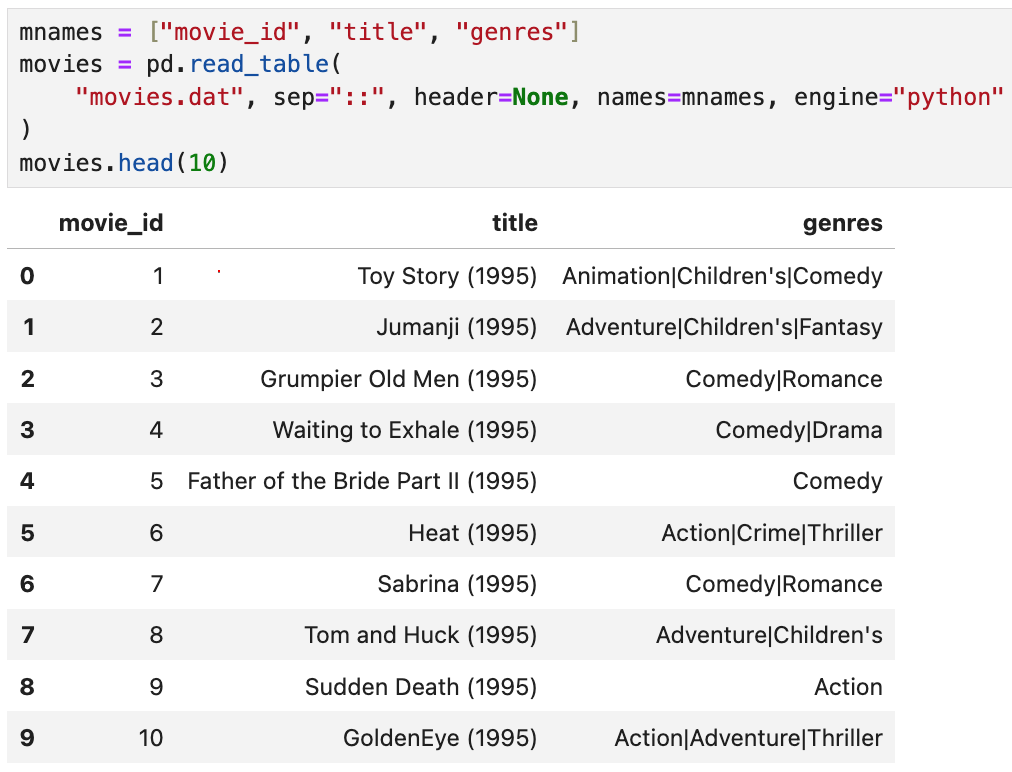
이런 데이터프레임이 있다고 하자. 여기서
- sep = "::"은 원본 데이터 파일에는 ::가 들어가 있었는데,
이걸 기준으로 해서 열을 구분해 주겠다는 의미다.
(이래서 원본 데이터가 어떻게 생겼는지를 아는 것도 중요) - header = None은 데이터에 열 이름이 따로 없다는 뜻이다. 열 이름을 별도로 지정해 줄 예정이기 때문에 이 옵션이 필요한 것.
- names = mnames로 열 이름을 mnames에 있는 값들로 지정해 준다.
- engine = "python"은 sep = "::"처럼 여러 문자의 구분자를 처리하기 위해 파이썬 엔진을 쓰겠다는 말이다.
이 데이터프레임에서는 하나의 영화(예를 들면 토이스토리)에
장르가 여러 개(Animation|Children's|Comedy)인 상황이 문제가 된다.
이럴 경우에는 원-핫 인코딩을 위해 str.get_dummies 메서드를 쓸 수 있다.
이 메서드는 구분 문자열을 써서 여러 그룹에 속하는 구성원을 처리한다.
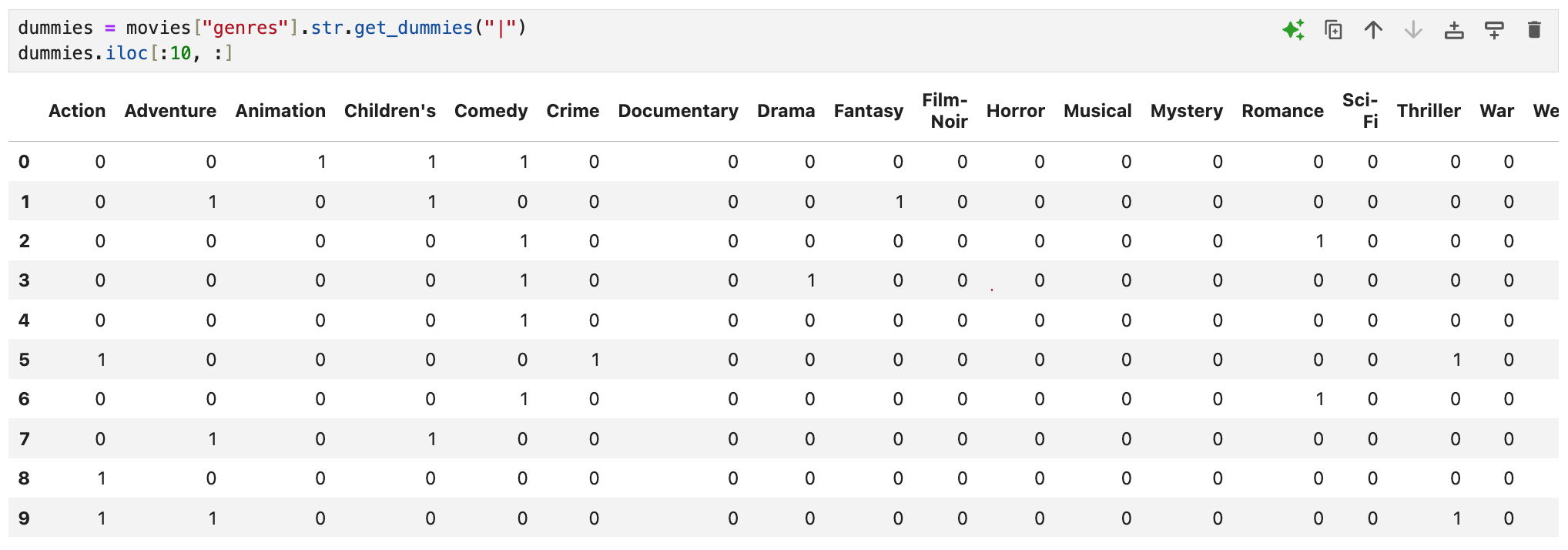
dummies를 만들기 위해 str.get_dummies를 쓰고
구분자로 "|"를 넣어주었다. 그런 다음 dummies를 처음 10행만 조회해 보면
genres에 해당하는 모든 값들이 원-핫 인코딩을 수행한 결과처럼
열 방향으로 펼쳐져 있고 각 영화에 해당하는 장르들만 1로 표기된다.
예컨대 0번 행의 토이스토리는 Animation, Children's, Comedy에
1이 표기되어 있고, 나머지는 모두 0으로 된 것을 확인할 수 있다.
이제 이 dummies를 movies와 결합하고
addprefix 메서드를 사용해 dummies의 열 이름 앞에
"Genre"를 추가해 보자.

결과는 이렇게 된다.
원본 movies 데이터프레임에 원핫인코딩의 결과가 잘 붙었고
각 열 이름 앞에 Genre_라는 텍스트가 이상없이 추가되었다.
⛳️ 이보다 데이터가 더 큰 경우라면 이 방법으로 표시자 변수를 생성하는 것은 그렇게 빠른 방법이 아닐 수 있다. 속도를 높이려면 직접 넘파이 배열에 접근하는 저수준의 함수를 작성해 DataFrame에 결과를 저장해야 한다.
get_dummies와 이전 포스팅에서 다루었던 cut같은 이산함수를 잘 조합하면
통계 어플리케이션에서 유용하게 사용할 수 있다. 예를 들어,

이렇게 생긴 values가 있다고 하자.
np.random의 seed를 고정시켜 두었기 때문에
코드를 반복 실행해도 숫자가 바뀌지 않는다.
(머신러닝에서의 random_state = 42와도 비슷하다)
그리고 size = 10, 즉 10개의 난수를 균등분포(uniform distribution)로 추출한 결과다.

이제 pd.cut을 이용해 values를 bins 구간에 따라 쪼갠 후,
pd.get_dummies를 통해 원-핫 인코딩을 실행해 준 결과는 위와 같다.
예컨대 첫 번째 값인 0.92961609는 0.8과 1 사이 구간에 있으므로
해당 구간만 True, 나머지는 False로 뜬다.
다른 값들도 해석은 마찬가지.

만약 결과를 불리언이 아니라 0과 1의 이진수로 받아보고 싶으면
get_dummies의 결과에 .astype(int)를 붙여서 명시적으로 타입을 지정하면 된다.

이렇게 써도 결과는 동일하다.
범주형 데이터의 처리는 머신러닝이나 통계 모델에서
워낙 중요하기 때문에 자주 마주치게 될 주제다.
추후에 다른 포스팅에서도 다룰 기회가 있을 듯!🔥
