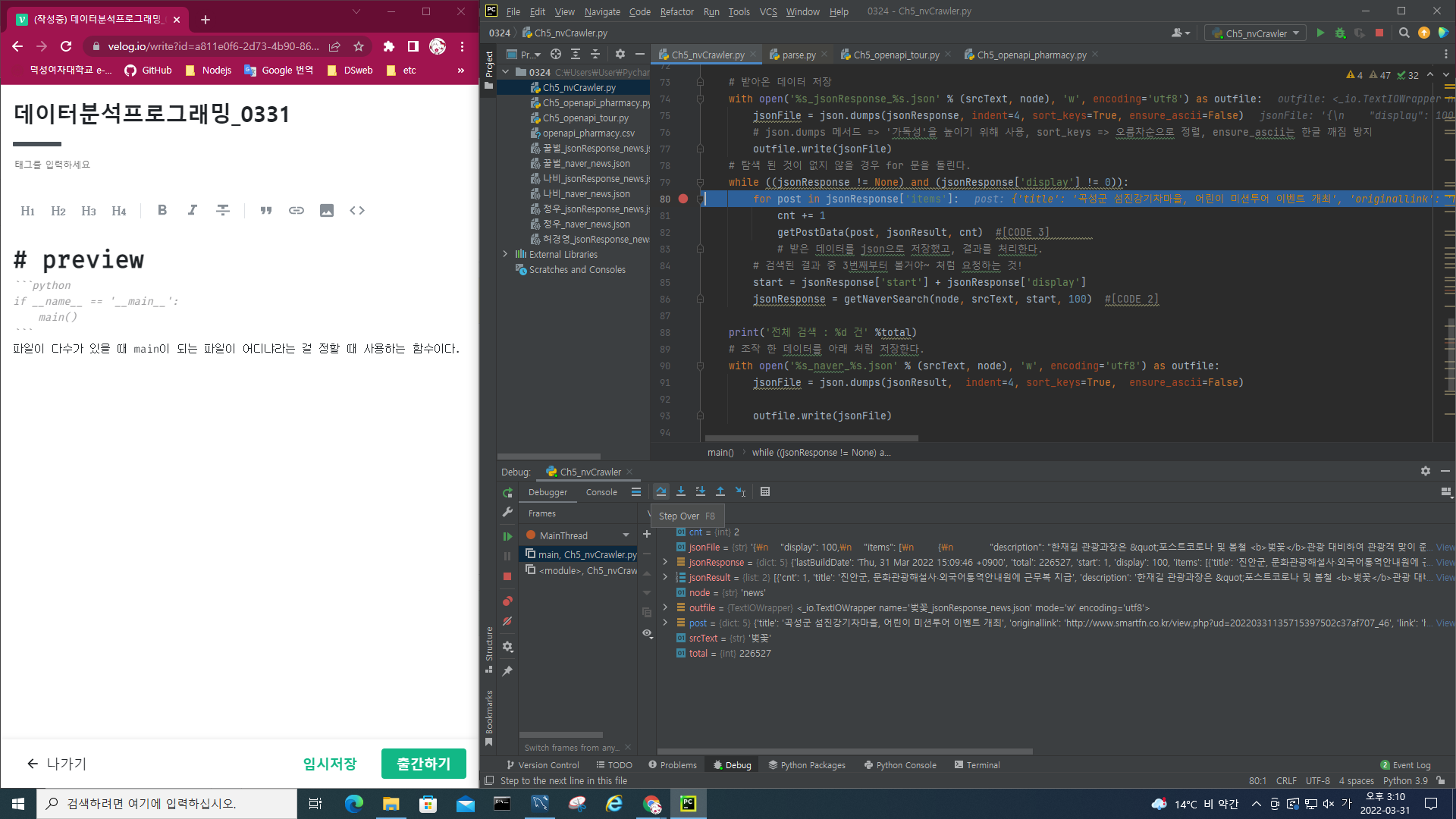
main
if __name__ == '__main__':
main() # main() 함수 호출파일이 다수가 있을 때 main(__main__)이 되는 파일이 어디냐라는 걸 정할 때 사용하는 함수이다.
지금은 하나의 파일밖에 없지만, 프로젝트 내 여러파일이 있을 경우 그 파일 중 시작하는 시점이 어디냐를 구별한다.
breaking point
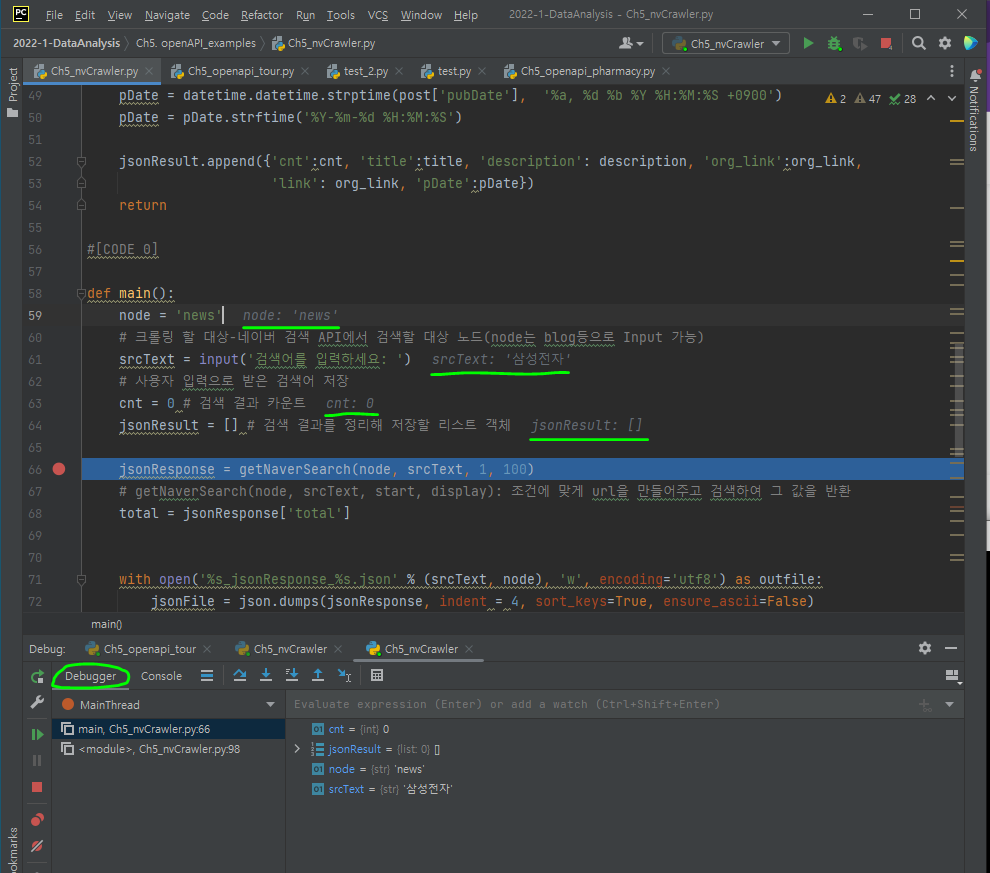
오류가 나는 부분 바로 전 줄에 breaking point를 건 다음 debug을 시행하면, 해당 포인트에서 실행이 멈추게 되고 코드 우측에 회색으로 breaking point을 한 함수의 **파라미터 값**들이 보이게 된다.
그 후 브레이킹포인트에서 어떻게 진행할거냐를 정해야하는데
F7
함수 안까지 들어가서 무슨일이 일어나고 있는지 보고 싶다, 호출한 함수가 올바른 결과를 반환하고 있는지 확신할 수 없을때 이 기능을 사용해 함수 내부 관찰 가능
F8
각각의 함수 실행 결과를 한번에 반영해 함수안으로 들어가지 않고 다음줄로 넘어가겠다, 실행결과를 return 받아 그 다음으로 넘어간다.
F9
한줄, 한줄 보지 않고 다음 브레이킹 포인트까지 넘어가서(Jump) 실행 결과를 보고싶다
정적 vs 동적
네이버에서 제공하는 오픈 API 말고 일반 웹페이지에서 데이터를 추출하고 싶을때는 어떻게 해야할까?
크롤링하려는 웹 페이지가 어떻게 구성되어있는지, html 태그 등을 잘 알고있어야 한다.
정적: static, 움직이지 않는다. 변하지 않는 것을 의미.
웹 브라우저에서 url을 입력하면 dns(domain name services)로 requests를 보냄
terminalping www.naver.com=> 어딘가에 접속을 해서 데이터를 받아와야!
pc는 dns에게 ping이라는 신호를 보내dns 서버에게 물어본다.pc: dns야, 데이터를 받으려면 어디에 요청을 해야 돼?
dns: 너가 요청한 신호는 [223.130.200.107]이야~
웹 브라우저가 dns 서버에 물어보고 url request을 한 다음, 받아온 정보를 화면으로 뿌리는 html 정보를 보내준다.
변경되지 않는 정보를 보여주는 건, 정적웹페이지이다.
예를 들어 유튜브의 경우, 새로고침을 할때마다 새로운 영상이 업데이트되므로 동적 웹페이지이다.
또한 네이버 지도의 경우, 선택한 지역별로 새로운 지도맵을 보여준다.
즉, 사용자 input에 따른 새로운 정보들을 제공하는 웹 페이지가 동적 웹페이지이다.
BeautifulSoup
목표: API를 제공하지 않는 웹 페이지를 크롤링 할 수 있다.
API 이용
url.requests -> response 결과로 xml, json형태의 데이터가 나와서 이를 파싱함.
일반 웹페이지(API 제공 X)에서 HTML정보를 요청하면 이를 Beautiful Soup로 처리해 json 형태로 보기 좋게 처리 가능.
즉, html 페이지를 json이나 엑셀처럼 구조화된 정보로 처리를 해준다.
pip install beautifulsoup4을 눌러 beautifulsoup4를 설치한다.
from bs4 import BeautifulSoup그냥 import 하지 않고 이렇게 한 이유는 다른 기능을 말고 'bs4라는 해당하는 함수만 쓰겠다! 라는 뜻이다.
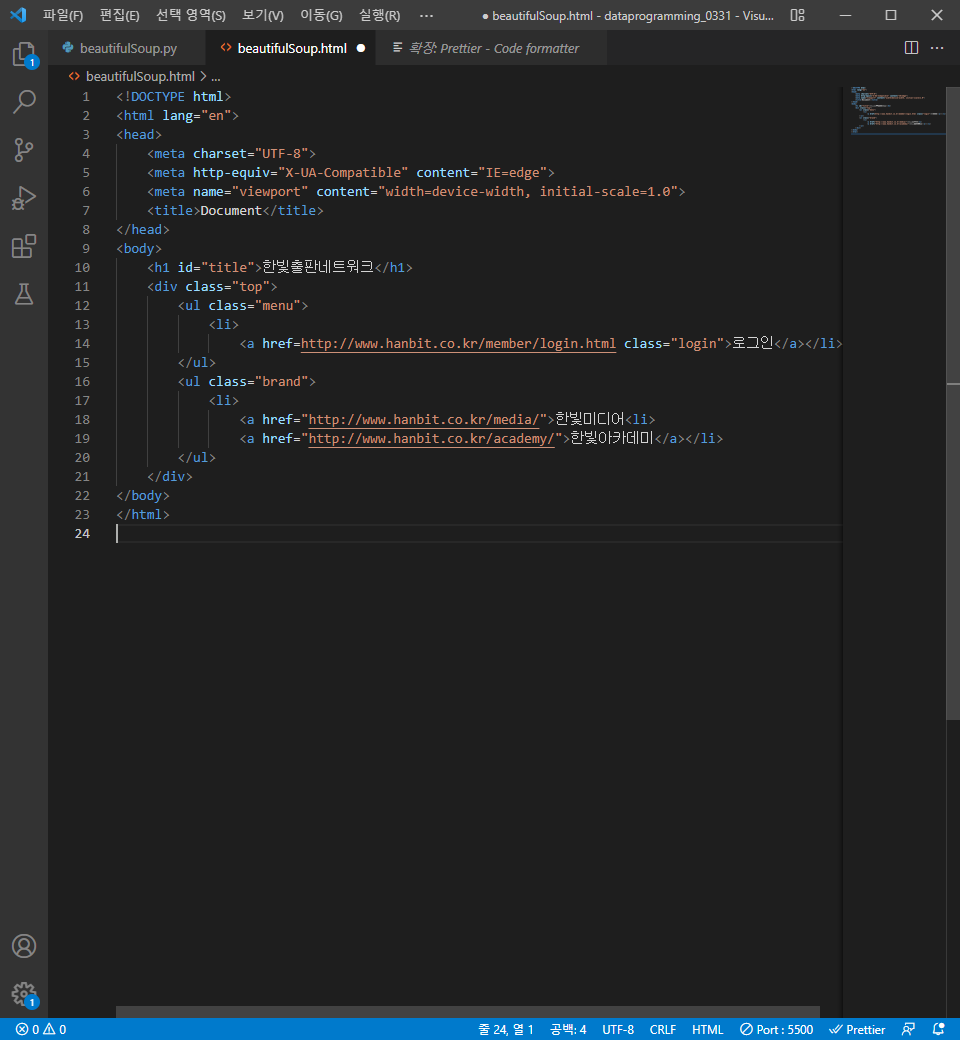
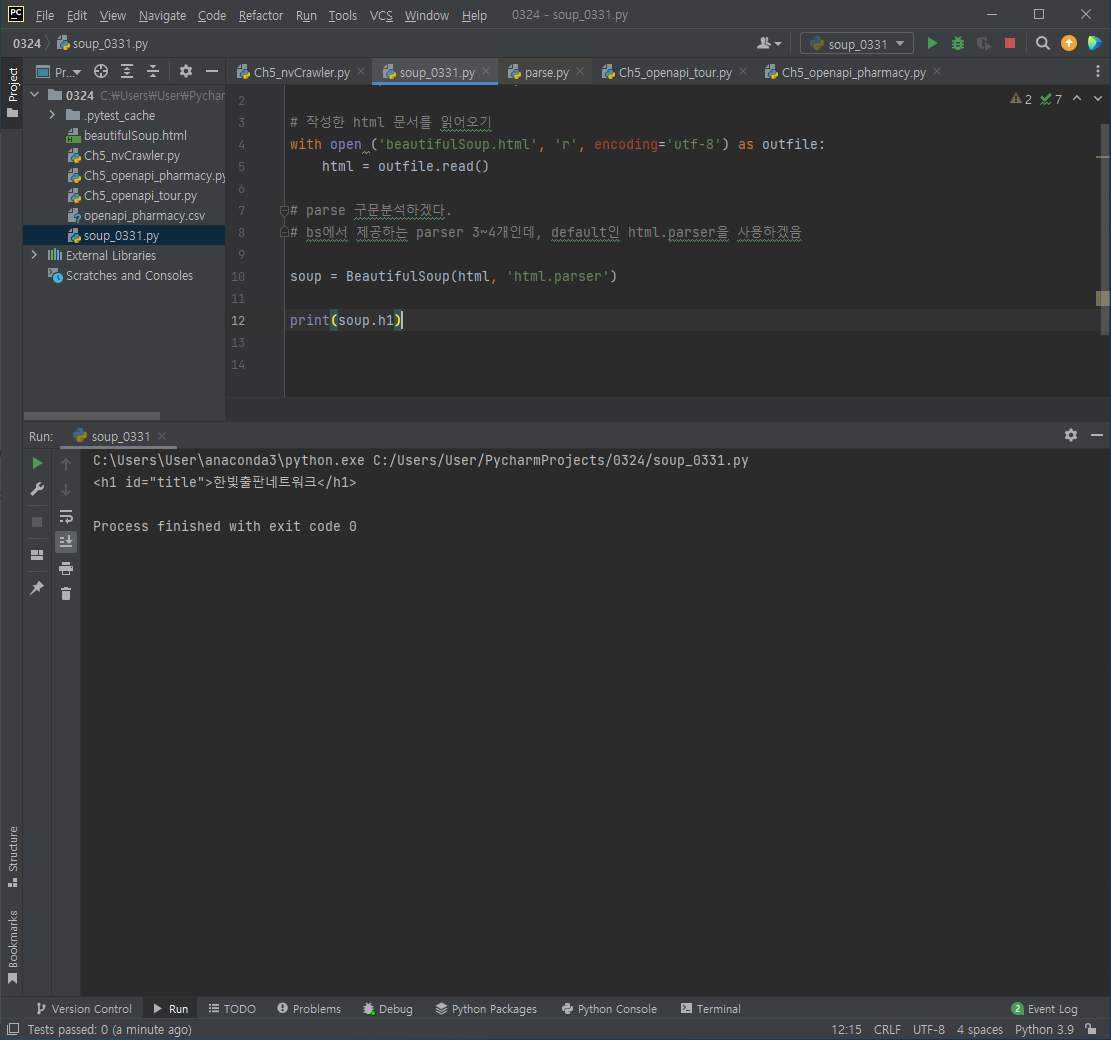
h1 태그가 하나만 있을 경우에는 soup.h1도 가능하지만
h1 태그가 두개 이상일 경우에는 soup.find('h1')으로 작성하자.
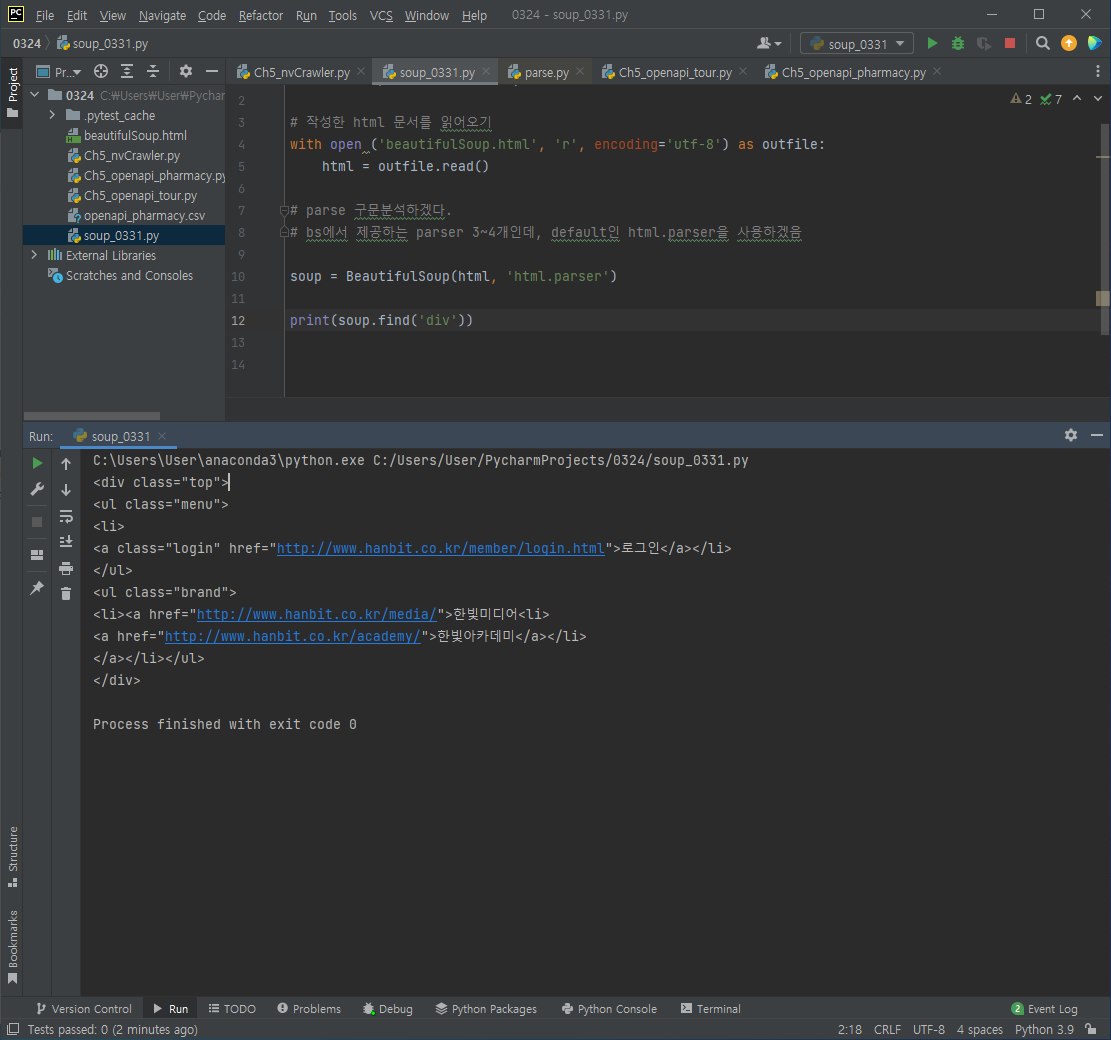
find 할 경우 제일 첫번째 있는 태그만 걸린다.
find_all할 경우 html 문서에 있는 해당 태그가 모두 걸린다.
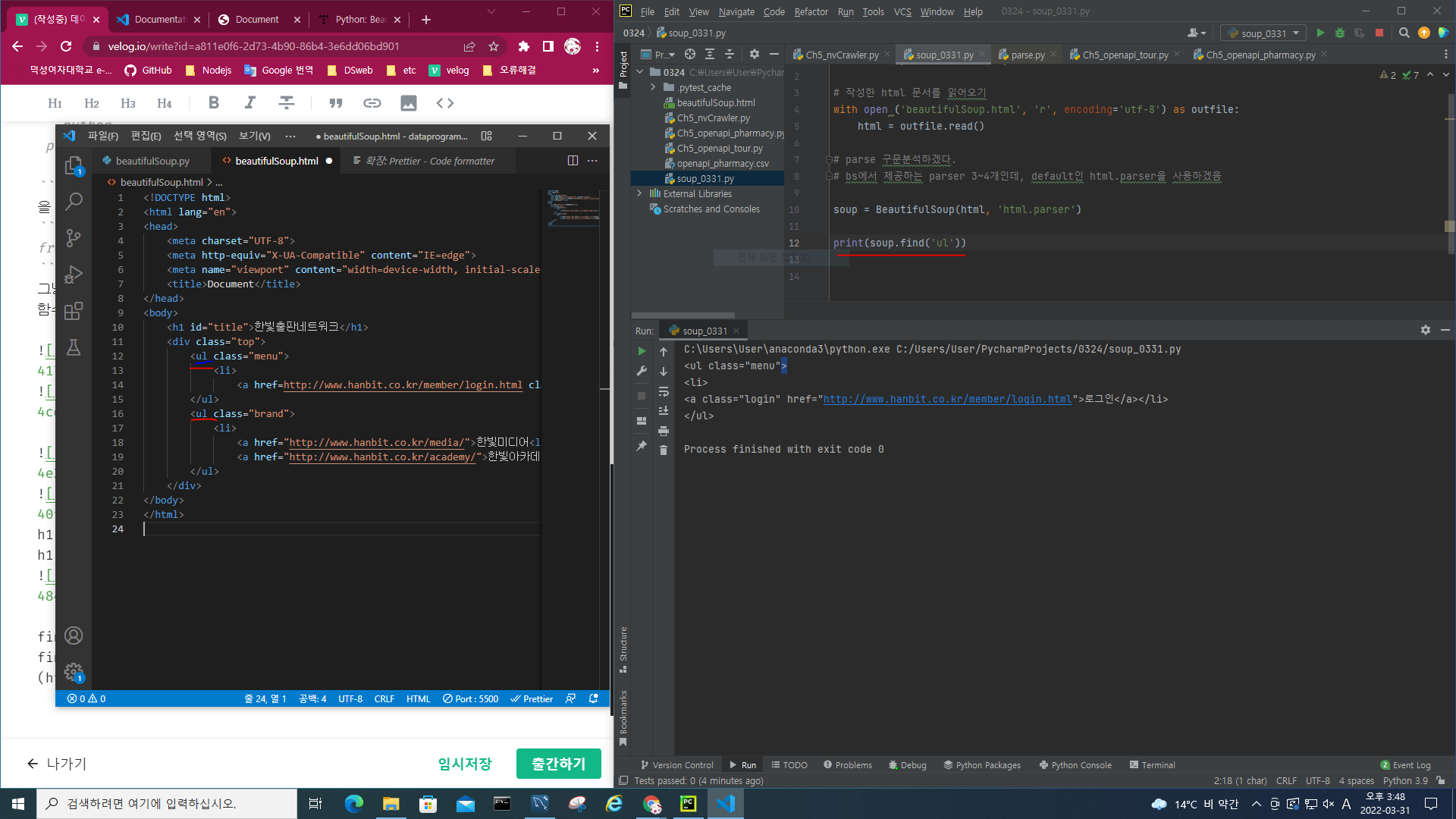
ul 태그가 2개인데, find 할 경우 첫번째 ul이 걸린다.
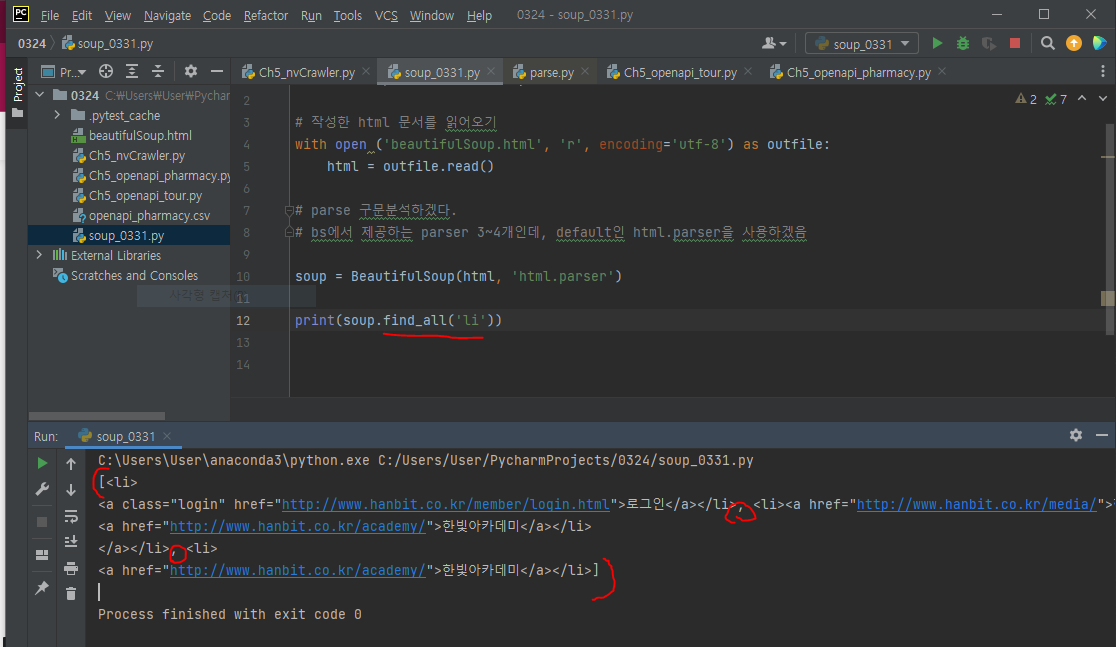
find_all로 li 태그들을 모두 가져온 모습이다.
대괄호 안에 li 태그들이 콤마(,)로 구분되어 있다.
속성을 이용해 파싱하기
1) attrs: 속성 이름과 속성 값으로 딕셔너리 구성
ex. {'class': 'brand'}
2) find(): 속성을 이용해 특정 태그 파싱
ex.
soup = BeautifulSoup(html_text, 'html.parser')
soup.find(id="title")
soup.find(class_='brand')
# class는 파이썬 예약어라 _로 구분필수
# 한 단계 아래 있는 <li>태그를 전체를 뽑고싶다면?
(soup.find(class_='brand').find_all('li'))
# 뽑은 결과인 리스트 중 몇번째 정보를 이용하고 싶은지? 인덱스로 접근해 선택가능
(soup.find(class_='brand').find_all('li')[1])3) select(): 지정한 태그를 모두 파싱해 리스트 구성
태그이름#id 속성값
태그이름.class 속성값
li_list = soup.select("div>ul.brand>li")
print(li_list)
# [<li><a href="http://www.hanbit.co.kr/media/">한빛미디어</a></li>, <li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li>]
for li in li_list:
print(li.string) # 원소의 string 값 출력
# print(li.text)와 결과 동일
# 한빛미디어
# 한빛아카데미from bs4 import BeautifulSoup
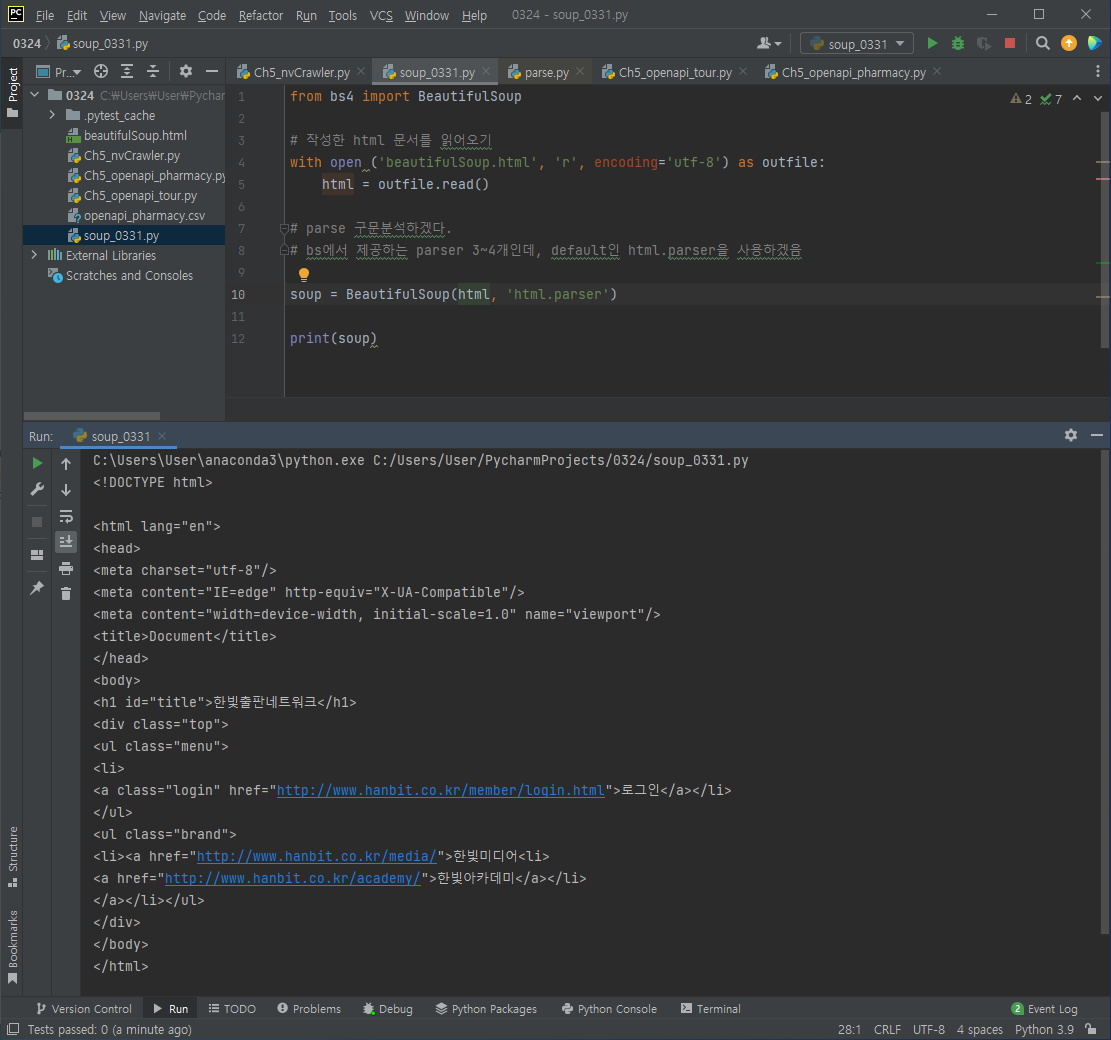
# 작성한 html 문서를 읽어오기
with open ('beautifulSoup.html', 'r', encoding='utf-8') as outfile:
html = outfile.read()
# parse 구문분석하겠다.
# bs에서 제공하는 parser 3~4개인데, default인 html.parser을 사용하겠음
soup = BeautifulSoup(html, 'html.parser')
'''
tag_a = soup.find("a")
print(tag_a.attrs)
print(tag_a['href'])
# class는 파이썬 '예약어'라 clas라는 변수를 사용할 땐 '_(언더바)'를 붙여주자
# class_ = 'brand' 이렇게 작성
print(soup.find(class_='brand').find_all('li'))
'''
# li_list는 리터러블한 객체
li_list = soup.select("div>ul.brand>li")
print(li_list)
for li in li_list:
print(li.string)
# print(li.text)
# print(li.get_text())
# 위 세개는 모두 결과가 동일함
