hyperparameter
- : 가장 중요한 파라미터, 알파는 0에 붙어있을 확률이 높다.
- 모멘텀,
- Adam optimizer, -
- #layers : (priority 3)
- #hidden units : (priority 2)
- Learning rate decay : (priority 3)
- Mini-batch size : (priority 2)
적절한 척도를 사용하여 하이퍼 파라미터 선택

지수 가중 평균에 대한 하이퍼 파라미터

배치 정규화
- logistic regression 모델을 훈련시킬떄, input feature 인 는 정규화 하면 학습 속도가 증가
- 입력만 왜 정규화를 해야돼? 각 layer 마다 하면 안되는건가? 라는 접근
- 즉, 배치 정규화란 레이어마다 정규화를 하는 방법중에 하나.
- 따라서,
- 을 더 빠르게 학습시키기 위해 를 정규화할 수 있을까?
- 대신 를 정규화 한다.

구현
- 어떻게 정규화를 할것인가?
- 미니 배치 안에서 정규화를 하자 라고 미니 배치를 정하고 레이어를 정규화하고 싶다면?
- 활성화값의 결과값 의 평균값을 구하느게 아니라 선형 결과 의 평균값을 사용해야한다.
- 평균, 분산을 구함 분모가 0 이 안되게 만드는 입실론 정규화
- 정규화를 한 을 또 다시 감마 를 이용하여 옮긴다
- learnable parameter 인 감마, 베타의 효과
: 우리가 만들고자 하는 를 설정할 수 있도록 한다

-
두번째 layer 에 들어가기 전에 배치 norm 이 들어감, 계속 진행.
-
레이어 마다 베타, 감마가 개별적으로 존재
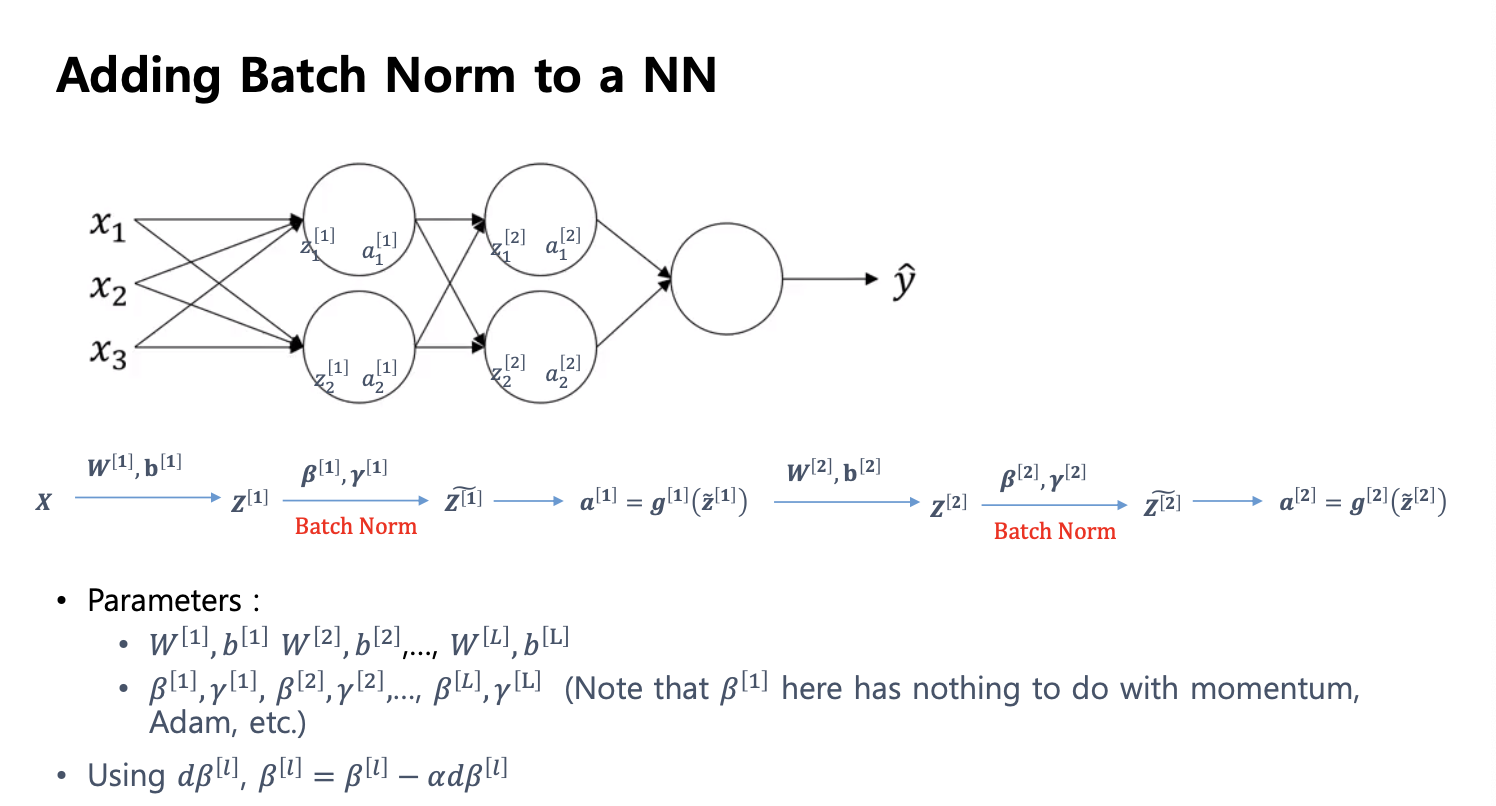
-
bias term 2개가 되버려서 사실상 하나가 필요가 없어짐
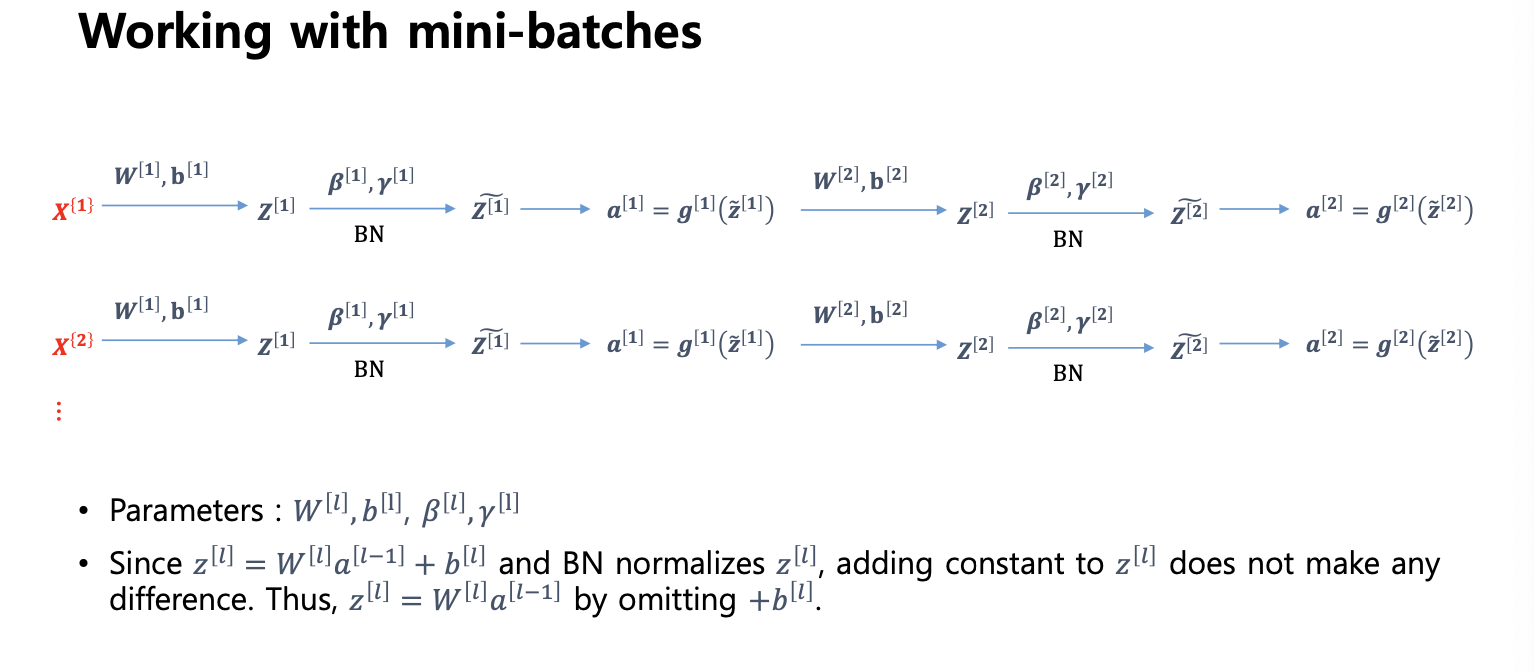
- 전방향 할떄 정구화된 z 를 사용
- 역전파 할때 업데이트 해야할 파라미터가 바뀜, w 베타, 감마 (bias가 없음)

왜 배치 정규화가 잘 동작하는가?
-
NN 의 큰 가정중 하나 -> Network 을 트레이닝 시켰고 테스트에 돌아갔더니 잘 돌아감 -> 이것은 우리 모델은 즉, 내가 본 데이터는, 내가 안본 데이터의 성격이 같다라는 가정이 있다, 다르면 동작하지 않는다
-
NN 은 트레이닝 데이터가 테스트 데이터가 거의 비슷하다라는 가정이 있다.
-
테스트 데이터가 다르기 떄문에 성능이 떨어짐 -> data shift
- 그 중에 하나가 covariate Shift

- 그 중에 하나가 covariate Shift
covariate Shift
- covariate shift : 학습데이터와 테스트 데이터의 분포가 다른 경우를 의미.
- 10개의 클래스가 있는 이미지 -> 동물 구분
- 모델 학습을 통해서 결국 -> 우리 모델은 x 를 주면 y 사 잘 나온다
- 그런데 데이터를 살펴보니까 x 와 y 의 입력 확룰 자체가 다름
- 트레이닝 데이터는 100개의 데이터가 균일 (개 10개, 고양이 10ro ...)
- 우리 분포와 테스트 데이터는 분포 자체가 달라서 균형이 무너짐.
- 제대로 분류를 못함

- 관계 분포는 잘 정의가 되어있으나 입력 분포 자체가 다르다
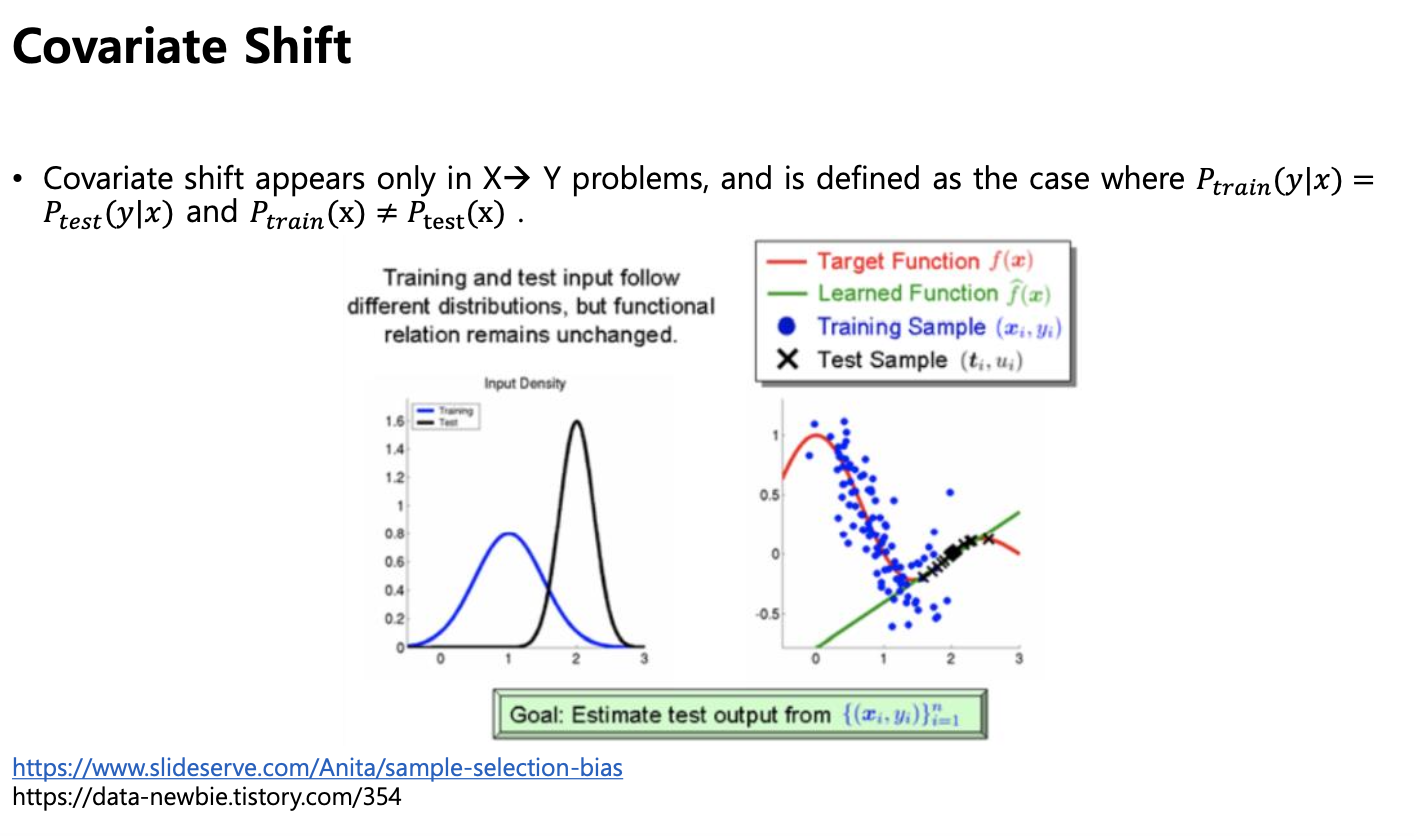
- loss를 떨어뜨리는 방향쪽으로 순전파, 역전파 하는데
나한테 넘어오는 앞단의 신호가 변하지 않을것이라는 가정이 있는것이다.
그러고 나서 그 가정으로 loss 를 계산했고,
그런데 내 앞에 있느것들도 다 업데이트가 됨.
-> 이것은 covaritae shift 가 아니냐라는 주장을 저자가 함.
-> 이 방법이 굉장히 혀괴적
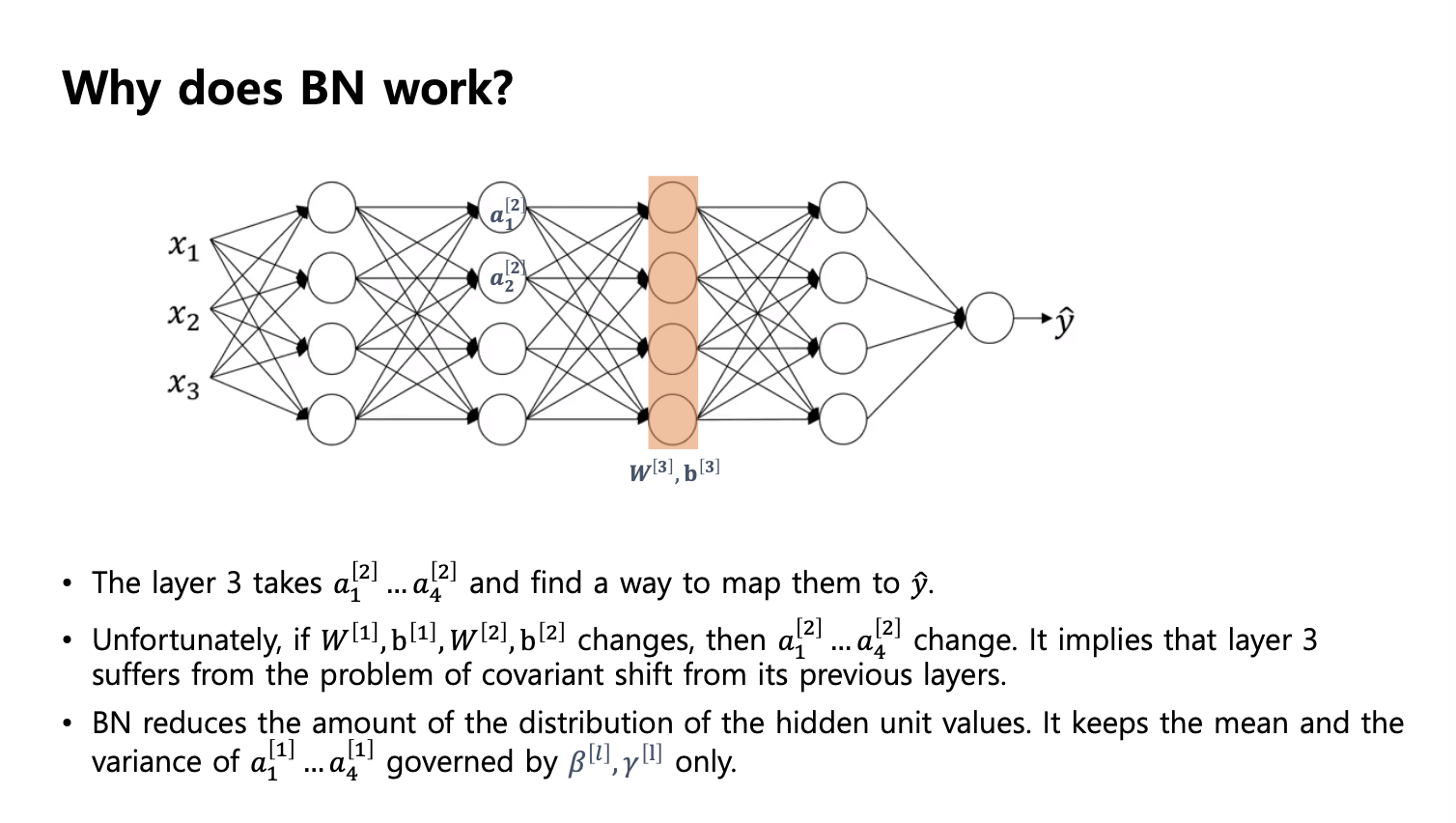

- 트레이닝 할때 구해놓은 미니 배치의 평균값을 테스트 할떄 사용한다.

- 배치 정규화가 왜 동작하는지에 대해서 작성한 글
- covariate shift 가 아니라는 아니다 라는 말
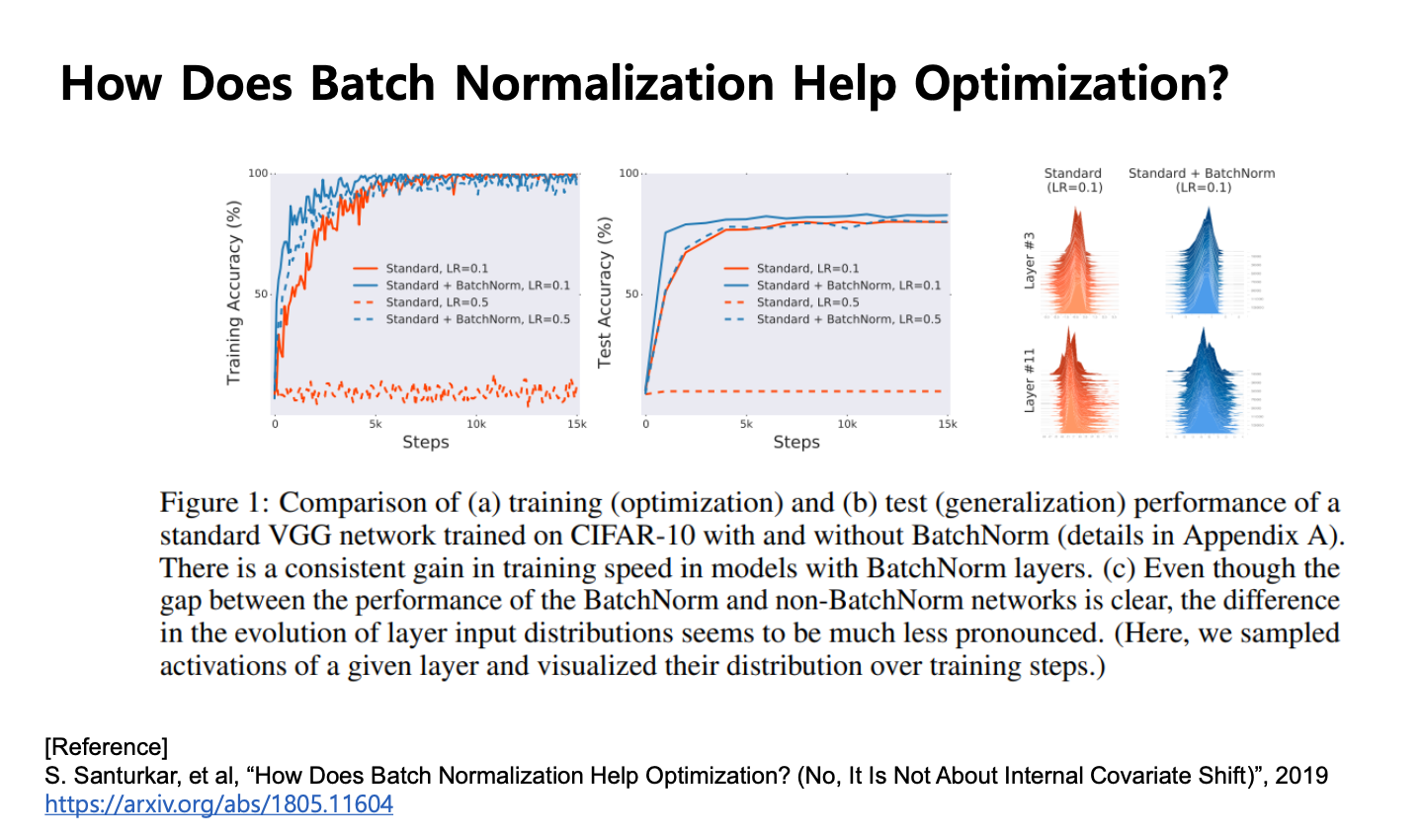
- 배치 정구화를 썼을 떄 파란색, 안쓴경우 빨간색
- 파란색이 빨간색보다 위에 존재
- 즉 파란색이 정확도 성능이 더 좋다
- 성능 좋은것은 맞으나 맨 오른쪽 그래프를 보면 매 레이어의 이전 레이어의 분포에 대한 그래프
- 배치 정구화를 하면 분포가 좀 더 좋아지더라 근데 변화는 그닥 없더라 라는 비판
- 저 분포가 굉장히 많이 달라져야하는거 아닌가 라는 주장
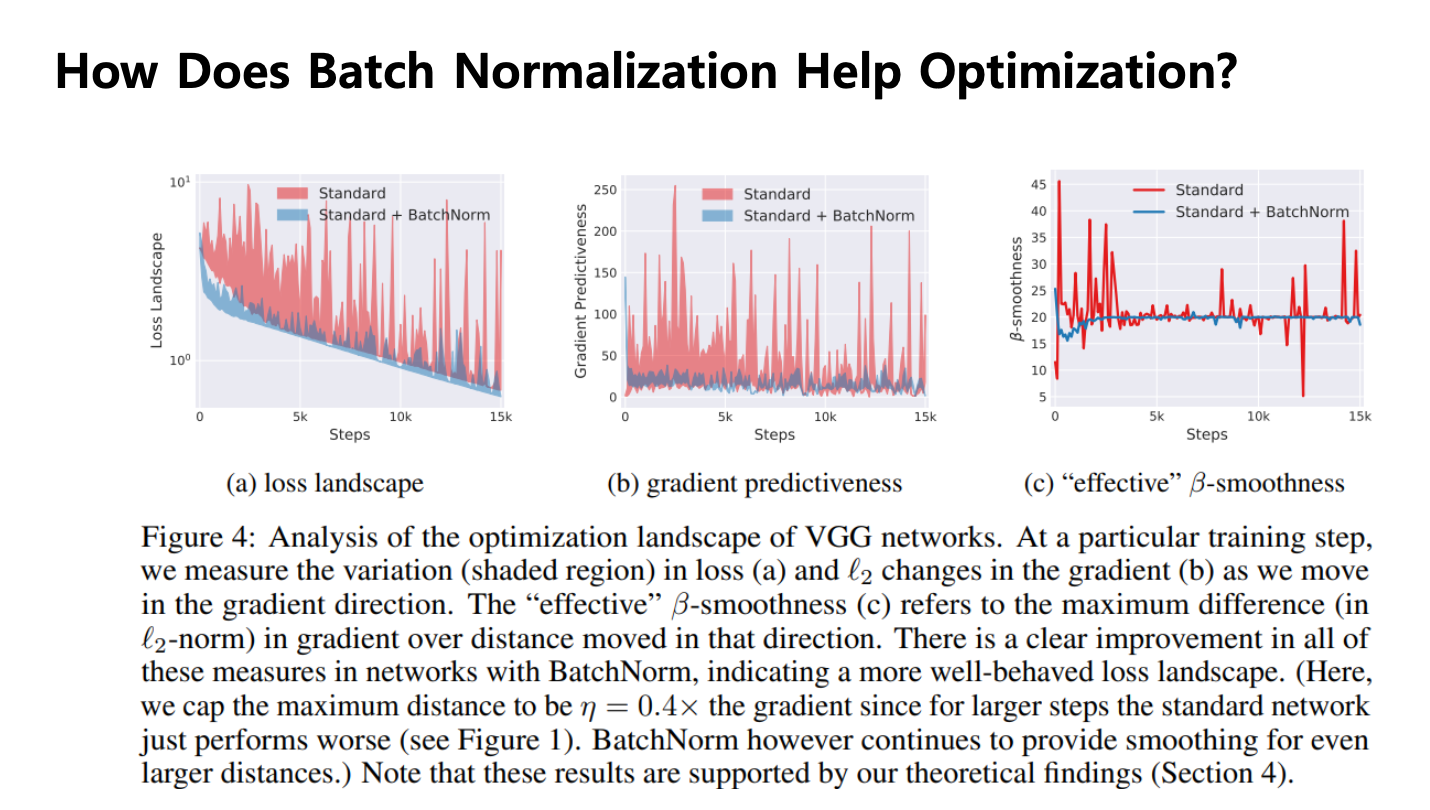
- 학습을 시키면서 learning rate 와 함께 grad_prediction(어떤 특정 지점에 loss 를 떨어뜨렸을때 있을때, 그때 w 의 모든 방향을 다 봐아서 가장 높은 방향을 찍어주는 그래프)
- 시각화 할 순 없지만 가장 큰 grad 는 매순간 존재하기 떄문에 찍어준것
- 배치 정규화를 쓰지 않았을때가 빨간색 -> 난리
- loss 함수의 모양이 매끄럽지 않은 모습
- 그런데 배치 정구화를 쓰면 파란색으로 바뀜 -> 훨씬 더 grad 가 나아짐
- 배치 정규화를 쓰면 covariate shift 가 없어지는게 아니라, loss 함수가 좀 더 부드러워진다 -> 경사하강법의 수렴을 더 잘 하게 된다고 주장.
- 배치 정규화를 쓰면 covariate shift 가 없어지는게 아니라, loss 함수가 좀 더 부드러워진다 -> 경사하강법의 수렴을 더 잘 하게 된다고 주장.
softmax 회귀를 사용한 멀티 클래스 분류
- Softmax regression (소프트맥스 회귀)는 다중 클래스 분류 문제를 다루기 위한 알고리즘 중 하나이다.
- 로지스틱 회귀는 이진 분류 문제를 해결하기 위해 사용되는 알고리즘
- 소프트맥스 회귀는 이를 다중 클래스 분류로 확장한 것
- 소프트맥스 회귀는 입력 변수의 선형 결합에 소프트맥스 함수를 적용하여 각 클래스에 대한 확률을 계산한다.
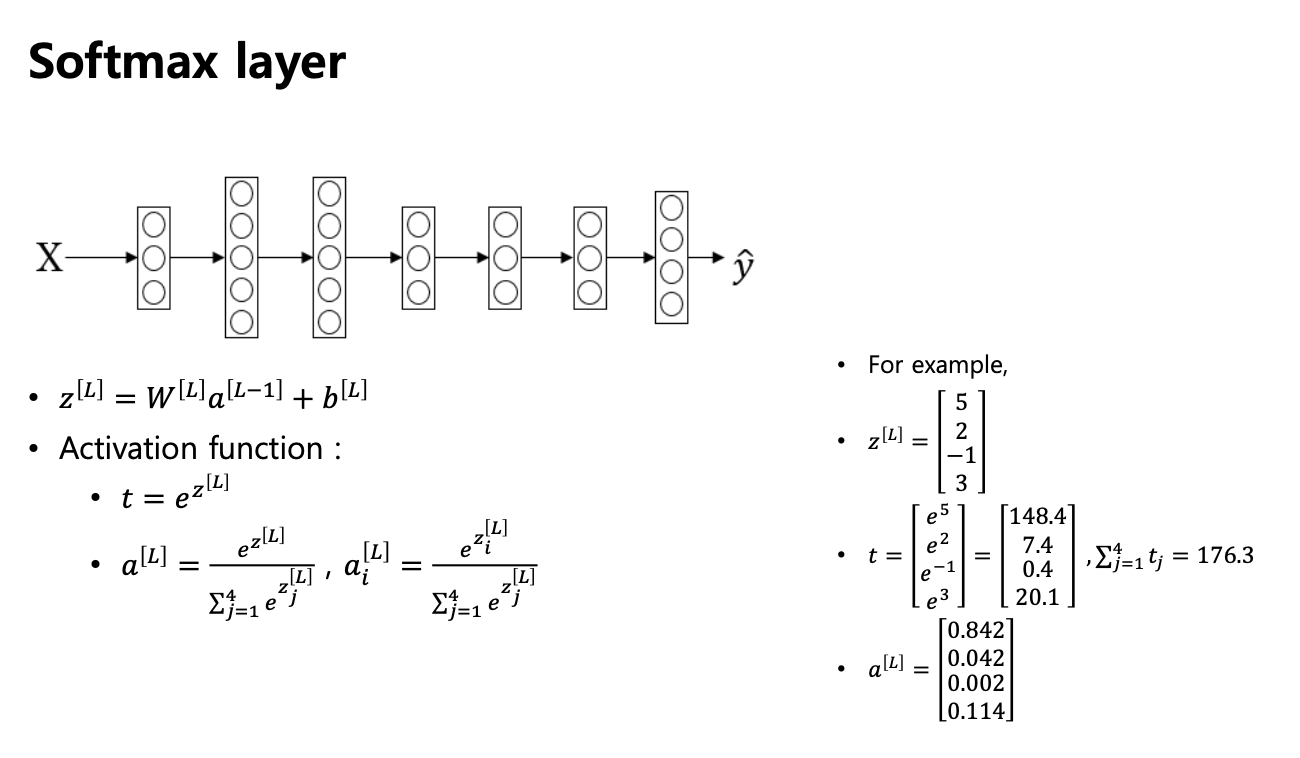
- 주어진 변수 x 에 대해 Softmax 회귀 단계
- 입력 변수 x에 대한 가중치 벡터 w와 b를 정의
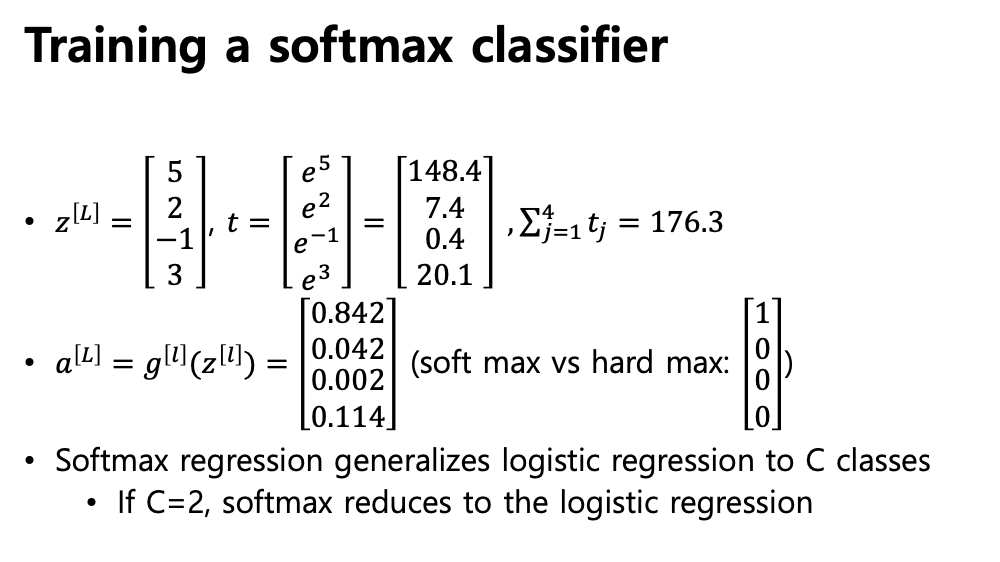
- linear transformation : z=w^T*x+b
- z 에 exponential 을 취한 것 t
- z 가 큰것과 작은것이 있으면 t 도 큰것과 작은것의 순서는 그대로 단 부호만 + 로 만들어주고 t의 모든 값들을 다 더하여 그것을 분모로 나누어주기
- 클래스가 4개니까 4개에 대해서 z의 exp를 취한 t를 구하고, 각 행을 t 값들의 합으로 나누어주기
- t1 t2 t3 t4 를 다 더하면 1 - > 확률값
- 4개를 다 더한값(148.4+7.4+ ...)을 각각을 다 나눠준것이 (0.842, ...)
- 첫번쨰는 클래스가 1일 확률 : 0.842 ...
- 클래스 1 일 확률이 가장 높으니까 결과적으로 클래스 1이다 라고 분류 하는것

-
soft 가 붙은 이유는 -> 미분 가능하다는 뜻
-
소프트맥스를 사용하게 되면 x1 x2 가 입력으러 들어왔을떄, 입력의 디멘젼 2 -> 분류를 하는데 클래스가 3개일때 첫번째 그림
-
클래스가 6개일때 밑의 그림

-
정답지는 max 1 0 0 0 -> 뭐 예를 들어서 코알라는 0 1 0 0 이야 등등의 정답지가 존재
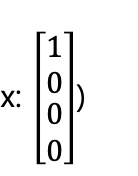
-
소프트맥스 아웃풋은 이런시그올 실수로 나옴
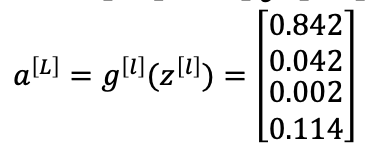
-
이진 분류에서서는 크로스 엔트로피를 사용했지만, 소프트맥스에서는 다음 식을 사용
- Negative log entropy
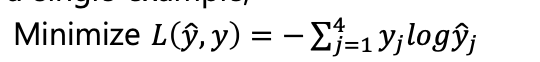

- Negative log entropy
-
이렇게 정의했을떄, 맨 마지막 단에 z 로 아까 봤던 크로스엔트로피를 미분하면 다음과 같은 식이 나온다.
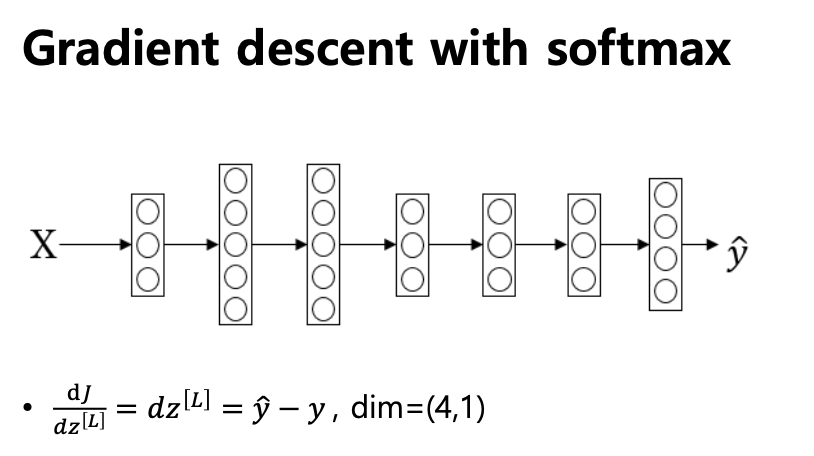
마지막 트랜스포메이션 을 loigt 이라고 한다.
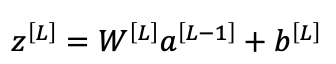
Be careful with torch.nn.CrossEntropyLoss
실습

공부한 것 기록용