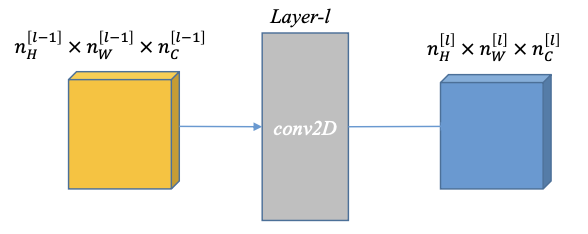
CNNs
컴퓨터 비전 문제
- 이미지 분류, 객체 탐지, Neural style transfer
큰 이미지의 딥러닝
- 입력 이미지의 해상도가 이라면, 하이퍼파라미터의 개수는 다음과 같다.
- 개의 hidden unit 존재한다고 가정
- 의 차원 : (12288, m)
- 첫번째 레이어에서 의 차원 : (1000, 12288)
- Fully Connected 이므로 개수는 1000 x 12228 = 12M
- 만약 입력 이미지의 해상도가 이라면, 하이퍼 파라미터가의 개수는 다음과 같다.
- 1000 개의 hidden unit 존재한다고 가정
- 의 차원 : (3M, m)
- 첫번째 레이어에서 W 의 차원 : (1000, 3M) 1000 x 3M = 3B
- weight 가 너무 많다는 문제점이 있다.
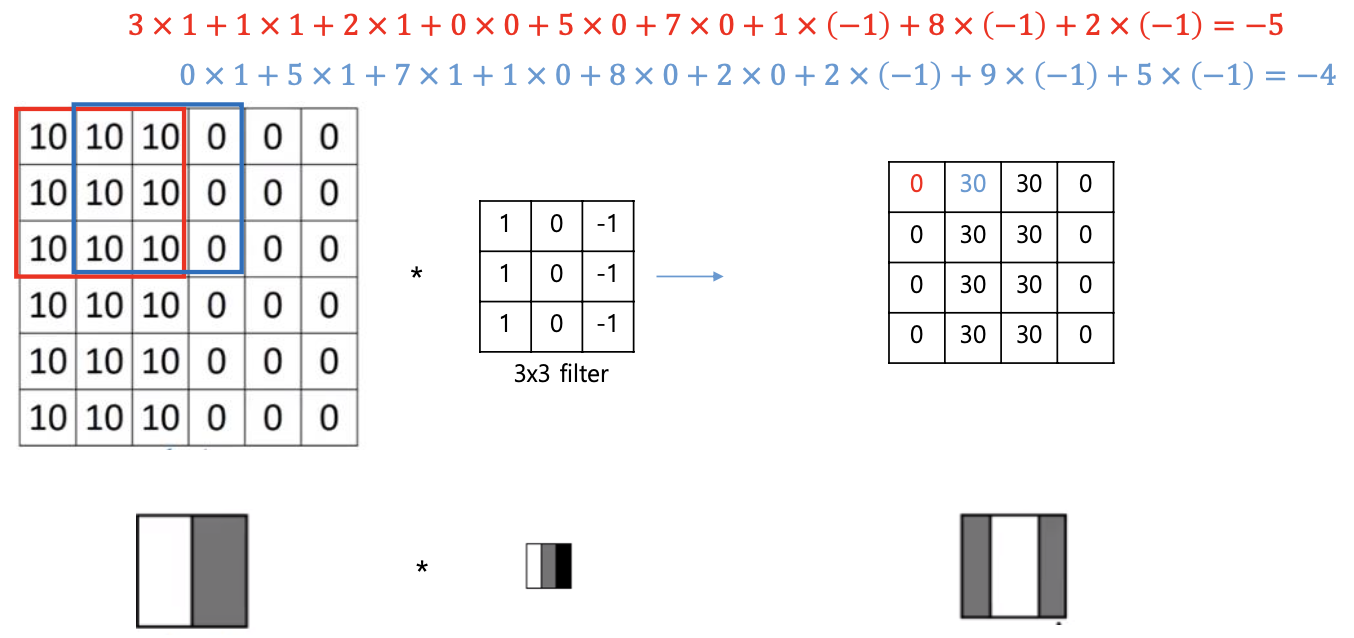
엣지 검출
- 이미지 내의 객체의 경계를 찾는 이미지 처리 기술
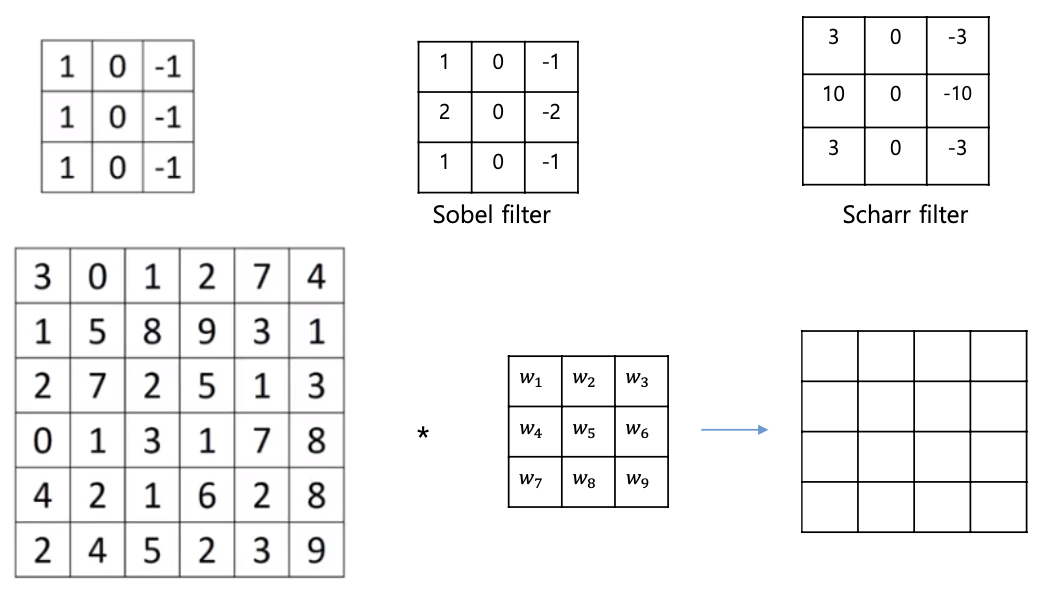
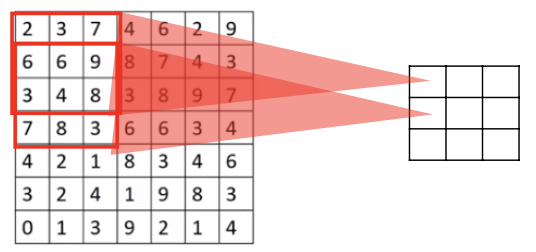
컨볼루션 연산에 의한 엣지 검출
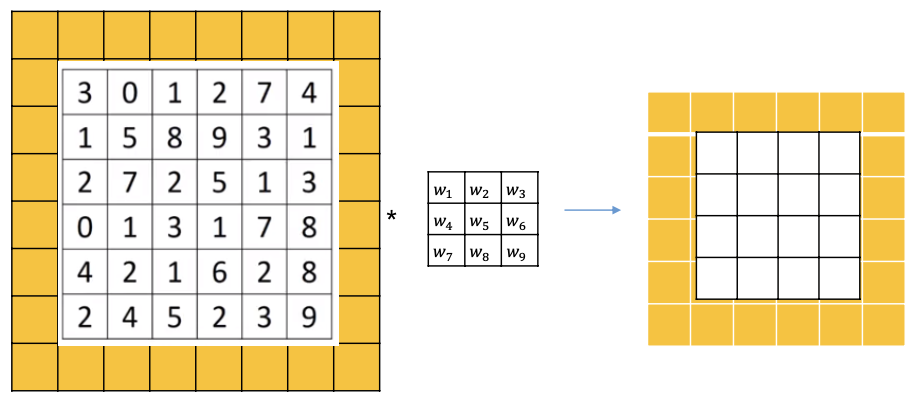
Padding
- 입력과 출력 사이즈가 달랐다는 문제를 보완하기 위해서 이미지 경계 바깥쪽에 추가적인 픽셀을 붙여주는 Padding 적용
- 이를 통해 결과값의 차원을 입력값의 차원과 같게 해줄 수 있다
- Input image size 𝑛×𝑛: 6×6
- Filter size 𝑓×𝑓: 3×3
- Padding size 𝑝: 𝑝 = 1
- Output image size : 암기 권장
- 입력사이즈와 출력사이즈를 같게 만들기 :
Stride
- 컨볼루션 필터를 이용하여 다음 칸으로 이동할 떄 몇칸을 이동할지 걸음걸이 결정
- Input image size 𝑛×𝑛: 7×7
- Filter size 𝑓×𝑓: 3×3
- Padding size 𝑝: 𝑝 = 0
- Stride : 𝑠 = 2 #위 아래 2칸을 이동하여 다음 컨볼루션 진행
- Output image size : -> 나보다 작은 정수 중에 큰것
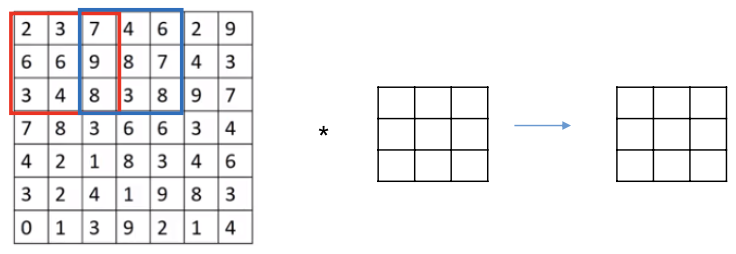
RGB 이미지에서 컨볼루션
- (이미지) * (필터) (연산결과 채널 차원 1 이 된다)
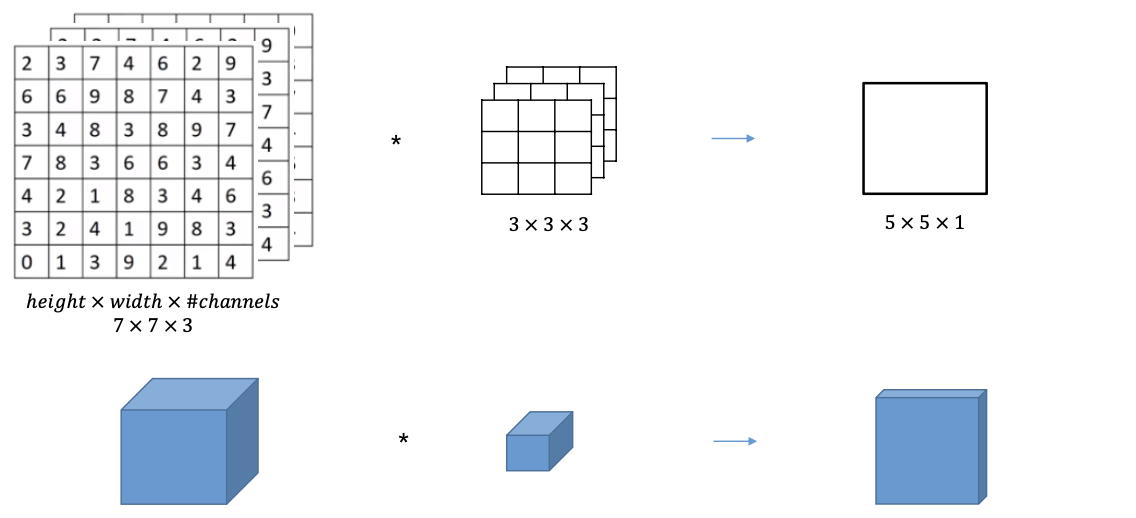
다중 필터
- 두개의 필터를 사용
- 결과 : 이 두개가 나오는 것이다 따라서
- 뒤의 2는 필터의 개수를 가리킨다
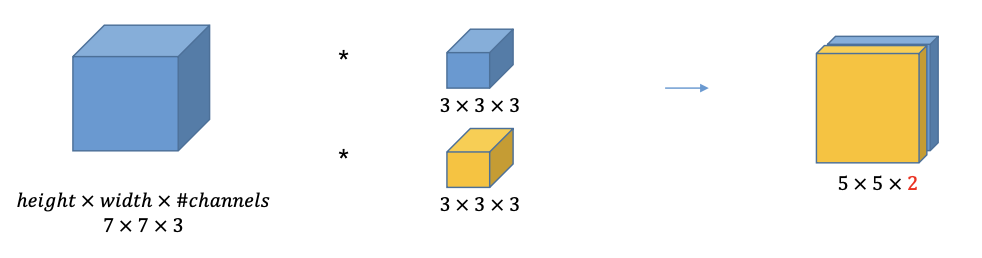
단일 컨볼루션 레이어
-
필터 두개를 사용하고, 컨볼루션 연산이 끝나면 그 연산 결과가 필터당 하나씩 나온다.
- // linear transformation Conv
- // not linear ReLU
-
NN 의 하나의 layer 에 각각 3 x 3 x 3 인 필터가 10개가 있다면
- 우선 CNN 에서는 weight 즉, 필터의 element 들이 학습 파라미터이다.
- 각 필터당 (3x3x3 = 27 개의 weight + 1 bias) 28 개의 parameters
- 따라서, 필터가 10개 이므로 총 280 개의 학습해야할 parameters 존재.
- input size 가 커지면 즉 이미지 크기가 1000x1000x3 이다 하고 우리는 필터를 2개 사용한다고 했을떄, learnable parameters 개수가 늘어날까?
- 필터의 learnable parameter 의 개수는 늘어나지 않는다. 즉 입력 차원과 상관이 없다.
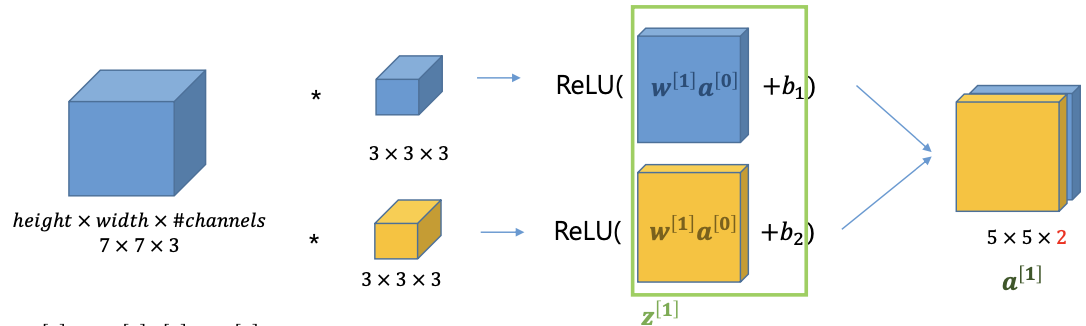
- 필터의 learnable parameter 의 개수는 늘어나지 않는다. 즉 입력 차원과 상관이 없다.
-
Notaions
- 컨볼루션 필터
- 필터 사이즈 :
- 패딩 :
- Stride :
- 출력의 채널 개수 : 컨볼루션 필터의 개수와 동일
- 입력 이미지 (가로 : Horizontal, 세로 : width, 채널 : Channel)
: - 필터 사이즈 :
- Activation
- Weights :
- Bias :
- 출력 (가로 세로 채널) :
Example
컨볼루션 레이어를 사용하는 방법은 칸볼루션 필터를 반복해서 사용하는 것이다.
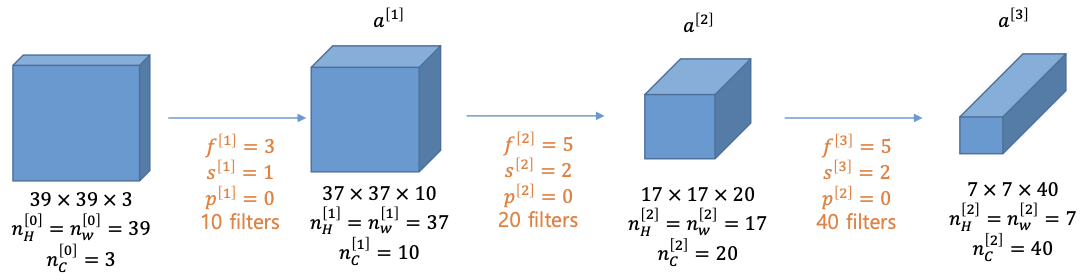
- 39x39x3 의 입력 이미지, 3x3 필터, stride 는 1, 패딩은 0, 필터의 개수는 10개라면
- 계산 결과
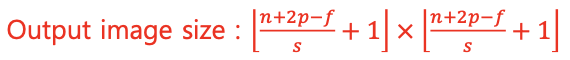
- 1) 출력 : 이라는 feature 벡터 생성
- 2) 출력 : 이라는 feature 벡터 생성
- 3) 출력 : 이라는 feature 벡터 생성
- 다음과 같이 element 개수가 계산이 된다.
Why convolutions
- 데이터 특성 때문에 컨볼루션 연산이 잘 이루어진다.
- 컨볼루션 레이어의 두가지 특성
- parameters sharing
- 컨볼루션 필터와 이동하여 적용한 컨볼루션 필터가 서로 같다 (같은 필터를 쓴다) -> learnable parmeters 의 크기가 줄었다.
- Sparse connection
- 내가 어떤 지점의 아웃풋 값을 계산할 때 전체를 보는것이 아니라 칸볼루션 필터가 딱 놓여져있는 필터만 본다.

- parameters 의 수는 다음과 같이 3072 x 4704 = 14M
- 그런데 컨볼루션 필터를사용한다고 하면, 입력 사이즈 무시!
- 파라미터 수는 76 x 6 = 456 로 계산됨.
- 내가 어떤 지점의 아웃풋 값을 계산할 때 전체를 보는것이 아니라 칸볼루션 필터가 딱 놓여져있는 필터만 본다.
- parameters sharing
Pooling layer : Max pooling
- 컨볼루션 레이어와 함게 Pooling 도 함께 사용
- 입력이 4x4 가 들어왔을때 출력이 2x2 가 들어옴을 계산할 수 있다.
- 제일 큰 값 하나를 고르는게 Max pooling vs Avg pooling
- 1 3 2 9 에 컨볼루션 연산을 해서 그것들중에 가장 큰 9 가 선택됨.

CNN - Examples
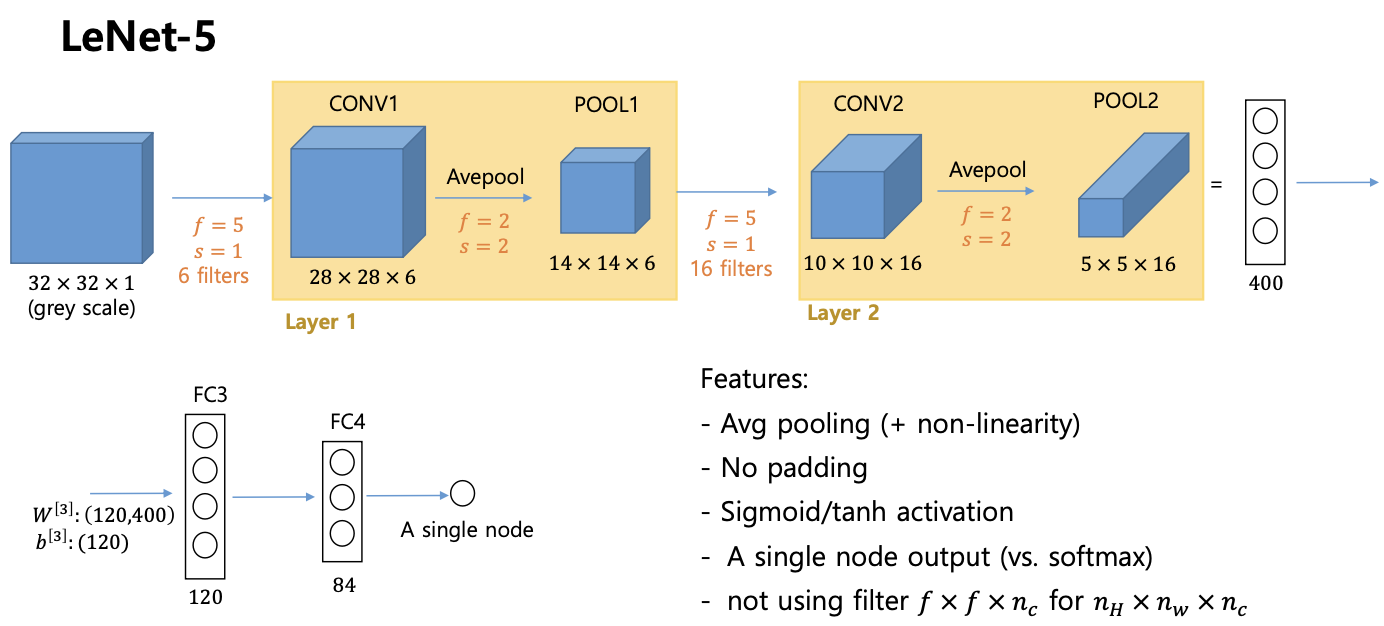
LeNet-5
- 최초의 CNN
- 입력이 들어오고 레이어가 컨볼루션 레이어 하나 pool 레이어 하나 컨볼루션 레이어 하나 pool 레이어 하나 이런식
- 그 다음에 fully connected layer, fully connected layer, 그다음에 softmax 이렇게 쌓아서 만든다.
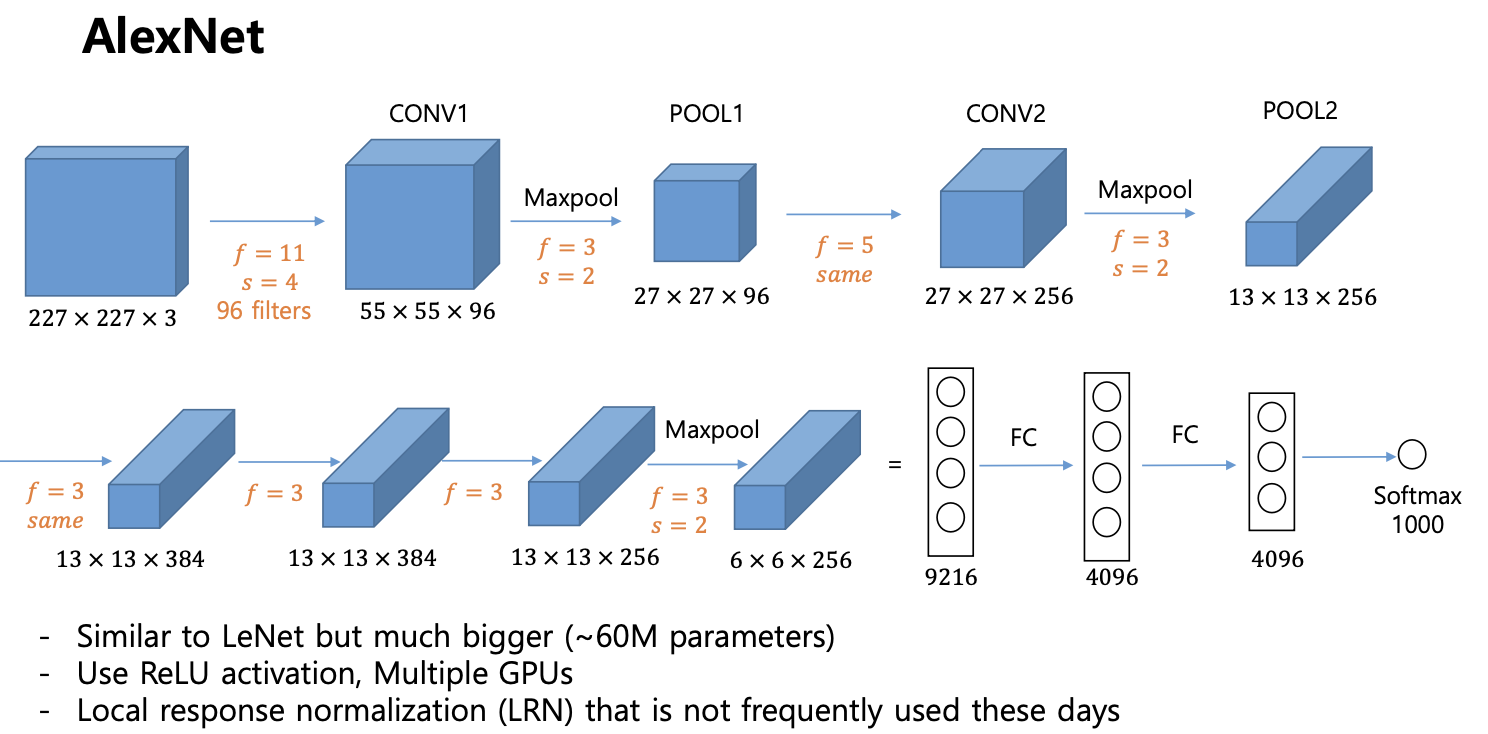
AlexNet
- LeNet 과 비슷하지만 더 크다
- ReLU 활성함수, Mulitple GPU 사용
- 모양 :
- 컨볼루션 레이어가 첫번쨰 -> 맥스 풀링 한번 -> 컨볼루션 레이어 -> 맥스 풀링 -> 컨볼루션 x 3 -> 맥스 풀링 -> flatten 진행(1차원 텐서로 쭉 늘려서 fully conected layer -> fully conected layer -> soft max 1000개
- soft max 가 1000개 라는 이야기는 여기서 구분해야 할 종류가 1000개라는 의미 (개 고양이 라고 하는 클래스가 1000개)
- 앞서 봤던 LeNet 보다 컨볼루션, fully conected layer 가 늘어났다 -> 파라미터 숫자도 늘어났다
- 컨볼루션 레이어에 ReLU 를 썼다.
- 드디어 GPU 를 사용했다.
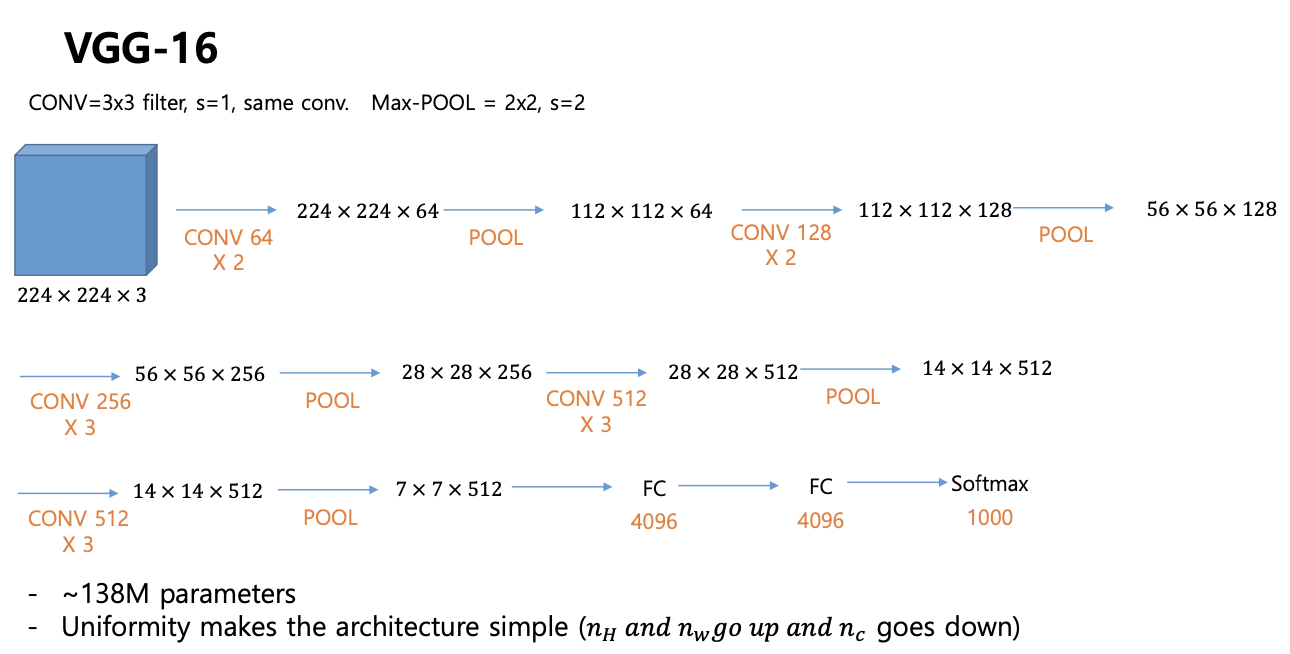
VGG-16
- CNN 이 발전하면서 많이 사용하는 네트워크
- 16 이라는 의미는 : CNN 레이어의 개수
- 모양:
- 컨볼루션 레이어, 맥스 풀링 계속 반복 -> 맨 마지막에 7x7x512 라는 feature 가 나오면 flattening 해서 FC -> FC -> Softmax
- 특성:
- 필터 사이즈를 변화시키지 않는다. 컨볼루션 레이어에서 3x3 필터를 처음부터 끝까지 사용
- 파라미터의 개수가 같은것을 쓴다. -> feature 모양도 우리가 에상했던 대로 얇고 넓은 것에서 좁고 긴 것으로 변하게 되었다.
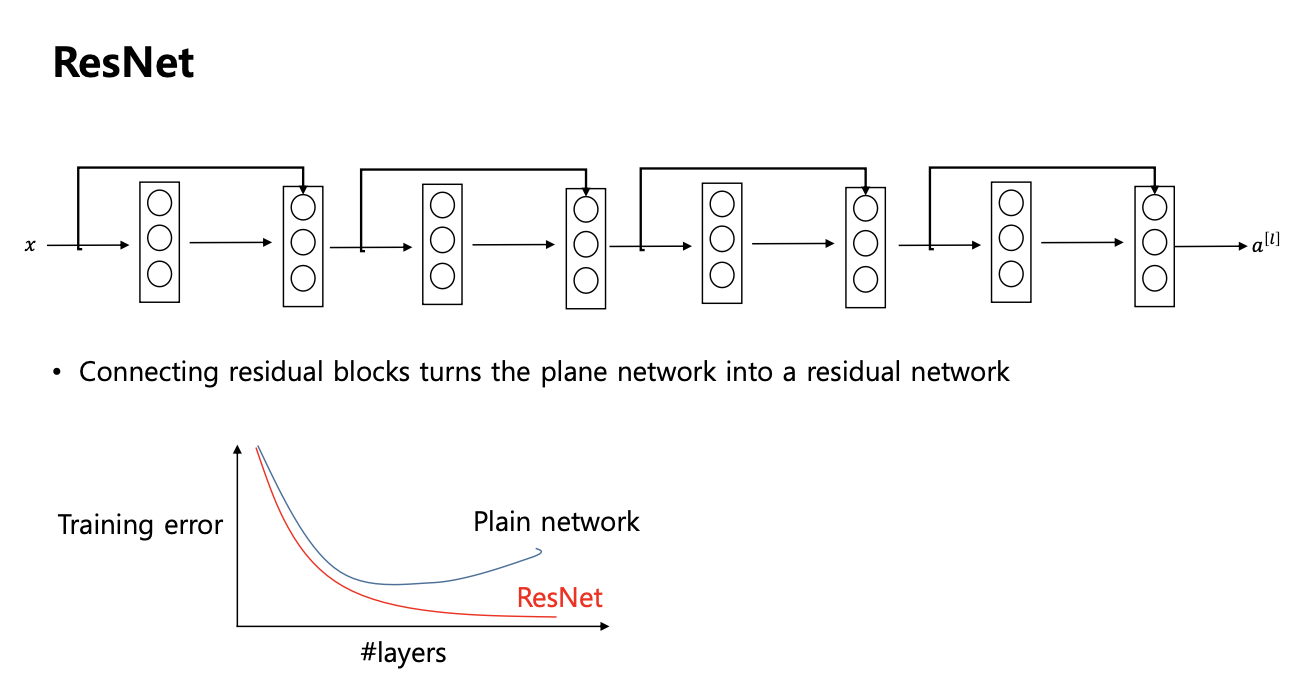
ResNets (Resideual network)
- VGG 랑 마찬가지로 파이토치에서 제공하는 표준화된 네트워크이다.
- 모양:
- 리니어 트랜스포메이션 ReLU 있다
- 비선형결합의 입력이 -> (자기의 선형결합 + 전 단의 아웃풋)
- Skip Connection : 입력이 리니어 레이어로 들어가면서 중간에 가시가 하나 나와서 통과하지 않고 다음 뉴런으로 들어가버리는 레이어를 스킵하는 구조
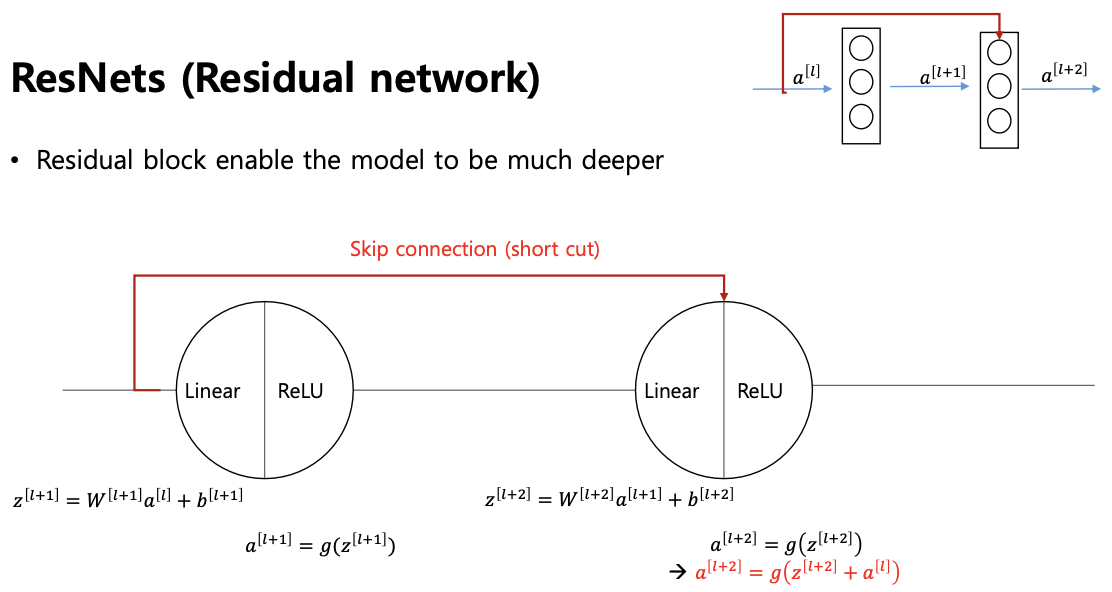
- Skip Connection을 한 이유?
- 입력을 넣었을때 가운데 아무것도 하지 않고 입력이 그대로 나오는 아이덴티티 기능을 만들기 위해 즉, 입력을 넣었는데 출력이랑 같도록 학습해서 만들고 싶다.
- 근데 skip connection 이 없는 경우는 그게 힘들다, 따라서 skip connection 이 있으면 그게 쉽다.
- 스킵하는게 하나씩 거쳐서 가는것보다 쉬워진다. -> 레이어를 많이 쌓을 수 있도록 도와준다.
- ResNet 을 사용해서 Skip connection 을 해주면 로스 펑션의 험준한 산이 매끄럽게 변하게 된다. -> 훨씬 더 학습이 잘 된다.

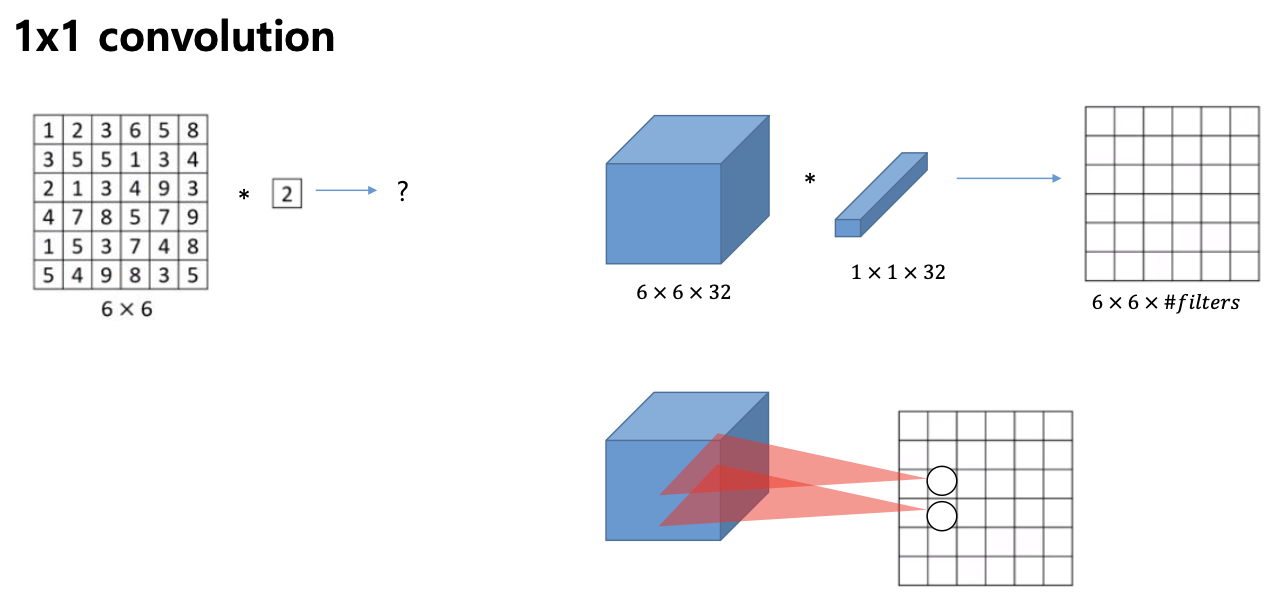
1 x 1 컨볼루션
-
이 컨볼루션을 쓰는 경우도 있다
-
1 x 1 컨볼루션을 쓰면 일단 컨볼루션의 채널 수는 입력과 수가 같다고 했는데, 채널 축으로 내적을 구하는 것이 된다.
-
이게 왜 필요하지 생각하지 말고 저런 효과가 있다.
-
채널 접근으로 컨볼루션을 한다.
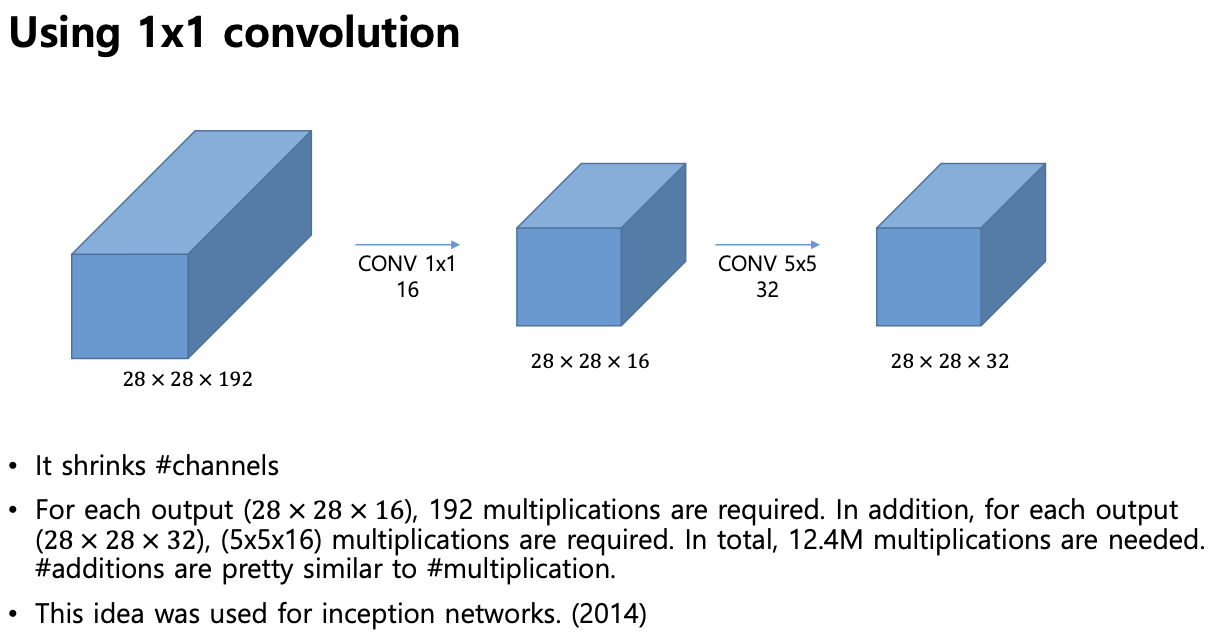
-
Regularization 에서 모델을 보면 아웃풋 레이어에 시그모이드를 출력을 한 것이 있었다.
-
그 이전에 파이토치 튜토리얼 했을때 클래스로 짜여진 모델을 하나 보여준적이 있다 -> foward 마지막 아웃풋은 시그모이드가 아니라 리니어 아웃풋을 그대로 냈었음
-
시그모이드가 붙을때가 있고 안붙을때가 있는데
-
파이토치는 그 두가지를 모두 제공한다.
-
우리 모델의 마지막 출력이 시그모이드 출력값이다 하면, 그 출력값을 가지고 크로스 엔트로피를 구해서 로스를 구하는데 그때 이 함수를 쓴다
- 즉 softmax 를 할떄는 torch.nn.functional.binary_cross_entropy 를 쓴다
-
우리 모델의 출력이 시그모이드의 출력이 아닌 출력을 받아서 크로스 엔트로피의 입력으로 줄수있는 방법
-
즉, softmax 를 내가 하지 않고 리니어 출력(logit)만 하고 그 logit 의 softmax 를 loss 함수에 맡길때 다음 사용
- torch.nn.functional.binary_cross_entropy_with_logits 을 쓴다

공부한 것 기록용