Task 별 sequence data를 처리하는 attention 학습 예정
Seq2seq with RNN
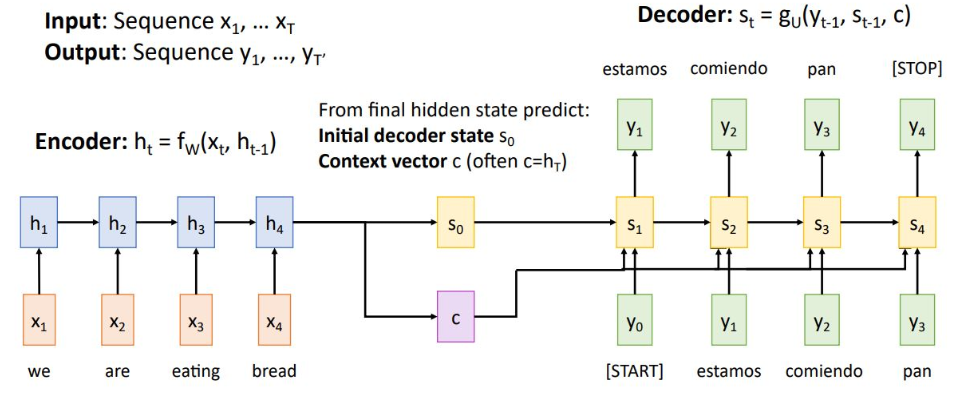
context vector는 input sequence를 single vector로 요약하여 decoder에 전달함
그러나 input이 sequence가 짧은 경우에는 잘 작동하지만, 한 권의 책 같은 학습 data가 들어오게 되면 잘 작동하지 않음
1. 하나의 context vector가 모든 input 정보를 압축하므로 정보 손실 발생
2. backprop시 gradient vanishing 문제
-> 이와같은 문제로 매 step별 context vector를 생성하는 Attention 기법 생성
Seq2Seq with RNN and Attention
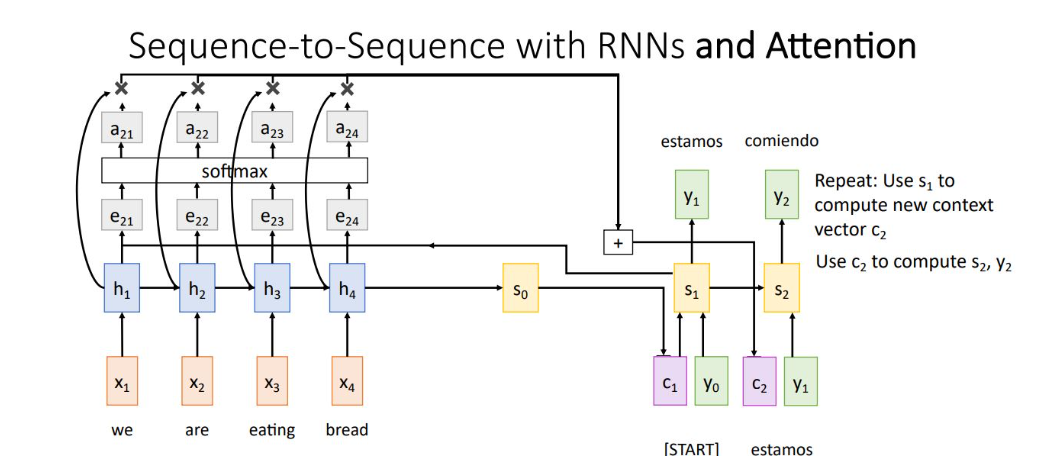
전체 구조는 위와 같음

alignment function을 통해 et,i의 scalar score를 추출. alignment function은 다양하게 사용되지만, dot product를 사용하기도 함
output score는 decoder의 현재 시점 t에서 encoder의 각 state에 집중하는 정도를 나타냄
soft max를 거쳐 et,i 는 at,i로 변환이 되고 attention weight이 되는데, 각 hidden state에 얼마나 가중치를 줄 것인지를 결정
decoder의 context vector ct는 attention weight과 hidden state의 weighted sum임
Decoder는 ct와 input yt-1을 사용하여 t시점의 state St를 생성하고 predict된 output 생성
이 모든 연산들은 미분가능하고 backprop과정을 통해 학습이 가능하여 network가 어떤 시점의 input state에 집중해야 하는지 학습함
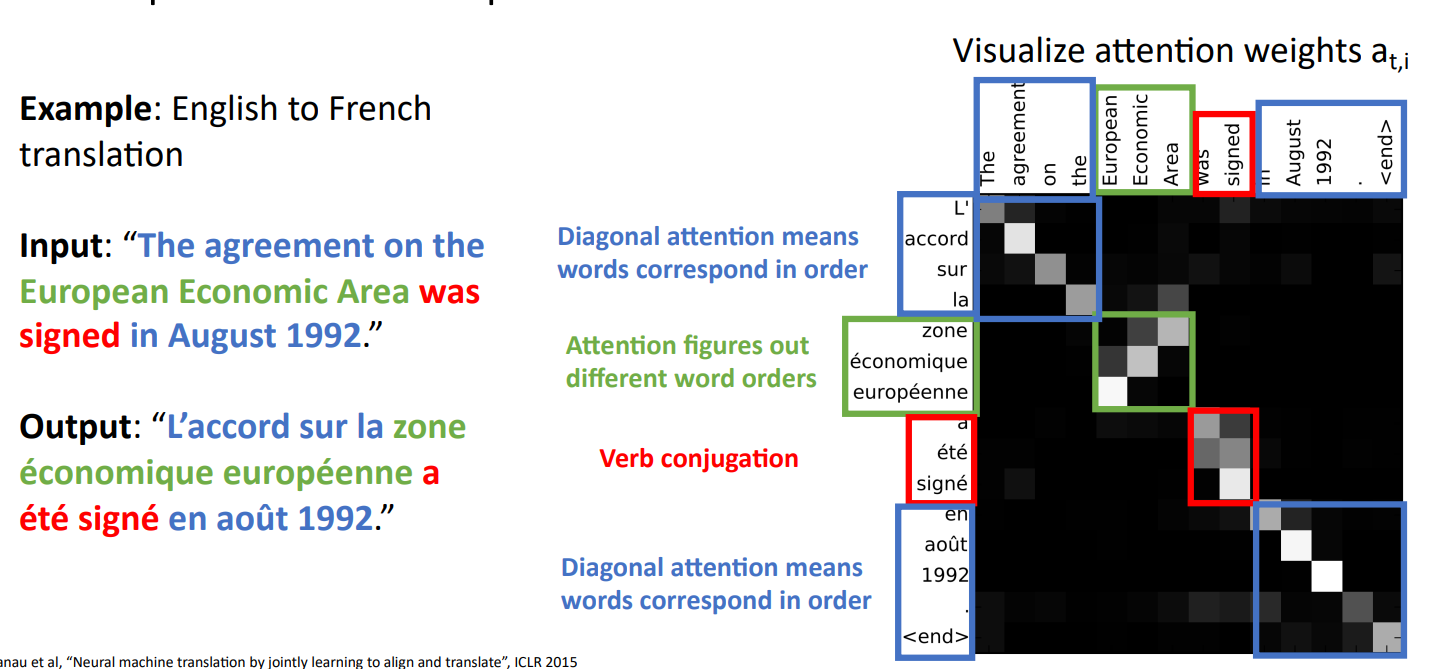
영어를 프랑스어로 해석하는 예시
attention weight을 통해 모델이 시점별로 input의 어느 state에 집중하는지를 볼 수 있음
Attention mechanism은 어느 input의 state에 집중할 것인지를 계산하기 때문에 ordered sequence일 필요는 없음
Image captioning with Attention
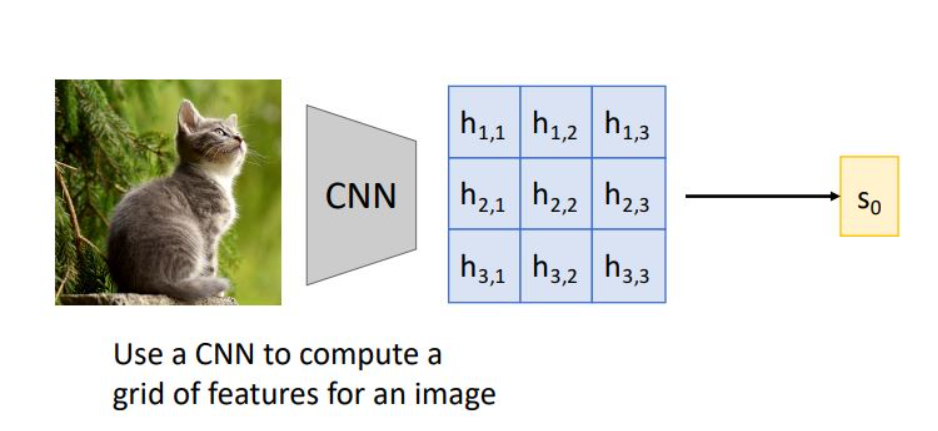
이전 RNN의 imageg captioning의 경우 feature vector를 뽑아내고 decoder의 input으로 사용했었는데, 여기서는 CNN에서 grid 형태로 feature vector를 뽑아내어 decoder의 input으로 사용함
*grid of feature vector는 spatial position임
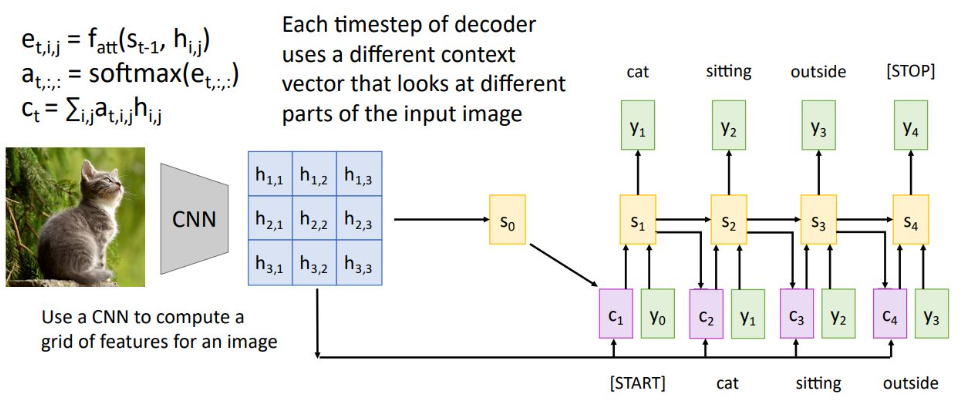
현재의 state st를 통해 alignment fn, softmax 거쳐 attention weight을 만들고 hidden state와 weighted sum 하여 다음 state의 context vextor로 사용
-> 각 time step에서 grid의 각각 feature vector들과 decoder의 st와 weighted sum을 시켜 context vector를 만드는 것

model이 이미지를 받아 각 step별 출력을 할 때 각 state에서 어떤 vector에 높은 가중치를 가지는지 시각화

또한 및줄 친 단어를 출력하는 state에서 그림의 어느 grid를 attention 하는지 보여준 것
Attention Layer
다양한 domain에서의 활용을 위해 일반화가 필요함
1)
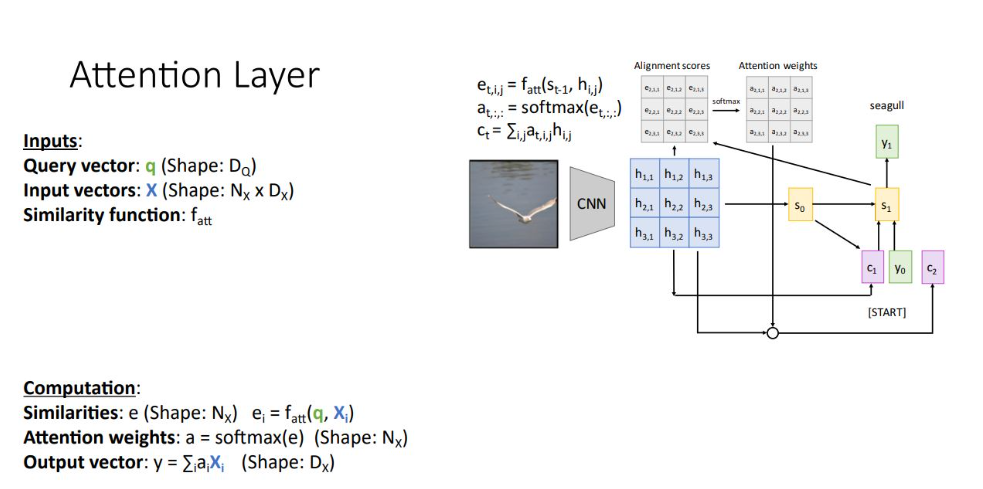
notation을 변경하여 일반화함
Input
1. Query vector q : decoder의 현재 시점 이전 hidden state vector
2. Input vector X : encoder의 각 hidden state의 collection
3. Similarity function fatt : query vector와 input vector를 비교하기 위한 함수
Computation
1. Similarities : query vector q와 input vector Xi를 silimarity function으로 unnormalized similarity scores를 얻음
2. Attention weights a : silimarity function을 통해 얻은 e에 softmax하여 normailzed probability distribution
3. Output vector y : Attention weight과 input vector를 weights sum 함

Similarity function을 scaled dot product로 변환
이때 sqrt(DQ)로 나누는 것이 달라지는데, smiarity score ei를 softmax에 input으로 넣기 때문에 벡터의 차원이 클 수록 값이 매우 커져 saturate되기 쉬움. 이는 gradient vanishing 문제를 야기함.
2)
두 번째 일반화 과정으로 multiple query vector를 사용
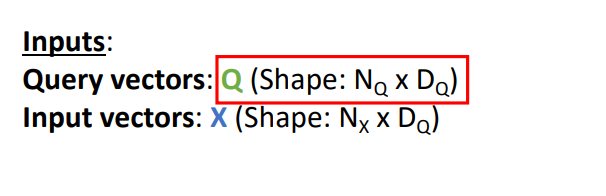
single query vector를 인풋으로 받지 않고, set of input query vector를 input으로 받아 similarity scores를 single matrix multiplication operation으로 하여 동시 처리
3)
세 번째 일반화 과정으로는 input vector X를 key vector K 및 Value vector W 로 분리

Wk와 Wv는 learnable matrix임

key vector K를 similarity 연산에 적용하고, vlaue vector V를 output 연산에 적용함
key, Value 연산 분리를 통해 좀 더 유연한 model 설계 가능
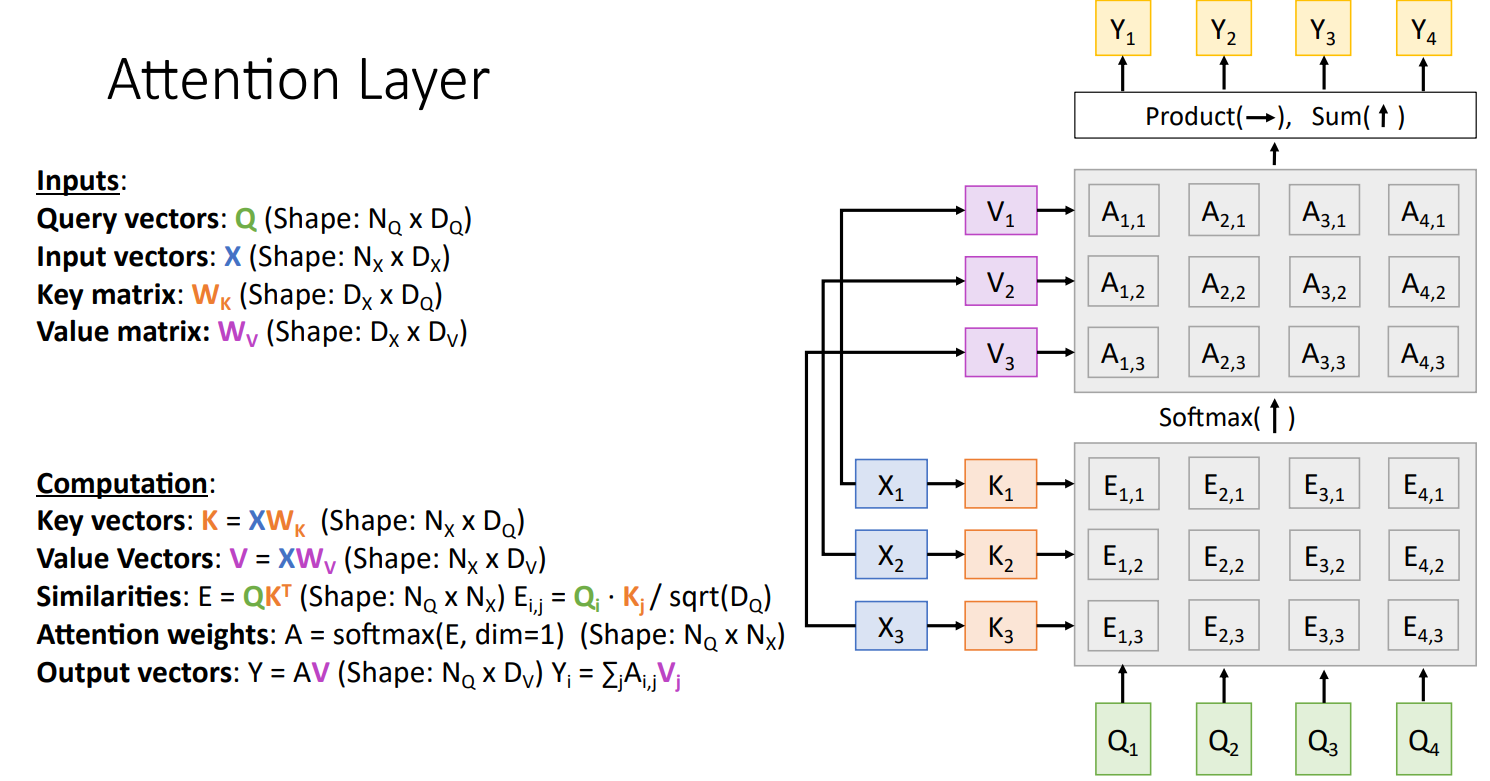
X : input 문장의 hidden state
Query : output 문장의 hidden state
- X로 key vector를 계산함 (각 X는 DX 차원이라면, K는 DQ 차원)
- Key vector와 Query vector간의 내적곱 (E를 통해 모든 alignment score를 동시에 계산)
- Query (여기서는 A1,1 A1,2 A1,3의 SUM이 1) 하나 당 softmax를 취해줌
- X에 weight matrix를 곱해 Value Vectors를 만듦 (V는 1*Dv 사이즈)
- Value vector와 attention weight을 곱하고 i가 같은것 끼리 더해서 Y를 출력
Self Attention Layer
Attention layer의 특이 case로 input set을 통해 input vector 끼리 비교하는 방식
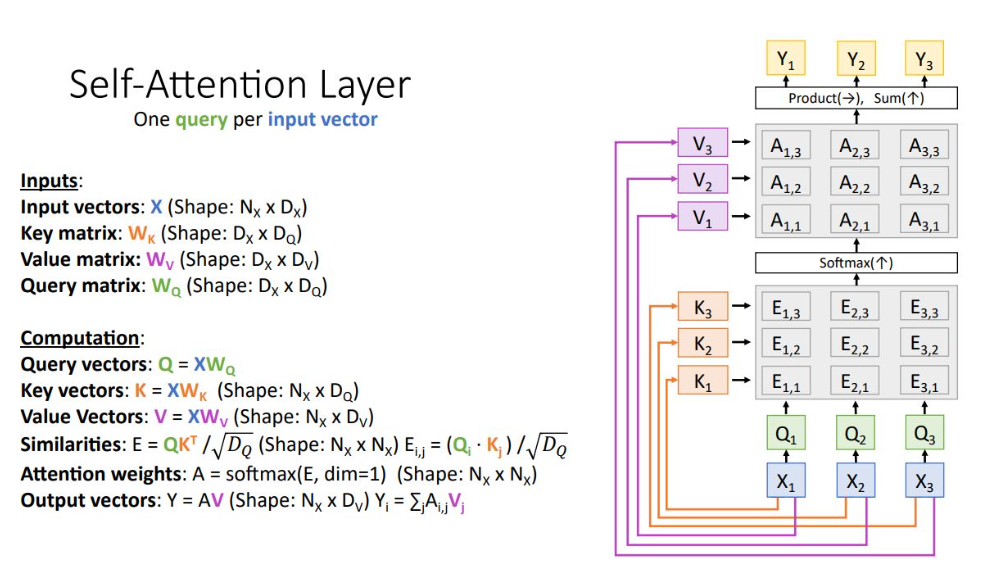
query vector를 input으로 받는 대신에 또 다른 weight matrix를 통해 input vector query vector로 transform 시킴
나머지는 Attention Layer와 동일
*Input vector의 순서를 바꾸는 permutting에 적용가능
- Input vector X 주어짐
- Query matix와 query vector가 새로 정의됨
- x로부터 key 벡터 만듦
- key 벡터와 query 벡터로 alignment matrix 만듦
- softmax를 통해 attention weight matrix 만듦
- attention 과 동일하게 X로 부터 value vector 만듦
- value vector 와 weight matrix product + sum을 하여 output 만듦
input에 무엇이 들어오든, input variables가 모든 요소들을 참조하여 output을 출력하게 됨
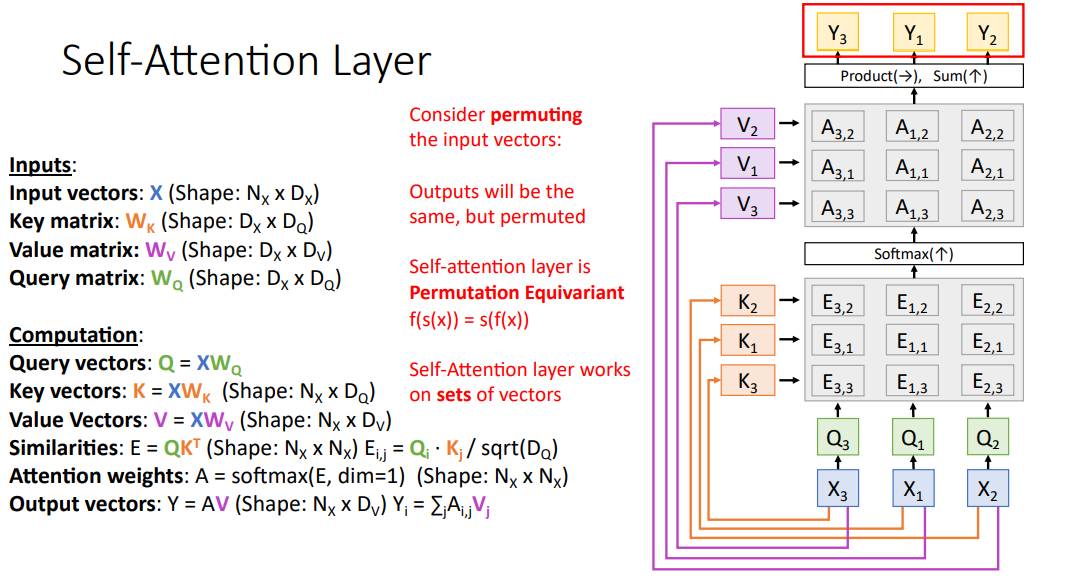
Input vector를 permutting 시키게 되면 query, value, output의 각 vector 또한 permute 된 상태
중요한 점은, self attention layer는 input 단어 순서를 기억하지 않음.
따라서, input 순서를 기억하게 하려면 position 정보를 추가해야 함
self-attetion과 permute 연산은 서로 순서가 바뀌어도 output이 동일
-> 즉, input의 sequence가 바뀌어도 결과는 set of vector의 output인 것은 동일함 (machine translation, image captioning 같은 경우는 input vector 순서가 permute 되면 안됨)
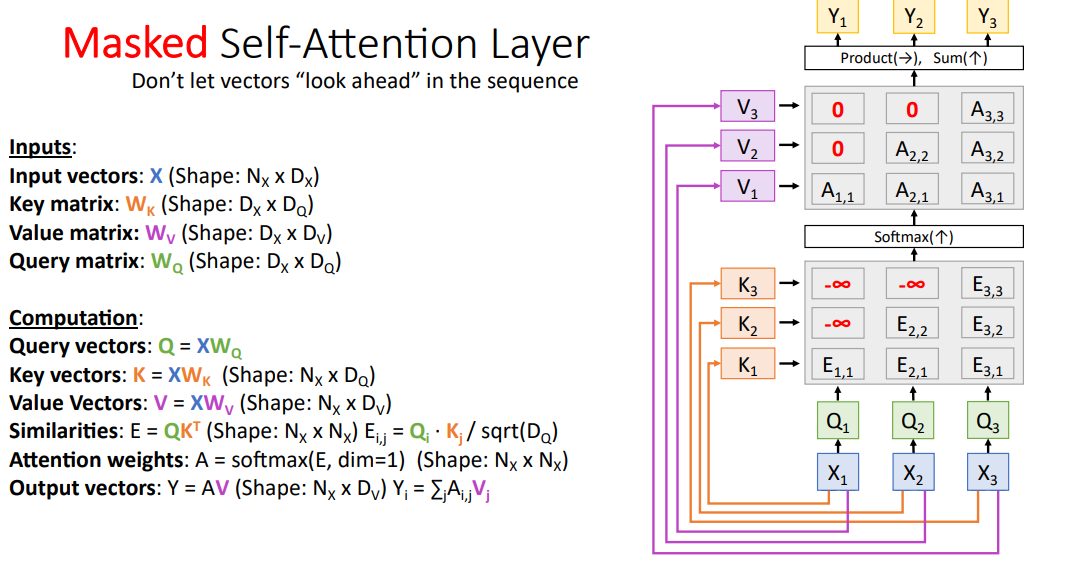
Masked self Attenion layer는 모델이 과거 정보만 기억하게 하는 것임
language model에서 현재 시점에서 미래에 있는 토큰을 참조하지 못하게 하는 것
similarity matrix E에 -inf 를 넣어 softmax에서 0이 되게 만드는 것
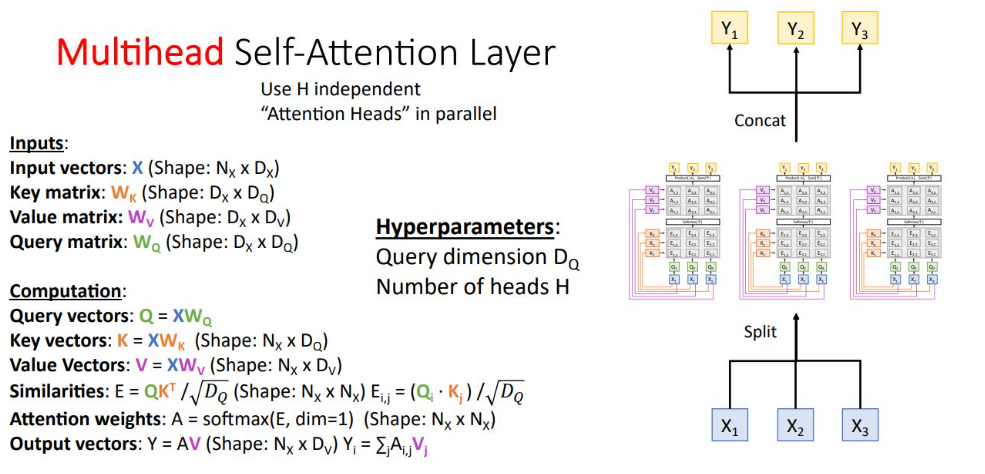
Multihead self-attention layer
H개의 self attemtion layer를 독립적으로, 병렬로 하여 처리함
Examples : CNN with Self-Attention
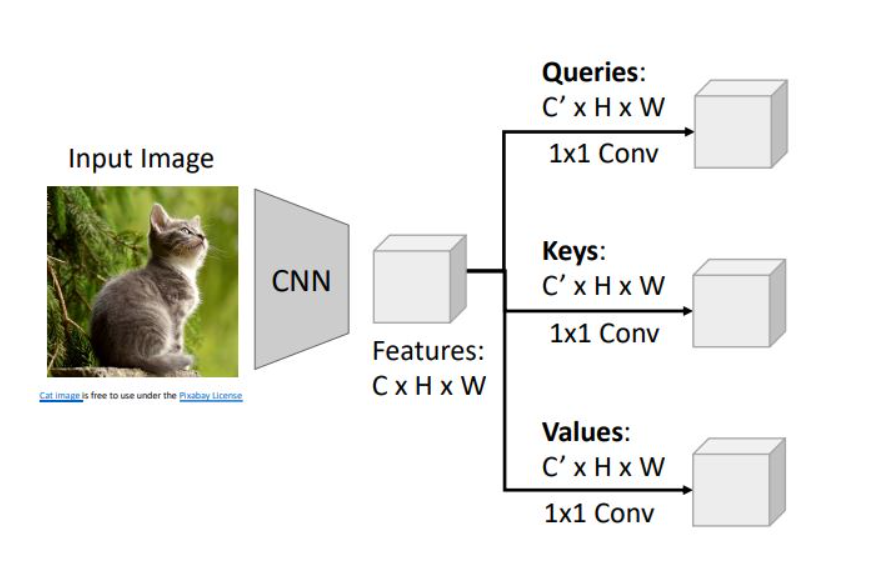
이전 image captioning에서와 같이 CNN으로 image에서 CxHxW size의 feature vector를 뽑아냄
feature vector를 1x1 convolution을 시켜 grid of Queries, keys, values로 변환. 각각의 1x1 weight을 가지고 진행함.
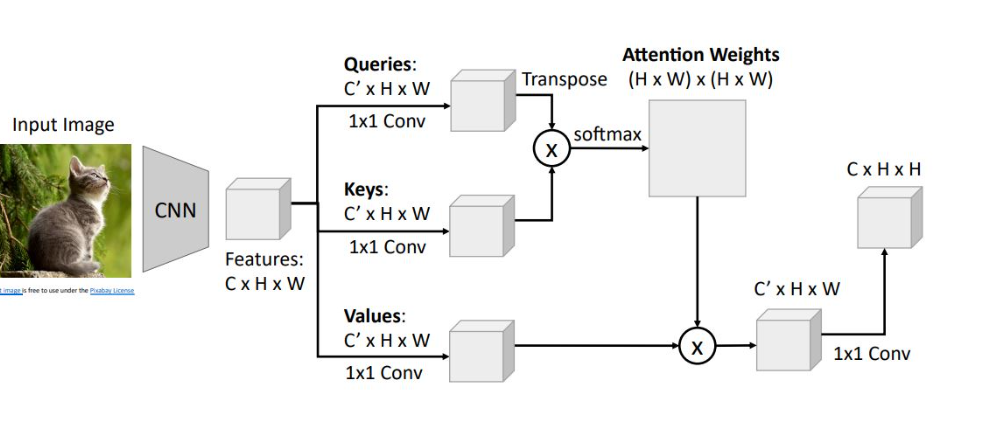
쿼리와 키를 내적곱하고 softmax를 거쳐 Attention weight을 만듦
Attention weight과 Value vector를 연산하여 new grid of feature vector를 생성
또다른 1x1 convolution을 통해 input feature와 channel dimension을 맞춤
이 과정을 self-attention module로써 neural network의 하나의 layer로 작동하게끔 만듦
Three ways of Processing Sequences
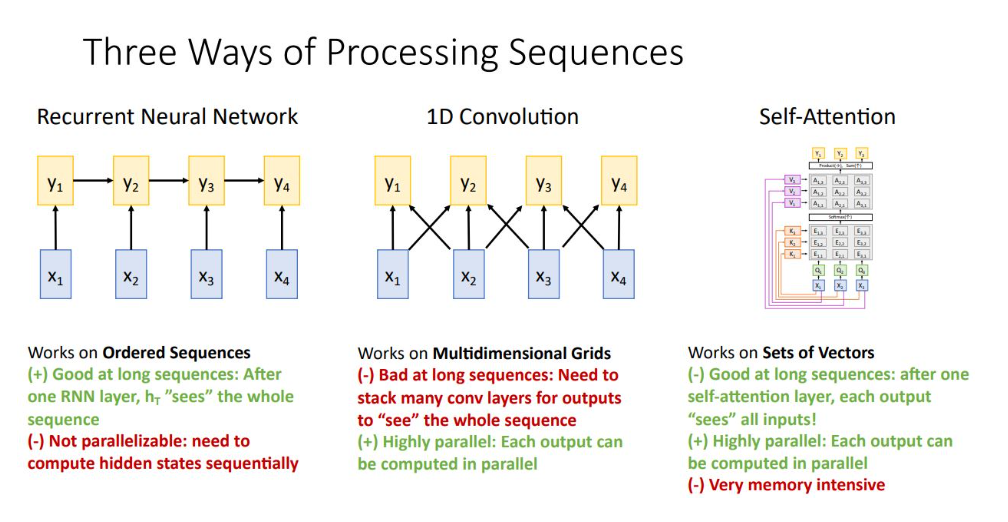
Sequence of vector를 처리하는 3가지 방법의 장단점
1. RNN
input sequence에 대해 일종의 summarize. LSTM의 경우 long seq를 다루는데 유리
GPU를 통한 병렬 연산 불가
2. 1D conv
각각의 kernel 을 독립적으로 연산 가능
long seq에 좋지 못한 연산 방법
3. Self-Attention
한 input set이 들어오면 vector들 끼리 query하여 비교하므로 각 output은 input에 영향을 받아 long seq에 유리
단지 몇 개의 matrix multipliers + softmax operation으로 이루어져 있어 병렬연산 가능하여 GPU에 적합
The transformer
Self-attention 만 사용하여 transformer block을 만듦
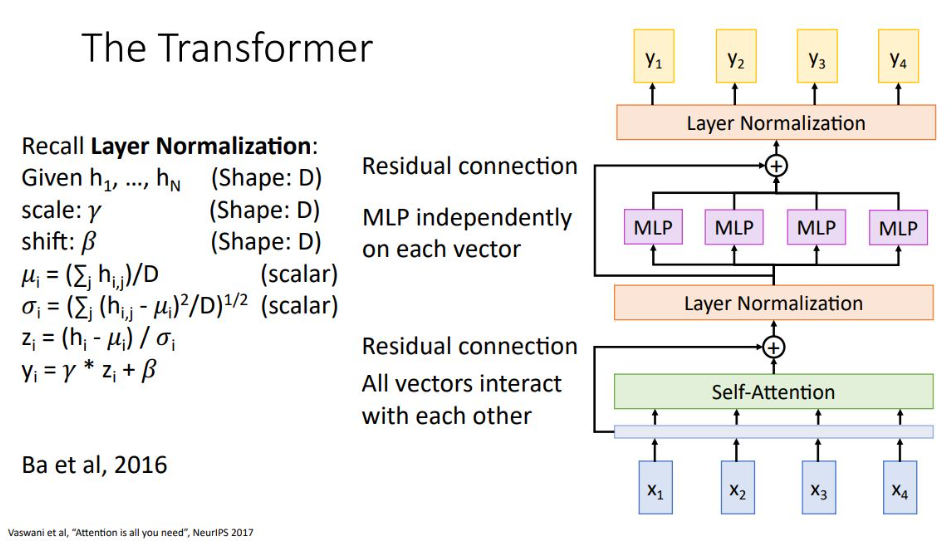
이전 Multihead self attention과 동일한 형태이지만, Layer normalization이 추가되어 batch normalization과 비슷하게 각각의 output vector들에 대해 독립적으로 normalize 함
또한 MLP를 Layer Normalization vector set에 대해 독립적으로 수행함
이 과정을 묶어 하나의 transformer block으로 사용함
가장 중요한 특징으로는 self-attention layer에서만 input vector간 iteration 이 이루어지고 Layer normalization 과 MLP에서는 각 vector들이 독립적으로 처리됨
즉, GPU 병렬 연산에 매우 최적화됨
Transformer는 Vision 분야에서 pretraiong & Finetuning 수행하는 basic block이 됨
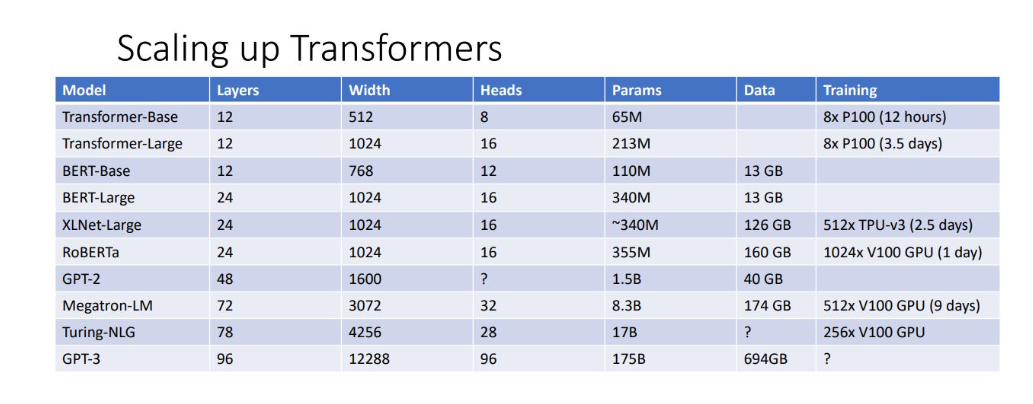
Transformer에서 더 발전한 여러 모델들이 있는데, layer를 더 많이 쌓고 큰 query를 사용하면 모델 학습 비용 및 시간이 늘어남
