미니 배치 경사 하강법
- 배치 경사 하강법
m 개의 훈련 세트를 효과적으로 계산하기 위해 Vetorization
- 전체 의 행렬 를 라고 했을 때, 전체 를 입력으로 넣고 이라는 출력값(forwardprop)을 얻어서 와 을 가지고 라는 ( ) 를 구하고 이것들을 가지고 backpropagation 을 통해 NN 업데이트를 n 번 반복시키는 것이 원래의 우리의 프로세스
- ex) , 큰 단위로 경사하강을 진행하기 까지 오랜 시간이 걸림
- 미니 배치 경사 하강법
- 따라서 라는 단위로 나누어 훈련 후 경사 하강을 진행한다.
- 사이즈가 1000 인 미니배치 5000 개로 나누어 훈련 및 경사 하강법을 진행하면 된다.
번째 Mini-batch
번쨰 training set :
- 전체 알고리즘도 살짝 변한다
- 미니배치 t = 1 번부터 5000번 까지 반복 이 과정이 다 끝나면 epoch 1개 그런 다음 다음 mini batch 5000번 하고 epoch 2개 이런식으로

- 미니배치 t = 1 번부터 5000번 까지 반복 이 과정이 다 끝나면 epoch 1개 그런 다음 다음 mini batch 5000번 하고 epoch 2개 이런식으로
미니 배치 경사 하강법 이해하기
-
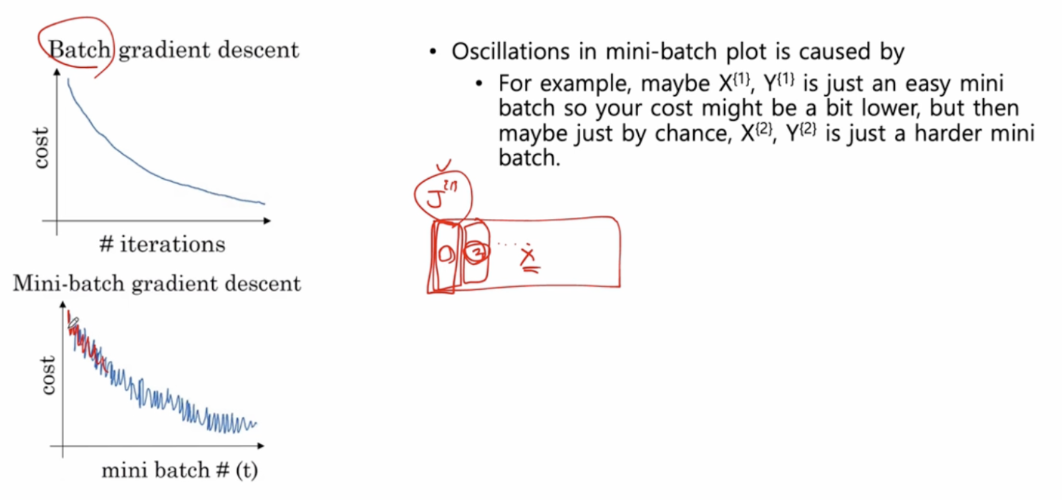
미니 배치 경사 하강법에서는 전체적으로 봤을떄는 비용 함수가 감소하는 경향을 보이지만 많은 노이즈가 발생한다.
-
mini batch 하나가 전체 X 를 대변하진 못하기 떄문에 예를 들어서 mini batch 하나를 가지고 계산한 1번이
J 를 minimize 하기 위해서 w 의 값을 떨어뜨렸는데 다음 mini batch 2번을 봤더니 1번에서 했던 업데이트 방향이 2번에서는 결코 좋은 방향은 아닐 수 있기 떄문에 다소 지저분한 그래프 모양이 나올 수 있는 것이다.
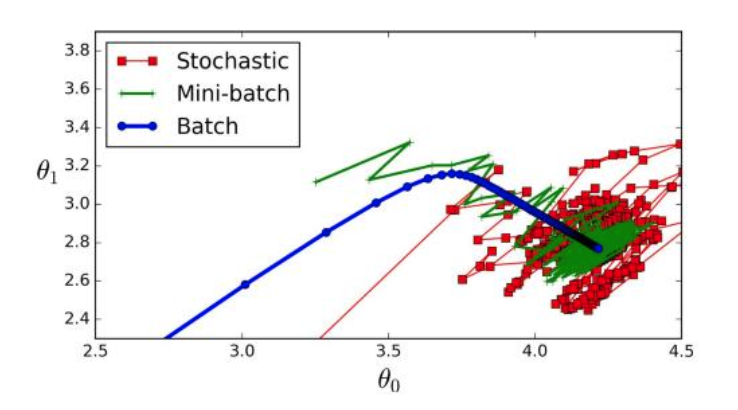
그렇다면 미니 배치 사이즈를 어떻게 결정할 것인가?
미니 배치 사이즈를 어떻게 선택하는지에 따라 학습 속도의 차이가 나기에 최적의 값을 찾아내는 것이 중요하다.
- 그림의 를 로 생각
- 만약 미니 배치 사이즈 = m 이면, Batch GD,
- 만약 미니 배치 사이즈 = 1 이면, Stochastic GD,
- 1과 m 사이에서
- 배치 경사하강법은 반복 당 너무 오래 걸립니다
- Stochastic GD는 벡터화로 인해 속도가 느려집니다
- 미니 배치 GD가 가장 빠름
Exploration vs Exploitation
-
Exploitation (사용)
- 내가 현재 위치 주변에 조금만 가면 적당한 다음 step(global optima) 이 있을거야 라고 생각하는것.
-
Exploration (탐색)
- 좀더 좋은 optima 가 내 주변 말고 저 산 너머에 있을거같은데? 라는 접근
-
우리의 Loss function 은 더이상 convex 가 아닌 험난한 산. 험난한 산에서 끝까지 내려가 global optima 를 발견해야 한다. 단순 GD 만으로는 이것이 불가능하기 때문에 학자들이 GD 를 개선하여는 연구 (Optimazation algo) 를 많이 해왔다. 따라서 이 두가지를 동시에 갖고 균형을 맞춰 사용하여 GD (Gradient Descent) 를 개선할 수 있다.
-
미니 배치 사이즈 결정
- 미니 배치 사이즈는 2의 제곱일때 훈련 속도가 가장 빠름
- 만약 훈련 세트가 작다면 (m < 2000) 모든 훈련 세트를 한 번에 학습 시키는 배치 경사 하강(batch GD)을 진행 한다.
- 훈련 세트가 2000 개보다 클 경우 전형적으로 선택하는 미니배치(mini batch) 사이즈는 64, 128, 256, 512 와 같은 2의 제곱수이다.
- 미니 배치 사이즈 가 CPU 혹은 GPU 메모리에 맞는지 확인해야한다.
최적화 알고리즘
-
일반적인 최적화 문제
- ex) 라는 목적함수를 가지고
이 목적함수를 최소화하는 w를 찾는데 그 w 는
constraint(제약조건) : 라는 방정식을 만족하는 중에서 고른다
- ex) 라는 목적함수를 가지고
-
-
contraint 가 없는 이 문제를 gradient descnet 알고리즘으로 NN 를 풀었다.
-
이는 는 convex 일떄만 적용되었다, 하지만 우리가 풀 문제는 convex 하지 않은 경우가 많기 떄문에
- 는 우리에게 최적해를 가져다주진 못한다.
- 따라서 다음에 배울 여러 최적화 알고리즘을 사용할 수 있다.
-
최적화 알고리즘 : 지수 가중 이동 평균
- 경사하강법보다 더 빠른 최적화 알고리즘
- 최근의 데이터에 더 많은 영향을 받는 데이터들의 평균 흐름을 계산하기 위해 지수 가중 이동 평균을 구한다.
- 지수 가중 이동 평균은 최근 데이터 지점에 더 높은 가중치를 준다.
1년 동안의 온도 변화를 구해서 평균을 구하면 다음 모양이 나온다.
- 는 현재 평균값 (지수 가중 이동 평균)
- 는 t 번째 날의 기온 즉, 관찰값 (찍힌 파란점들).
이렇게 되면 빨간색 선처럼 평균값을 나타낼 수 있다.
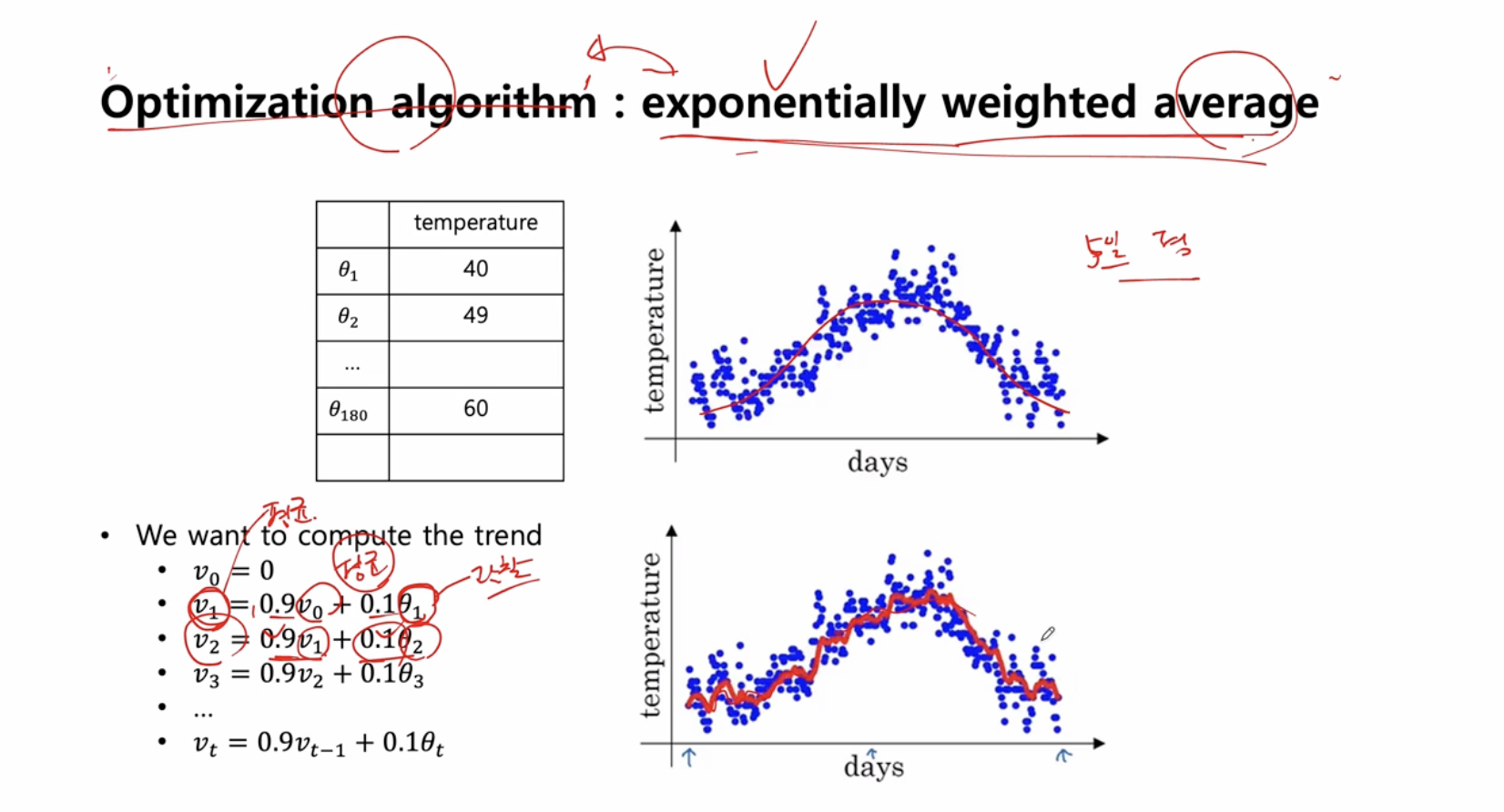
지수 가중 이동 평균
-
(현재 평균값) (weight) (바로 이전 step 의 평균값) (weight) (현재 관찰값)
-
는 하이퍼 파라미터로 최적의 값을 찾아야 하는데, 보통
-
는 기간 동안 기온의 평균을 의미
-
과거 평균값에 큰 weight 를 줄수록 오랜시간의 평균을 나타낸다.
- E,g 10 일 동안의 온도 평균 (red)
- E,g 50 일 동안의 온도 평균 (green)
-
과거 평균에 적은 weight 를 줄수록, 현재 관찰값에 더 많은 weight 를 주는 것과 같기 떄문에, 짧은 기간의 평균
- E,g 2 일 동안의 온도 평균 (yellow)
- 2일 평균이기 떄문에 노이즈가 많이 섞여있다.
-
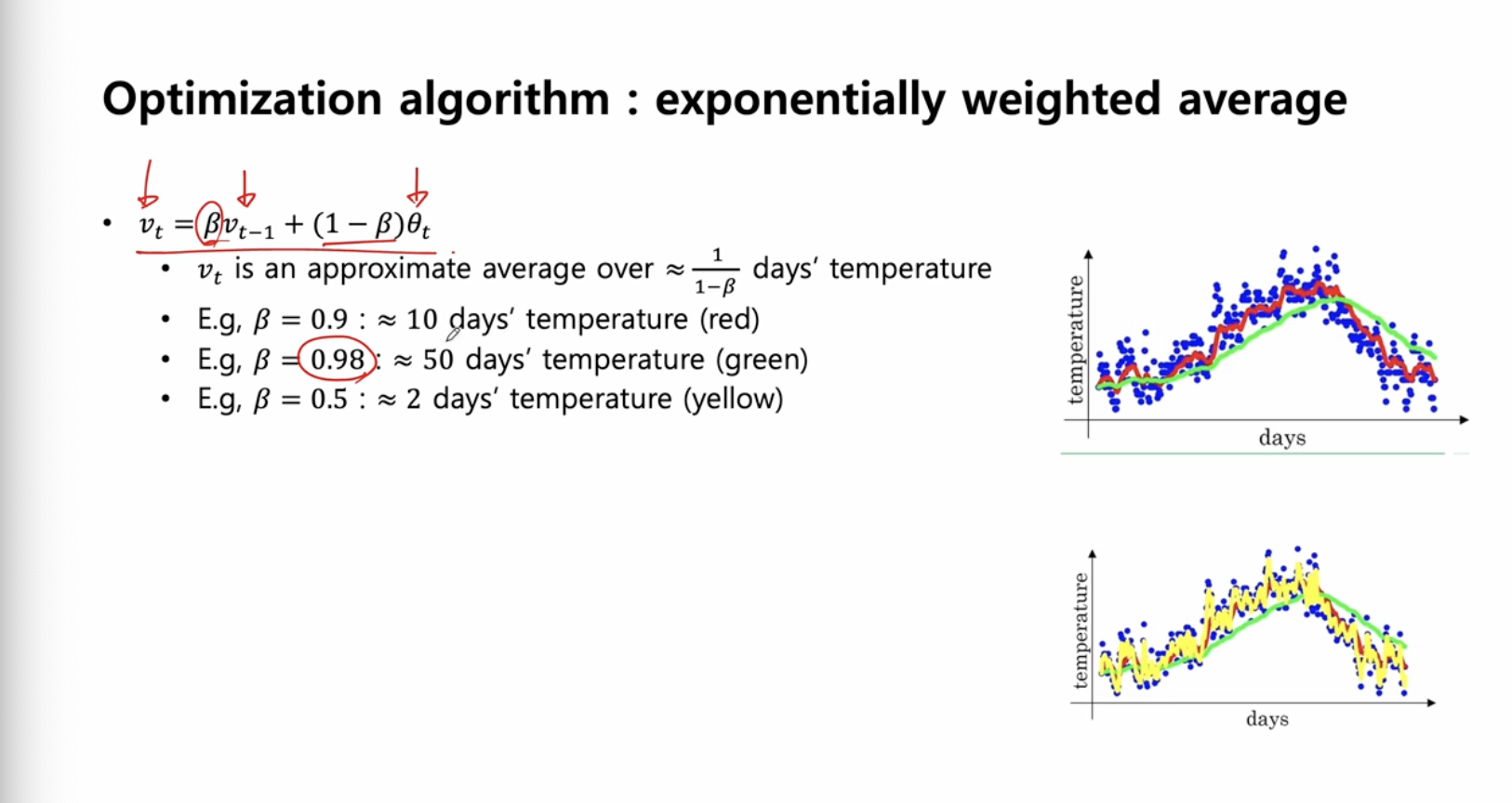
지수 가중 이동 평균 이해하기
-
의 식을 전부 풀어서 정리하면,
- ...
-
weight 가 예를 들어서 0.9 라면, 과거로 가면 갈 수록 weight 가 작아짐
- ...
-
그래프상에서 만약 현재값이 이라면 과거에서 현재로 갈수록 weight 들이 증가하는 것을 볼 수 있다.
-

지수 가중 이동 평균 구현
repeat {
Get next
}
-
왜 moving average 말고 이 식을 사용해서 평균값을 구하는지?
-
moving average 의 경우 예를 들어서 5일 평균을 구하라 했을 때 5일의 관찰값 들을 다 저장하고 있어야 하지만
-
의 경우 과거 평균값 하나()만 계속 저장하면 되기 떄문에
지수 가중 이동 평균의 장점은 구현 시 적은 메모리를 사용한다는 것이다.
-
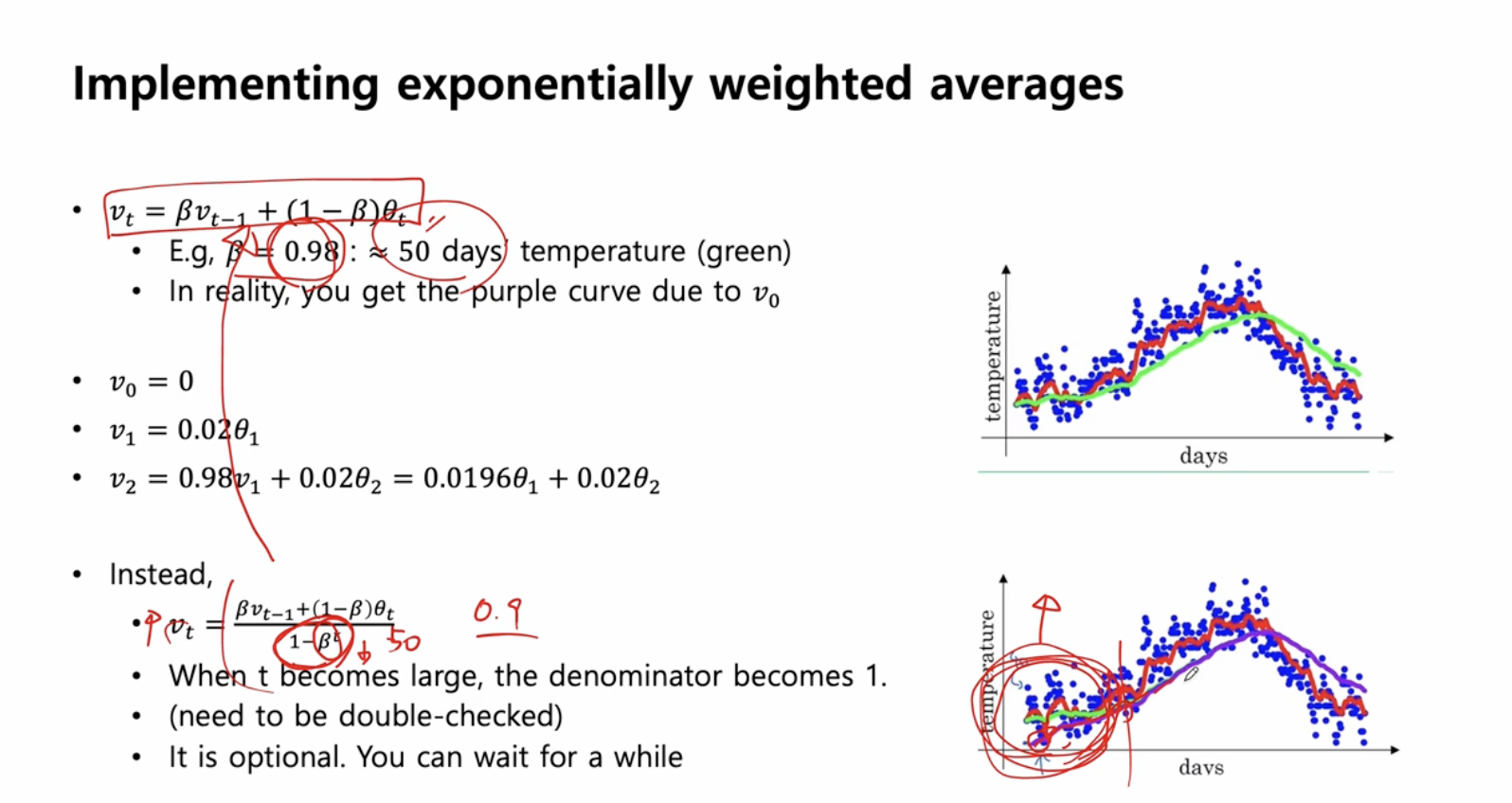
지수 가중 이동 평균의 편항보정
- 혹은 등 가 초기일 때 원하는 값보다 굉장히 낮은 값이 나오므로 편향 보정을 해줄 수 있다.
- 편향 보정으로 평균을 더 정확하게 계산할 수 있다.
- 이라면 현재 관측값에 를 곱한 값이 첫 번째 값이 되는데, 이는 우리가 원하는 실제 의 값과 차이가 나게 된다.
- 따라서 를 취해서 초기 값에서 실제 값과 비슷해지게 한다.
- 시간이 지남에 는 1에 가까워지므로 우리가 원하는 값과 일치하게 되기 때문에 보통 머신러닝에서 구현하지는 않는다.
- 그렇지만 신경이 쓰인다면 구현하는게 옳다.
- 가 이면 50일 동안의 온도 평균을 나타내는데 (초록색 곡선)
- 실제로는 으로 인해 지수 가중 이동 평균 결과 보라색 곡선을 얻는다.
- 50일이 지나지 않았기 떄문에 초반에 보면 평균을 대표하지 못하는것처럼 보인다
- 충분한 데이터가 들어오지 않았기 떄문, 따라서 50일이 지나야 비로소 50일 평균을 대표하는것처럼 나타난다.
즉, 어떤 초반 부분에 어떤 데이터가 충분히 모이기 전에 이 값이 평균값보다 현저히 떨어지는 경향을 보이기 때문에 다음 식 사용
-
는 0.9 정도로 생각했을때 분모를 살펴보자
-
t 가 적을떄는 가 크기 때문에 분모가 작아지게 되어 값이 커지게 된다
-
따라서, 초반에 v 값을 boosting 하는 역할을 한다.
-
그런데 만약 t 가 크다면 (t=50), 가 굉장히 0에 가까워지게 되면 결국 이 식은 로 회귀 하게 된다.
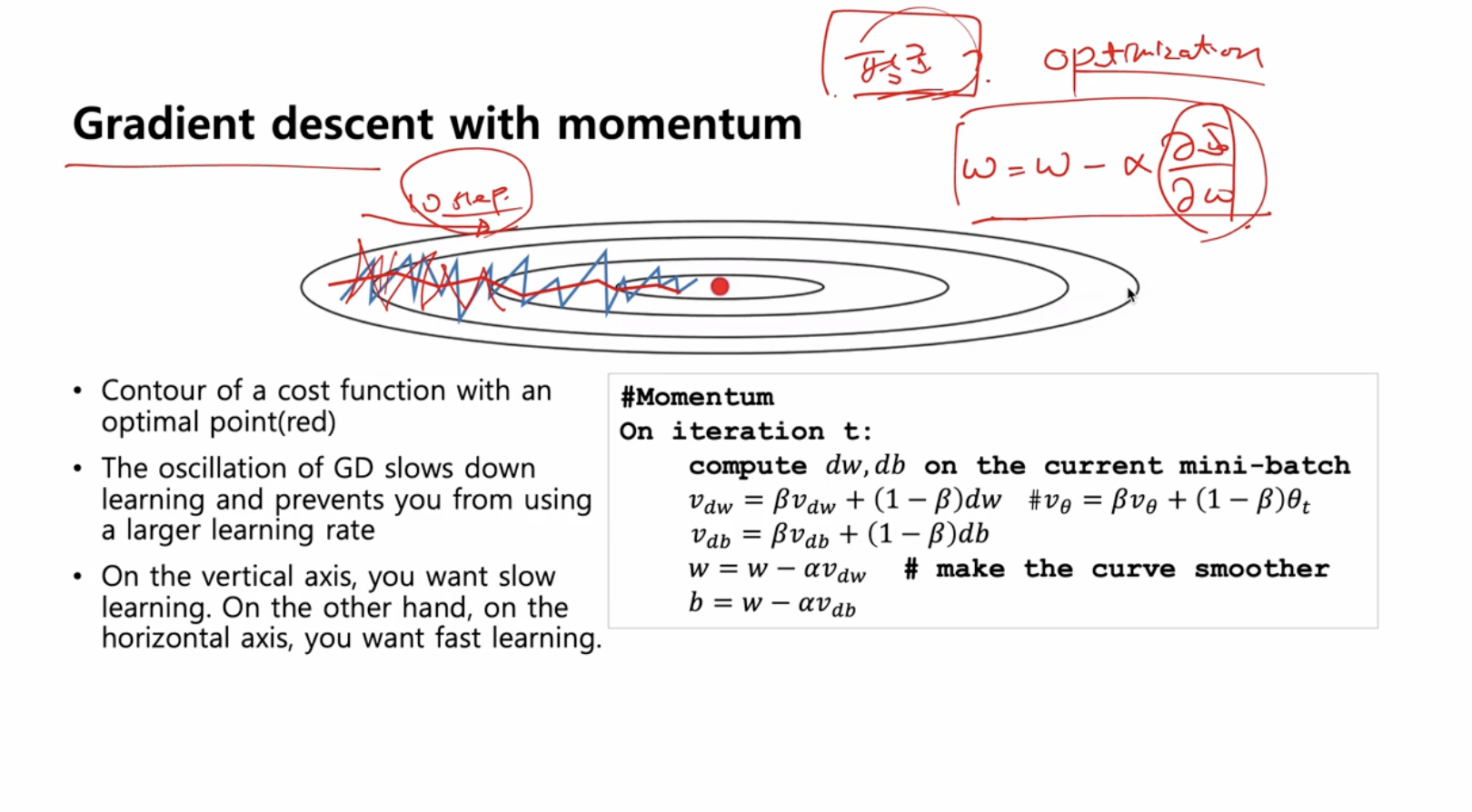
Momentum 최적화 알고리즘
-
모멘텀이 있는 알고리즘은 일반 경사하강법보다 빠르다
-
최적화를 위해 기존의 GD 식 를 구하는 방법을 바꾸고자 한다.
-
이 부분을 gradient 를 쓰는게 아니라 gradient 의 평균값을 사용할 것이다.
-
알고리즘은 다음과 같다.
- 하이퍼파라미터 :
- 는 최근 10개의 gradient 에 대한 평균
- step 이 10 단계정도 넘어가면 이동 평균은 준비가 되서 bias 보정은 더이상 일어나지 않기 때문에 bias 보정은 필요하지 않다.
-
모멘텀의 장점은 매 단계의 경사 하강 정도를 부드럽게 만들어준다.
-
설명
- 노이즈가 굉장히 많은 산을 내려가면서 gradient 의 평균 값을 쓴다는 것은
- 험난한 산을 내려갔다 올라갔다 하지만 예를 들어 내가 10 걸음을 갔더니 노이즈들의 어떤 경향이 보이더라 라는것이다
- 빨간색의 optimal point 가 있는 cost function 의 등고선 그림에서 마치 오른쪽 방향으로 내려가는것 같더라 라는 경향
- 따라서 순간순간의 gradient 보다, gradient 의 평균값을 사용하여 안정적으로 내려가겠다 라는 것이 gradient descent 를 개선하는 모멘텀 최적화 알고리즘이다.
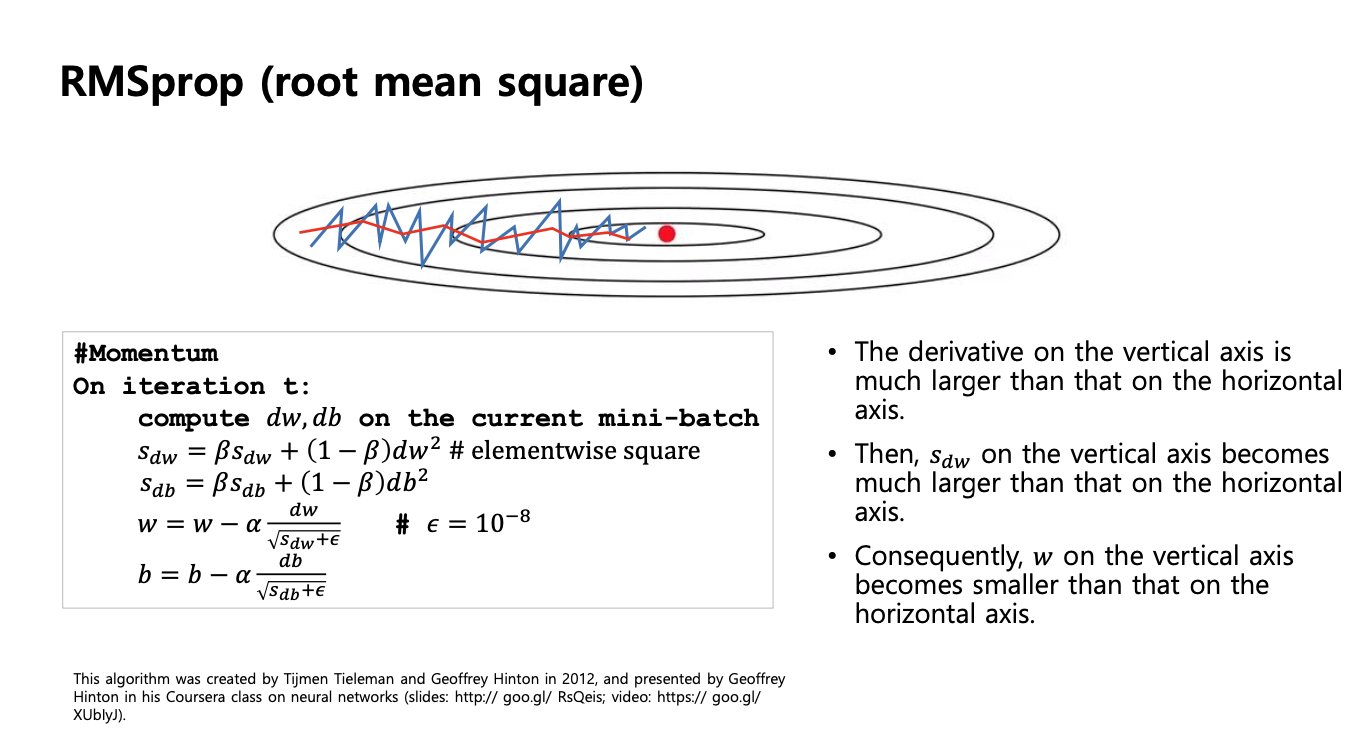
RMSProp 최적화 알고리즘 (root mean square)
-
알고리즘
-
- 기존 기울기(미분값 : gradient)의 제곱값에 대한 이동평균
- 은 벡터를 요소별(element wise) 제곱을 의미한다.
-
업데이트
- : 분모가 0이 되지 못하도록 하는 아주 작은 값
- 분모 : gradient 의 절댓값(gradient 제곱의 루트이므로)
- 따라서 gradient 의 크기를 gradient 의 절댓값으로 나누었으므로 방향만 존재하게 된다.
-
-
RMSProp 의 장점은 미분값(gradient)이 큰 곳에서는 업데이트 시 큰 값으로 나누어 주기 떄문에 기존 학습률 보다 작은 값으로 업데이트 된다.
-
따라서 진동을 줄이는데 도움이된다.
-
반면 미분값이 작은 곳에서는 업데이트시 작은 값으로 나누어 주기 떄문에 기존 학습률 보다 큰 값으로 업데이트 된다.
-
이는 더 빠르게 수렴하는 효과를 불러온다.
Adam 최적화 알고리즘
- Adam 은 Momentum 과 RMSProp 을 섞은 알고리즘이다
- 알고리즘
- 로 초기화
- Momentum 항 :
- RMSProp 항 :
- bias correction :
- 업데이트 :

학습률 감쇠
-
작은 미니 배치 일수록 잡음이 심해서 일정한 학습률이라면 최적값에 수렴하기 어려운 현상을 볼 수 있다.
-
학습률 감쇠 기법을 사용하는 이유는 점점 학습률을 작게 줘서 최적값을 더 빨리 찾도록 만드는 것이다
- learning rate 를 점점 작게 만들기(학습 초기에는 뛰어가다 뒤로갈수록 촘촘하게 걸아가는)
-
다양한 학습률 감쇠 기법들이 존재.
-
1 epoch 전체 데이터를 1번 훑고 지나가는 횟수
-
-
(exponential dacay 라 부름)
-
-
-
step 별로 를 다르게 설정.

-
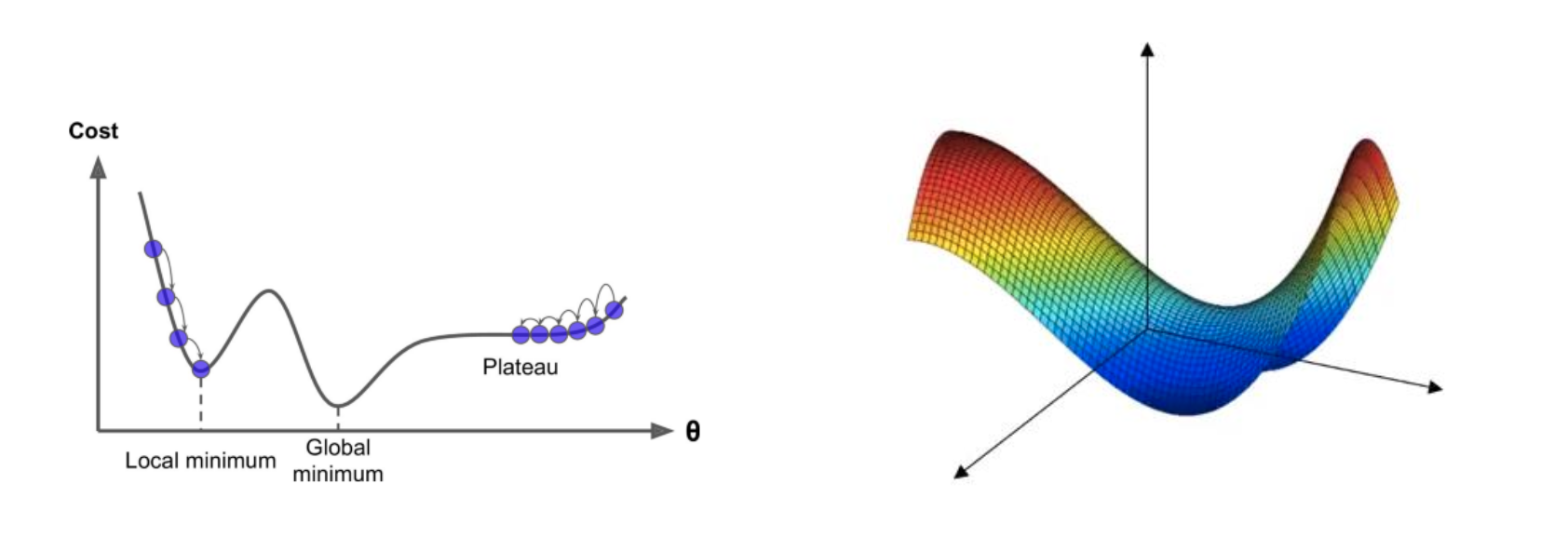
최적화가 어려운 이유
- local optima 문제
- 미분값이 0인 대부분의 점은 local optima가 아니라 saddle point 이다.
- 예를 들어, 20000 차원을 고려할 때, 모든 방향의 함수는 local optima가 되기 위해 볼록(convex)하거나 오목(concave)해야 한다.
- plateaus 문제
- plateaus 는 bad local optima 에 갇힐 가능성은 없다.
- plateaus를 건너는 데는 매우 오랜 시간이 걸릴 것이고, 만약 가다가 너무 일찍 멈추게 되면 절대로 global minimum 에 도달하지 못할 것이다.