[논문리뷰] High-Resolution Image Synthesis with Latent Diffusion Models (LDM, 2022)
Diffusion Models
목록 보기
6/8
1. Introduction
-
Diffusion Models
- 기존 모델들(Autoregressive model, GANs)의 단점을 보완
- mode collapse, training instabilities 해결 - SOTA performance
- RGB image를 그대로 다루기 때문에 high-dimensional space에서 계산이 이루어진다
- training도 inference도 오래 걸림 + 자원 낭비
- 기존 모델들(Autoregressive model, GANs)의 단점을 보완
-
departure to latent space
-
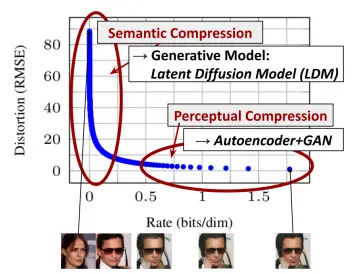
-
learning은 two-stage로 나눌 수 있음
1) perceptual compression : high-freq details를 제거하고 semantic variation은 거의 안 배우는 구간
2) semantic compression : semantic & conceptual composition of data를 배우는 구간, 우리가 보통 생각하는 'learning' -
basic idea: Let's find a perceptually equivalent,but computationally more suitable space
-
-
Latent Diffusion Models
- two distinct phases
1) data space와 perceptually equivalent한 low-dim representational space로 보내는 autoencoder 학습
2) learned latent space에서 Diffusion model 학습 - universal autoencoder 한 번만 학습하면 여러 DMs에 universal하게 적용 가능
- two distinct phases
3. Method
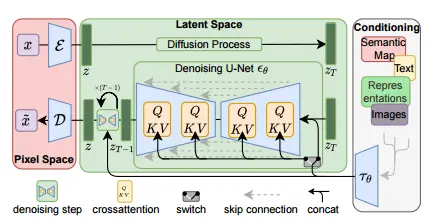
3.1. Perceptual Image Compression
- image 를 latent 로 보내는 encoder/decoder
- encoder가 이미지를 배만큼 downsample 시키는 과정으로 볼 수 있음
- latent space의 variance가 커지는 것을 막기 위해 두 가지 regularizations를 실험해봄
- KL-reg : learned latent와 standard normal을 비교한 KL-penalty를 약간 걸어주기
- VQ-reg : decoder 단에서 vector quantized layer를 사용하기
- autoencoder training
- 자세한 내용은 appendix C에
- discriminator 가 와 를 구분하도록 adversarial training
3.2. Latent Diffusion Models
- 기존 DDPM loss
- LDM은 말고 latent space에 있는 를 쓴다
- advantages
1) 모델이 important, semantic bits of data에 집중할 수 있다
2) lower dimension에서 계산하니까 더 효율적이다 - latent space에서 다뤄지는 기존 모델들과 달리 LDM에서는 이미지별 inductive bias(??)를 활용할 수 있다
3.3. Conditioning Mechanisms
- conditioning
- 다른 생성모델들처럼 data distribution 대신 condition 를 넣은 를 배우게 하면 된다
- 대신 사용
- 그런데 아직은 다양한 종류의 condition을 다루지는 못함
- cross-attention mechanism
- 어떤 modality의 가 들어와도 작동하도록 domain specific encoder 를 학습시키자
- 를 intermediate representation 로 project
- 는 cross-attention layer를 통해서 UNet 중간중간에 매핑할 수 있다
- 여기서 는 를 implement하는 UNet 중간 representation
- , , 는 모두 learnable projection matrices
- 어떤 modality의 가 들어와도 작동하도록 domain specific encoder 를 학습시키자
- Objective
- 와 는 동시에 optimized된다
- 설계 방식은 자유
4. Experiments
4.1. On Perceptual Compression Tradeoffs
- downsampling factor 로 비교 실험
- -1 = 기존 DM
- Results
- -{1,2}는 학습이 느렸고
- -{32}는 너무 압축해서 information loss가 일어난 탓에 quality가 크게 떨어졌다
- -{4,8}이 sweet spot
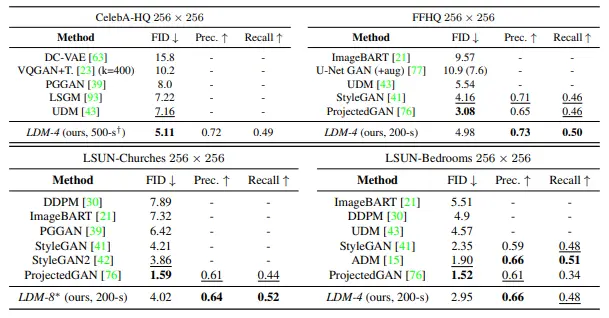
4.2. Image Generation with Latent Diffusion
- -{4,8}과 기존 generative models를 비교
- unconditional 256x256 generation
- Results
- 잘 나왔다
4.3. Conditional Latent Diffusion
-
cross-attention based conditioning의 활용
-
text-to-image
-
layout-to-image
-
class-conditional generation
-
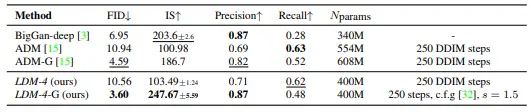
-
기존 SOTA인 ADM 이겼음
-
-
Classifier-Free Diffusion Guidance를 같이 쓰면 성능이 훨씬 좋아진다
-
-
sampling beyond
-

-
256x256으로 학습시키고 그보다 더 큰 resolution으로 샘플링이 가능함
-


4.4. Super-Resolution with Latent Diffusion
- low resolution image를 condition으로 넣어서 SR을 할 수 있다
- 실험 결과 기존 모델인 SR3랑 성능이 엇비슷했음

4.5. Inpainting with Latent Diffusion
5. Limitations
- 기존 DMs보다는 빨라지긴 했지만 여전히 GAN보다 훨씬 느리다
- 정확도가 중요한 task에서는 쓰일 수 있을지 여전히 의문이다
