Data Visualization Basic(samples) 다운 받기
Preview
pandas_data_cleaning 파일
저번 시간 공백, 결측치 데이터를 없앨 때 대여소 번호, 대여 시간이 삭제안되는 이슈
연속적 수치라고 하면 평균값으로 대치할 때 오류 -> 범주형 데이터가 포함되어 있어 평균값 구할 때 오류 발생.
이를 해결하려면 범주형이 아닌 수치형 데이터로만 측정을 하면 됨.
결측치 정보 없애기df.dropna(), 대체하는 법df.fillna() 다룸.
-
이상 데이터
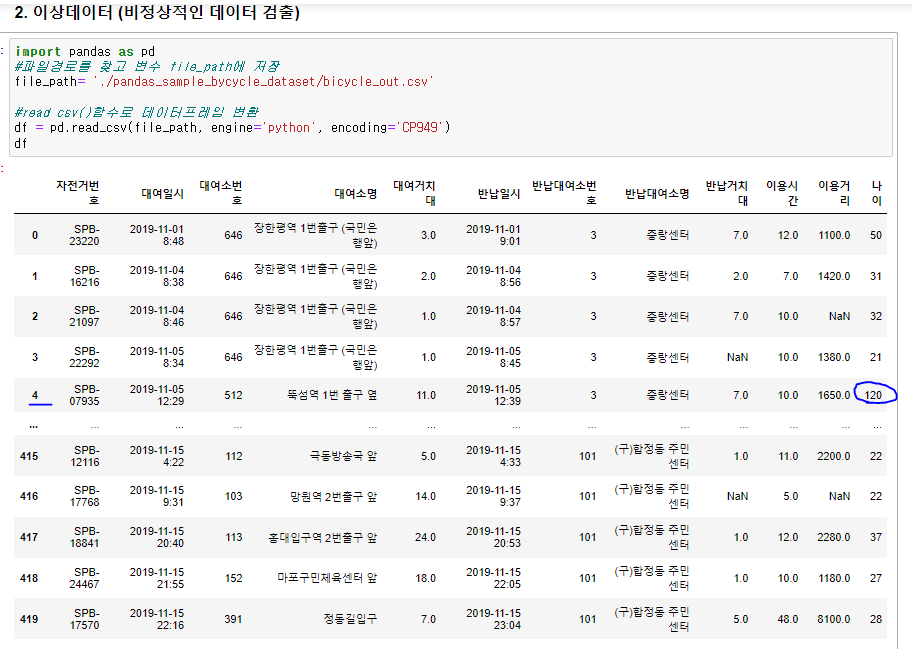
나이가 120살인 4번 인덱스 row가 이상데이터라고 할 수 있음.
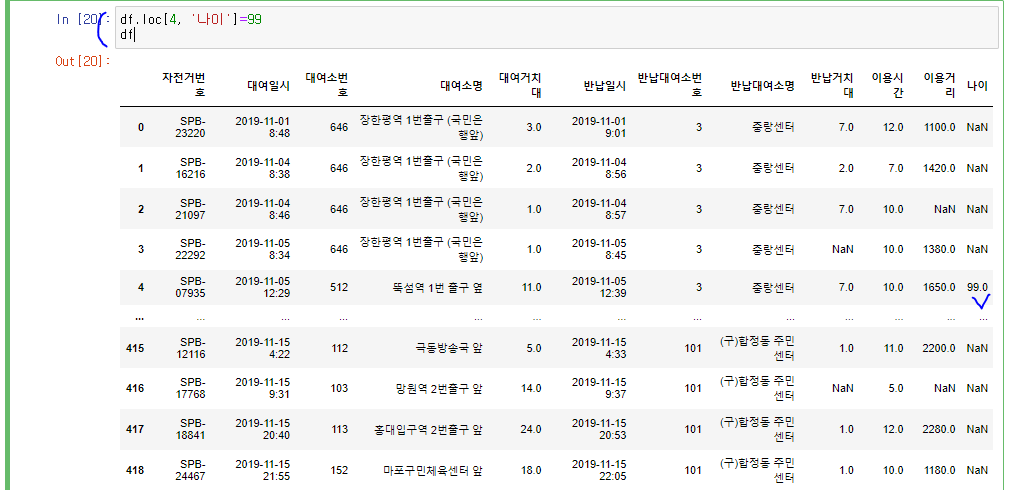
loc를 이용해서 행 또는 열의 데이터를 조회할 수 있음
loc는 소괄호()가 아닌 대괄호[]로 감싼다.
loc의 첫번째는 행에 대한 정보, 두번째는 열에 대한 정보를 입력
따라서 df.loc[4, '나이']=99로 120살 => 99살로 이상데이터 수정
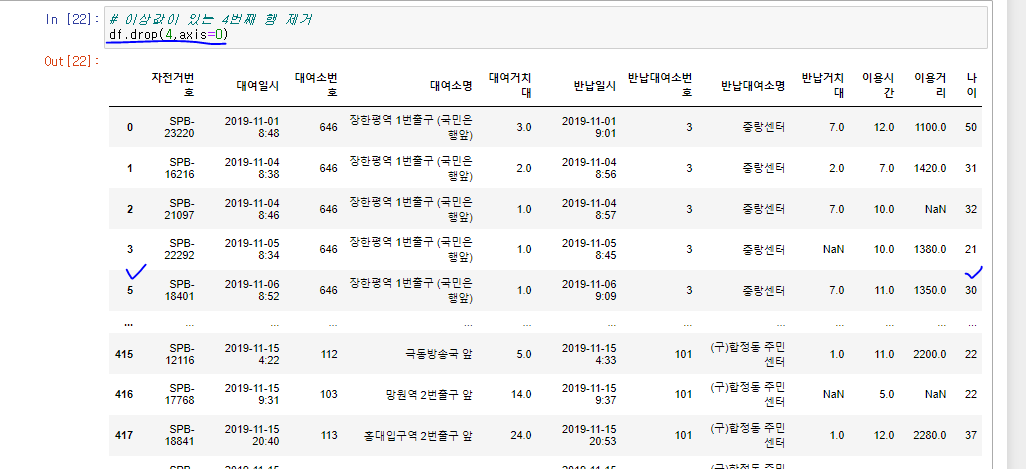
또는 df.drop(4, axis=0)으로 4번째 행 제거
boxplot의 특징
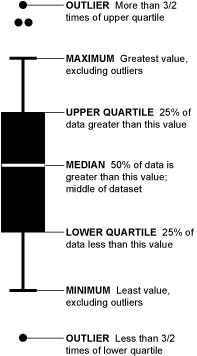
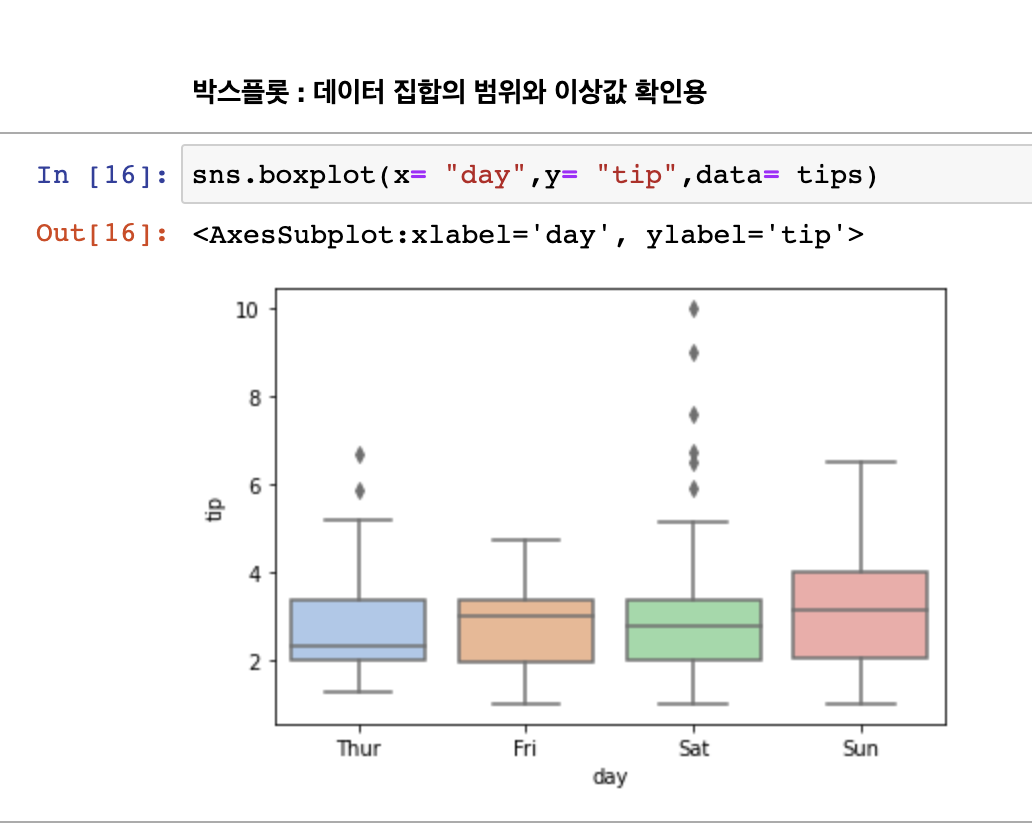
박스 플롯을 사용하는 이유는 많은 데이터를 눈으로 확인하기 어려울 때 그림을 이용해 데이터 집합의 범위와 중앙값을 빠르게 확인할 수 있는 목적으로 사용한다. 또한 통계적으로 이상치(outlier)가 있는지도 확인이 가능하다.
'박스 플롯'은 '상자 수염 그림'(Box-and-Whisker Plot) '상자 그림' 등 다양한 이름으로 불린다.
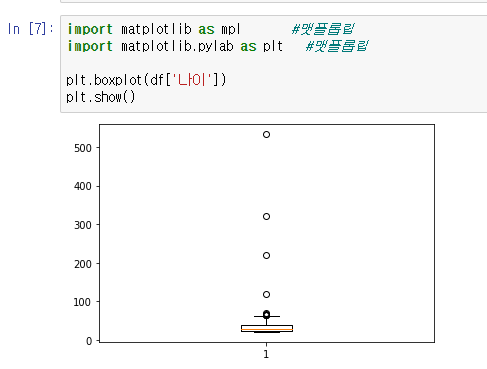
선 = median 값
중간값, but 평균은 아님
평균은 점, 삼각형으로 나타낼 수 있음.
max값, min값을 보여줌.
25%, 75%를 박스로 표시함. 대충 나이가 갖는 범위를!
그곳을 벗어난 범위의 데이터 존재(아웃라이너)를 확인
중복데이터
똑같은 데이터가 리소스만 많이 차지(하드, ssd) => 중복데이터 찾아서 제거
공공데이터 포털에서 데이터를 다운받으면 중복, 결측치가 없으나 교수님이 추가하심.
중복데이터 확인
duplicated() 메소드
dataFrame.duplicated(['컬럼명'])는 중복된 데이터면 True, 그렇지 않으면 False 의 boolean 형태의 Series반환.
ex. df.duplicated(['이용거리'])
row 데이터에 대해 식별할 수 있는 데이터
나이+이용거리 면 식별할 수 있는 데이터가 되는데(중복x) 그럼에도 불구하고 중복되는 데이터를 찾는다.
중복데이터 시작과 끝
df.duplicated(['컬럼명'], keep='first')
기본값.
keep = 'first'가 default이며, 중복값이 있으면 첫번째 값의 duplicated 여부를 False로 반환/ 나머지 중복값에 대해서는 True를 반환
df.duplicated(['컬럼명'], keep='last')
last: 처음 중복되는 값을 True로 반환, 나머지 false
df.duplicated(['이용거리'],keep=False)
keep=False는 처음이나 끝값인지 여부는 고려를 안하고 중복이면 무조건 True를 반환
중복데이터 삭제
drop_duplicates(['컬럼명', keep='first'(or 'last', 'False'])
중복 제거, 유일한 1개 키만 남기고 나머지는 중복 제거
Data Visualization Basic samples
평균, 표준편차가 같으면 같은 데이터? 다른 데이터?
=> 다른 데이터일 수 있음.
엔스콤 이라는 사람이 수치만 가지고 나타날 수 있는 데이터분석의 한계를 제시
=> 데이터 시각화를 강조함
seaborn
파이썬 데이터 시각화 라이브러리 중 하나인 Seaborn
파이썬의 대표적인 시각화 도구로는 matplotlib과 seaborn이 있음. seaborn은 matplot 대비 손쉽게 그래프를 그리고 그래프 스타일 설정을 할 수 있다는 장점이 있음.
정교하게 그래프의 크기를 조절, 각 축의 범례를 조절할 땐 matplotlib을 함께 사용해야 하지만, seaborn 사용법에 익숙해진다면 큰 문제가 되지 않음.
아래 표는 seaborn 라이브러리에서 제공해주는 그래프(plot)의 종류를 정리한 표임.
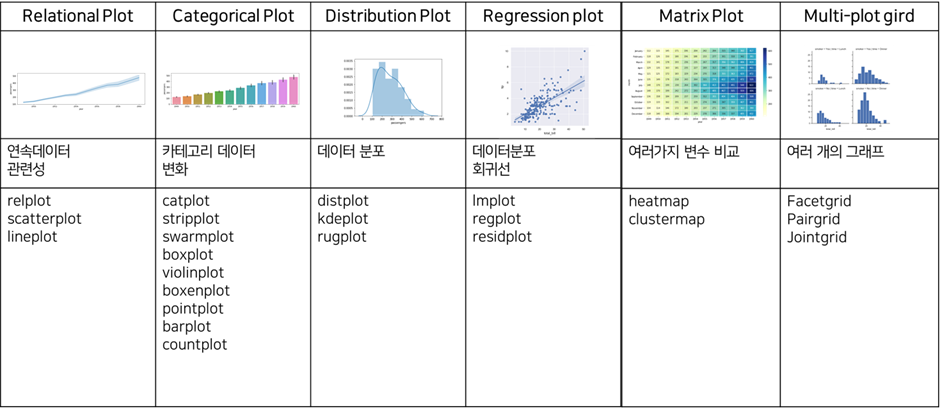
다양한 종류의 plot(그래프)를 제공하기 때문에 데이터의 종류가 연속형 데이터인지, 범주형(카테고리 데이터)인지, 궁금한 내용이 시계열적 변화인지 분포인지에 따라 적합한 그래프를 선택해 도식화하면 된다!
범주형 데이터 => 카테고리로 묶을 수 있음(groupby)
데이터에 따라 line / box plot를 선택해 그래프를 그린다.
#엔스콤 데이터는 seaborn 라이브러리에 내장 되어 있음
#seaborn 라이브러리 호출
import seaborn as sns
# seaborn에서 제공하는 anscombe 데이터셋 사용
ans = sns.load_dataset('anscombe')
#데이터 확인
ans 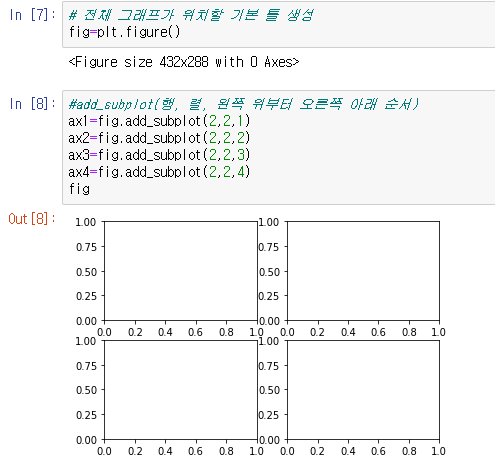
fig=plt.figure()
# 전체 그래프가 위치할 기본 틀 생성
#add_subplot(행, 렬, 왼쪽 위부터 오른쪽 아래 순서)
ax1=fig.add_subplot(2,2,1)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)
ax4=fig.add_subplot(2,2,4)
figadd_subplot: 1,2,3,4 사분면으로 나눠 그래프 그림
ax1.plot(data1['x'],data1['y'],'o' )
ax2.plot(data2['x'],data2['y'],'o' )
ax3.plot(data3['x'],data3['y'],'o' )
ax4.plot(data4['x'],data4['y'],'o' )
fig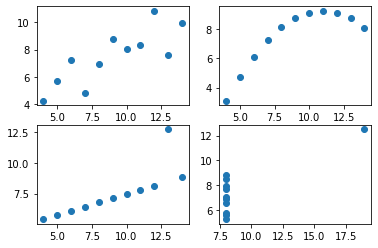
# 그래프 제목 달기
ax1.set_title('data1')
ax2.set_title('data2')
ax3.set_title('data3')
ax4.set_title('data4')
fig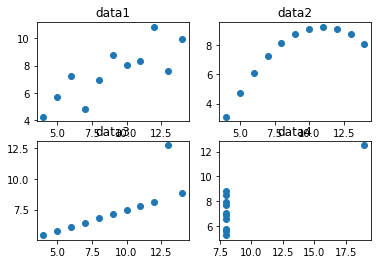
# 그래프 주제를 달았더니 글자가 서로 겹쳐보임
# 그래프 LAYOUT 조절
fig.tight_layout()
fig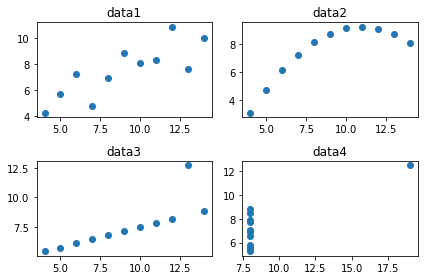
기본시각화
참고자료
https://wikidocs.net/book/5011
한글화문서 참고해서 matplotlib과 친해지기
https://matplotlib.org/
공식문서를 들어가서 그려진 그래프들을 확인
=> 다음에 그래프를 그리게 될 때 참고할 것
import matplotlib as mpl
import matplotlib.pyplot as pltpyplot은 data visualization과 상관없는 것!
이런식으로 구성해!라는 기능이다.
실질적으로 화면에 뿌리는 기능은 mpl.rcParams로 설정한다.
import matplotlib.pylab as pltpylab = matplotlib과 numpy가 합쳐진 것.
그러나 pylab은 권장하지 않고, import numpy as np로 넘파이를 인포트해 사용을 권함.
리스트로 입력하면 matplotlib.pyplot 패키지가 알아서 그래프를 그려줌.
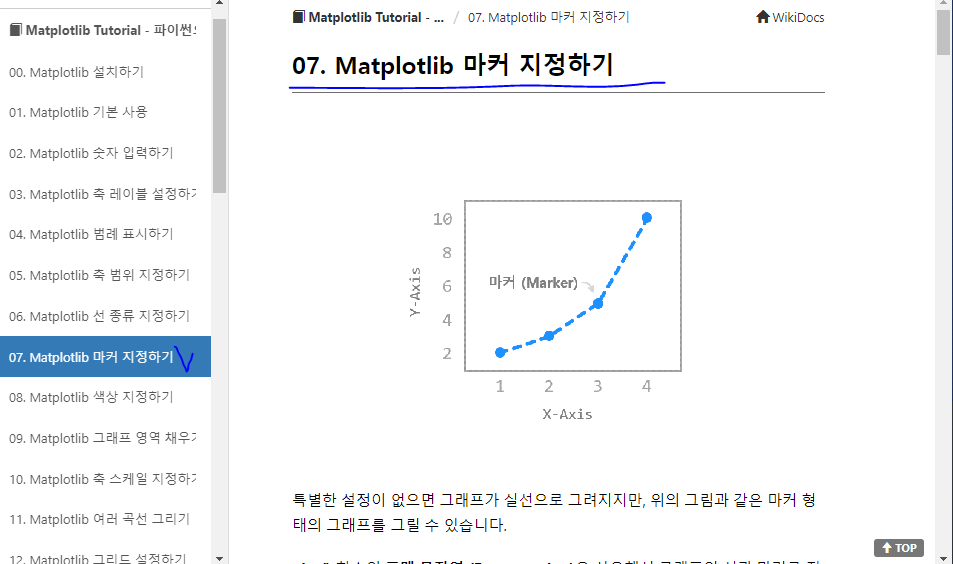
https://wikidocs.net/92083 에 자세한 정보가 나와있으니 그래프 그릴 때 참고할 것.
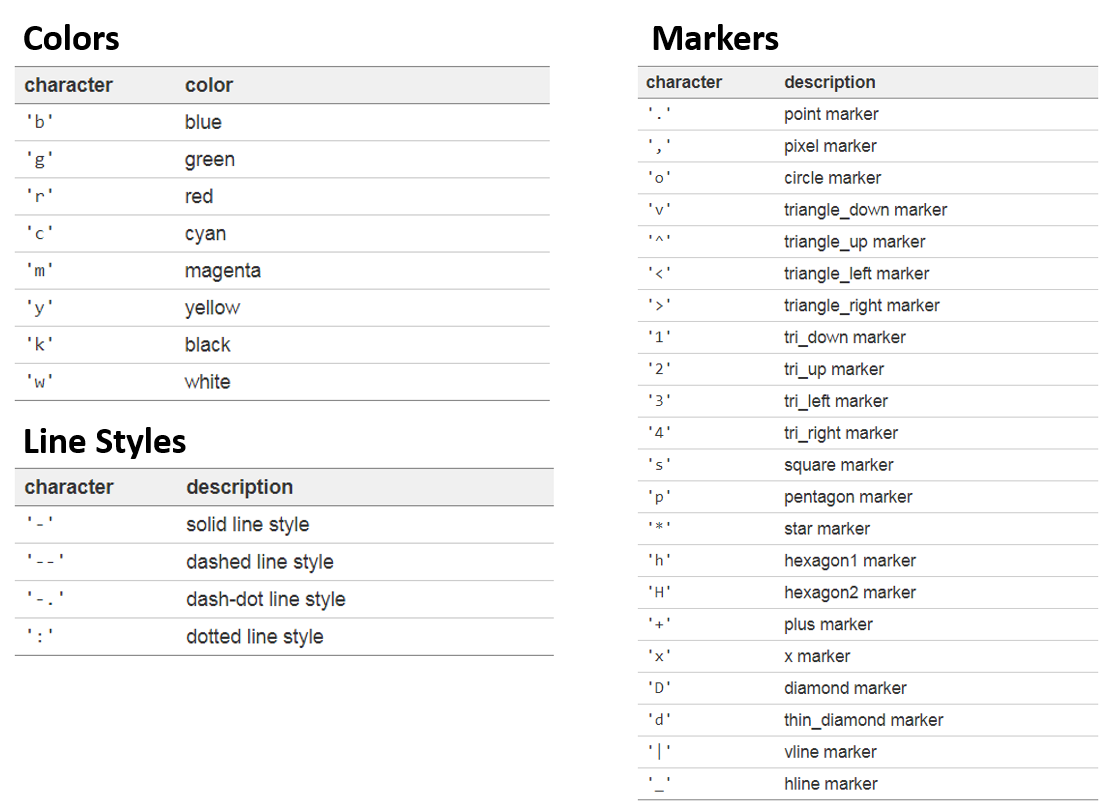
maker에 어떤 모양으로 점을 찍을 지 결정 가능
matplotlib말고 seaborn을 쓰면 파스텔 톤 그래프 그리기 가능.
시각화옵션- 제목/범례/색상/축이름
범례 추가
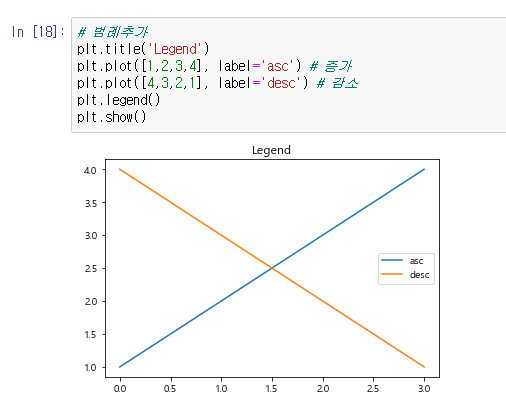
- 기호, 한글이 잘 안보이면 한글 폰트를 설정해주고 unicode_minus를 False 설정한다.
# 그림 범위 : 그래프의 범위가 명확히 보이지 않을 때 x, y 축 범위 수동 조정
# 폰트 에러 해결
# -기호가 표시 안되어 에러나는 경우 있음
mpl.rc('axes', unicode_minus=False)
#matplotlib 패키지 한글 폰트 설정 시작
#윈도우
plt.rc('font', family='Malgun Gothic')
#Mac
#plt.rc('font', family='AppleGothic')
plt.title("x, y 레인지")
plt.plot([10, 20, 30, 40], [1, 4, 9, 16],
c="b", lw=5, ls="--", marker="o", ms=15, mec="g", mew=5, mfc="r")
plt.xlim(0, 50)
plt.ylim(-10, 30)
plt.show()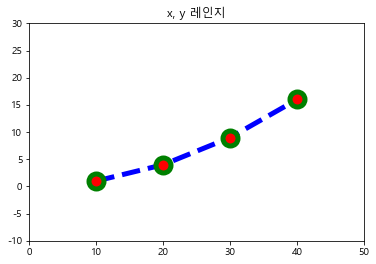
일차시각화
#dataframe 내 연속형(수치형) 데이터 그래프 그리기
#기본 선
tips.plot()
tips.plot(kind='line')
#히스토그램
tips.plot(kind='hist')
#박스플롯
tips.plot(kind='box')고급시각화
주피터 노트북은 자동완성 기능까지는 제공해줌.
- 박스플롯: 데이터 집합의 범위와 이상값 확인용
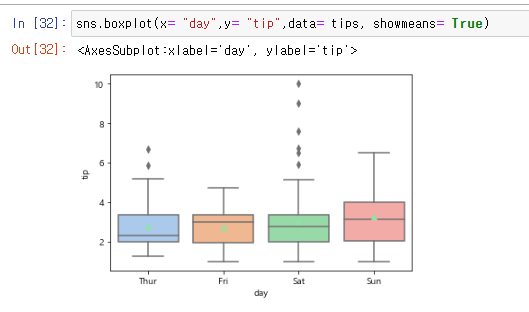
showmeans=True
sns.boxplot(x= "day",y= "tip",data= tips, showmeans= True)
옵션을 추가해 평균 값 표시가능.(연두색 삼각형이 평균값이다)
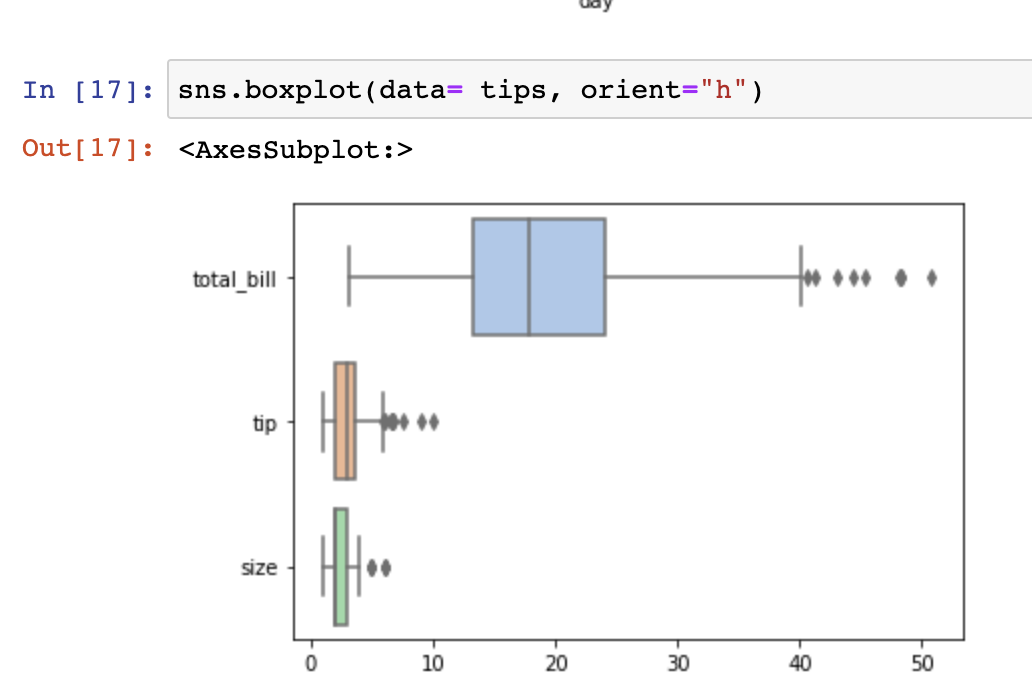
축: vertical이 기본이나 orient="h" 옵션으로 축 변경도 가능.
sns.boxplot(data= tips, orient="h")
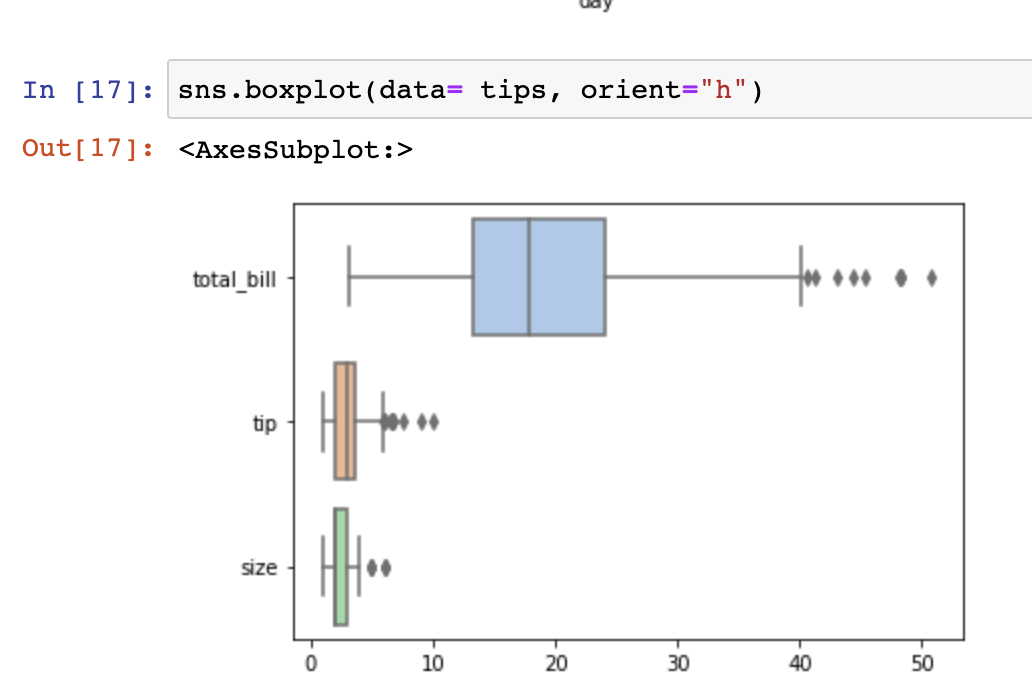
박스플롯으로 이상치 제거 시각화
<total_bill> 에 이상치가 있다고 가정을 하자.
이때, 'total_bill' 중 40달러 보다 작고, 'tips'의 경우 8달러 보다 작은 데이터를 추출하려고 한다.
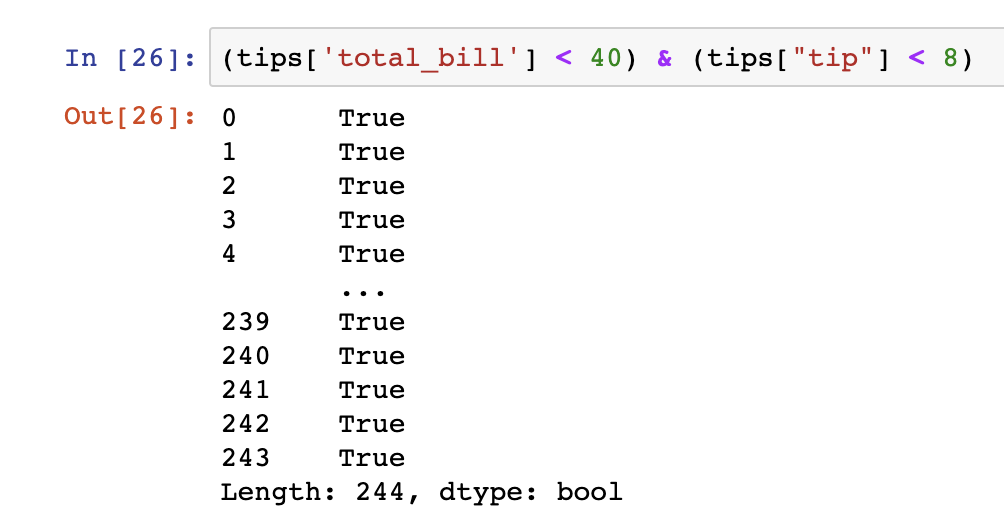
결과는 244개가 출력됨.

10개의 데이터가 삭제되고 234개의 데이터 추출(이상치 데이터를 삭제)
조건을 계속 달면 아웃라이너가 계속 나올 수 있음.
seaborn의 다양한 추가 기능
matplotlib의 경우 복잡한 일을 해결
seaborn의 경우 복잡한 것을 가독성 좋고 예쁘게 보이게끔 함.
- jointplot
산점도를 기본으로 표시하고 x-y축 두개의 수치형 변수에 대한 관계를 연구할 수 있다.
x, y 인자에 원하는 열 이름을 지정하고 data 인잣값으로 데이터프레임을 지정
두 변수의 관계와 데이터가 분산되어 있는 정도를 한눈에 파악하기 쉽다.
#jointplot(x="x_name", y="y_name", data=dataframe, kind='scatter')
sns.jointplot(x="total_bill", y="tip", data=tips)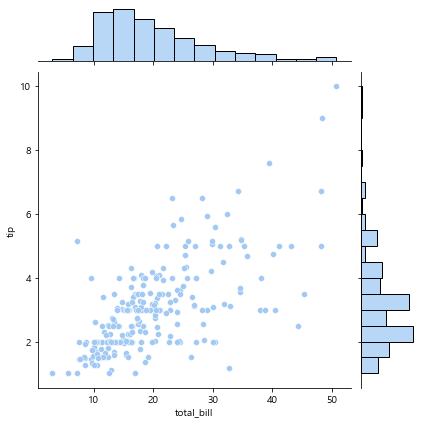
범주형 데이터, 연속형 데이터 사용하는 유형이 있으나 필수적으로 따라해야 할 필요는 없음.
커널밀도함수가 어떤것? 이런 기능이 있다 정도만 알아둘것.
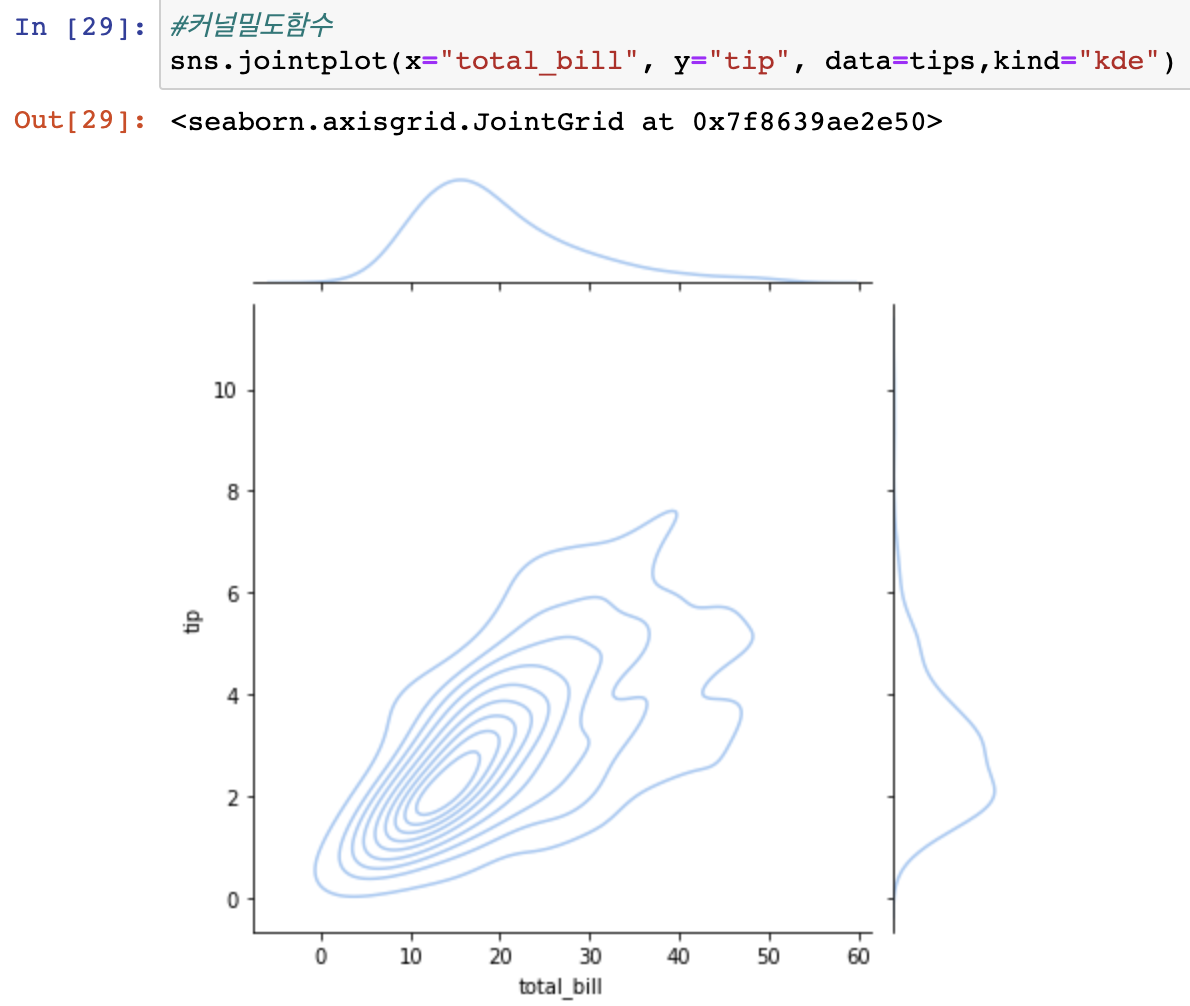
- 다변량 연속형
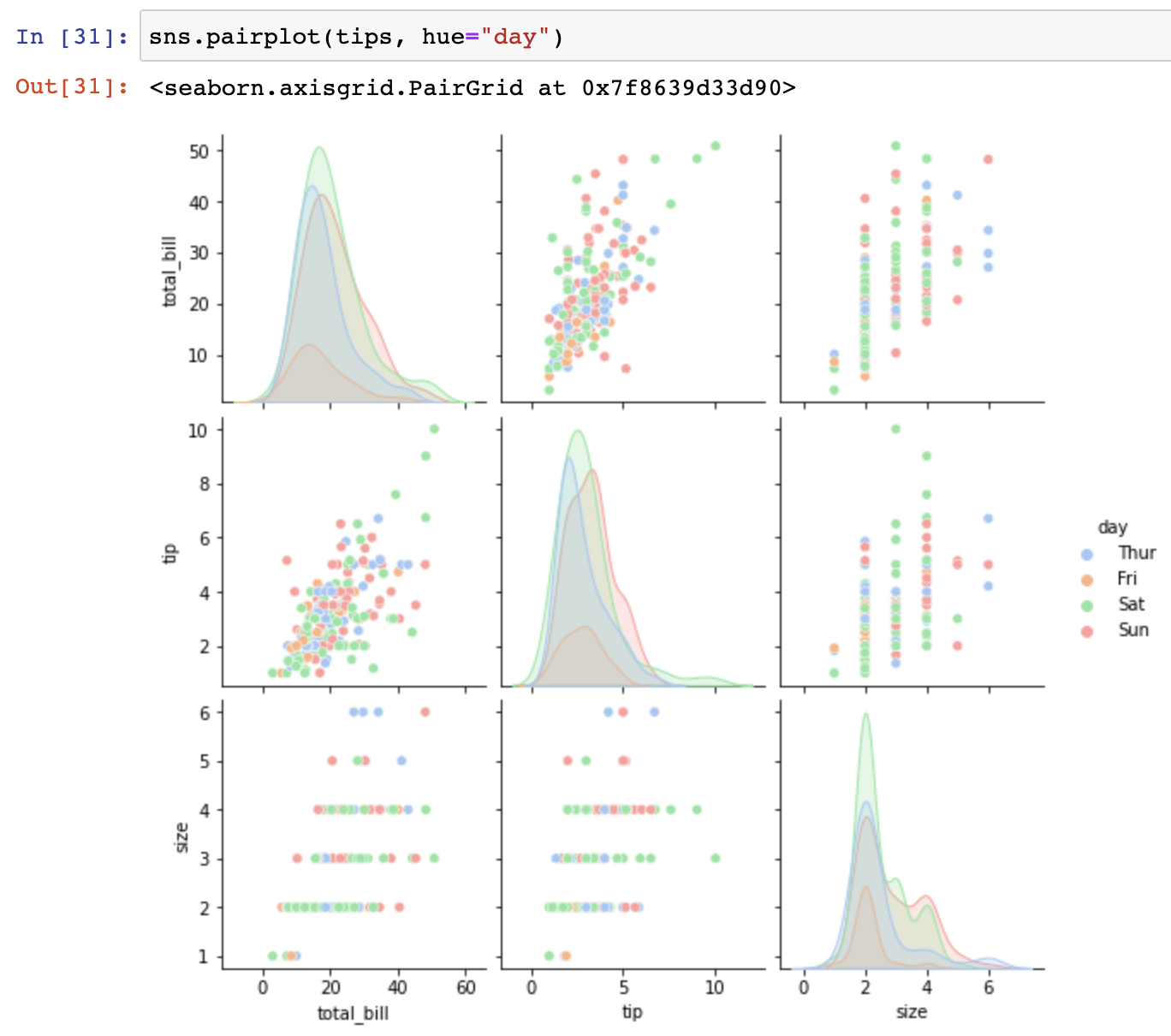
일일이 그래프를 그리지 않고 여러가지 그래프를 볼 수 있음.
day별로 total_bill을 표시하기
Interactive 시각화
상호작용이라는 뜻의 interactive.
상호관계라는게 클라이언트에게 데이터를 뿌리기만 하는 것이 아니라 그래프를 확대, 축소가 가능하게끔(상호작용)
google에 interactive 시각화를 검색하면 굉장히 많은 기능이 나옴.
데이터분석에 필요한 numpy
(파라미터 생성할때 순차적인 행렬, 간격 정할 때 이용-deep learning 이용), pandas(데이터 유형, 탐색), seaborn을 통해 그래프 그려봄.
3주뒤 정도 다시 다룰 듯.
다음 시간부터는 웹 페이지 크롤링(데이터 확보 방법)
중간고사 관련 정보
이런 기능들이 있었지..중복데이터 제거, 대체, 삭제하는법.. 해당 column에 있는 값 수정하는 법 등 키워드를 중심으로 구글링할 수 있어야.
시험 문제로 나올 예정(누가 빨리 찾느냐)
꼭 실습을 해봐야 함!
참고
https://leebaro.tistory.com/entry/%EB%B0%95%EC%8A%A4-%ED%94%8C%EB%A1%AFbox-plot-%EC%84%A4%EB%AA%85
