preview
네이버 오픈 api를 활용한 크롤링을 진행했음
주피터 노트북이 아닌 파이참을 쓰는 이유: 객체의 속성값, 하위 속성 ... => 디버깅을 하며 계속 확인 가능
단편적으로 한 줄 한 줄 씩 실행하려면 주피터 노트북이 적절하나, 디버깅을 하기위해 파이참을 사용.
https://developers.naver.com/docs/serviceapi/search/news/news.md#%EB%89%B4%EC%8A%A4
Breaking point
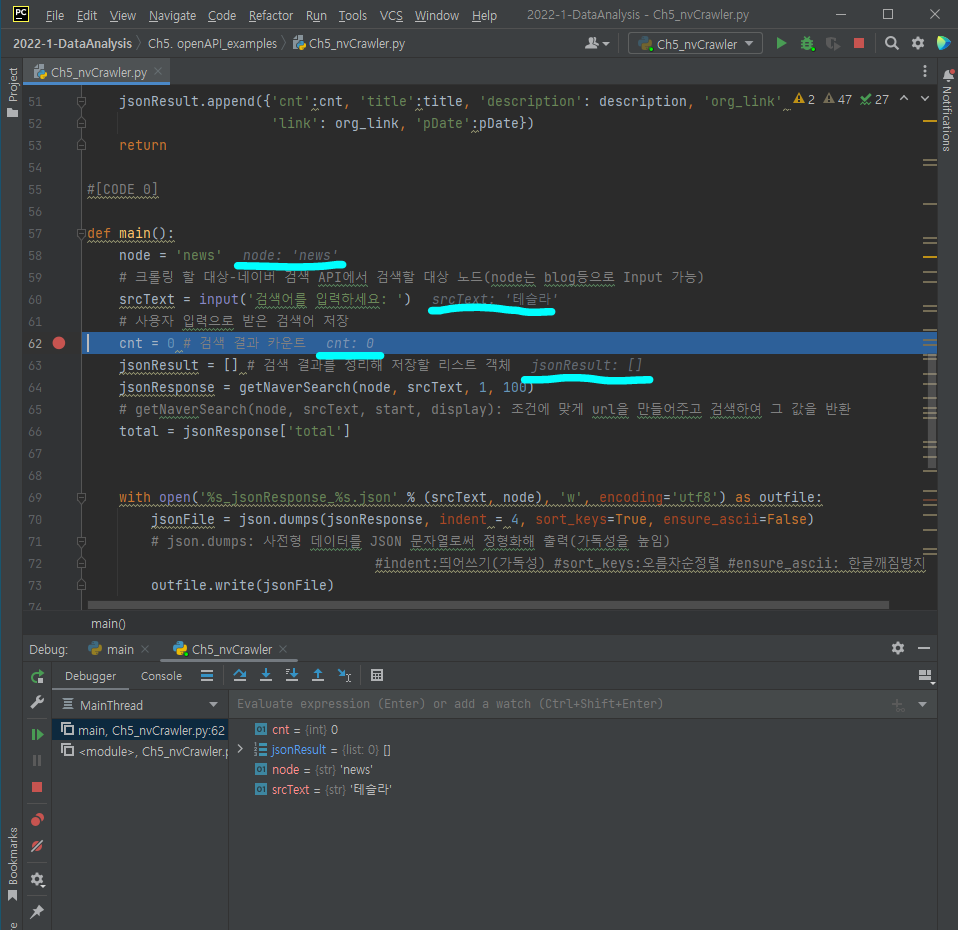
행 번호 옆을 클릭하면 빨간 점이 생기는데, 이를 'Breaking point'라고 하며 디버깅을 위해 사용된다.
보통 에러가 나는 줄 바로 위를 잡아 디버깅을 수행한다.
네이버 오픈 API를 이용한 네이버 뉴스 크롤링
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print ("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return Noneurl말고, header 정보에 정보를 붙여 전송 가능.
req라는 url을 호출하는 객체를 만들어 호출
response는 file과 유사한 객체.
원하는 데이터를 뽑으려면 read를 해주고 unicode(utf-8)로 변환한다.
def main():
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) #[CODE 2]
#디폴트는 10, 최대 100개까지 가능
total = jsonResponse['total']딕셔너리 형태의 jsonResponse.
딕셔너리 => json 파일로 변환 후 저장
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']: #item = 뉴스 url
cnt += 1
getPostData(post, jsonResult, cnt) #[CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) #[CODE 2]item을 하나씩 읽어온다.
getPostData를 통해 json 형태로 저장(?)
jsonResponse의 start = 1
1000개까지만 네이버 openAPI가 지원하니, 1001가 되는 순간 반복문을 빠져나온다.
키워드를 가지고 뉴스 검색 해 임의의 JSON 형태로 파일이 저장됨.
크롤링을 했던 사례 어떤 사이트를 어떤 방법으로 크롤링해서 어떤 데이터를 가져왔다~ 지원은 선착순 메일로-3명 (혜택은 2회 과제면제권 )
공공데이터포털 이용
API란?
서버 같은 걸 만든 후 서비스를 하고 싶음 => 사용자에게 어떻게 요청, 응답을 할지 (모든 시스템에 있으나 공개가 되지 않음. 공개가 된 것이 오픈 API임)
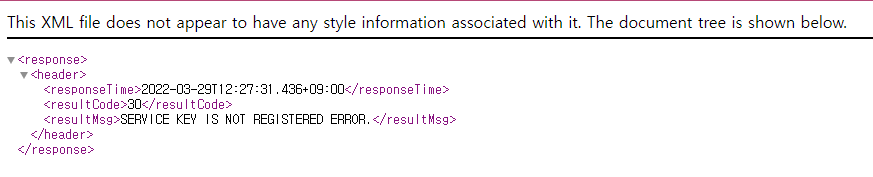
아직 승인 전에 미리보기 클릭 시 아직 API가 승인되지 않았다는 오류 발생함
인증키?
API 환경 또는 API 호출 조건에 따라 인증키가 적용되는 방식이 다를 수 있습니다.
포털에서 제공되는 Encoding/Decoding 된 인증키를 적용하면서 구동되는 키를 사용하시기 바랍니다. * 향후 포털에서 더 명확한 정보를 제공하기 위해 노력하겠습니다.
-
encoding
html에서 직접 호출하거나 'url'을 만들어 직접 호출할때 이용
(네이버 뉴스 크롤링 할 때도 URL을 호출함으로써 크롤링함) -
decoding
url을 직접 지정하지 않음.
request 모듈을 이용할때와 같이 파이썬 함수의 힘을 빌려 사용할때 이용
Ch5_openapi_tour.py
해당하는 가상환경에서 가져와서 열린 가상환경 터미널
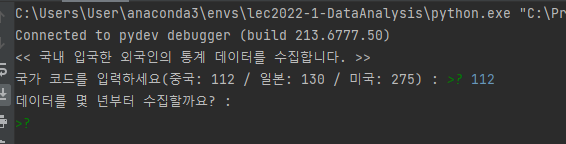
getTourismStatsService에는 입,출국/ start와 종료시점을 넣으면 jsonResult등이 나온다.
F7을 눌러서 함수 안으로 들어간다.
f9을 눌러 jump 가능
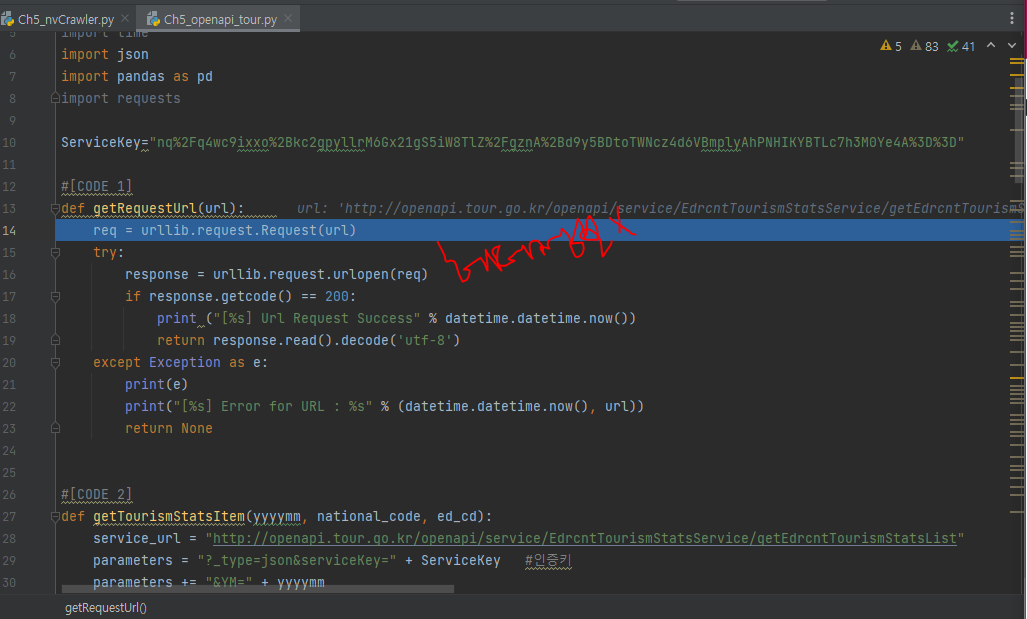
네이버 api와 달리 헤더정보가 없다.
내용을 읽어와야 해독이 가능하다.
return json.loads(retData)json 데이터를 불러옴
item에 검색된 데이터(딕셔너리)를 잘 확인해보자.(결괏값)
response header의 메시지가 ok인지 확인.
natName = natName.replace(' ', '')
을 통해 국가명에 띄어쓰기된 것을 없애준다.
jsonResult.append({'nat_name': natName, 'nat_cd': nat_cd, 'yyyymm': yyyymm, 'visit_cnt': num})
result.append([natName, nat_cd, yyyymm, num])append를 통해 딕셔너리에 값을 계속 추가해준다.
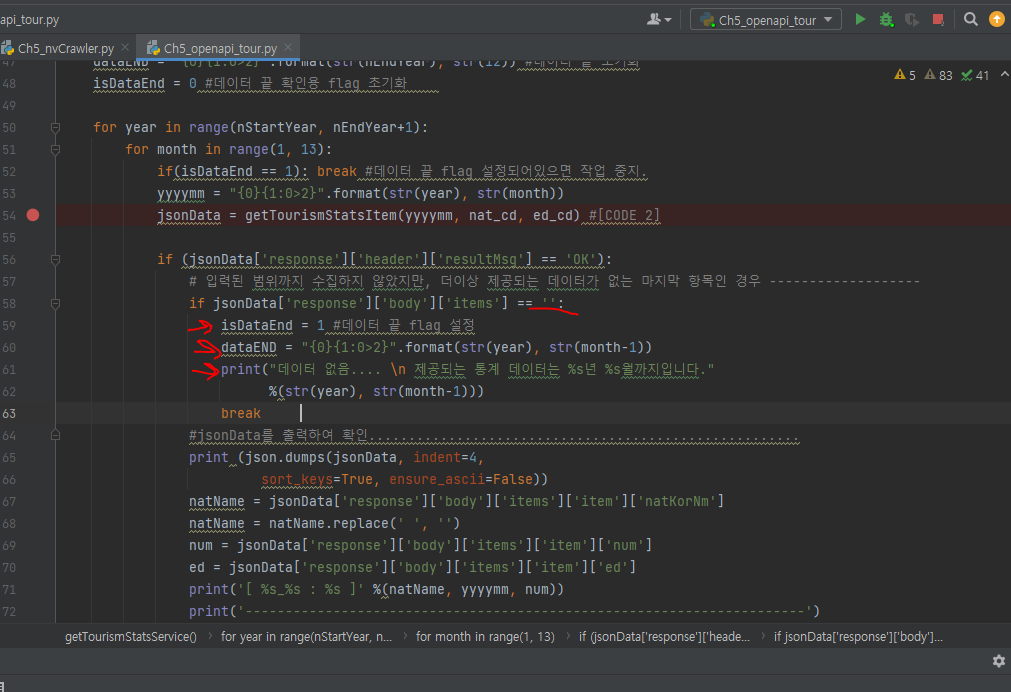
만약 데이터가 더 이상 없다면, if문의 걸려 break 된다.
openapi.pharmacy.py
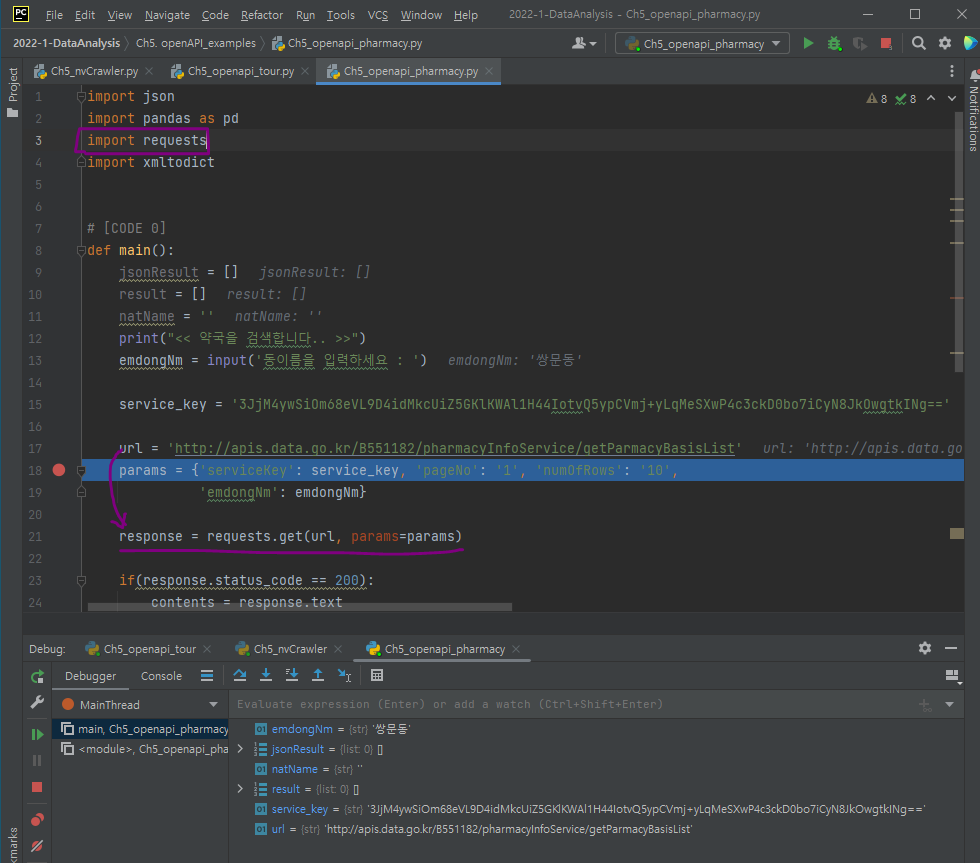
requests를 임포트 한 후, requests.get 메소드 사용
인증키 선택?
일반인증키는 Encoding과 Decoding이 있는데 웹 브라우저에서 바로 Call 하고 싶을 때는 Encoding 인증키를 사용하고 프로그램으로 돌리고 싶을 때는 Decoding 인증키를 사용하면 알아서 Encoding으로 데이터를 불러옵니다.
url='http://apis.data.go.kr/B551182/pharmacyInfoService/getParmacyBasisList'
params = {'serviceKey': service_key, 'pageNo': '1', 'numOfRows': '10',
'emdongNm': emdongNm}파라미터는 완전한 텍스트가 아닌 딕셔너리 형태임=> url을 직접 지정하지 않았으니 Encoding이 아닌**decoding** 인증키를 사용하면 된다!
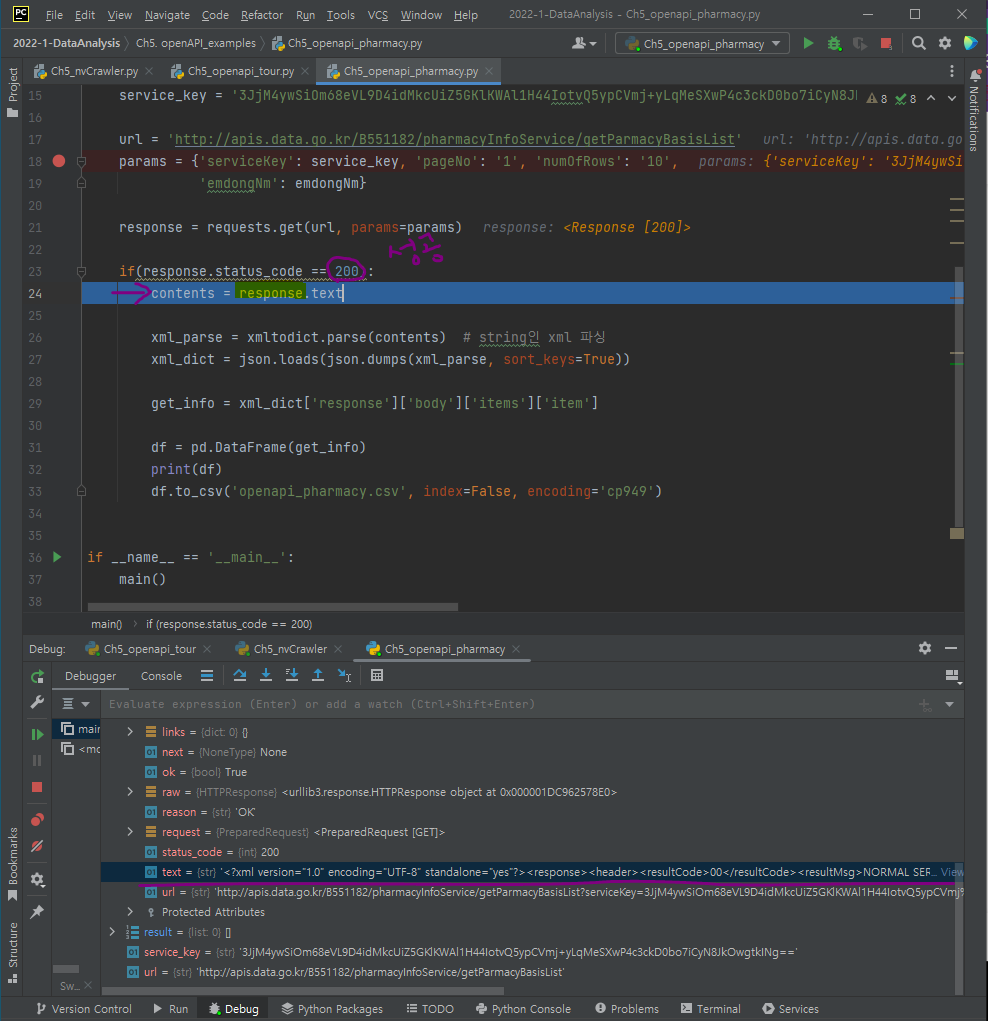
response 객체가 받은 정보(plain text=xml)를 dictionary로 변환하기 위해 사용하는 라이브러리 => xmltodict
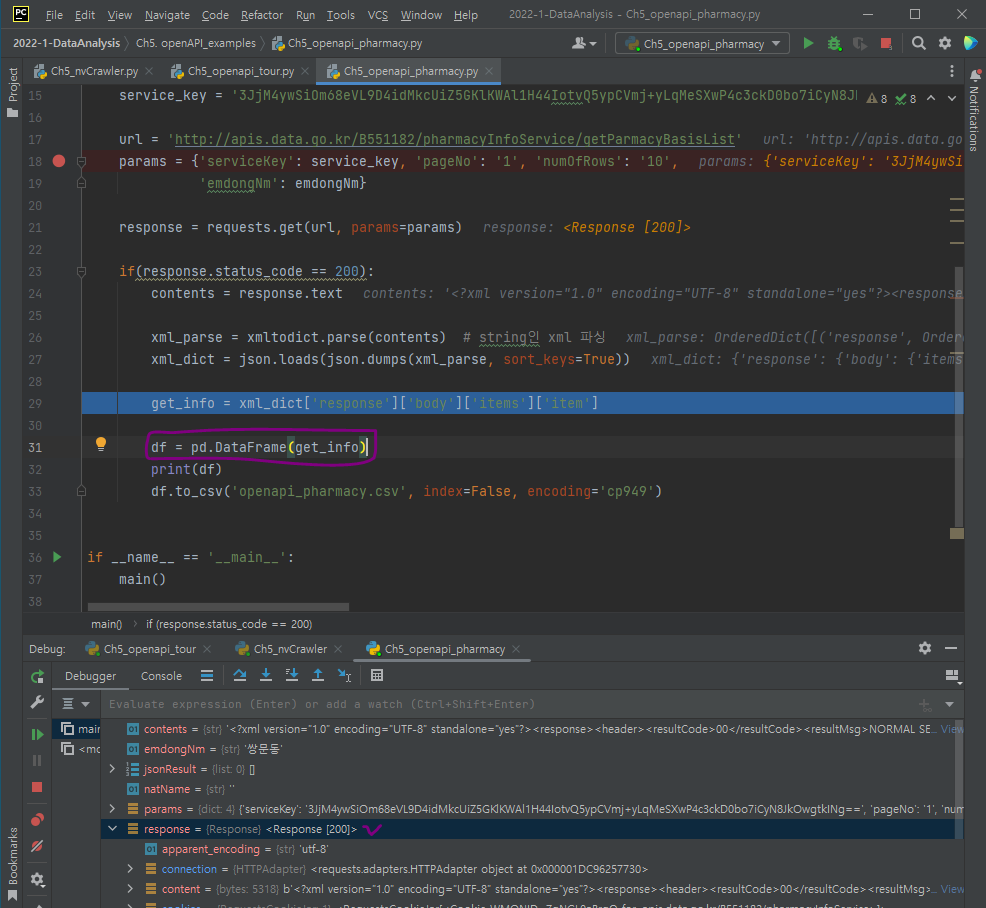
바뀐 response 객체의 dictionary 데이터를 데이터프레임으로 변환할 수도 있음.
그렇다면,
앞서 배운 파일인 openapi_tour.py 파일을 openapi_pharmacy.py파일에서 사용한 형식으로 바꿔보자.(=requests 패키지를 사용 + response된 데이터인 xml을 dictionart로 변환)
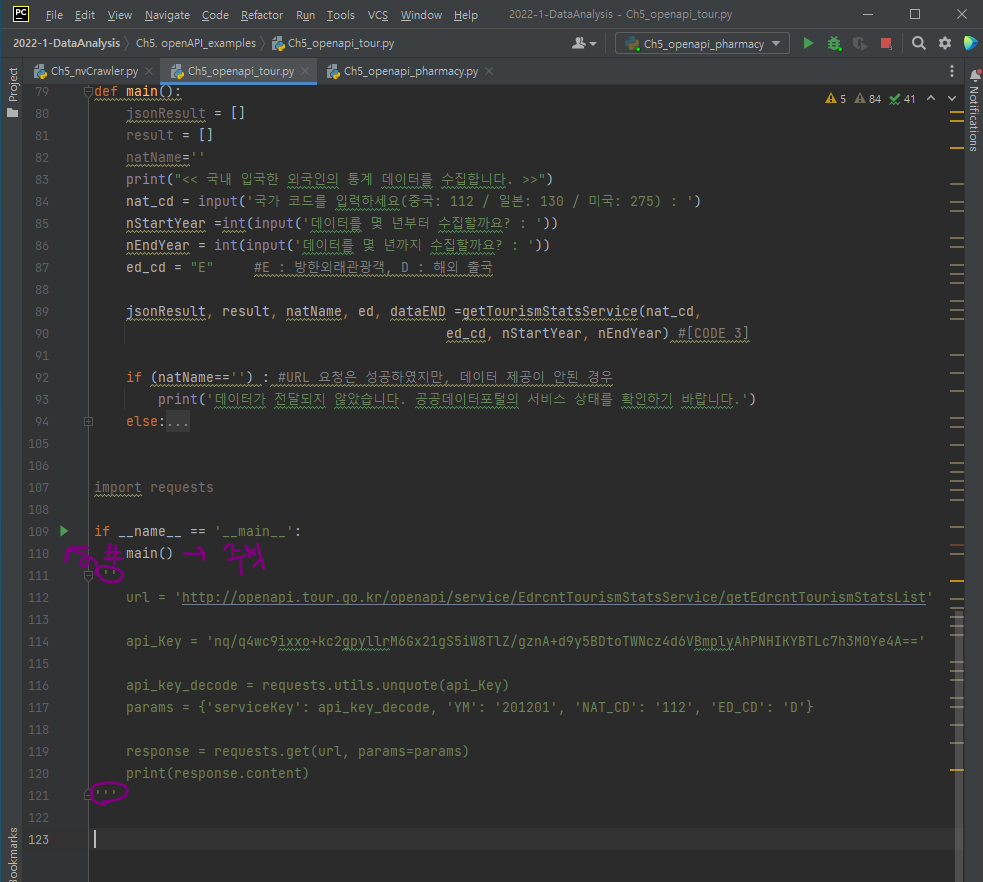
if __name__ == '__main__':
main()
...에서
1. main()을 주석처리하고,
2. url='..'부터의 주석처리한 것을 취소해주자.
api_key를 encoding key에서 decoding key로 변환
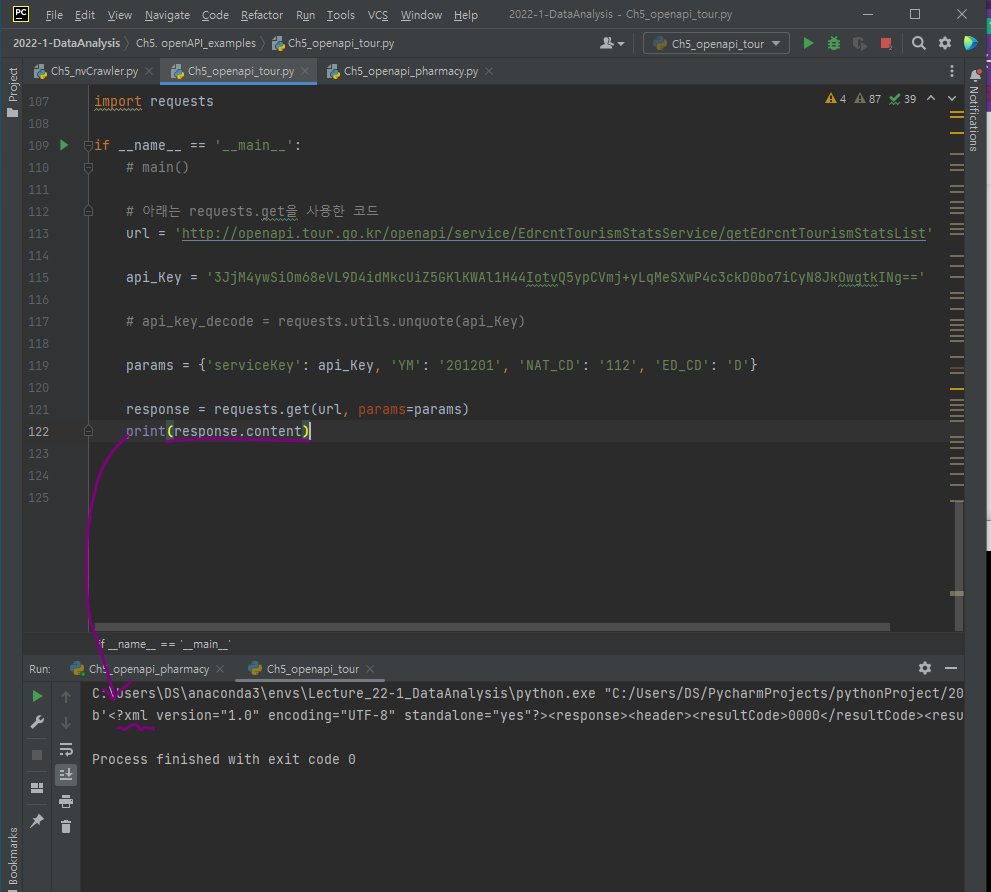
api_key를 바꾼 후 response.content를 print해보면 xml 형태로 데이터가 출력되는 걸 알 수 있다.
따라서 xml => dictionary 형태로 변환해보자.
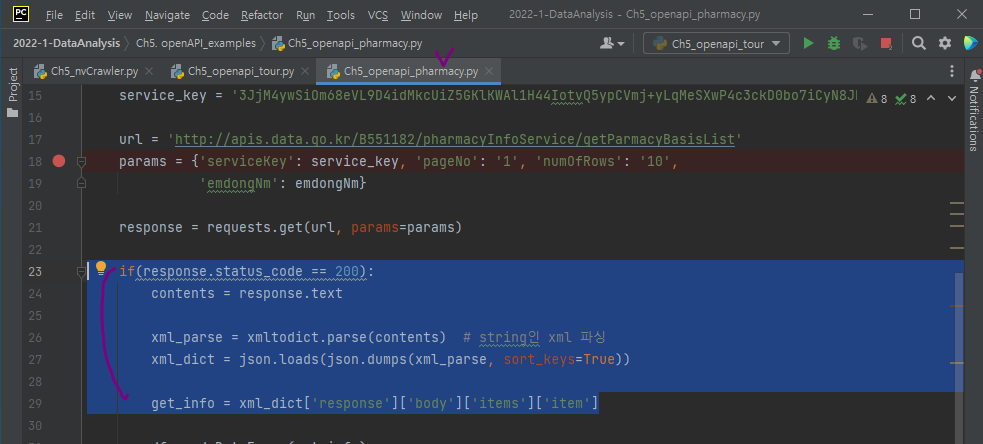
그러기위해 openapi_pharmacy.py의 xml을 변환한 코드를 복사해오자.
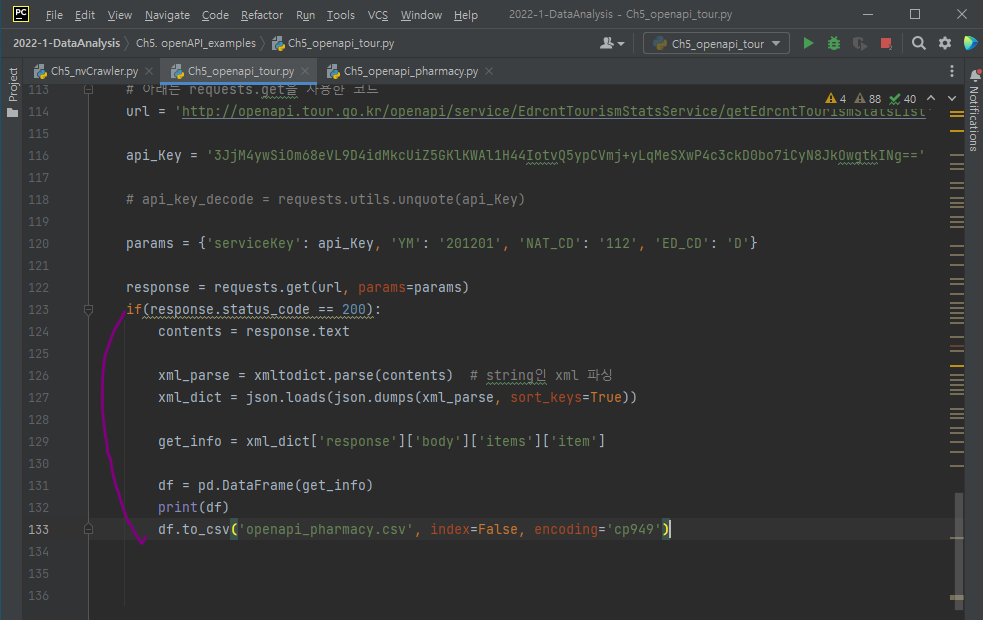
dataFrame으로 출력하기 위한 코드 추가
또한, params 변수에 입/출국 변수 설정에서 D(출국) => E(입국)으로 변경하자.
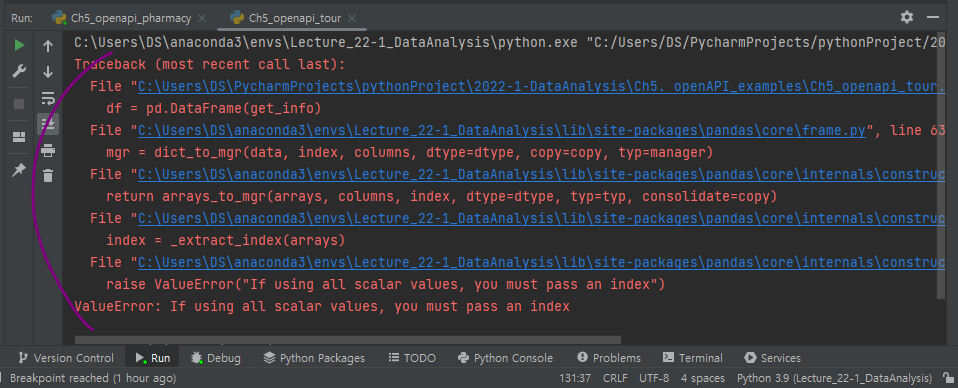
실행시키면 오류가 나는데,
json이 1차원 데이터(scalar values)라 pandas에서 dataframe으로 변환하고자 해서 발생한 오류.
dataframe이 아닌 series로 바꾸면 오류가 해결될 것.
이렇게 하지 않고 스칼라든 시리즈든 데이터프레임으로 바꾸려면?
pd.json_normalize(get_info)
pandas의 json_normalize을 이용한다.
1차원, 2차원 상관없이 json 데이터를 데이터프레임으로 바꿔준다!
데이터프레임을 만들때,
1. 컬럼을 직접 지정해주거나
2. json_normailize을 이용하면 이 아이가 컬럼을 직접 만들어준후 데이터프레임 생성
과제
- nvCrawler.py =>
requests 모듈을 써서 해보기- 데이터 뽑아와서 csv로 저장하기
원래,
nvCrawler.py, tour.py => url 직접 호출하는 방식을 배움
(코드 상으로 req = urllib.request.Request(url) 사용함)
그러나 pharmacy.py 에서 requests과 params를 따로 지정해 코드 작성했음
헤더 말고 파라미터로 넘겨보기
네이버는 html header에 정보를 담아 보냈음.
(url+파라미터 정보를 텍스트로 만든 정보를 보냄)
requests로 어떻게?
딕셔너리를 헤더로 넘기기~
결과를 해당되는 (주석 ######### or 하이라이트) 코드를 올리기(직접 실행해볼 예정)
