회귀분석
- 독립변수(11개)에 대한 회귀 변수를 배움
- 다양한 데이터가 도출되지만, 가장 중요하게 봐야 할 데이터는
R-squared이다.
R-squared
결정계수이며, R 제곱이라고 불린다. 결정계수는 회귀 모델에서 독립변수가 종속 변수를 얼마만큼 설명해 주는지를 가리키는 지표.
설명력이라고도 불린다.
즉, 결정계수가 높을수록 독립변수가 종속변수를 많이 설명한다는 뜻이다.
- 0.292(29.2%)이면 독립변수가 종속변수의 30% 정도를 설명한다.
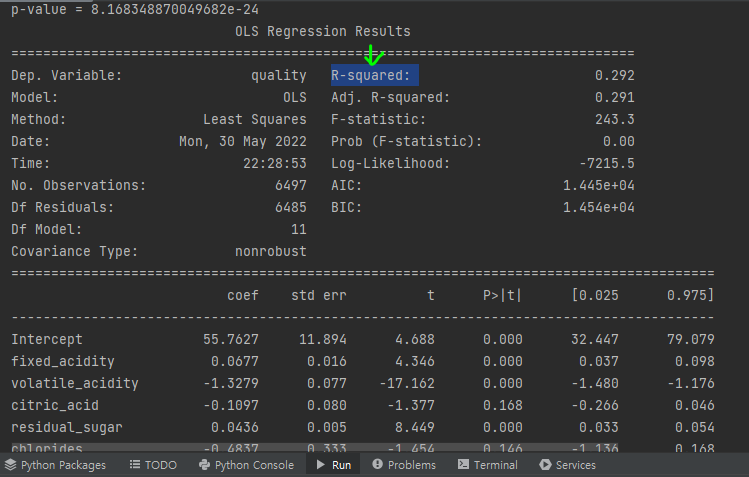
기본적으로 50~60%는 맞아야 그래도 쓸만한 모델임을 알 수 있음
각각의 독립변수에 대한 회귀계수(coefficient)는 주어진 데이터를 가장 잘 표현하는 y절편과 기울기이다.

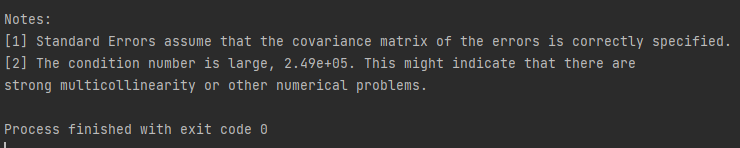
실행 결과에 출력된 warnings의 원인?
독립 변수값의 단위와 범위가 다른 것과 독립 변수 간의 높은 상관관계로 인해 다중 공선성(multicollinearity)문제가 발생한 것에 대한 경고이다.
즉 x축, y축의 범위가 안 맞아~라는 의미
=> 데이터 normalization이 필요하다!
What is 다중공정성?
ex)
1. 술 섭취량과 시험성적과의 상관관계
2. 혈중알코올농도와 시험성적과의 상관관계
=> 이때 술 섭취량-혈중알코올농도는 서로 비슷한 데이터셋으로 상관관계가 높다.
이처럼 독립 변수의 일부가 다른 독립 변수의 조합으로 표현될 수 있는 경우를 다중공선성이라고 하며, 독립 변수들이 서로 독립이 아니라 상호상관관계가 강한 경우에 발생!
다중공정성으로 불필요한 모델로 복잡성이 올라가고 성능이 나빠짐(따라서 여러개의 독립변수를 제거함)
=> 이때 PCA 기법을 가장 잘 사용.
데이터분포가 안 맞음/다중공정성이 있는 데이터가 있는 경우
1. 분포를 맞춰주거나(정규화)
2. 중복되는 독립변수 제거 요망(PCA)
회귀분석
회귀분석 하는 이유
=> 추정을 하기 위해
기존 데이터로 새로운 데이터의 결과가 어떻게 도출될까?
위 질문에 대한 답을 구하기 위해 회귀분석을 사용함.
회귀 분석 모델로 새로운 샘플의 품질 등급 예측하기
회귀 분석 모델을 이용해 새로운 샘플 데이터의 품질 등급을 예측하려면 먼저 독립 변수인 11개 속성에 대한 샘플 데이터가 필요하다.
이를 위해 임의의 샘플 2개를 만들어 예측을 수행해보자.
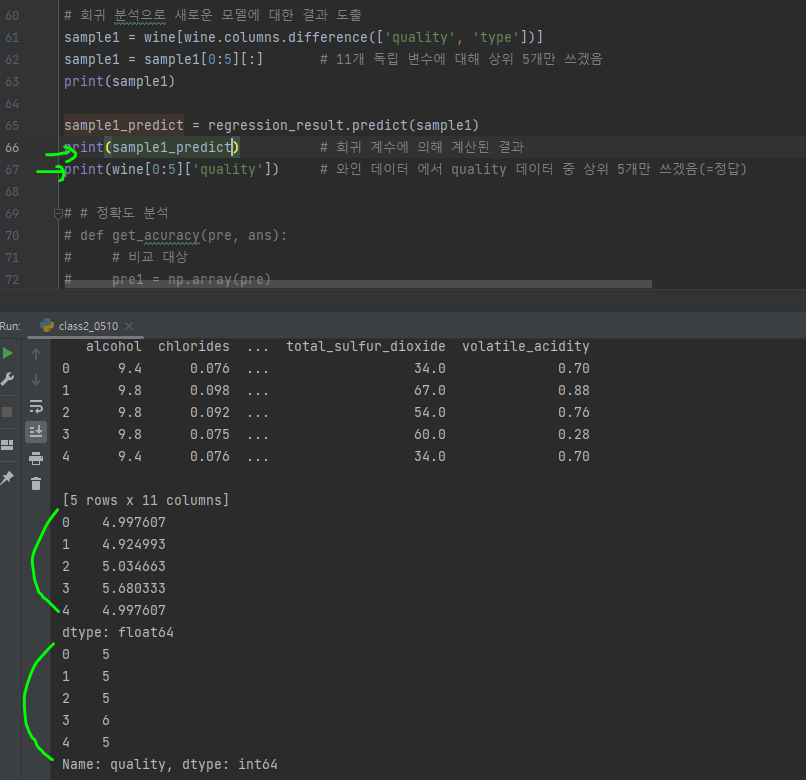
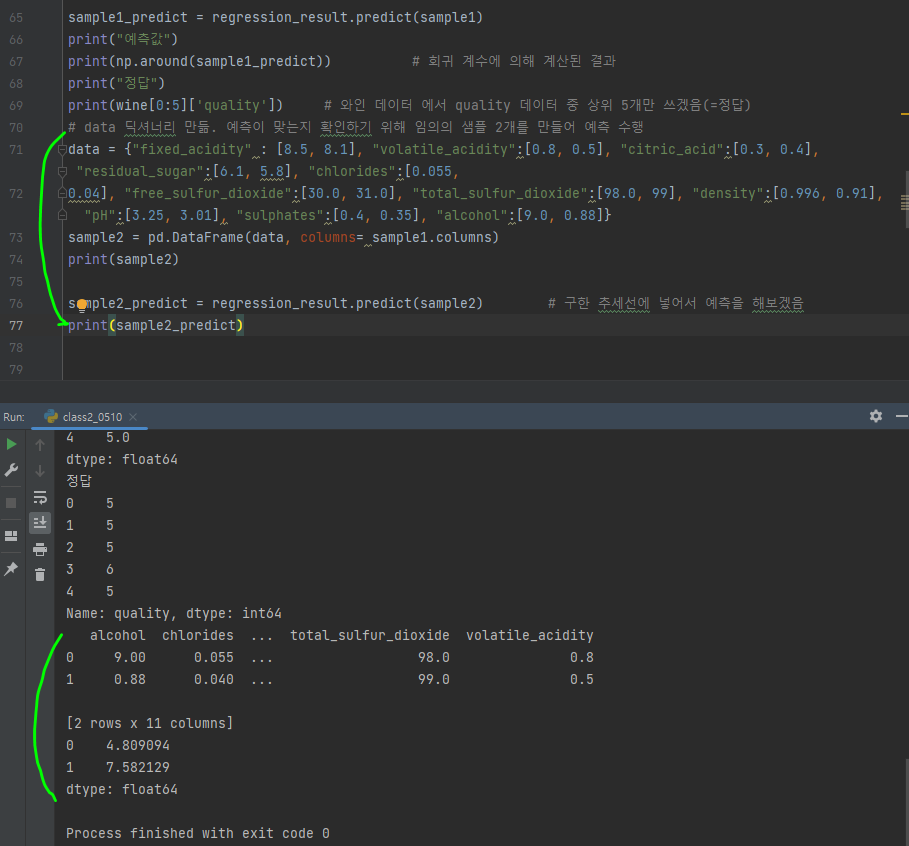
- 회귀식에 사용한 독립 변수에 대입할 임의의 값을 딕셔너리 형태로 만든다.
- 딕셔너리 형태의 값과 sample1의 열 이름만 뽑아 데이터 프레임으로 묶은 sample2를 만든다.
- sample2를 출력해 제대로 구성되었는지 확인
- 샘플 데이터를 회귀 분석 모델인(regression_result)의 예측 함수 predict()에 적용해 수행한 후 결과 예측값을 sample2_predict에 저장
- 출력해 예측한 quality를 확인
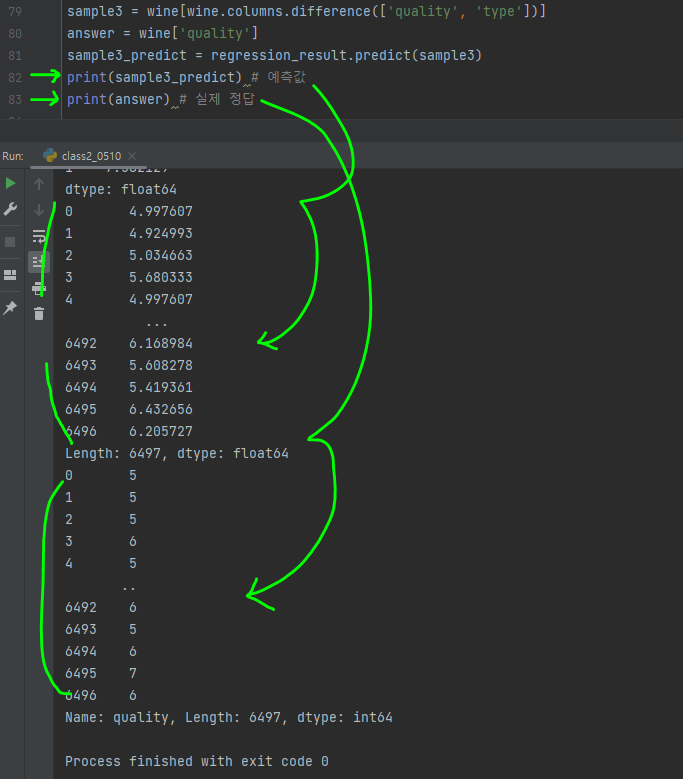
- 정확도 분석
prediction 한 값, answer 값 비교 후 맞았으면 1, 틀렸으면 0이 출력되게끔
기존 파이썬라이브러리 기능을 사용시 정확도 50% => 규칙을 바꾸면 정확도가 올라갈 수 있음
결과 시각화
분석 결과를 시각화하기 위해 와인 유형에 따른 품질 등급을 히스토그램과 부분 회귀 플롯으로 나타낸다.
와인 유형에 따른 품질 등급 히스토그램 그리기
결과를 시각화해 나타내기 위해 와인 유형에 따른 품질 등급을 히스토그램으로 먼저 나타내보자.
히스토그램은 matplotlib.pyplot라이브러리 패키지와 seaborn 라이브러리 패키지를 사용해 나타냄.
아래 코드 입력
# 결과 시각화
import matplotlib.pyplot as plt
import seaborn as sns
red_wine_quality = wine.loc[wine['type'] == 'red', 'quality']
white_wine_quality = wine.loc[wine['type'] == 'white', 'quality']
sns.set_style('dark') # 히스토그램 차트의 배경색 스타일 설정
# 레드 와인에 대한 histplot 객체 생성
sns.histplot(red_wine_quality, kde=True, color="red", label='redwine')
# 화이트 와인에 대한 histplot 객체 생성
sns.histplot(white_wine_quality, kde=True, label='white wine')
# 차트 제목 설정
plt.title("Quality of Wine Type")
# 차트 범례 설정
plt.legend()
# 설정한 내용대로 차트 표시
plt.show()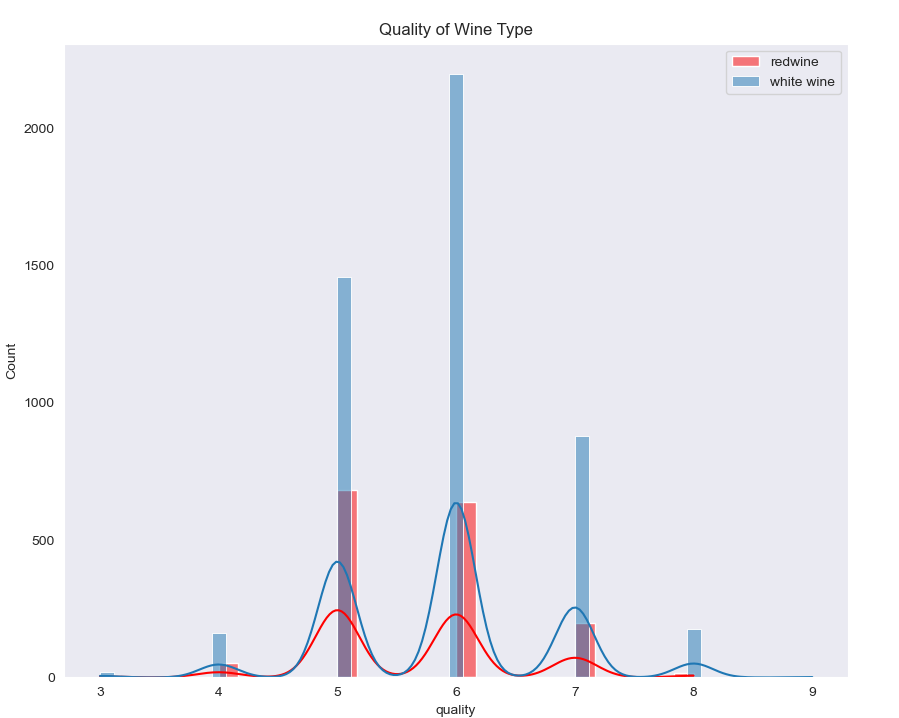
커널밀도함수 적용 => smooth하게
커널밀도함수 란?
커널함수(적분값이 1이고, 양함수)를 바탕으로 확률 밀도를 추정
참고
https://niceguy1575.medium.com/kernel-density-estimation-kde-%EC%BB%A4%EB%84%90%EB%B0%80%EB%8F%84%ED%95%A8%EC%88%98-7f214643c0e1
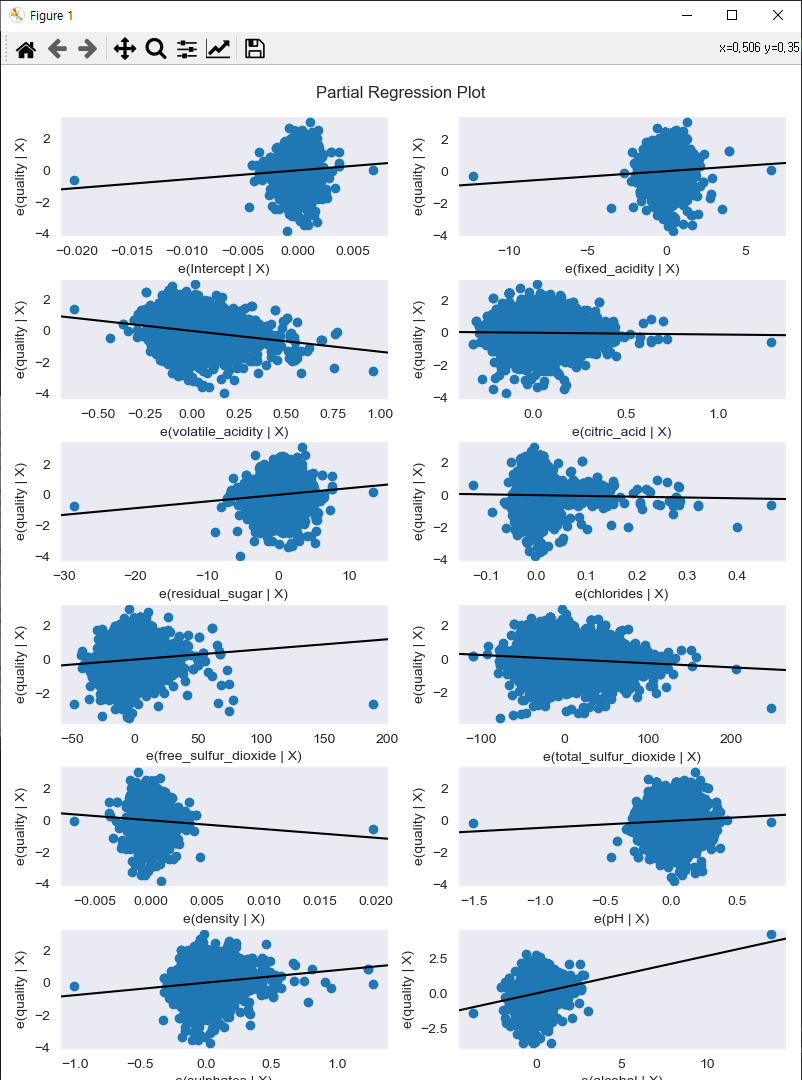
부분 회귀 플롯으로 시각화하기
# 부분 회귀 플롯으로 시각화하기
# 구축한 다중 선형 회귀 분석 모델처럼 독립 변수가 2개 이상인 경우에는 부분 회귀 플롯을 사용해 하나의 독립 변수가 종속 변수에 미치는 영향력을 시각화함으로써 결과를 분석 가능
# fixed_acidity가 종속 변수 quality에 미치는 영향을 분석하기 위해 부분 회귀 결과를 시각화 + 각 독립변수에 대한 부분 회귀 결과도 시각화
import statsmodels.api as sm
others = list(wine.columns.difference(["quality", "fixed_acidity"]))
p, resids = sm.graphics.plot_partregress("quality", "fixed_acidity", others, data=wine, ret_coords=True)
plt.show()
fig = plt.figure(figsize=(8, 13))
sm.graphics.plot_partregress_grid(regression_result, fig=fig)
plt.show()독립 변수 fixed_acidity와 종속 변수 quality에 대한 부분 회귀 시각화
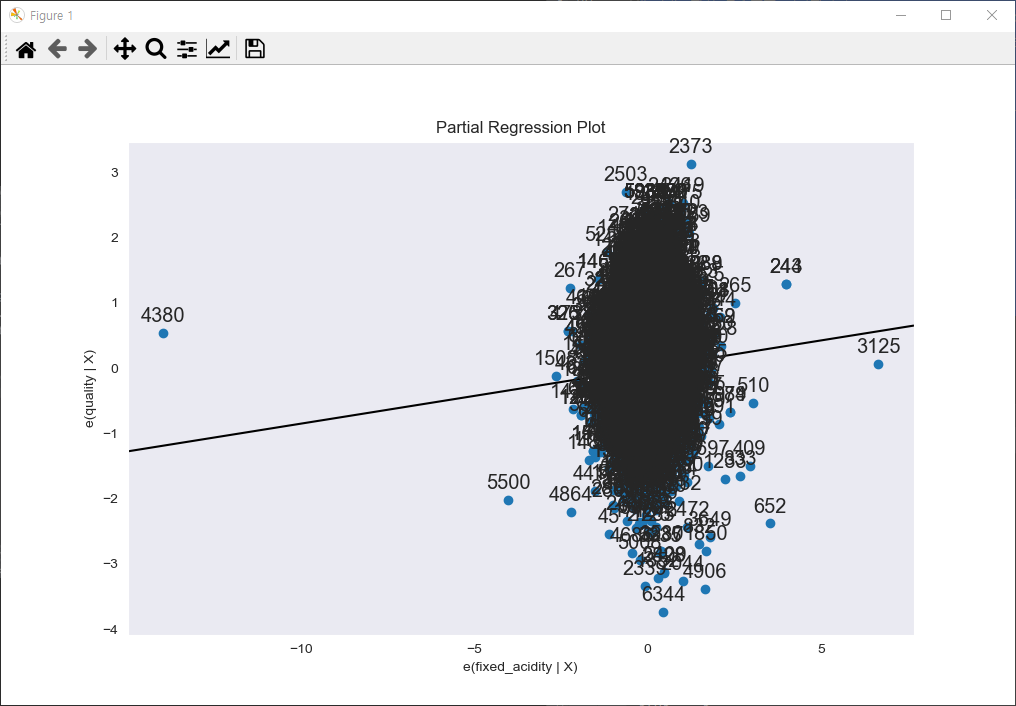
각 독립 변수가 종속 변수 quality에 미치는 영향력 시각화
상관분석 + 히트맵
상관분석
회귀분석: 목적, 임의의 데이터 대한 예측을 위함
상관분석: 두 데이터 간 상관 정도가 강하냐? 약하냐?
그래프에 있어 상관성 확인
회귀분석 => 원인과 결과를(인과관계) 분석해 추정을 하기 위함
상관분석 => 그냥 변수들 간 관계성(상관정도)을 확인하기 위함
타이타닉호 생존율 분석하기
타이타닉호의 생존자와 관련된 변수의 상관관계를 찾아보고 생존과 가장 상관도 높은 변수는 무엇인지 분석
상관 분석을 위해 피어슨 상관 계수 사용
변수 간의 상관관계는 시각화해 분석
상관 분석 은 변수들이 서로 독립적인지 아니면 서로 영향을 주고받는지를 알아내는 분석 방법
해당 데이터 셋은 파이썬의 seaborn 라이브러리 패키지에서 제공하는 데이터셋이다.
인과 관계를 분석하는 회귀 분석과 달리 상관 계수는 두 변수가 연관된 정도만 나타낼 뿐 인과 관계를 설명하지 않으므로 정확한 예측 계산 x
- 상관 계수
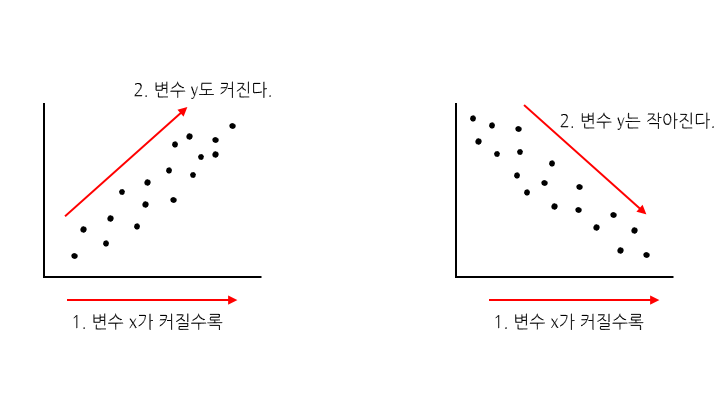
상관 계수는 변수 간 관계의 정도(0~1)와 방향(+, -)을 하나의 수치로 요약해주는 지수로 -1에서 +1 사이의 값을 가진다.
상관 계수가 +이면 양의 상관관계이며 한 변수가 증가하면 다른 변수도 증가
상관 계수가 -이면 음의 상관관계이며 한 변수가 증가할 때 다른 변수는 감소
0.4~0.6: 상관관계가 있다.
0.8~1.0: 매우 강한 상관관계가 있다.
-
피어슨 상관 계수
상관 계수 중에서 많이 사용하는 것은 피어슨 상관 계수이다. -
상관 분석 결과를 시각화할 때는 두 변수의 관계를 보여주는 산점도나 히트맵을 많이 사용
데이터 수집
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset("titanic")
titanic.to_csv('./titanic.csv', index = False)
print(titanic.isnull().sum()) # null 값 확인
# age, deck, embark_town 데이터에 null 존재
# age: 연속형 변수 => 평균 넣으면 될 듯?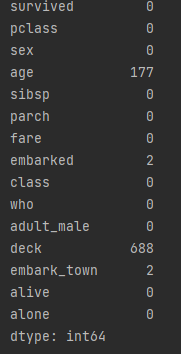
age와 embarked, deck, emback_town 항목 중에 결측값(누락된 값)이 있다.
결측값이 있으면 정확한 분석을 할 수 없어서 치환해서 채워줘야!
age의 결측값은 중앙값으로, embarked와 embark_town은 최빈값으로 치환한다. deck는 형식이 category이므로 최빈 category로 바꿔넣는다.
# median(): 중간값 찾아줘~
# print(titanic.info())
# 연속형, 범주형 데이터 확인(범주형 데이터 => 최빈값으로 대체)
titanic['age'] =titanic['age'].fillna(titanic['age'].median())
# mode(): 최빈값
return_value = titanic['embarked'].mode()[0]
# print(retrun_value, type(retrun_value)) # 판다스 데이터 종류 중 S(eries) 나옴
titanic['embarked']=titanic['embarked'].fillna(return_value)
# S, C, Q 중 S가 최빈값임
return_value = titanic['embark_town'].mode()[0] # mode(): 최빈값
# print(retrun_value, type(retrun_value)) # 판다스 데이터 종류 중 S(eries) 나옴
titanic['embark_town']=titanic['embark_town'].fillna(return_value)
return_value = titanic['deck'].mode()[0] # mode(): 최빈값
# print(retrun_value, type(retrun_value)) # 판다스 데이터 종류 중 S(eries) 나옴
titanic['deck']=titanic['deck'].fillna(return_value)
print(titanic.isnull().sum()) # null 값 확인
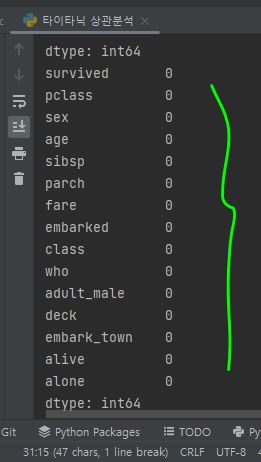
null 값이 없음을 확인! => 분석할 준비가 된 것
데이터 탐색
데이터의 기본 정보를 탐색해보자.
데이터의 기본 정보 탐색하기
titanic 데이터의 기본 정보를 탐색하기 위해 info() 함수 이용
# 데이터 탐색
print(titanic.info())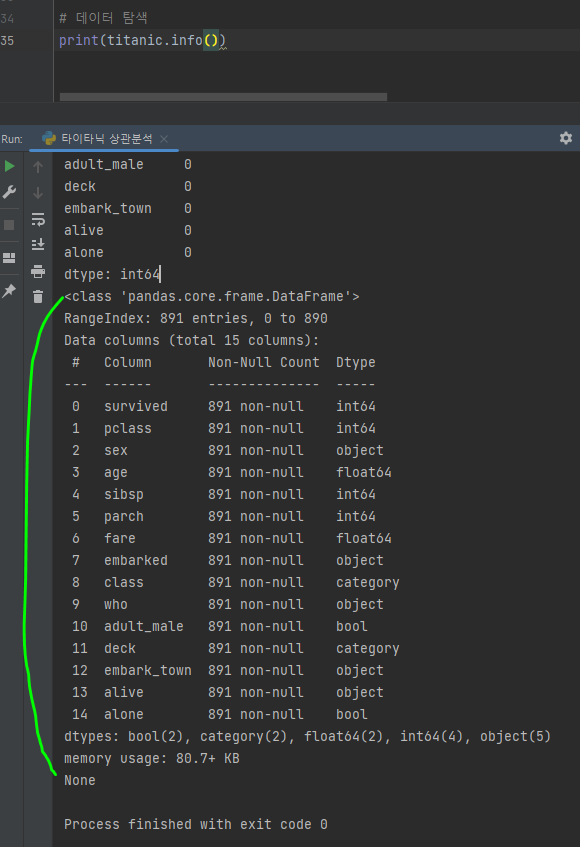
- 전체 샘플의 수는 891개
- 속성은 15개(컬럼 수)
survived 속성값의 빈도를 확인한다.
survived는 생존 여부를 1(생존), 0(사망)으로 나타냄
alive는 생존 여부를 yes(생존), no(사망)으로 나타냄
print(titanic.survived.value_counts())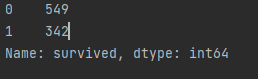
- 샘플 891명 중에서 생존자는 342명이고 사망자는 549명이다.
차트를 그려 데이터를 시각적으로 탐색하기
import matplotlib.pyplot as plt
f,ax = plt.subplots(1, 2, figsize = (10, 5))
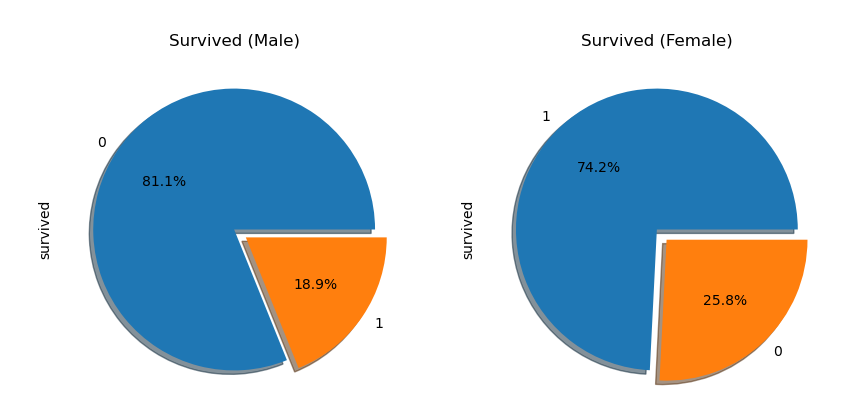
titanic['survived'][titanic['sex'] == 'male'].value_counts().plot.pie(explode = [0,0.1], autopct = '%1.1f%%', ax = ax[0], shadow = True)
titanic['survived'][titanic['sex'] == 'female'].value_counts().plot.pie(explode = [0,0.1], autopct = '%1.1f%%', ax = ax[1], shadow = True)
ax[0].set_title('Survived (Male)')
ax[1].set_title('Survived (Female)')
plt.show()