Introduction
Persistent memory는 byte addressable하고 non-volatile한 특성을 지니고 있어서, PCI interface를 사용하지 않고 memory bus를 통해서 접근이 가능하다. 그리고 failure atomicity unit은 8 bytes보다 작거나 cache line의 작거나 같다는 특성을 지니고 있다.
하지만 failure atomicity unit의 크기가 작을 수록, consistency를 위한 overhead가 크다는 단점을 지니고 있다. 현대의 processors은, 메모리 쓰기 과정에서 reorder하는 과정을 요구하게 되고, 그로 인해 memory fence와 cache line flush instruction을 요한다. 이 두가지 instruction은 성능 저하에 주요 원인으로 자리 잡고 있다. 또한 failure-atomic write unit보다 큰 data가 write되어야 한다면, logging이나 copy-on-write(CoW) 메커니즘이 consistency를 위해 존재해야 한다.
Memory barrier (Memory Fence) : Memory barrier는 CPU나 Complier에게 barrier 명령문 전 후 의 메모리 연산을 순서에 맞게 강제하는 기능이다. 즉, barrier 이전에 나온 연산들이 barrier 이후에 나온 연산보다 먼저 실행이 되는게 보장되어야 하는 것이다 (MultiCore Synchronization 에서 필요한 기능)
Background and Motivation
Consistency in Persistent Memory
Persistent indexing structure에서 recovery correctess를 보장하기 위해서는 추가적인 memory write ordering 제약이 필요하다. Disk-based indexing에서는 DRAM에서의 임의적인 변화는 disk에 persist하게 저장이 되어있는 data에는 영향을 주지 않는다. 하지만 8bytes의 failure-atomic write granularity를 보장하는 persistent memory의 경우에는 변경사항의 순서를 보장하는 것이 중요하다. 예를들어서, node의 entry 수 를 증가시키는 operation은 new entry가 저장이 되고 난 후에 이루어져야 하는 operation이다. 그렇지 않으면, entry수가 증가한 후 system failure가 발생하게 된다면, new entry가 저장이 되지 않은채 빈공간의 entry로 낭비되는 경우가 발생한다(garbage entry).따라서 volatile CPU caches와 non-volatile memory의 consistency를 보장하기 위해서는, memory fence 와 cache line flush instruction을 통해서 memory write의 순서를 지켜줘야 한다. 하지만 memory barrier instruction과 cache line flush instruction은 expensive하다는 단점이 있다.
Consistency를 보장하기 위해 필요한 또 다른 관점은 write size이다. Write size가 failure-atomic write unit보다 큰 data가 write되어야 한다면, logging이나 copy-on-write(CoW) 메커니즘을 필요로 한다. B-Tree의 관점에서 본다면, insertion 또는 deletion 연산으로 인해 tree내부에서 많은 변화가 생기기 때문에, 이러한 경우 앞에서 언급한 것과 같이 추가적인 매커니즘을 필요로 한다. 하지만 logging이나 CoW 매커니즘은 update하는 데이터의 양이 많을 수록 성능 저하를 유발하는데, 이는 write amplification에 의한 성능 저하이다.
Radix Tree for Persistent Memory
Radix Tree
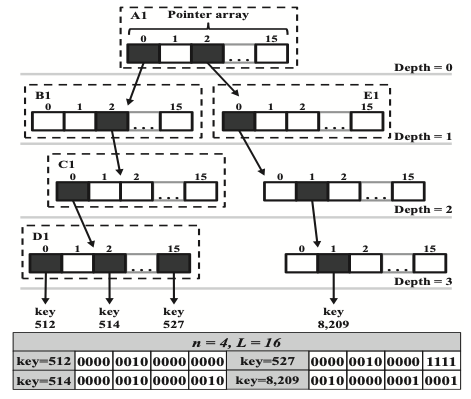
Radix Tree는 B-Tree varient와 달리 하나의 노드에 하나의 키를 저장하는 방식이 아니라, 각각의 노드는 Hash-based index와 유사하게 search key의 bit chunck로 표시된다. 아래 그림의 radix tree의 각 키는 16bits로 구성되며, 하나의 노드에서는 4bit chunck를 가지게 된다. 그리고 root node에서 시작하여 각 키의 최상위 4bits는 포인터 배열 내부에서 entry를 결정하는데 사용된다. Radix tree의 기본적인 구조와 검색 알고리즘은 생략하도록 하겠다.
Failure Atomic Write in Radix Tree
Radix Tree는 insert 혹은 delete 연산에 의해 tree structure의 구조가 많이 변경(modification)되는 B-Tree variant와는 다르게 두가지 간단한 변경(modification)에 의해 consistency를 유지할수 있다.
첫번째 modification은, leaf node에 가까운 node의 pointer 변경 작업을 우선으로 하고, root node에 가까운 node의 pointer 변경 작업을 후 순위로 한다. 그렇게 함으로써 system failure가 발생했을 때 garbage entry가 생기는 것을 방지할 수 있다. 또한 radix tree는 오직 8bytes pointer variable만 변경을 하므로, logging 이나 CoW 매커니즘을 필요로 하지 않는다.
두번째 modification은, failure atomicity를 보장하기 위해 몇가지 memory access serialization을 수행해야 한다. 예를 들면, 모든 노드들이 leaf node를 가르키도록 memory fence 와 cache line flush operation을 수행해야 한다. 따라서 모든 modification이 memory내부에 persistent 하게 유지된다.
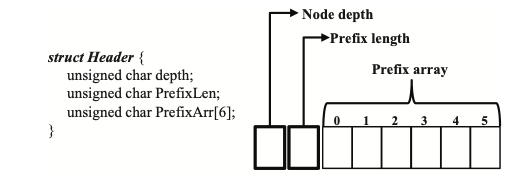
또한, compression header를 두어, sparse data workload에서 발생할 수 있는 memory space uttilization problem을 해결하고 search path를 단축시켜 indexing performnace를 향상시킨다. 또한 compression header의 크기를 8bytes로 유지해, failure-atomic size에 맞췄다.