machine learning에서는 일반적으로 학습하기 전에 전체 data를 training set과 validation set, test set으로 나누는 과정을 거친다.
data set 중에서 training set은 모델을 training(학습)시키는 데에 활용하며, test set의 경우 모델을 evaludation(검증)하는 데에 사용한다.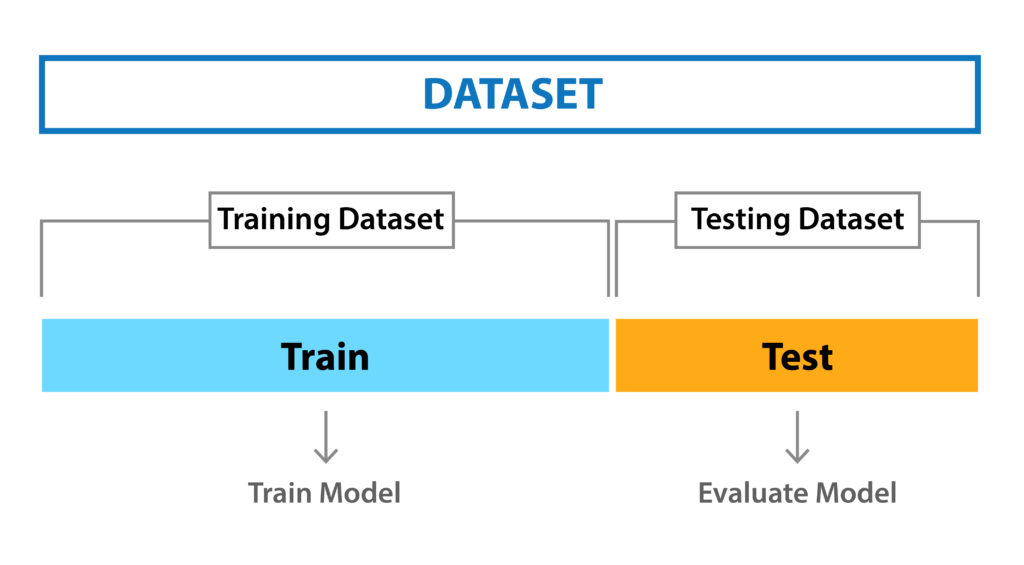
머신러닝 모델의 학습에서 전체 데이터를 학습에 전부 사용하지 않고 나누어 사용하는 이유를 알아보자.
machine learning은 컴퓨터에게 학습을 시키는 것이다.
즉 학습하는 데에 있어 정답을 알고 학습을 할 경우, 주어진 data set에서는 높은 확률로 정답을 맞힐 수 있겠지만 새로운 데이터가 input으로 주어질 경우, 낮은 확률로 정답을 맞힐 가능성이 커진다.
이를 overfitting(오버피팅, 과적합)이라 한다.
overfitting을 간략하게 설명한다면 기존 data set에서의 답을 컴퓨터가 학습하며 달달 외운 거다.
그러니 기존 data set은 통달했겠지만, 새로운 문제에 대해서는 해답을 잘 찾지 못하는 것이다.
컴퓨터를 학습시키기 이전에 기존의 있던 데이터를 활용하여 학습한 뒤에 새로운 데이터가 들어왔을 때도 일반화된 답을 낼 수 있도록 하는 목적이 있다.
그렇기 때문에 학습 이전에 training set과 test set으로 split(나뉘다)해준다.
보통 split 할 때는 8:2, 7:3, 6:4로 진행하며 data size, task마다 다르지만 보통 8:2로 진행한다.
추가적으로 training set, test set과 별개로 validation set이 있는데, 이 또한 split 해주는 이유를 알아보자
validation set은 예를 들어 시험으로 치자면 모의고사에 해당한다.
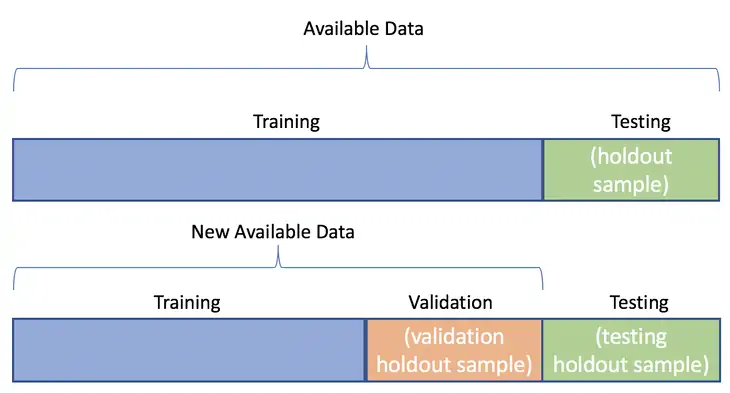
이미지에서 보이는 것과 같이 validation set은 이전 split 한 training set에서 다시 한번 training, validation 으로 split 하여
일반적으로 (training set) 6 : (validation set) 2 : (test set) 2로 split 해준다.
추가적으로 편중된 학습을 보완하고자 cross validation이 있으며, 가장 일반적인 교차 방법으로는 k-fold cross validation이 있다.
