0. Abstract
1. Introduction
-
기존 generative models
- GANs, autoregressive, flow-based, VAE -
-
-
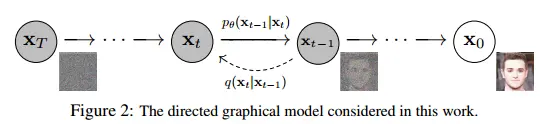
= a parameterized Markov chain
-
아직까지는 high quality samples에 적용하기는 어렵다
-
-
Contributions
- Diffusion models가 high quality samples도 만들 수 있다는 것을 보임
- certain parameterization에서 denoising score matching과 같다는 것을 보임
2. Background
- DPM의 내용인데 notation이 조금 다르다
- latent variable models of the form
- where are latents of the same dimensionality as the data
- reverse process
- joint distribution := reverse process
- 에서 시작하는 Markov chain (with learned Gaussian)으로 정의된다
- forward process
- 다른 latent variable models와 달리 approximate posterior 이 fixed되어 있다
- := forward process (or diffusion process)
- Markov chain that gradually adds Gaussian noise to the data according to a fixed variance schedule
-
Loss
- 모델의 negative log likelihood를 minimize하는 방향으로 학습
- 이 때 variational bound를 이용
- Comparison with DPM notations
- negative log likelihood
- DDPM :
- DPM :
- variational bound
- DDPM :
- DPM :
- negative log likelihood
-
one-step forward diffusion
- sampling at an arbitrary timestep can be done in closed form
- Use notation and , then
- Proof
-
Rewrite Loss using KLD
- DPM의 Appendix B와 같은 내용
- divided into three parts
- DPM의 Appendix B와 같은 내용
-
directly compare forward & backward process
- backward process 와 forward posterior(GT) 를 비교
- 는 계산하기 어렵지만 condition이 추가로 주어지면 쉽게 계산할 수 있다
-
Proof
-
이제 Loss 내의 모든 KLD comparisons는 Gaussian으로만 이루어지게 됨
-
can be calculated in a Rao-Blackwellized fashion with closed form expressions, instead of high variance Monte Carlo estimates


3. Diffusion models and denoising autoencoders
3.1. Forward process and
- 를 learnable하게 설정할 수도 있지만 DDPM에서는 fixed schedule로 고정하였음
- 그러면 posterior 에 learnable parameter가 없으므로 는 constant
3.2. Reverse process and
-
-
에서 를 어떻게 디자인할까?
-
- 로, sigma는 timestep에 따른 fixed constant로 설정하였음 (X train)
- 는 로 놓아도 되지만 (의 sigma) 실험적으로는 그냥 로 놓는 거랑 별 차이 없었음
- 따라서 로 설정
-
- 을 를 이용해서 다시 쓰면,
- 여기서 는 forward process posterior mean이고, 우리의 모델이 이걸 예측하도록 하게 만들면 된다
- 을 를 이용해서 다시 쓰면,
-
introducing
-
- using one-step diffusion
- 이걸로 식을 reparameterizing하면 좀 더 단순화시킬 수 있다
- 계산 과정에 넣어보면 증명됨
- 이제 는 를 예측해야 함.
- 여기서 는 의 noise를 예측하는 모델
- 를 으로 바꿔서 을 한번 더 단순화시키면,
-
-
이제 은 denoising score matching과 같은 꼴이 된다
- 는 Langevin-like reverse process의 variational bound와 같아짐
3.3. Data scaling, reverse process decoder, and
- 이미지는 {0,1, ..., 255}에서 [-1, 1]로 scaled 되어서 네트워크에 들어간다
- 마지막 reverse process의 결과는 다시 {0,1, ..., 255} 이미지로 변환되어야 하니까 마지막 는 예외적으로 아래와 같이 정의한다
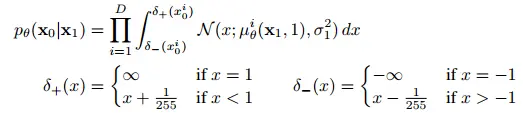
3.4. Simplified training objective
- DDPM의 최종 Loss term
- is uniform between 1 and
- 일 때는 3.3.절의 term을 예외적으로 따른다 (ignore and edge effects)
- 일 때는 3.2.절의 term에서 weight를 뺀 것
- weight를 왜 뺐나?
- weight 는 가 작아짐에 따라 커진다
- 따라서 에 가까운 매우 작은 noise를 제거하는 단계에 학습이 집중됨
- 모든 timestep이 동일한 loss 비중을 가지게 하려면 이 weight를 빼는 게 낫다
- NCSN에서도 timestep에 따른 loss 비중 맞춰주려고 weight를 조작했음

