Original Paper (Arxiv) : BERT (https://arxiv.org/pdf/1810.04805)
📥Background
1. ELMo (Embeddings from Language Model)
(1) biLM(Birdirectional Language Model)의 사전 훈련
ELMo는 문맥을 반영한 워드 임베딩을 위해 순방향 언어 모델과 역방향 언어 모델 2개를 학습한다.
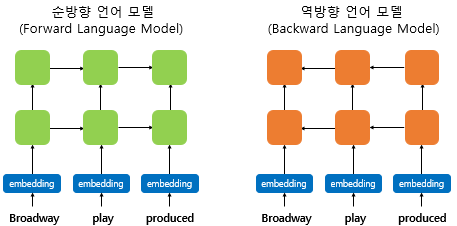
[그림1] biLM 구조 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 9장 [https://wikidocs.net/33930])
⚠️주의할 점 : 양방향 RNN과 biLM은 다르다!
- 양방향 RNN : 순방향 RNN과 역방향 RNN의 은닉 상태를 연결하여 다음층의 입력으로 사용
- biLM : 순방향 언어 모델 & 역방향 언어 모델, 2개 모델을 별개의 모델로 간주하여 학습 진행
즉, 양방향 RNN은 하나의 모델에서 2개의 방향성을 띄는 것이고, biLM은 하나의 모델에서 하나의 방향성(순/역)만 갖는 것이다.
(2) 학습 과정 - ELMo 표현 도출
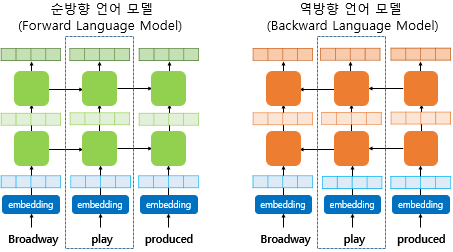
[그림2] biLM 학습 과정_"play" 임베딩 중 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 9장 [https://wikidocs.net/33930])
① 각 층의 출력값을 연결
[그림2]에서 점선의 사각형 내부의 각 층의 결과값을 연결한다. ("순방향 - 역방향"을 하나의 쌍으로)
② 각 층의 출력값에 대하여 가중합
각 층의 출력값에 가중치를 부여한 후 모두 벡터를 모두 더한다. 이때 는 모두 학습 가능한 스칼라이고 softmax를 통과한 값이다.
③ 벡터에 스칼라 매개변수 곱하기
도 학습 가능 한 스칼라이다.
전체 수식 :
(3) 태스크에 적용
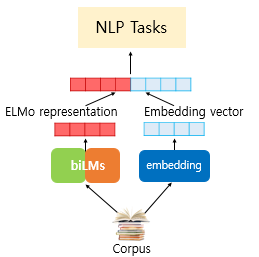
[그림3] ELMo를 NLP 태스크에 적용하는 과정 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 9장 [https://wikidocs.net/33930])
GloVe와 같은 기존의 임베딩 방법을 사용한 임베딩 벡터를 ELMo 표현에 연결하여 NLP 태스크의 입력으로 사용한다. 이때, biLM 모델 내부 셀의 가중치는 고정되어 있고, 는 훈련 과정에서 학습된다.
2. GPT-1
GPT-1 정리 글 참고
https://velog.io/@angel5893/GPT-1-Improving-Language-Understandingby-Generative-Pre-Training-2018
unlabled text로 pre-train 한 후, 각 태스크에 대해서 fine-tuning하는 방식이다. 비지도 사전훈련 모델은 Transformer의 decoder 부분만 따온 형태로, Text & Position Embed, Masked Multi Self Attention, Residual Connection, Layer Norm, Feed Forward로 이루어져 있다.
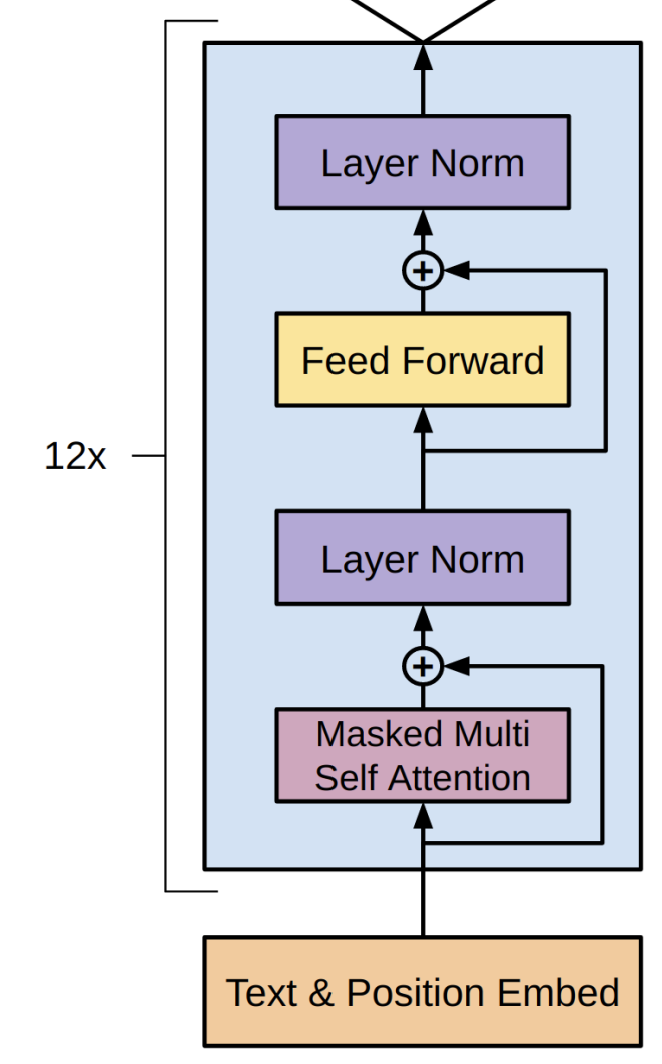
[그림4] GPT-1 unsupervised pre-training 구조 (출처 : 논문 발췌)
① 토큰 & 위치 임베딩
② Masked Multi Self Attention : attention score 계산 시, 상삼각 행렬을 활용하여 masking 진행
③ Residual Connection & Layer Norm : Post LN 2번
④ Feed Forward : Linear와 ReLU를 통한 비선형성 추가
이렇게 사전학슴한 모델에 각 태스크를 입력으로 준 후, 마지막 Tranformer 블록의 토큰을 새롭게 추가한 선형 분류기에 넣음으로써 예측 확률을 계산한다.
📄Paper Review
0. Abstract
최근 언어 모델들과 다르게 BERT는 깊은 양방향 표현을 학습하여 오직 하나의 추가 출력층만으로도 fine-tuning 되며, 그 결과 다양한 태스크에 대하여 SOTA를 달성하였다.
BERT는 개념적으로는 간단하지만, 실질적으로는 강력한 모델로 아래 과제를 포함한 11개 분야에서 새로운 SOTA가 될 수 있었다.
- GLUE: 80.5% (7.7%p 향상)
- MultiNLI 정확도: 86.7% (4.6% 향상)
- SQuAD v1.1: 93.2 (1.5 향상)
- SQuAD v2.0: 93.1 (5.1 향상)
1. Introduction
기존 모델
언어 모델의 사전학습은 자연어 추론, QA 등 다양한 자연어처리 태스크에서 성능 향상에 큰 효과를 보여주었다. 사전학습된 언어 표현을 과제에 적용하는 데에는 다음 2가지 전략이 있다.
(1) feature-based
사전학습 표현을 추가 feature로 활용하되, 과제에 맞는 별도의 아키텍처가 필요한 방법으로 ELMo가 가장 대표적인 예시이다.
(2) fine-tuning
고정된 표현이 아니라 사전학습 모델 전체를 다운스트림 과제에 맞춰 재학습하는 방식으로 GPT-1에서 하나의 층만 추가한 것처럼, 최소한의 추가 구조만 도입한다.
❗현재의 단방향 모델은 사전학습에 사용될 수 있는 구조의 선택을 한정시킨다.
예를 들어, GPT-1을 보면 모델이 왼쪽에서 오른쪽으로만 정보를 처리하는 구조로, 각 self-attention에서 각 토큰이 오직 이전 토큰들만 참고할 수 있다는 문제점이 있다.
→ 문장 수준 과제에 대해 최적이 아니다.
→ QA와 같이 토큰 수준의 과제에서는 양방향 문맥을 활용하는 것이 매우 중요하기 때문에 매우 치명적일 수 있다.
BERT 모델
본 논문의 BERT는 masked language model (MLM) 사전학습 목표를 활용하여 단방향성 제약을 경감한다.
MLM으로 입력의 토큰에서 몇 개를 랜덤으로 마스킹한 후, 문맥에 기반하여 마스킹된 단어의 원본 id를 예측한다. MLM 목적함수는 좌측과 우측 문맥을 융합하여 표현을 만들 수 있게 하며, 이를 통해 깊은 양방향 Transofrmer를 사전학습할 수 있게 된다.
더불어, text쌍으로 사전학습하는 next sentence prediction (NSP) 태스크도 활용하였다.
BERT 모델의 기여
- 언어표현에 있어 양방향 사전학습의 중요성을 증명함.
- BERT는 문장 수준 및 토큰 수준의 다양한 NLP 과제에서 SOTA를 기록한 첫번째 fine-tuning 기반 모델임.
- NLP 11개 태스크에서 SOTA 기록.
2. Related Work
2.1 Unsupervised Feature-based Approaches
(1) 단어 수준 표현 학습
Word2Vec, GloVe와 같은 사전학습된 임베딩은 초기화 없이 학습한 임베딩보다 훨씬 뛰어난 성능 제공한다. 대표적인 학습 목표는 좌→우 언어 모델링, 올바른 단어 vs 틀린 단어 구별 등이 있다.
(2) 문장/문단 수준 확장
이후 문장 및 문단 수준의 학습으로 확장되었는데, 문장 표현을 학습하기 위해서 다음 문장 순위 매기기, 다음 문장 단어 생성과 같은 목적함수가 사용되었다.
(3) ELMo: 문맥 기반 단어 표현
LSTM 기반 양방향 언어 모델에서 좌→우 및 우→좌 2개 방향에 대하여 문맥적 특징 추출한다. 두 방향의 표현을 연결해서 출력을 구성하였고 그 결과, QA, 감정 분석, 개체명 인식 등 다양한 과제에서 SOTA를 달성했다.
2.2 Unsupervised Fine-tuning Approaches
초기에는 단어 임베딩만 사전학습하였는데, 최근에는 문장/문서 수준 인코더 사전학습 후 전체 모델 fine-tuning하는 방식으로 연구가 진행되고 있다.
GPT-1처럼 새로 학습할 파라미터 수가 적다는 점에서 학습 효율 향상된다는 장점이 있다. GPT-1는 GLUE 벤치마크의 여러 문장 수준 과제에서 SOTA 달성했다.
2.3 Transfer Learning from Supervised Data
대규모 지도 학습 데이터에서 전이 학습하는 시도도 있었다. - 자연어 추론(NLI) 기반 전이, 기계 번역 기반 표현 활용
| 접근 방식 | 설명 | 대표 모델 |
|---|---|---|
| Feature-based | 사전학습 표현을 고정된 feature로 사용 | ELMo |
| Fine-tuning | 사전학습 모델 전체를 다운스트림 task에 맞춰 조정 | GPT, ULMFiT |
| Supervised Transfer | 대규모 지도 학습 데이터 기반 전이 | InferSent, McCann |
💡 BERT는 사전학습에서 양방향 문맥 학습 (MLM) + 파인튜닝 기반 전이 학습!
3. BERT
(1) Model Architecture
양방향 Transformer encoder를 여러 층 쌓은 형태로, 원본 Transformer과 구조가 거의 동일하다.
본 논문에서는 사이즈가 서로 다른 2개의 모델을 사용했다.
- : 12개층, 은닉층 768개, self-attention head 개수 12개
- : 24개층, 은닉층 1024개, self-attention head 개수 16개
(*는 GPT-1과의 성능 비교를 위해 GPT-1과 같은 크기로 설정했다.)
(2) Input/Output Representations
- Token Enbedding : WordPiece 토큰화 (subword tokenizer)
실질적인 입력이 되는 워드 임베딩으로, 다음 경우에 따라 임베딩을 진행한다.
- 토큰이 단어 집합에 존재할 경우, 해당 토큰은 분리하지 않는다.
- 토큰이 단어 집합에 존재하지 않을 경우, 해당 토큰을 서브워드로 분리한 후, 단어의 중간부터 등장하는 서브워드라는 것을 알려주기 위해 단어 앞에 “##”을 추가한다.
OoV 문제 해결
e.g. "embeddings"
→ 단어 집합에 em, ##bed, ##ding, #s라는 서브 워드들이 존재
→ embeddings를 em, ##bed, ##ding, #s로 분리
- Segment Embedding : 두 개의 문장을 구분
BERT는 두 개의 문장을 한 번에 입력할 수 있도록 설계되어있기 때문에 두 문장을 구별하기 위해 다음 임베딩을 진행한다.[CLS] He went to school [SEP] He studied math [SEP]-
"He went to school" → Segment A
-
"He studied math" → Segment B
-
[CLS],[SEP]도 Segment A, B 중 하나로 처리됨.※
[CLS]토큰 : 분류 문제를 풀기 위한 특별한 토큰
※ 이때 단일 문장이 입력될 때에는 모든 토큰을 Segment A 처리한다.
-
- Position Embedding : 위치 정보를 학습
Transformer와 똑같이 순서를 고려하지 않기 때문에 위치 정보를 추가해야 한다. Transformer의 경우 사인/코사인 함수를 사용했지만, BERT에서는 학습 가능한 벡터로 설정하여 더 유연하게 활용할 수 있도록 한다.
3.1 Pre-training BERT
우리는 다음 2개의 비지도 task를 통해 사전학습했다.
Task #1: Masked LM
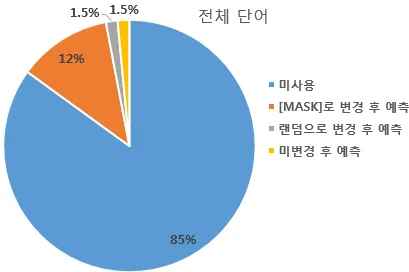
[그림5] MLM에서 마스킹되는 단어 비율 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 17장 https://wikidocs.net/115055)
1. Masking
입력 텍스트의 15%를 랜덤으로 마스킹하는데, 이는 양방향 학습에 있어 매우 중요한 기능이다. 랜덤으로 선택한 15% 단어에 대하여 다음과 같은 처리를 진행한다.
- 80% : [MASK]
- 10% : 랜덤으로 대체
- 10% : 미변경 (원래 단어 그대로)
해당 부분을 리딩하다가 다음 2개의 의문이 생겼다.
❓왜 15% 단어 모두를 masking 하지 않는가
사전 학습 단계에서 100% 마스킹을 하면, 파인 튜닝 시 [MASK]가 없는 환경과 불일치 문제가 발생한다. 그렇다고 [MASK]를 아예 없애면 모델이 단어를 복원하는 능력을 학습하지 못하는 문제가 발생한다.
⇒ 모델이 마스킹된 상황에서 학습하면서, 파인 튜닝 단계에서 불일치를 줄일 수 있도록 설계
❓10%를 변경하지 않을 거면 애초에 랜덤 선택하지 않았으면 되지 않는가?
모델이 "마스킹 자체"를 학습하는 것을 방지하기 위함으로 [그림6]을 보면 알겠지만, 이렇게 선택된 단어의 임베딩 벡터만 사용하여 예측이 진행된다.
⇒ 모델이 어떤 단어가 마스킹될지 예측할 수 없게 되므로, 더 강력한 일반화 학습이 가능
⇒ 마스킹된 단어뿐만 아니라 원본 단어도 학습하게 되어 문맥 이해력이 향상
2. 출력층
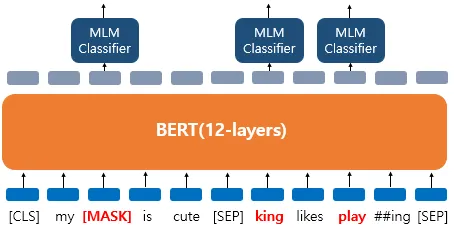
[그림6] Masking 후 출력되는 과정 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 17장 https://wikidocs.net/115055)
출력 시 사용되는 벡터는 랜덤하게 선택된 15%의 단어 벡터로 [그림6]에서는 다음과 같이 처리되었다. 이때 다른 토큰에 대한 예측은 무시한다.
- dog' 토큰 → [MASK]
- 'he' 토큰 → 'king'
- 'play' 토큰 → 변경X (그대로 'play')
- transofrmer self-attention를 통해 모든 단어에 대한 attention score 벡터 생성
- 마스킹 or 선택된 단어의 벡터만 dense + softmax layer로 넘기기
→ 앞서 언근한 바와 같이, attention score까지는 모든 단어가 계산되지만, 최종 예측에서는 마스킹된 단어의 벡터만 사용한다.
Task #2: Next Sentence Prediction (NSP)
다음에 올 문장을 예측하는 과정으로, 2개의 문장을 준 후에 서로 이어지는 문장인지 아닌지를 맞추는 방식이다. 훈련 과정은 다음과 같다.
- 실제 이어지는 2개의 문장 & 랜덤으로 이어붙인 2개의 문장 input


- segment embedding
[CLS] He went to school [SEP] He studied math [SEP]- "He went to school" → Segment A
- "He studied math" → Segment B
[CLS],[SEP]도 Segment A, B 중 하나로 처리됨.
- transformer encoder 통과
두 문장의 정보를 종합한 벡터를 계산한다.
- 앞서 Masked 벡터만 가져와서 softmax에 넣은 것처럼 [CLS] 벡터를 softmax에 넣어서 확률 출력
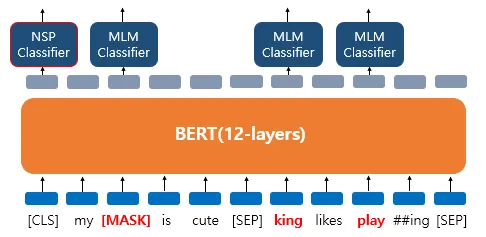
[그림7] NSP classifier (출처 : 딥러닝을 이용한 자연어 처리 입문 - 17장 https://wikidocs.net/115055)
- "YES" (1) → 문장 A와 B가 실제 연속된 문장
- "NO" (0) → 문장 A와 B가 랜덤하게 선택된 문장
- 손실함수 계산 및 학습
y_hat과 y를 비교하여 Cross-Entropy Loss 계산한다.
3.2 Fine-tuning BERT
사전학습 모델에 대하여 입력/출력만 교체하여 처리할 수 있기 때문에 fine-tuning은 비교적 간단하다. 과제의 유형에 따라 다음과 같이 처리된다.
-
토큰 수준 과제(token-level task)
→ 각 토큰의 출력 벡터를 출력층에 전달
→ 예: 질의응답, 시퀀스 태깅 -
문장 수준 과제(sentence-level task)
→ [CLS] 토큰의 출력 벡터를 출력층에 전달
→ 예: 감정 분석, 문장 분류, 함의 판별- 문장 쌍 → 패러프레이징
- 가설-전제 쌍 → 텍스트 함의(entailment)
- 질문-본문 쌍 → 질의응답(QA)
- 텍스트-빈문장 쌍 → 텍스트 분류나 시퀀스 태깅
4. Experiments
4.1 GLUE
- batch_size = 32
- epochs = 3
- learning rate = [5e-5, 4e-5, 3e-5, 2e-5] 중 가장 성능이 좋은 것으로 사용
- WNLI를 제외한 8개의 task에 대해 실험 진행
- 첫 번째 입력 토큰
[CLS]에 해당하는 최종 은닉 벡터(C)를 전체 문장을 대표하는 벡터로 사용 - 새롭게 추가된 파라미터 : classification task에서 레이블의 개수에 따른 가중치 (W)
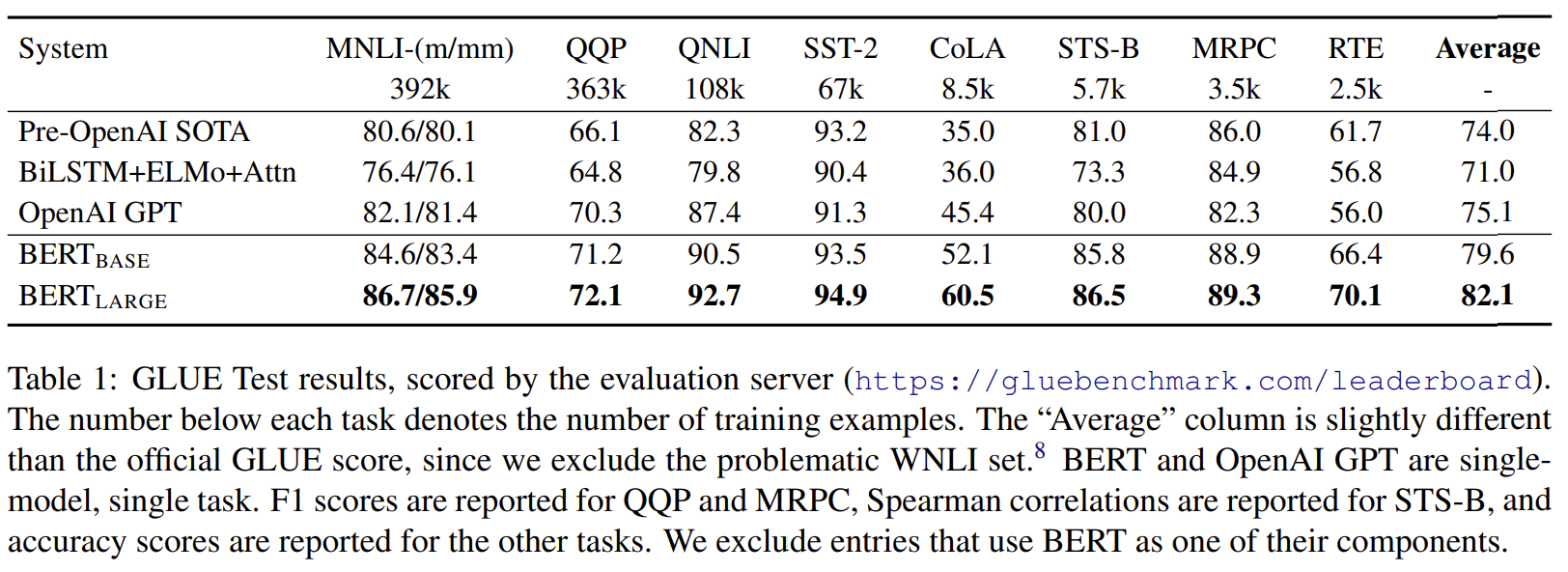
[그림8] GLUE 실험 결과 (출처 : 논문 발췌)
- BERT_BASE와 BERT_LARGE 둘 다 모든 task에서 기존 SOTA보다 좋은 성능을 보임 = New SOTA
(평균 정확도에서 각각 4.5%, 7% 향상을 보임) - 특히 BERT_LARGE가 80.5의 점수를 획득하며 72.8을 기록한 OpenAI GPT보다 좋은 성능을 보임
(※BERT_LARGE의 경우, 작은 데이터셋에서 fine-tuning이 불안정할 때가 있었음. 이에 몇 번의 random restart를 진행함)
4.2 SQuAD v1.1
SQuAD란?
- Stanford Question Answering Dataset의 약자로, 10만 개의 질문/답변 쌍으로 구성되어 있음
- 입력 : 주어진 질문 & 정답이 포함된 위키피디아 문단
- 출력 : 문단 내에서 정답이 포함된 텍스트(span)를 예측
- 질문 : segment A / 문단 : segment B
- 각 단어가 정답 텍스트의 시작 또는 끝이 될 확률 예측
- TriviaQA 활용
- 데이터 출처 : 위키백과 + 뉴스 기사
- 질문 유형 : 퀴즈 스타일의 질문
- 정답 찾는 방식 : 문서 여러 개에서 찾음 → 정답 범위 : 문장 전체
→ 정답 범위가 더 크고, 다양한 문서에서 답을 찾아야 하기 때문에 일반적인 QA task에서 더 강력한 모델을 만들 수 있음
→ TriviaQA로 먼저 학습한 후, SQuAD로 fine-tuning 진행
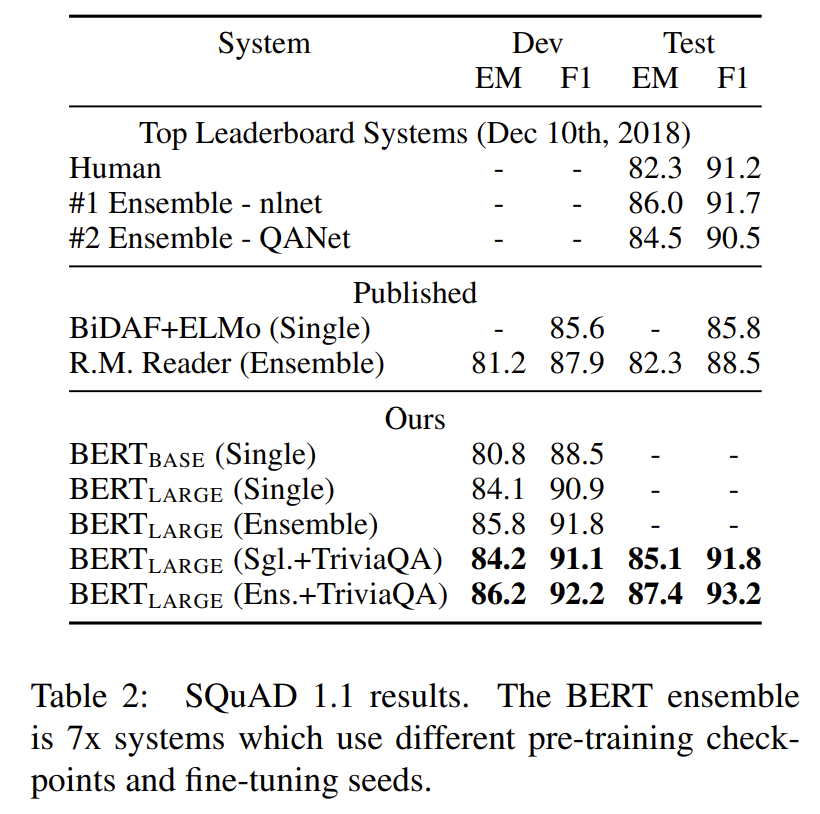
[그림9] SQuAD v1.1 (출처 : 논문 발췌)
- batch_size = 32
- epochs = 3
- learning rate = 5e-5
- 단일 모델로도 기존 리더보드 1위보다 1.3 높은 성능을 보임
- 앙상블 모델의 경우 1.5 높은 성능을 보임
4.3 SQuAD v2.0
SQuAD v2.0이란?
SQuAD v1.1의 확장된 버전으로 문단 내에 “짧은 정답”이 존재하지 않을 가능성을 두어 보다 현실적으로 문제를 정의함
- 정답이 없는 질문의 경우, [CLS] 토큰을 정답 위치로 설정
→ 시작/끝 위치 확률을 계산할 때, [CLS] 토큰도 고려하도록 확장
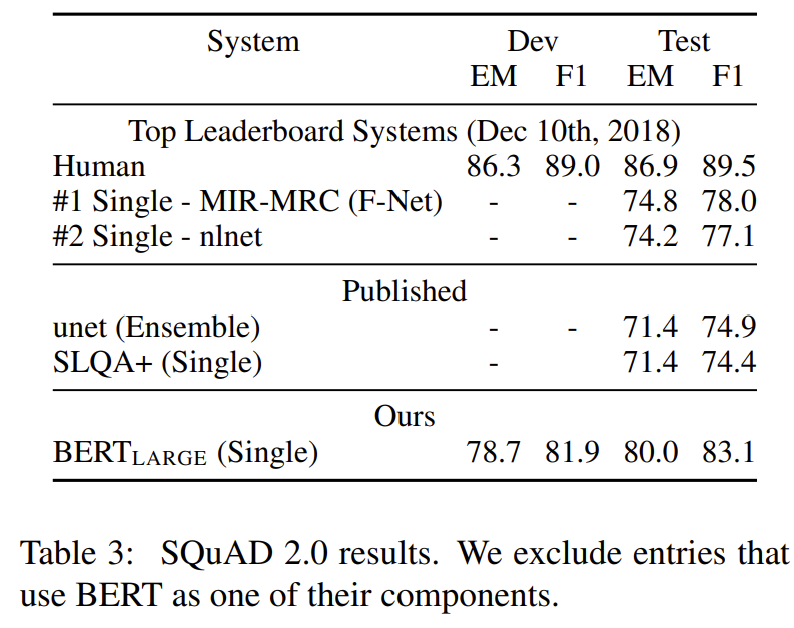
[그림10] SQuAD v2.0 (출처 : 논문 발췌)
- batch_size = 48
- epochs = 2
- learning rate = 5e-5
- TriviaQA 사용X
- F1 score 5.1 향상
4.3 SWAG
SWAG이란?
- Situations With Adversarial Generations의 약자로, 113,000개의 문장 완성 예제로 구성됨
- 입력 : 하나의 문장
- 출력 : 다음에 올 문장 4개 중 문맥 상 가장 적절한 문장 선택
각 입력 문장과 4개의 선택지를 조합하여 총 4개의 입력 시퀀스 생성
e.g. "남자가 손을 뻗어 문을 열었다." 뒤에 올 문장 선택
(A) 그는 방으로 들어갔다.
(B) 그는 갑자기 달리기 시작했다.
(C) 문이 저절로 닫혔다.
(D) 그는 조용히 노래를 부르기 시작했다.
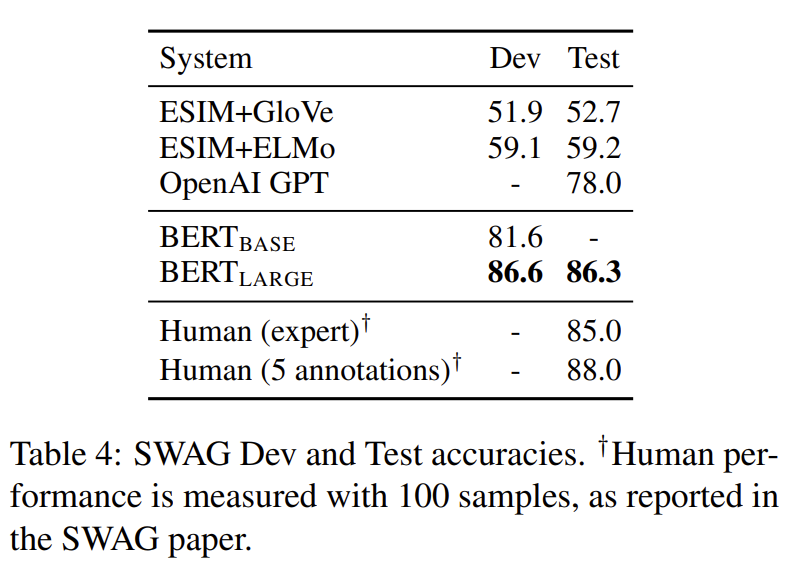
[그림11] SWAG (출처 : 논문 발췌)
- batch_size = 16
- epochs = 3
- learning rate = 2e-5
- 새롭게 추가된 파라미터 : 벡터 W
→ [CLS] 토큰의 표현 C와 내적을 수행하여
각 후보 문장의 점수를 계산
→ 계산된 점수를 softmax 레이어에 넣어
확률로 변환 - BERT_BASE, BERT_LARGE : 기존 SOTA보다 뛰어난 성능 기록
- 특히, BERT_LARGE의 경우, ESIM 계열보다 월등히 높은 성능
- 인간 전문가 수준을 뛰어 넘어, 여러 주석자의 평균 수치에 근접한 성능을 보임
🤔 My Thoughts
- Transformer가 엄청난 모델이긴 하구나
- 늘 느끼는 건데 성능 향상은 한끗 차이인듯
