
RNN 기본 구조 및 Vanilla RNN 수식, computational graph 다룸
RNN variants에 대한 구조도 알아볼 예정
Seq-to-Seq Process
RNN은 언어 도메인에서 주로 사용
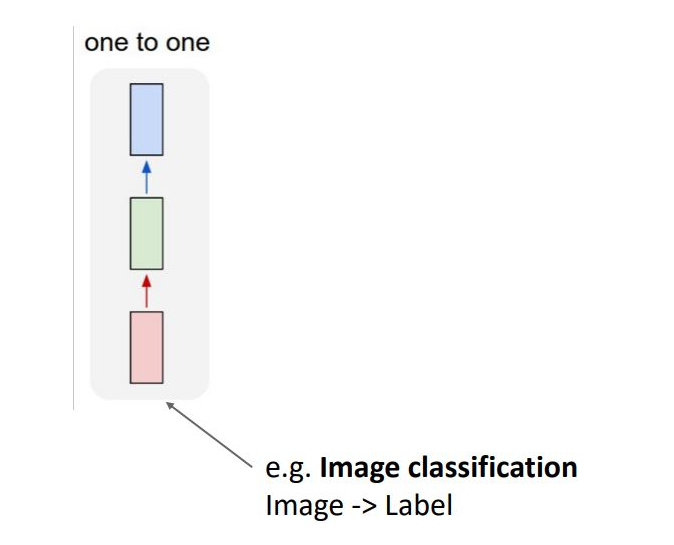
기존 CNN 혹은 Fully-Connected NN은 input, output이 1대1로 대응되는 one to one형태
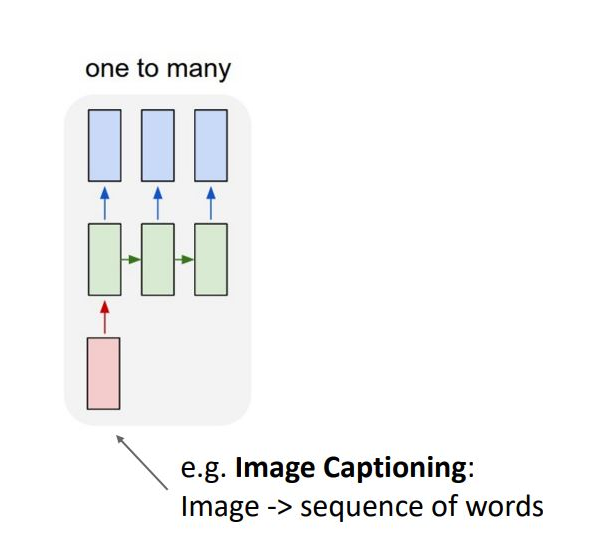
one to many 형태로 single-input을 입력으로 output을 single 라벨이 아닌 sequence 형태로 출력함
ex) 이미지 내용을 설명하는 single 이미지의 input에서 sequence of words를 output으로 내보내는 image captioning 이 있음
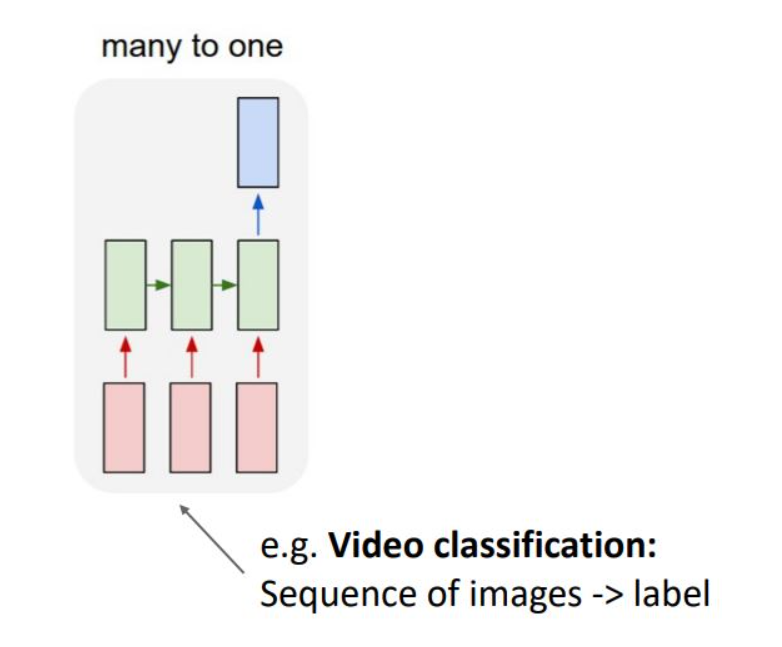
many to one 형태로 input이 squence이며, output은 single label을 출력함
ex) video frame이 input, output은 판별 정보로 video classification 을 예로 들 수 있음
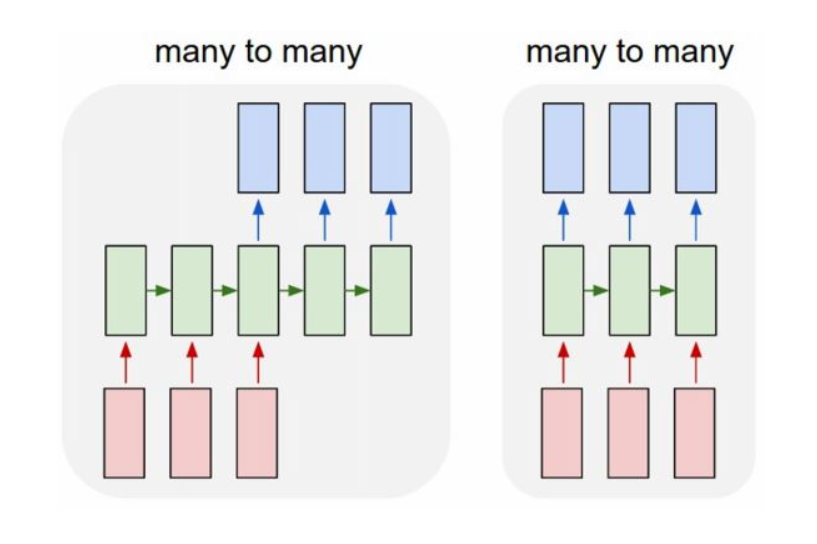
input 및 output 모두 sequence임 machine translation 형태라고 함 ex) machine translation, per frame video classification
Sequential processing of Non-sequential data
multiple glimpses를 주는 neural network으로, step마다 이미지의 한 부분을 보고 이전 step의 정보에 따라 classification decision을 함
Recurrent neural network
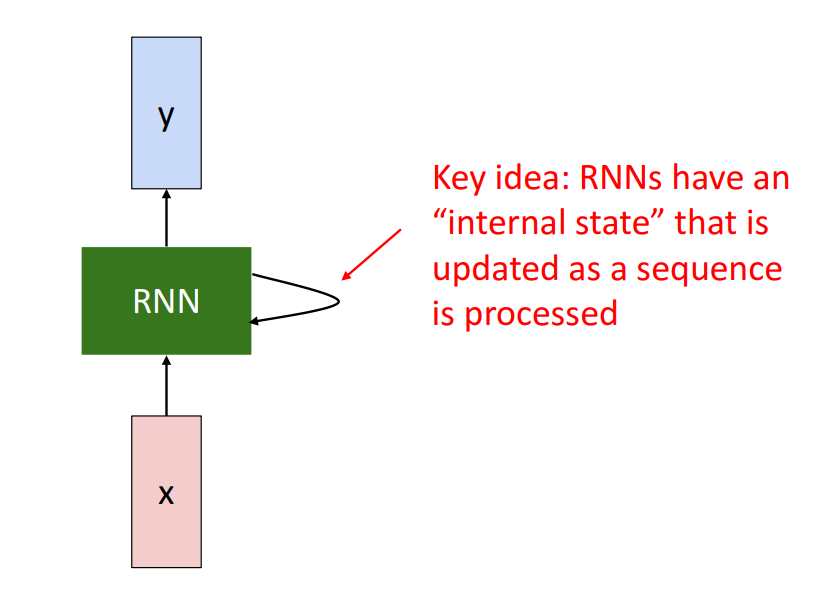
Recurrent neural network는 x를 input으로 network안에 hidden internal state를 통해 업데이트를 지속적으로 하고 output y를 출력함

hidden internal state는 다음과 같이 나타남
t-1 시점의 state에 t 시점의 input x를 input으로 받아 w의 함수인 f를 거쳐 t시점의 new state를 output으로 출력
*모든 time step에서 사용되는 parameter와 함수는 동일
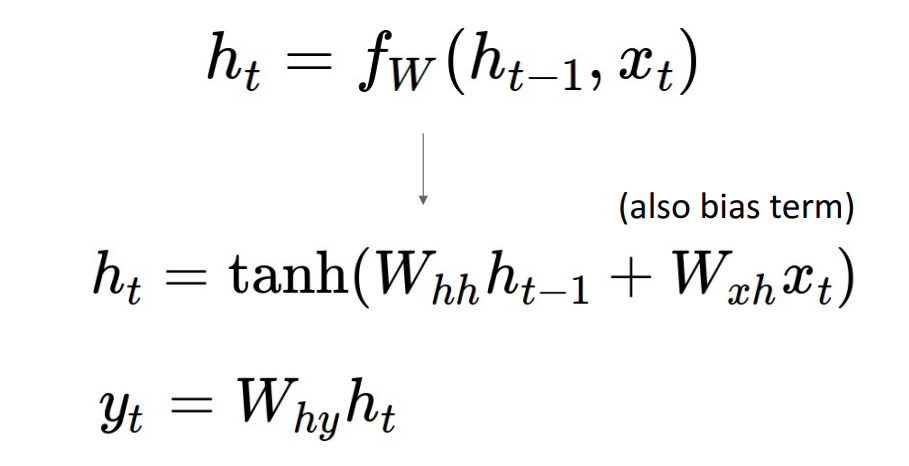
Vanila RNN 에서는 output을 다음과 같이 구함
hidden state를 구하기 위해 2개의 learnable matrix Whh, Wxh가 있고, 두개의 dot porduct 를 더해주고 tanh activation fn.
hidden state에 weihgt를 곱하고 output을 냄
RNN computational graph
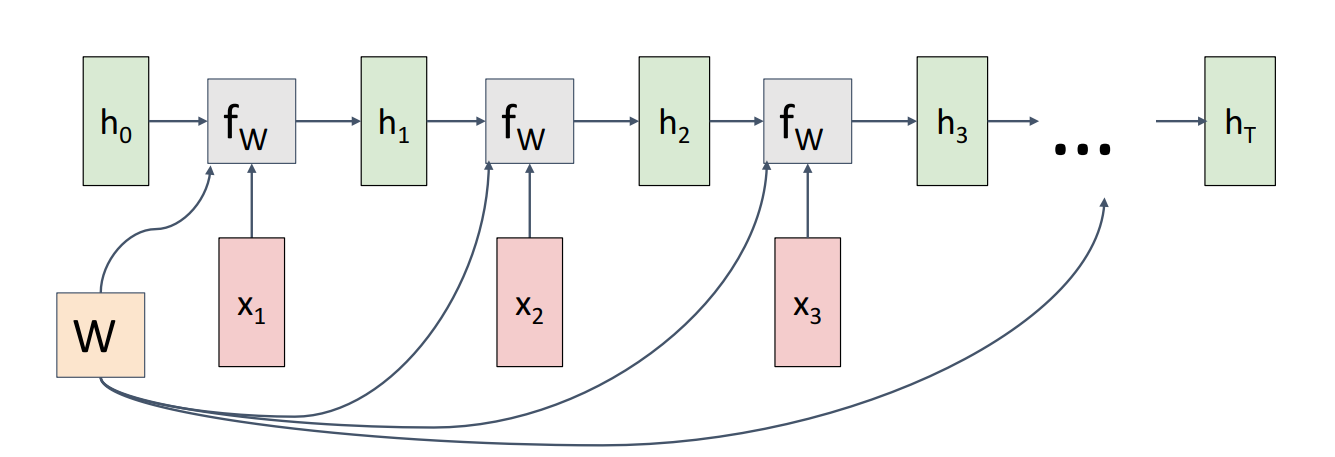
RNN의 hidden state h0는0으로 initialized 됨. same fn, weight를 가지고 input x1, x2, ... xt length에 대해 반복함
Copy gate로 볼 수 있고 각 fw 노드의 gradient를 summation하는 역할을 함
1) Many to Many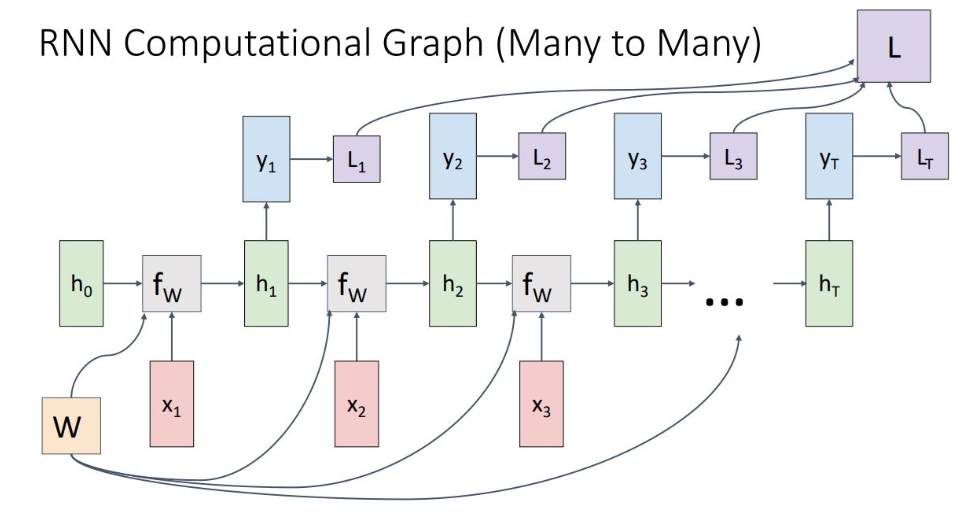
input을 sequence로 받아 time step 마다 output을 출력함. ht에서 output을 출력하기 위해 weight matrix Wy 사용되며, yt을 통해 step 별 로스인 Lt가 생성되고, final loss는 이를 다 더해서 계산
2) Many to One 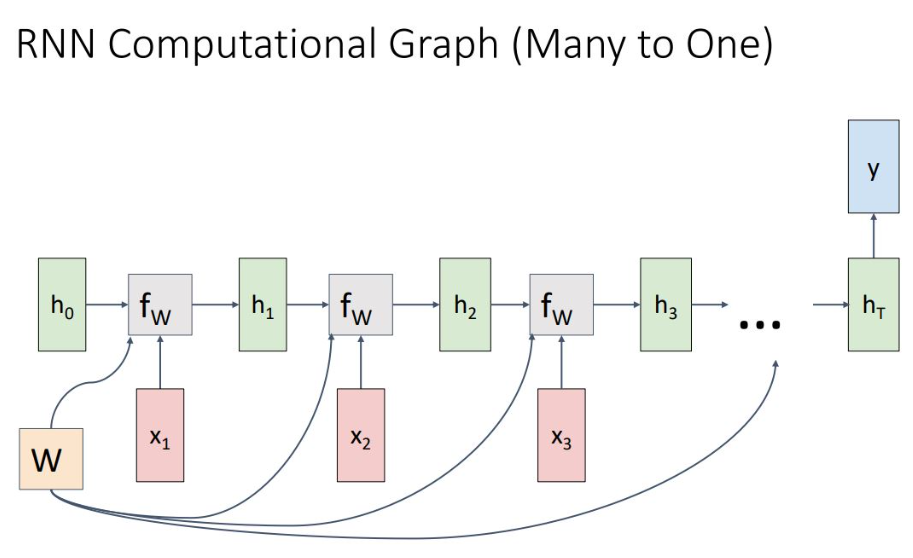
final hidden state는 ht가 계산된 이후 weight 을 곱해져 나오며 network의 모든 sequence 정보들이 하나의 output 정보에 활용됨
3) One to Many 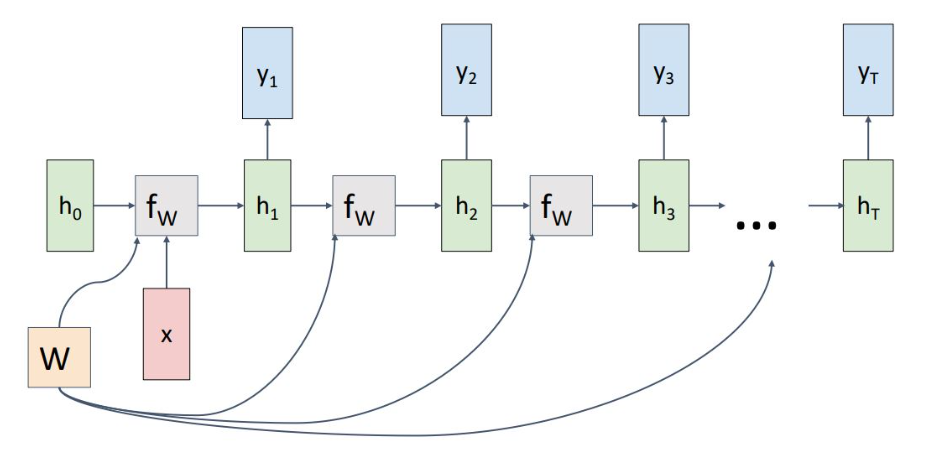
하나의 input에 계속적인 recurrent를 통해 sequenctial output을 냄
4) sequence to seqeucne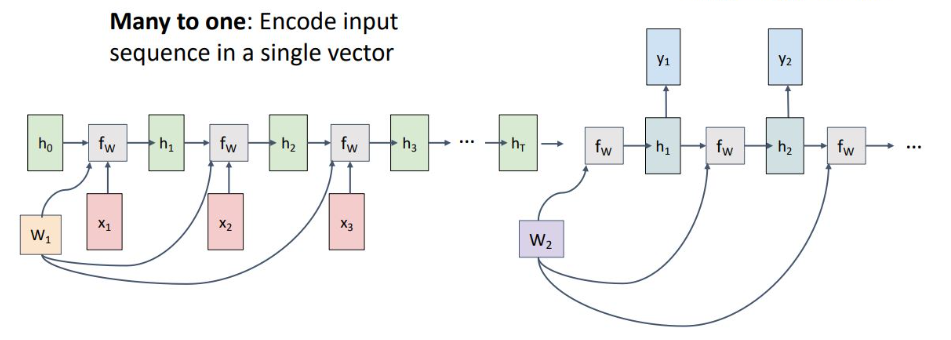
seq to seq는 many to one이 encoder 역할을 하고, one to many가 decoder 역할을 함
encoder와 decoder를 분리한 이유는 weight matrix를 분리하기 위함
Language Model
character predition 문제 (문장 채우기)
input data stream을 받아서 매 time point마다 next charater 예측
학습
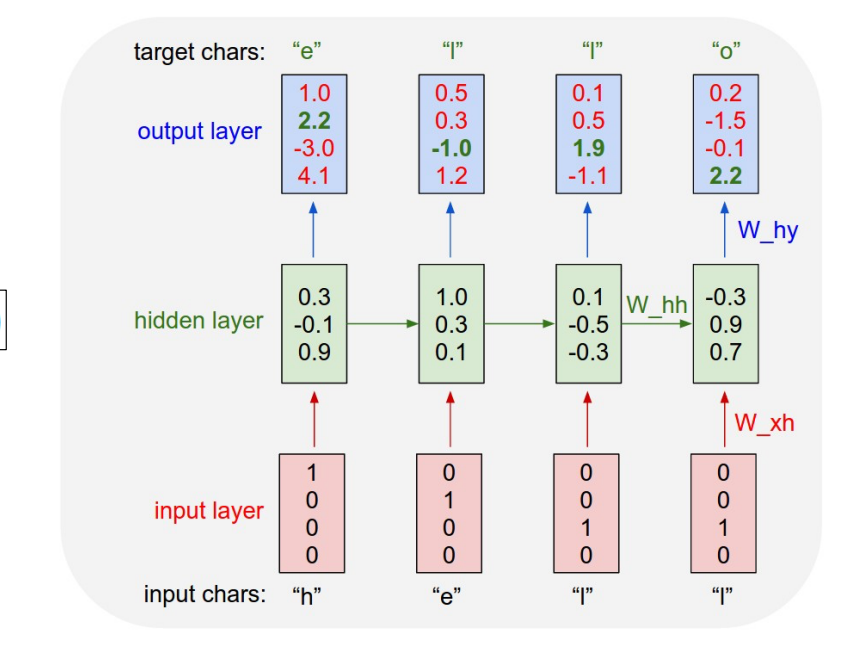
정해진 단어를 one-hot encoding vector로 input
각 time point별 단어에 대한 예측 결과로 output 출력하여 다음 올 단어를 예측하게 됨
이는 처음 input h를 받으면 다음을 e가 나오게끔 cross-entropy loss를 학습하도록함
테스트
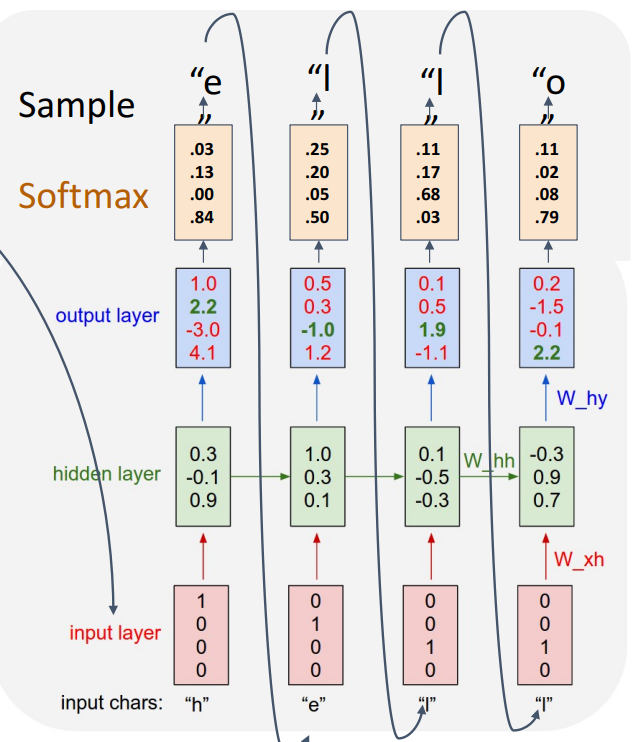
h만 input으로 입력해도 predict한 것을 다시 입력으로 넣어 sequence를 모두 예측 가능함
계산량을 줄이기 위해 one-hot vector와 weight matrix 연산이 비효율 적이므로 input layer와 hidden layer 사이에 Embedding layer를 추가함
연산 최적화
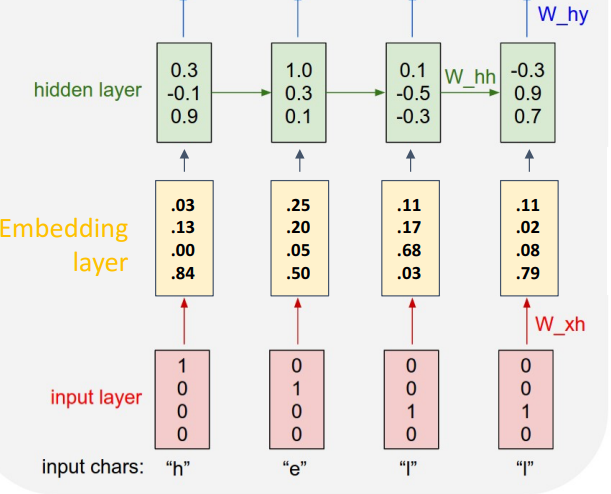
이를 통해 sparce한 matrix-vector 연산을 하지 않고도 특정 column만 추출해서 빠른 연산 가능
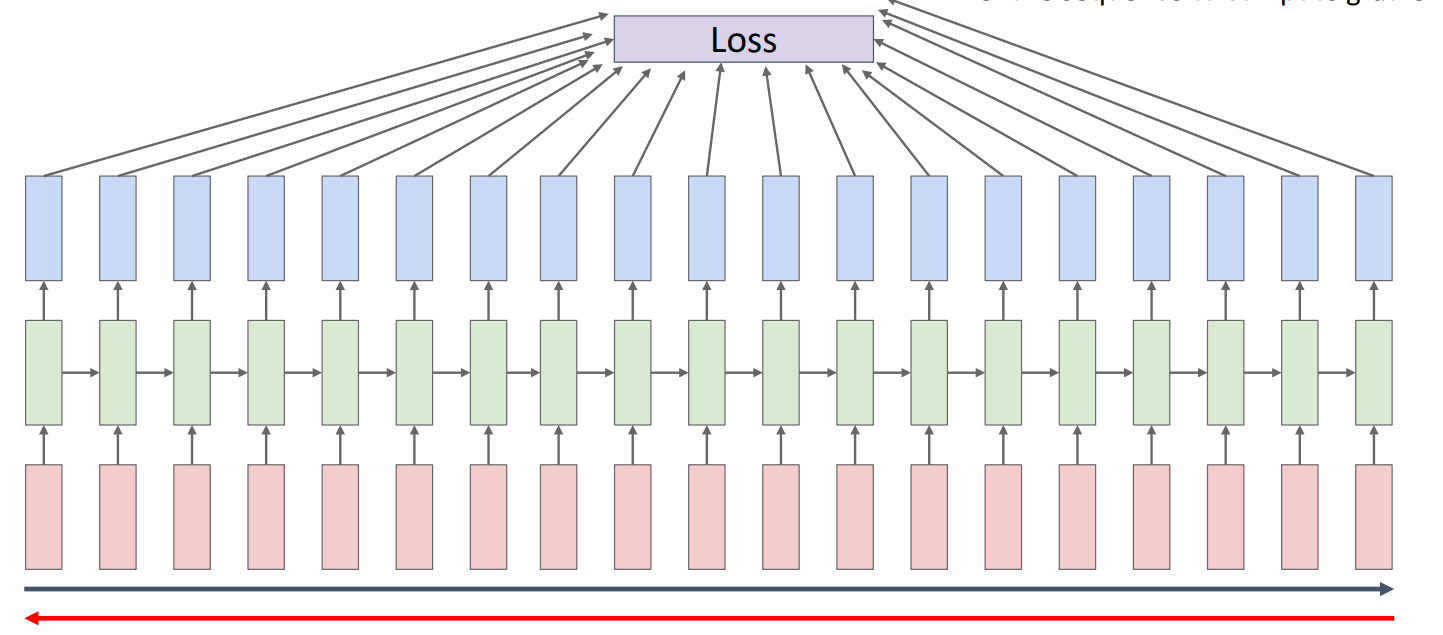
RNN language model에서 backpropagation에서 많은 memory를 요구한다는 단점이 있는데, Truncated backpropagation으로 극복함
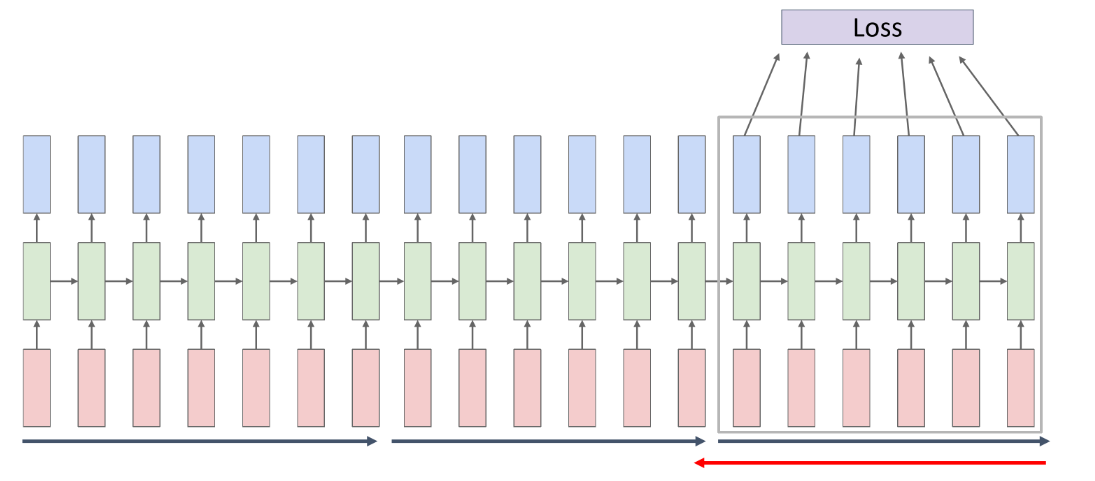
sequence를 잘라내어 진행하는 방법으로 chunk of sequence에서 자르고 W, hT를 이 단위로 업데이트하는 것을 반복함
Example : Character generation
쉐익스피어 작품을 통째로 학습함

학습을 점점 진행할 수록 text가 사람과 비슷해짐
수 천 페이지의 algebric geometry textbook 학습

수학적으로 맞지는 않지만 diagram 및 증명도 나옴
리눅스 코드 학습

code 형태로 나옴
Interpretable Hidden Unit
다양한 유형의 data에서 어떤 것을 학습하는지 연구
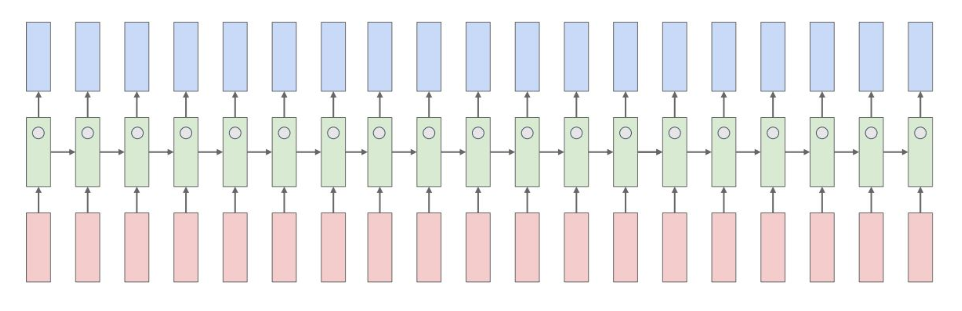
RNN 학습 후 predict 과정에서 hidden state vector를 tanh 거쳐 출력하는 과정에서 -1~1 의 boundary에서 character 값의 크기를 color 강도로 클 수록 빨강으로 표기하였고 hidden state의 element들이 어떻게 다른지 판단

리눅스 커널의 경우 직관을 얻을 수는 없음

어떤 hidden unit은 input에서 따옴표 앞 뒤로 character 값의 크기가 달라짐을 볼 수 있음

어떤 hidden unit은 엔터키를 기준으로 봄

어떤 hidden unit은 if 절 안을 봄

어떤 hidden unit은 depth가 깊어질수록 주목하는 cell도 있었음
-> 모델이 단순히 다음 문자를 학습하는 것이 아닌, data의 구조에 따라 의미 있게 학습을 진행함을 알 수 있음
Image captioning
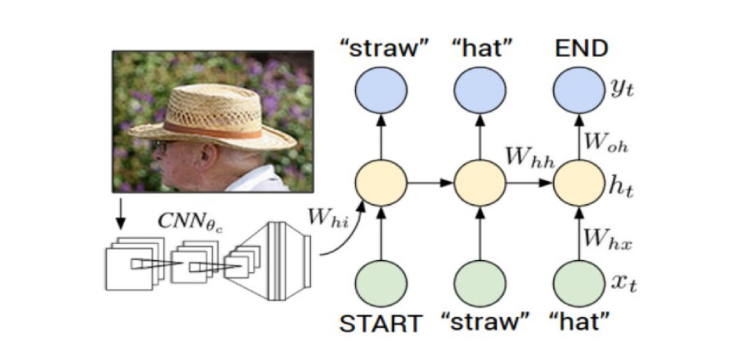
Input이 이미지이며, output은 이미지를 설명하는 문장을 return함
Input을 processing 하는 것은 CNN 아키텍쳐이고, 언어를 generate 하는 파트는 RNN 아키텍쳐임

Feature extraction을 하기 위해 마지막 FC layer는 제거함
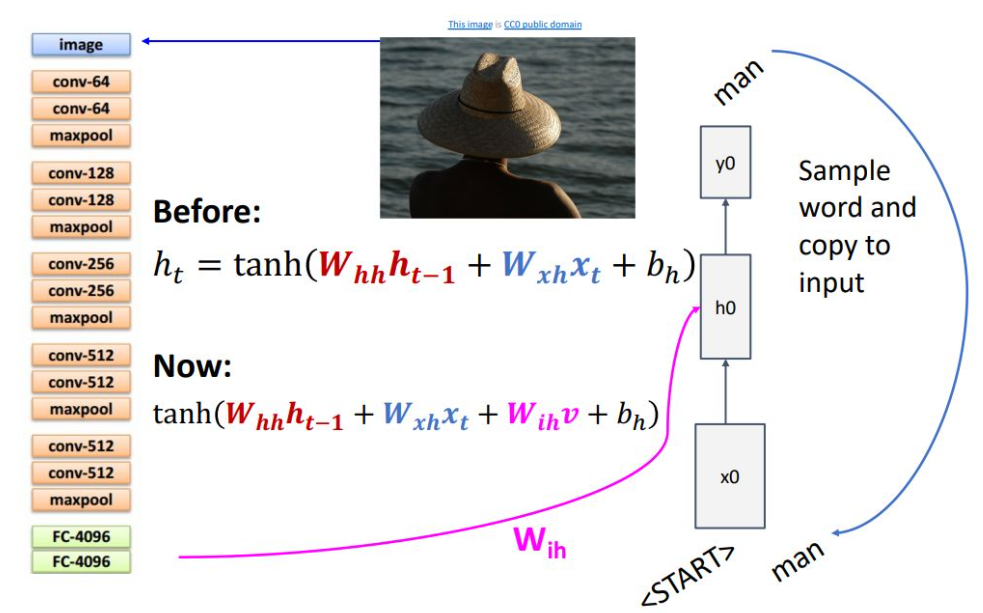
CNN과 RNN을 연결하기 위해 ht연산을 다음과 같이 변환함
-> 기존 input x와 previous state 연산 식에서 추가로 WihV텀이 추가가 되었는데, CNN 출력 feature V에 대해 linear transform을 시켜 더해주는 것임
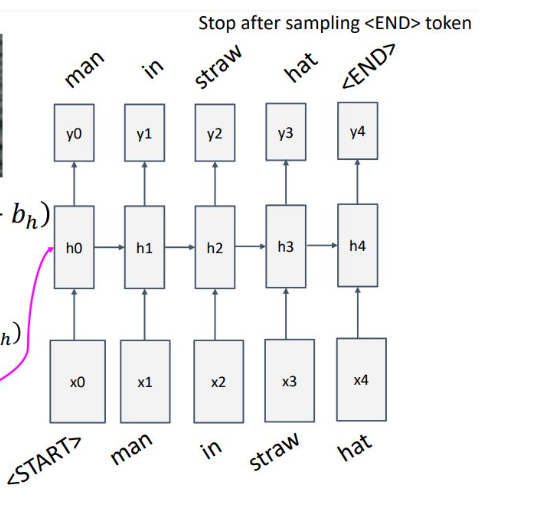
Start 토큰으로 시작해서, next 토큰을 예측 하다가 end 토큰을 출력하면 model이 sampling을 끝냄

다음과 같이 예측이 성공하기도 하고, 실패도 함
Vanilla RNN Gradient Flow
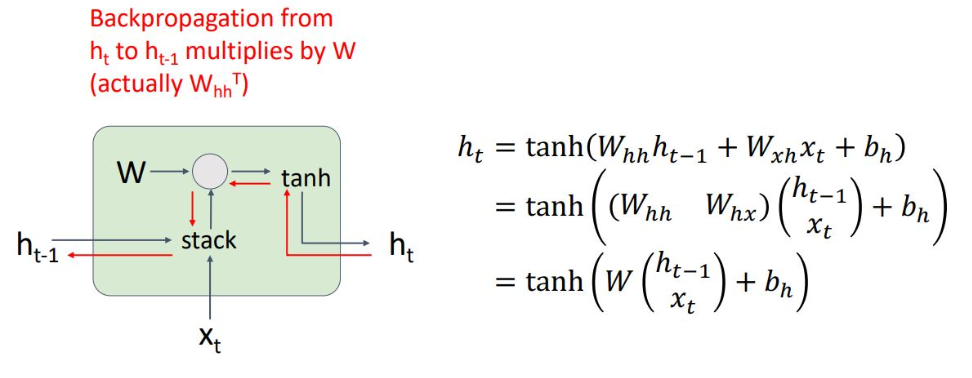
Vanilla RNN에서는 ht-1의 gradient를 구하려면, ht의 loss로 부터 backprop을 통해 gradient를 구해야 하고 2가지의 문제점
1. tanh의 non-linearity가 좋지 않음
(vanilla RNN가 옛날에 나옴)
2. backprop시 매번 W를 곱해줘야 함
직관적으로 singular scala 값이라고 생각한다면, 거듭제곱 형식이므로 W가 1 이상이면 발산, 1 이하면 0으로 수렴하게 될 것임.
1이상이면, exploding gradient가 발생하는데 이를 해결하기 위해 clipping을 통해 해결
1이하면, vanishing gradient가 발생하는데 이를 해결하려면 아키텍처를 바꿔야 함
LSTM
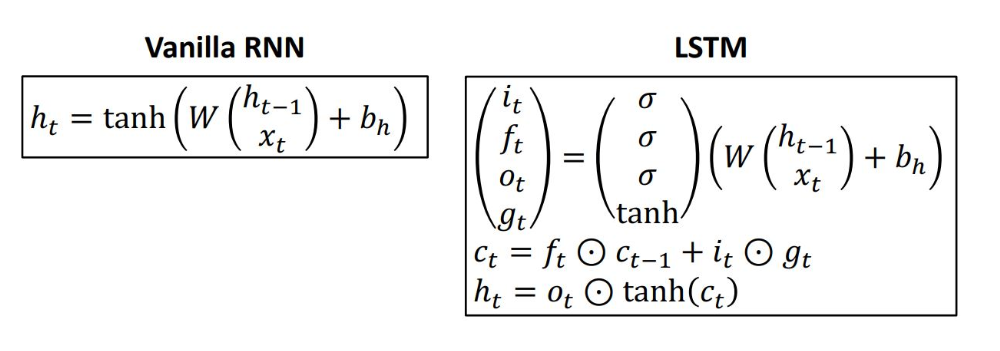
이런 vanilla RNN을 대신해 보통 LSTM이 많이 사용됨
매 step마다 single hidden state vector를 기억하는 것이 아닌,
ct(cell state)와 ht(hidden state)의 2개의 state vector를 기억하게 됨
ht-1과 xt를 통해 4개의 gate values를 계산하여 이를 통해 ct와 ht를 구하게 됨

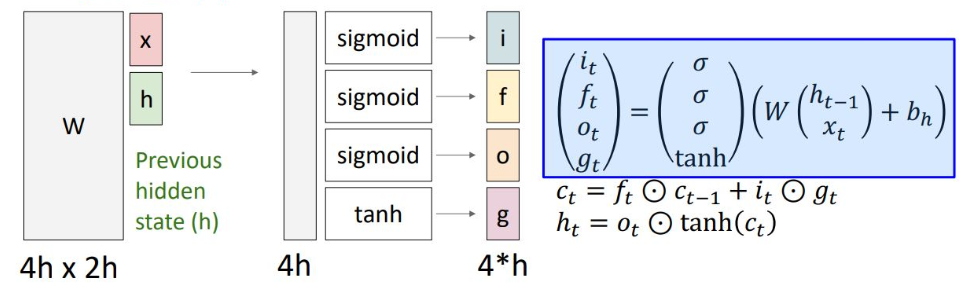
Input gate는 g를 얼마나 input으로 내보낼 지
Forget gate는 이전 cell state를 얼마나 잊어버릴 지
Output gate는 cell state를 얼마나 나타낼 지
Gate gate는 얼마나 cell state를 wirte 할 지
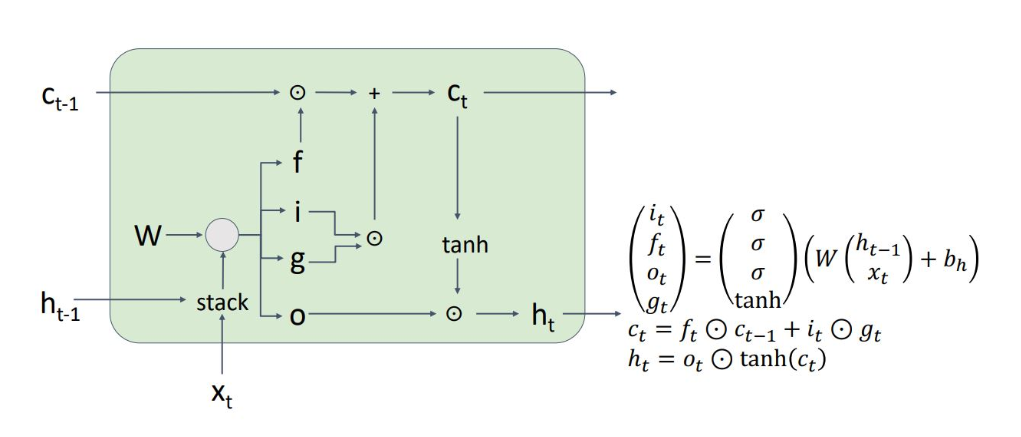
Ct에서 Ct-1로의 과정에서 f 연산이 되는데, W의 거듭제곱 형태가 없음
f는 0~1값을 가지는데, 1이면 온전한 값을 전파하며, 0이면 없앤다는 의미임.
또한 f gate를 통한 값이 0에 가까우면 gradient가 vanishing되긴 하지만, non-linearity가 아니므로 vanishing 문제는 아님
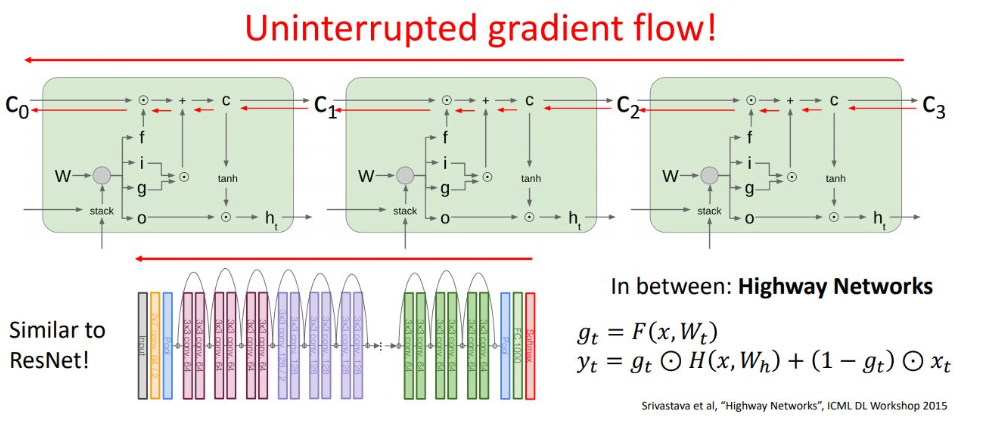
결국 cell state의 도입을 통해 RNN에서는 gradient의 backprop 과정에서 어떤 non-linearty를 추가하지도 않고, W의 거듭제곱 term도 없어짐. ResNet의 shortcut과 유사한 형태로 direct propagate 하는 것을 보장하기 때문에 Long-Term dependency 문제를 해결
이 외에도 Multi-layer RNN, GRU(gated recurrent unit) 등 다양한 model이 있음
SUMMARY

RNN은 feed forward 네트워크에서 벗어나 여러 유연한 아키텍처 적용
Vanilla RNN 은 심플 but 작동이 원활하지 않음
Gradient flow의 방해를 받지 않는 LSTM과 GRU를 주로 사용함
