eclass에서 다운로드 받은 파일을 pycharm 프로젝트 폴더로 옮기기위해, pycharm 프로젝트 폴더 우클릭 >
Open In > Explorer 선택
파이썬 크롤링
pandas -> 2차원 테이블 형태.
필요없는 데이터 제거 후 유형, 개수 세기 등.
네이버 오픈 API 생성
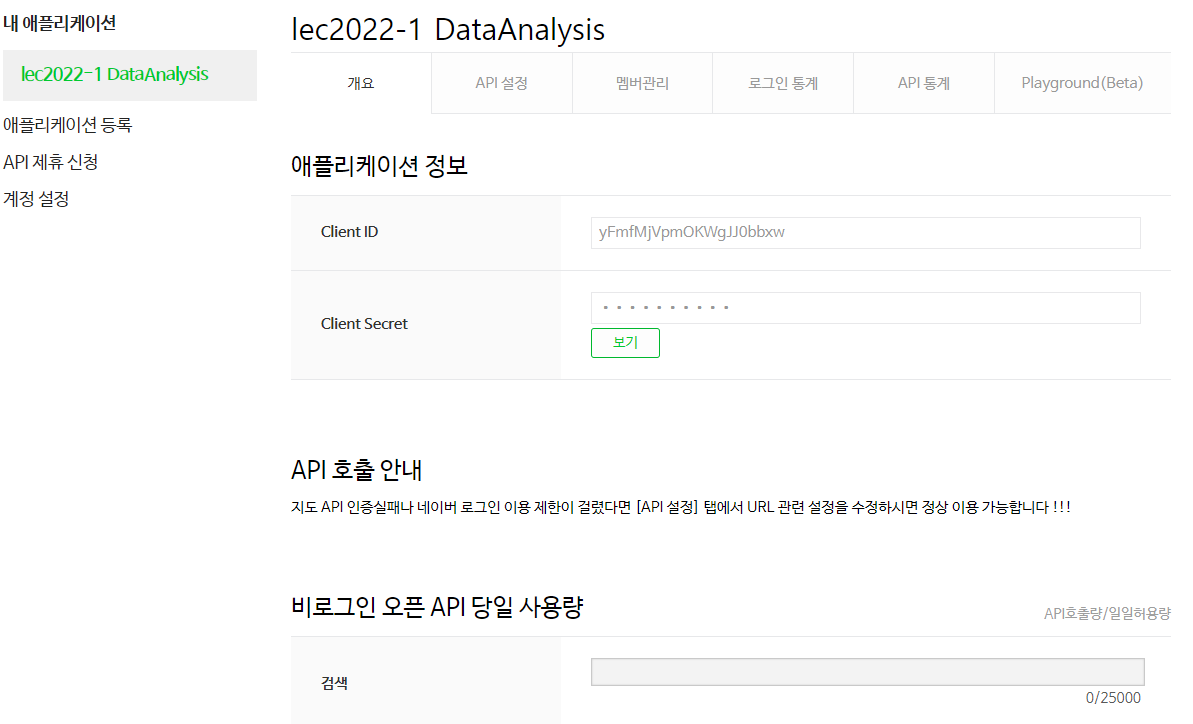
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)전체 작업 설계하기
- 검색 keyword 지정하기
request를 요청하면response로 결과를 보낸다.
XML=> 사용자가 원하는 태그를 입력 가능
JSON => 파이썬딕셔너리구조와 똑같다.(KEY/VALUE 의 조합)
주피터 -> 파이참으로 에디터를 옮긴 이유?
=> 코드 디버깅하기 위해서.
import os
import sys
import urllib.request
import datetime
import time
import json
client_id = 'yFmfMjVpmOKWgJJ0bbxw'
client_secret = 'ZyIwBR6iPz'
#[CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print ("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
#[CODE 2]
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) #[CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
# string 값을 딕셔너리 형태로 변환
#[CODE 3]
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900') # 발행 날짜
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S') #strptime vs strftime: 전자: 텍스트를 날짜로 변경해줌, 후자: 날짜를 텍스트로 변경.
jsonResult.append({'cnt':cnt, 'title':title, 'description': description, 'org_link':org_link,
'link': org_link, 'pDate':pDate})
return
#[CODE 0]
def main():
node = 'news' # 크롤링 할 대상, node를 blog 등으로 바꾸면 바꾸어 용도 변경 후 사용가능하다.
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
# 검색 결과 받아옴
# jsonResponse는 딕셔너리
jsonResponse = getNaverSearch(node, srcText, 1, 100) #[CODE 2]
total = jsonResponse['total']
# jsonResponse의 key값 중 total값 가져와
# 받아온 데이터 저장
with open('%s_jsonResponse_%s.json' % (srcText, node), 'w', encoding='utf8') as outfile:
jsonFile = json.dumps(jsonResponse, indent=4, sort_keys=True, ensure_ascii=False)
# json.dumps 메서드 => '가독성'을 높이기 위해 사용, sort_keys => 오름차순으로 정렬, ensure_ascii는 한글 깨짐 방지
outfile.write(jsonFile)
# 탐색 된 것이 없지 않을 경우 for 문을 돌린다.
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) #[CODE 3]
# 받은 데이터를 json으로 저장했고, 결과를 처리한다.
# 검색된 결과 중 3번째부터 볼거야~ 처럼 요청하는 것!
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) #[CODE 2]
print('전체 검색 : %d 건' %total)
# 조작 한 데이터를 아래 처럼 저장한다.
with open('%s_naver_%s.json' % (srcText, node), 'w', encoding='utf8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d 건" %(cnt))
print ('%s_naver_%s.json SAVED' % (srcText, node))
if __name__ == '__main__':
main()
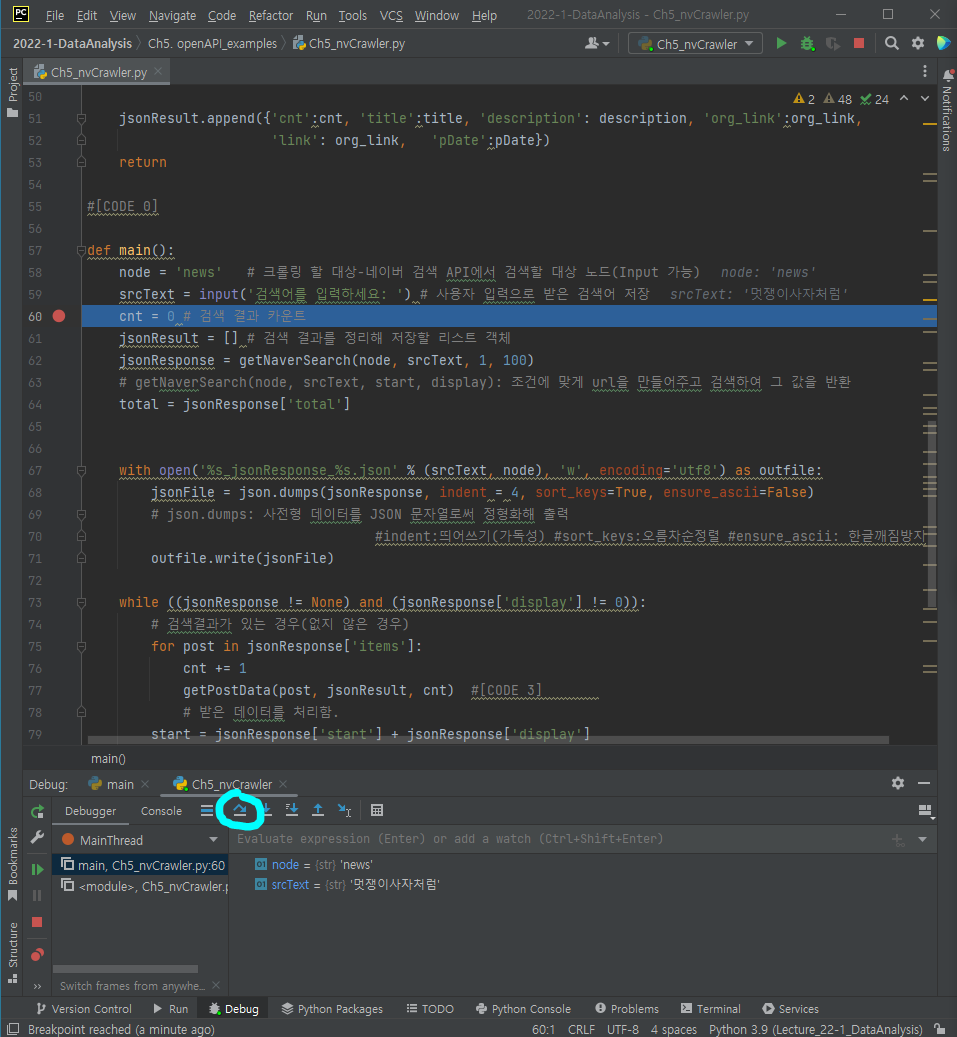
Breakpoint를 건 다음 디버깅모드로 실행한다 => 그럼 아래 박스가 새로 뜨게 되는데 여기 동그라미 친 부분을 클릭하면 한줄씩 코드가 실행된다.(단축어는 F8)
함수로 들어가는 단축키는 F7이다.

모든 건 zero 부터, 차근차근 헛둘헛둘