0. Abstract
- present DDIM
- DDPM을 non-Markovian process로 generalize
- generative process가 deterministic해짐
- 더 빠른 샘플링 가능
- can produce high quality samples 10~50x faster
- computation time <-> sample quality tradeoff 있음
- DDPM을 non-Markovian process로 generalize
1. Introduction
-
DDPM requires many iterations
-
DDIM
-

-
DDPM과 같은 objective로 학습됨
- 학습은 DDPM으로 해놓고 샘플링할 때 둘 중에 선택할 수 있음
-
기존 diffusion process가 Markovian이었던 걸 non-Markovian으로 일반화
-
sampling step 수를 적게 가져갈 때 DDPM보다 나은 성능을 보임
-
“consistency” property를 가짐
- initial latent variable에 따라 어느정도 결과가 정해져 있음
- semantically meaningful image interpolation 가능
-
2. Background
- DDPM의 diffusion process
- parameter 학습은 VLB를 maximize (를 true data distribution 에 fit)하는 방향으로 진행
- forward process
- fixed inference procedure 이용
- 여기서 는 DDPM의 (의 cumulative product)와 같음
- Markov Chain을 Gaussian transition으로 구현했을 때 식은 아래와 같다
- our latent variable model
- to sampling을 수행하는 Markov chain
- reverse process (which is intractable)를 approximate
- -notation
- DDPM의 one-step diffusion 덕분에 를 와 noise의 linear combination으로 바꿔 쓸 수 있다
- 가 0에 충분히 가까우면 는 true noise에 가까워지므로 로 놓을 수 있다
- 을 이용해서 training objective를 정리하면 아래와 같음
- NCSN의 denoising score matching 기반 loss와도 같다
- DDPM의 one-step diffusion 덕분에 를 와 noise의 linear combination으로 바꿔 쓸 수 있다
- Timestep 문제
- length of the diffusion process는 DDPM의 성능에 있어서 매우 중요한 hyperparameter임
- 가 클수록 reverse process가 Gaussian에 가까워져서 DDPM의 approximation이 잘 맞는다
- sampling은 timestep 순서대로 해야 하므로 병렬화가 안 돼서 시간이 오래 걸린다
3. Variational Inference for non-Markovian Forward Processes
3.0. Key Observation
- DDPM objective 를 잘 보면 marginal 를 보고 학습하지 joint 는 상관하지 않는다
- 똑같은 marginal 라도 그걸 내놓는 과정 (inference distributions / joints)은 다르게 설계할 수 있다
- -> DDPM objective로 학습시켜놓고, inference할 때는 기존의 Markov process 대신 똑같은 marginal을 내놓는 non-Markovian process를 설계해서 쓸 수 있을 것이다
3.1. non-Markovian Forward Processes
-
diffusion kernel들이 에 dependent하도록 length real vector 에 대한 inference distribution을 새로 정의하자
-
DDPM의 objective를 그대로 갖다 쓰려면 marginal 를 보장해야 함
-
그러면 새로운 diffusion kernel은 아래와 같이 유도됨
-
귀납법으로 증명 (Appendix B lemma 1)
-
-
-
이제 Bayes rule을 이용하면 아래와 같이 forward process를 얻을 수 있고, 모든 는 와 에 dependent 하게 됨
- forward process는 더 이상 Markovian은 아니지만 여전히 Gaussian이다
- 는 forward process의 stochastic한 정도를 조절하는 변수로 쓰임
- 으로 가면 를 알고 있다는 가정 하에 모든 이 fixed된다

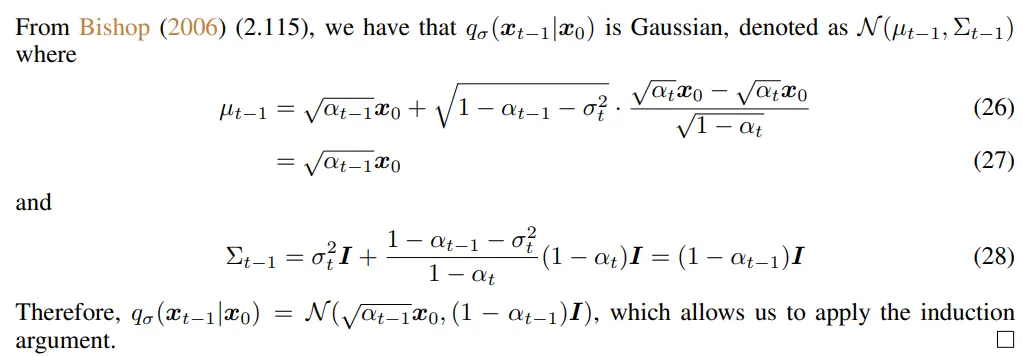
3.2. Generative Process and Unified Variational Inference Objective
-
generative process
- 를 따라하도록 학습된 로 generative process 를 만들었다 치자
- 샘플링을 하려면 각 단계에서 그 전 단계와 를 알아야 하는데, 학습할 때와 달리 inference 할 때는 를 모른다
- -> 를 이용해서 각 단계마다 를 예측해서 쓰자
- denoised observation (prediction of given )
- 예측을 학습시켜서 좀 더 정교하게 해볼 수도 있지만, 이렇게 단순하게 유도하는 거랑 별로 차이가 없었다
- 그러면 generative process with fixed prior 는 아래와 같이 쓸 수 있다
- 을 이용해서 샘플링하되 는 로 대체한 것
-
objective
-
새로운 objective는 와 를 매칭함
-
정의에 의하면 값에 따라 각기 다른 모델을 train시켜야 하지만, 특정 weight 조건을 만족하면 를 DDPM objective 와 같게 만들 수 있다
-
Theorem 1.
-
Proof (Appendix B)
-

-
31에서 32번 식으로 넘어가는 과정 이해 안 됨 (가 어디서 나온 건지?)
-
-
(DDPM loss) =
- 각 timestep에서 예측된 는 다른 timestep에서는 전혀 쓰이지 않음
- weight 에 따라 timestep 별로 학습되는 속도는 다를 수 있지만, optimal solution에는 영향이 없다
- 즉, 원래는 마다 를 만족하는 값이 다르지만 그걸 모두 로 퉁쳐도 어차피 optimal solution은 똑같이 얻어진다
- 따라서 에 관계 없이 DDPM loss를 그대로 사용해도 된다
-
4. Sampling from Generalized Generative Processes
4.1. Denoising Diffusion Implicit Models
- diffusion kernel 의 자리에 를 대입해서 식을 정리해보면 로부터 를 샘플링하는 점화식은 아래와 같음
- Extreme case 1 :
- forward process가 Markovian이 됨 (=DDPM)
- Extreme case 2 :
- forward process becomes deterministic given and , except for (으로 가는 마지막 단계)
- Theorem 1(DDIM loss = DDPM loss를 증명)에서는 인 경우만 생각하므로, 실제로는 으로 근사해야 함
4.2. Accelerated Generation Processes
- 요약: timestep 수를 줄여서 샘플링이 가능하다
- DDPM에서는 generative process reverse process로 두었으므로 forward process가 steps로 정의되었으면 generative process도 반드시 steps이어야 했다
- 그러나 objective는 만을 참고하지 forward process가 어떻게 생겨먹었는지와는 관련이 없으므로, generative process reverse process라는 정의만 없으면 timestep 몇 개 빼먹어도 무방하다
- sampling trajectory
- timestep 중에 개만 뽑아서 간소화된 forward process 를 정의하자
- 이걸 뒤집어서 ddim sampling을 해도 이론 상으로 문제가 없다
- sampling trajectory length가 보다 월등히 작으면 샘플링 효율을 크게 높일 수 있음
4.3. Relevance to Neural ODEs
- 요약: 에서 로 inversion이 가능하다
- DDIM iterate를 ODE 꼴로 바꿔 쓸 수 있다
- derivation
- 를 이용하면
- 식을 이쁘게 reparameterization: ,
- initial condition 으로 설정해서 식을 다시 정리하면
- 를 이용하면
- 이제 유도된 ODE를 Euler method를 이용해서 풀 수 있다
- timestep 수가 충분히 많다는 가정 하에 ODE를 풀어서 로부터 를 구하는 것이 가능
- latent encoding이 가능하다 -> 다양한 downstream applications에 쓰일 수 있다
- derivation
- relevance to "probability flow ODE"
- DDIM에서 유도된 ODE는 score-SDE에서 정의된 probability flow ODE의 special case라고 볼 수 있다
- 증명은 Appendix B (proposition 1)에
- ODE는 같지만 sampling procedure는 좀 다르다
- 와 가 충분히 비슷할 때(timestep 수가 많을 때)는 두 procedures가 같지만 fewer timestep으로 샘플링할 때는
- ODE for VE-SDE(probability flow ODE)는 에 대한 Euler step을 취하는 반면
- ODE for DDIM은 에 대한 Euler step을 취함 (less dependent to )
- DDIM에서 유도된 ODE는 score-SDE에서 정의된 probability flow ODE의 special case라고 볼 수 있다
5. Experiments
-
Settings
- same trained model (=1000)으로 DDPM, DDIM sampling을 모두 수행함
- (timestep sub-sequences)와 (stochasticity)에 따른 결과를 관찰함
- 는 일 때 extreme case(DDPM)이므로 새 변수 를 도입해서 parameterization을 좀 더 쉽게 함
- 일 때 DDIM, 일 때 DDPM
-
- random noise의 std가 1보다 큰 경우
- 로 치면 인 경우 (DDPM)
-
5.1. Sample Quality and Efficiency
-
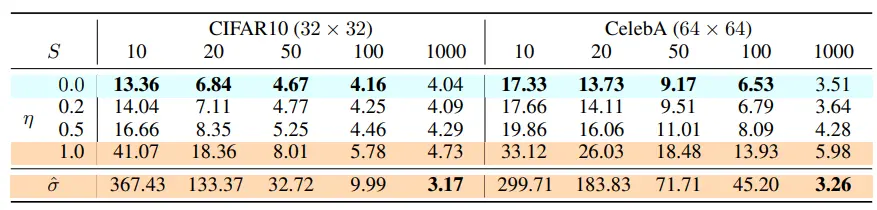
-
CIFAR10, CelebA에서 실험, FID로 평가
-
timestep 수에 따른 sample quality <-> computational cost tradeoff가 있었다
-
같은 timestep일 때 DDIM이 성능이 더 좋았다
-
다만 full timestep을 이용한 경우 가 가장 좋았음
- 케이스는 non-Markovian sampling의 정의에서 벗어나기 때문에 timestep을 줄이는 조건이 ill-suited하다
-
DDIM으로 10x ~ 50x speedup이 가능하다
-
-
5.2. Sample Consistency in DDIMs
-

-
DDIM의 경우 generative process가 deterministic하므로, 는 initial state 에 따라 결정된다
-
-> 가 fixed 되어 있으면 timestep을 달리 해도 퀄리티만 살짝 다른 같은 결과물이 나온다
-
alone would be an informative latent encoding of the image
-
-
5.3. Interpolation in Deterministic Generative Processes
-

-
5.2.에 이어서, 서로 다른 두 를 섞으면 결과물 끼리 적당히 interpolation된 결과물이 나온다 (semantically meaningful interpolation)
-
DDIM은 latent variable 단에서 high level contents를 직접 조절할 수 있다 (DDPM에서는 안 됨)
-
-
5.4. Reconstruction from Latent Space
-

-
DDIM은 particular ODE의 Euler integration이므로, 로부터 를 인코딩한 뒤 다시 로 를 복원할 수 있다
-
CIFAR10으로 reconstruction 실험해봤더니 잘 됐다, timestep 수가 많을 수록 error가 적었음
-
DDPM에서는 stochastic nature 때문에 이게 안 된다
-
