NVMe-CR: A Scalable Ephemeral Storage Runtime for Checkpoint/Restart with NVMe-over-Fabrics
Paper Review
Introduction
Enormous compute power를 자랑하는 exascale system은 잦은 system failure로 인해 내부 상태(Internal state)를 persistent storage에 저장하는 checkpoint policy를 통해 unavoidable failure으로 부터 application을 보호한다. 하지만 checkpoint policy는 checkpointing의 overhead에 의해 system의 전반적인 성능이 저하된다는 문제점을 동반한다.
현재 HPC syste에서 사용되고 있는 Parallel File System(PFS)은 highly concurrent하고 ephemeral data를 관리하는 checkpoint policy를 뒷받침하기에는 역부족이다. 그 이유는 두가지로 생각할 수 있다. 첫번째 이유는, storage system이 여러 layer로 이루어진 POSIX File System 아래에서 동작하기 때문에, bandwidth가 낮다는 것이다. 두번째 이유는, 이러한 File System은 high concurrency 환경에서 POSIX의 atomic operation의 특성으로 인해 많은 overhead를 동반하는 것이다. 따라서 현재 HPC 환경에서 사용되는 PFS는 checkpoint policy를 뒷받침하기에는 적합하지 않다.
Background and Related Work
NVMf-based Stroage and Application-Level Checkpointing
스케일 아웃 시스템은 컴퓨팅, 메모리, 스토리지의 확장을 지원한다. 그리고 확장이라는 독립적인 문제를 해결하기 위해서는 시스템의 컴퓨팅, 메모리, 스토리지를 네트위크를 통해 분리해야한다. 동시에 최적의 성능을 보장하려면 네트워크는 네트워크 홉이나 프로토콜 지연과 같은 overhead 없이도 민첩해야한다.
NVME-of (NVMe over Fabrics)란, NVMe 네트워크 프로토콜을 내부의 PCLe 통신으로 부터 이더넷과 파이버 채널로 확장한 것으로, 서버와 스토리지 간의 더욱 빠르고 효율적인 연결을 제공함과 동시에 어플리케이션 호스트 서버의 CPU사용률을 절감시키는 기술이다. 아래 그림은 application이 NVMf를 통해 remote SSD device에 kernel based로 접근하는 방식을 나타낸 것이다.
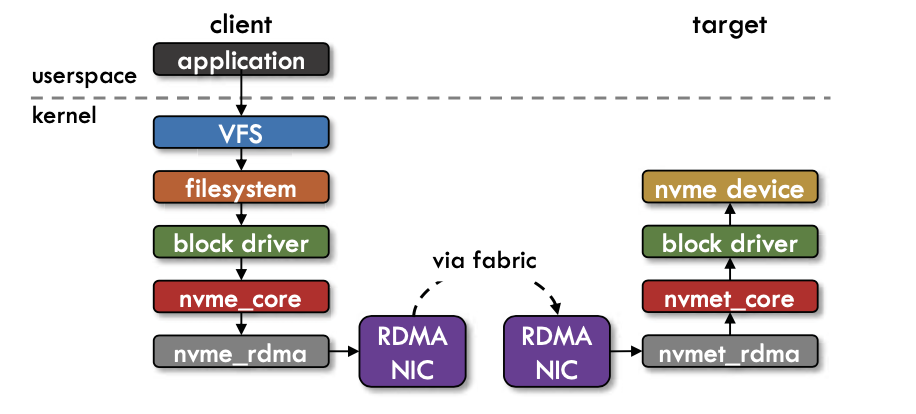
NVMe-of의 빠르고 효율적인 연결을 제공하는 특성으로 인해, application-level checkpointing은 checkpoint overhead를 줄일 수 있다. 하지만 NVMe-of의 장점을 완전하게 이용하기 위해서는 operation 수행을 kernel을 거쳐서 하는 방식(OS trap)이 아닌 storage access에 필요한 unprivileged usrspace를 제공하는 방식을 고려해야한다.
Related Work
Application Overhead를 줄이기 위한 연구가 지속적으로 진행되어 왔다. 다양한 연구들이 checkpoint overhead를 줄이는 것에 기여를 한것에도 불구하고, 이 전의 연구들은 두가지의 한계에 붙딪히게 되었다. 첫번재로는, device 위에 올려져있는 filesystem이 POSIX filesystem 이라는 것이다. 두번째는, metadata operation의 serialization 과정에서 발생하는 overhead와 client간의 synchronization에서 발생하는 overhead가 I/O bandwidth를 fully-utilized 못하게 한다.
NVMe-CR Design
A. The microFS Abstraction
해당 paper에서는 micro filesystem을 도입하였고, 이는 ephemeral distributed filesystem의 powerful design template이다. MicroFS는 kernel filesystem과는 다르게 불필요한 software layer를 거치지 않고 application으로 하여금 storage device에 direct하게 접근을 하도록 한다. 즉 모든 opertaion마다 운영체제에 trap 되는 것이 아닌 kernel virtual filesystem 과 block driver를 우회(bypass)하는 정책을 사용한다. 또한 microFS는 각 application process마다 namespace를 할당하여 shared namespace를 사용했을 때의 synchronization overhead를 최소화 하는 정책을 사용한다. 이러한 디자인을 위해서 사용해야할 정책은 다음과 같다.
Principle 1: Direct userspace access to storage device
Unprivileged userspace가 device에 access 하도록, microFS는 vfio kernel module를 사용한다. I/O operation은 memory mapped I/O를 사용하여 userspace에서 DMA operation을 통하여 수행되게 된다.
Principle 2: Maintaining storage device integrity
Storage device는 여러개의 microFS instance에 의해 공유된다. 따라서 storage device의 logical, physical partitioning에 의해서 instance간의 integrity가 관리된다. Partition은 group communicator이 생성되는 초기화 된계에 형성이 되고, partition 작업이 완료되고 나면 각각의 runtime instance는 자신에게 할당된 공간만을 사용하게 되고, 이러한 이유로 인해 각 instance간의 coordination과정이 생략된다.
Principle 3: Synchronization-free control and data plans
Data plane은 분리된 hardware I/O queue로 관리를 함으로써, synchronization-free하게 관리되게 된다. 각각의 instance마다 하나의 I/O queue를 부여하는 것은 현재의 storage device의 기술로는 가능하며, 가령 Intel Optane P4800X SSD의 경우에는 32개의 hardware queue를 지원한다. 따라서, data plane에서 parallel I/O를 지원할 수 있다. 또한 control plane같은 경우에는 앞서 언급했듯이 inter-microFS coordination이 없기 때문에 synchronization을 요구하지 않는다.
Princple 4: Data and metadata durability
기존의 file system은 OS-level cache와 journaling 기법을 사용해서 data와 metadata의 durability를 유지한다. microFS에서는 기존의 FS와 는 다르게, data를 device-level RAM에 direct하게 write해서 durability를 유지하고, metadata의 경우에는 lightweight operation logging을 통하여 durability를 유지한다. 또한 runtime instance는 internal microFS의 상태를 확인하여 log의 크기가 무한정 늘어나지 않도록 검사한다.
Architecture
NVMe-CR은 NVMf protocol을 사용ㅇ해서 scalable C/R을 받쳐주기 위해 설계된 storage runtime이다. NMVe-CR은 microFS 위에 설계되었으며, 이는 I/O의 low latency를 위해 만들어졌다. NVMe-CR runtime은 아래 그림과 같이 각 runtime에 할당된 storage 영역에 NVMf를 통해 접근한다. 각 runtime의 구성요소는 control plane, data plane 그리고 storage balancer로 이루어져 있다.
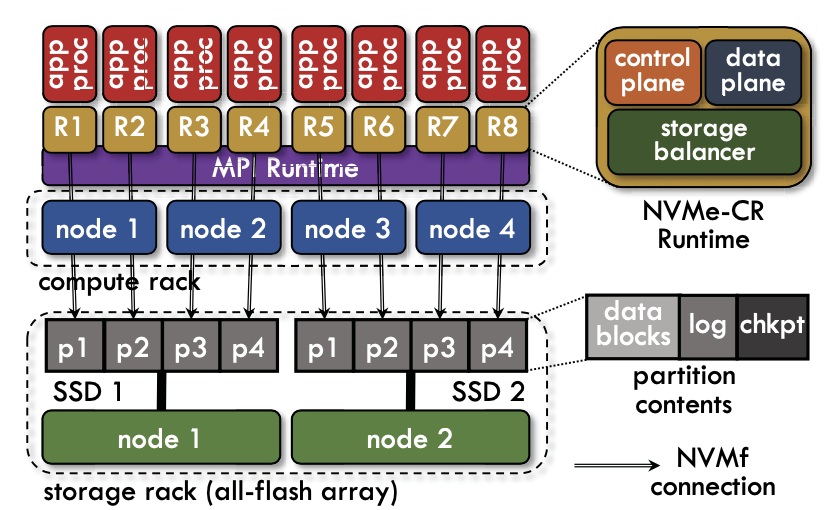
Application Obliviousness
Application modification을 하지 않고, storage runtime의 향상을 위한 방법으로 GNU ld linker에서 제공하는 symbol interception을 사용한다. 이를 통해서 standard POSIX I/O library calls를 intercept하고 NVMe-CR runtime에 rediction 해준다. 또한 MPI_Init, MPI_Finalize와 같은 calls도 intercept하여, runtime의 initialization과정과 finalization과정 모두 userspace의 wrapper에서 관리한다. MPI runtime을 관리하는 과정에서 instance간의 identification 작업을 위해 초기화 단계에서 instance간 coordination이 일어나고, control plane과 data plane은 instance 간 synchronization이 불필요하다.
Data Storage using NVMf - Data Plane
Userspace에서 remote SSD로 접근하기 위해 NVMf는 SPDK library를 사용한다. Storage Performance Development Kit (SPDK) 는 고성능, 고확장성의 유저 스페이스 애플리케이션을 구현하기 위한 다양한 툴과 라이브러리들을 제공한다. 또한 NVMf server는 multi-tenant하기 때문에 각 storge node에 SPDK NVMf server가 daemon으로 돌아가고 있다. 따라서 data plane operation은 SPDK NVMf request형태로 translate되어야 하고 NVMe-CR runtime가 관리한다.
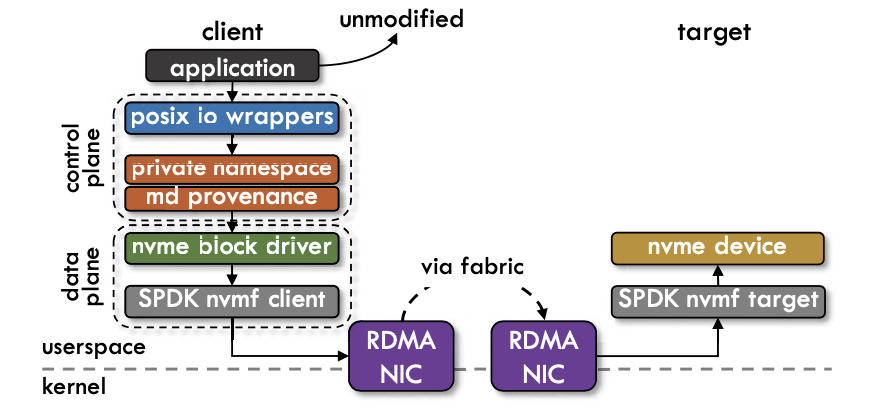
Metadata Management - Control Plane
Control plane은 metadata를 관리하는 것에 목적을 둔다. Control plane의 주 목적은 distributed synchronization을 제거하는 것이다. NVMe-CR의 control plane design은 몇가지 이점을 가진다. 첫째로, 각 runtime의 control plane은 private namespace에만 노출이 되게 되어서 metadata operation에서 다른 process간의 coordinate는 불필요로 한다. 따라서 global namespace를 사용하여 각 process에서 처리해야하는 lock bus message 처리를 요하는 다른 distributed system에 비해 overhead가 없다. 두번째로, metadata는 DRAM에서 관리하고 persistency를 위해 lightweight logging operation으로 관리하게 된다. 따라서 compact log records를 읽고 쓰는 network I/O만 발생하게 된다.
Load-aware I/O -Storage Balancer
Storage balacer는 job에 대한 Storage node 할당과 사용 가능한 스토리지 장치간 I/O load balancing을 담당한다. NVMe-CR은 remote SSD간에 데이터를 배포하는 동안 load balancing과 fault-tolerance의 두가지 중요한 요소를 고려한다. Load balancing은 사용가능한 I/O bandwidth를 활용하고 모든 프로세스가 bandwidth를 균등하게 분배하도록 하는 것에 중요한 역할을 한다. Fault-tolerance는 chekcpoint 데이터를 프로세스가 존재하는 domain과 다른 domain에 배치해야 하는 중요한 요소이다. 그렇지 않으면 프로세스의 실패가 체크포인트 데이터 손실을 유발할 수 있다. 따라서 이 두가지 요소 모두를 고려하기 위해서 NVMe-CR은 새로운 data distribution algoritm을 사용한다.
첫번째 방법은 network topology를 사용하여 각 노드의 failure domain을 식별한다. 하드웨어를 공유하는 노드는 동일한 도메인에 배치된다. 예를 들어, rack 내의 모든 노드와 power를 공유하는 모든 노드는 동일한 domain에 배치한다. 다음으로 두 partner node가 별도의 failure domain에 있도록 partner failure domain을 만든다. 각 failure domain에 대해 partner domain간의 스위치 홉 수를 기준으로 정렬된 partner domain의 목록을 만든다. 마지막으로 각 failure domain이 partner이고 각 스토리지 노드의 load가 가능한 동일하도록 프로세스와 스토리지 노드의 매핑을 생성한다. 매핑을 구성하는 알고리즘은 communication cost를 최소화 하는 greedy algorithm을 사용하여 구성한다. 스토리지 장치는 사용가능한 가장 가까운 partner domain에 할당한다.
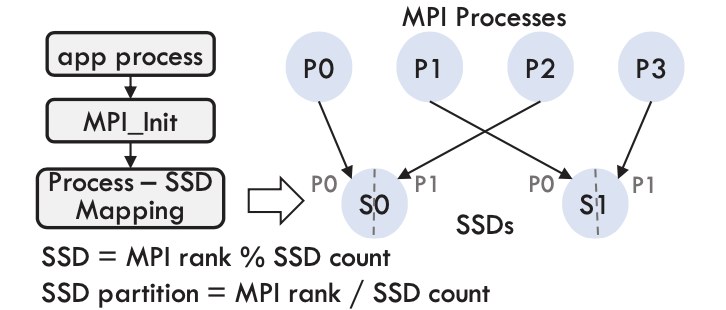
Job 내부의 프로세스는 load balancing을 달성하기 위해서 round-robin 방식으로 할당된 SSD에 할당된다. 이 mapping이 만들어지고 나면, 모든 프로세스에 대해 MPI_COMM_CR이라는 MPI Communication을 생성한다. 그런 다음 SSD는 연결된 Communicator process간에 분할된다. 각 프로세스는 순위와 communicator 크기에 따라 SSD의 연속적인 세그먼트를 얻는다. 아래 그림은 사용가능한 스토리지가 어떻게 분할되고 MPI 프로세스에 할당되는지 보여주는 그림이다.
Unknown Concepts
NVMe-over-Fabrics (NVMf) standard
NVMe-over-Fabrics (NVMf) standard is an extension of the NVMe standard to allow remote access to SSDs using fast RDMA-enabled networks
Checkpoint/Restart
In terms of file transfer, checkpoint restart means that a file transmission that has been interrupted due to an Internet connection or computer failure will automatically pick up where it left off when the system is back online, rather than having to start over.
MicroFS
Template for coordination-free filesystems. And MicroFS abstraction is most related to the design of DeltaFS. DeltaFS does not expose one single namespace, but a collection of snapshots that can be used by applications to construct their own namespace view. This provides the ability to execute large numbers of parallel metadata operations with minimal coordination.
MicroFS is designed to peel off the unnecessary software layers that hinder performance and allow applications to directly access storage devices.
POSIX Semantics
By using SPDK for remote I/O, we can indeed bypass the kernel, but need to provide a POSIX filesystem like interface to applications. NVMe-CR implements wrappers for commonly used POSIX I/O syscalls.
