Original Paper (Arxiv) : SpanBERT (https://arxiv.org/pdf/1907.10529)
📥Background : BERT
(1) MLM
입력 텍스트의 15%를 랜덤으로 마스킹한다.
- 80% : [MASK]
- 10% : 랜덤으로 대체
- 10% : 미변경 (원래 단어 그대로)
해당 토큰들 이외에 다른 토큰에 대한 예측은 무시한다.
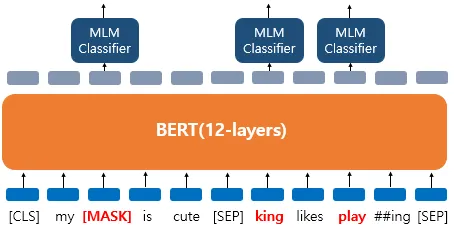
[그림1] Masking 후 출력되는 과정 (출처 : BERT 논문 발췌)
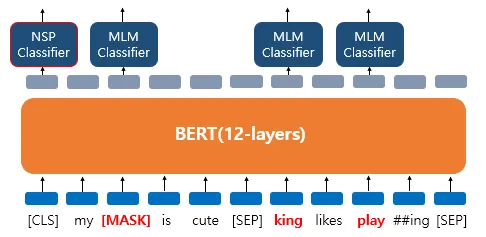
(2) NSP
다음에 올 문장을 예측하는 과정으로, 2개의 문장을 준 후에 서로 이어지는 문장인지 아닌지를 맞추는 방식이다.
1. 실제 이어지는 2개의 문장 & 랜덤으로 이어붙인 2개의 문장 input


2. segment embedding
[CLS] He went to school [SEP] He studied math [SEP]
- "He went to school" → Segment A
- "He studied math" → Segment B
[CLS],[SEP]도 Segment A, B 중 하나로 처리
3. transformer encoder 통과
두 문장의 정보를 종합한 벡터를 계산한다.
4. 앞서 Masked 벡터만 가져와서 softmax에 넣은 것처럼 [CLS] 벡터를 softmax에 넣어서 확률 출력
[그림2] NSP classifier (출처 : 딥러닝을 이용한 자연어 처리 입문 - 17장 https://wikidocs.net/115055)
- "YES" (1) → 문장 A와 B가 실제 연속된 문장 - "NO" (0) → 문장 A와 B가 랜덤하게 선택된 문장
5. 손실함수 계산 및 학습
y_hat과 y를 비교하여 Cross-Entropy Loss 계산한다.
📄Paper Review
0. Abstract
SpanBERT는 텍스트의 연속된 구간(span)을 더 잘 표현하고 예측하기 위해 고안된 사전학습 방식이다.
이 모델은 기존 BERT를 다음 두 가지 방식으로 확장한다.
- 무작위로 개별 토큰이 아닌 span을 마스킹
- 마스킹된 span의 시작/끝 경계를 활용해 전체 내용을 예측하도록 학습 (개별 토큰의 표현에 의존하지 않음)
BERT 및 다른 튜닝된 베이스라인보다 뛰어난 성능을 보였으며,특히 질문 응답(SQuAD)과 개체 간 지시(coreference resolution) 같은 span 선택 과제에서 큰 향상을 보였다.
실험 결과
- SQuAD 1.1: 94.6% F1,
- SQuAD 2.0: 88.7% F1,
- OntoNotes coreference: 79.6% F1 (SOTA 달성)
- TACRED 관계 추출, GLUE 벤치마크에서도 성능 향상
1. Introduction
(1) 배경 및 문제 제기
-
BERT와 같은 사전 학습 방법은 개별 단어 또는 서브워드를 마스킹하여 학습하는 방식으로 좋은 성능을 보였다.
-
하지만 많은 NLP 태스크에서는 두 개 이상의 텍스트 span 간의 관계를 이해하는 것이 중요하다.
(2) SpanBERT 제안 및 BERT와의 차이점
-
연속된 span 마스킹(span-based masking): 개별 토큰이 아니라 연속된 텍스트 span을 마스킹하여 학습한다.
-
span 경계 목적 함수(span-boundary objective, SBO): 마스킹된 span의 경계 정보를 활용하여 전체 span을 예측하도록 학습한다.
→ 이를 통해 모델이 문맥 속에서 전체 span을 보다 잘 이해하고 저장할 수 있도록 한다.
(3) 모델 성능 및 개선점
-
SpanBERT는 BERT 기반 모델보다 질의응답 및 문맥 내 핵심어 추출 태스크에서 더 높은 성능을 보였다.
-
SQuAD 1.1 및 2.0에서 각각 94.6%, 88.7%의 F1-score 달성했다 (BERT 대비 오류율 최대 27% 감소)
-
CoNLL-2012 문서 수준 개체 연결 태스크에서 79.6%의 F1-score 기록했다 (이전 최고 모델 대비 6.6%p 향상).
-
질의응답 외에도 TACRED(관계 추출) 및 GLUE(문장 이해 태스크)에서도 성능 향상이 확인됐다.
2. Background: BERT
BERT 개요
- transformer 기반의 사전 학습 모델로, self-supervised 학습을 통해 대량의 비라벨링된 텍스트에서 학습된다.
- 주요 학습 목표는 (1) MLM(Masked Language Model)과 (2) NSP(Next Sentence Prediction).
(1) MLM(Masked Language Model)
- 문장에서 15%의 토큰을 마스킹하고, 이를 원래대로 복원하는 방식으로 학습한다.
- 마스킹된 토큰의 80%는 [MASK], 10%는 랜덤 토큰, 10%는 원래 토큰을 유지한다.
- BERT는 개별 토큰을 독립적으로 마스킹하지만, SpanBERT는 연속된 span을 마스킹한다.
(2) NSP(Next Sentence Prediction)
- 두 문장이 연속적인지 여부를 예측하는 태스크
- 문장 쌍 중 하나는 실제 연속된 문장, 나머지는 랜덤으로 샘플링됐다.
- [CLS] 토큰을 활용하여 문맥적 연관성을 학습한다.
SpanBERT의 개선점
BERT는 개별 단어 예측에 집중하지만, SpanBERT는 연속된 span을 예측하도록 개선하여 보다 강력한 문맥 이해 능력을 갖췄다.
3. Model
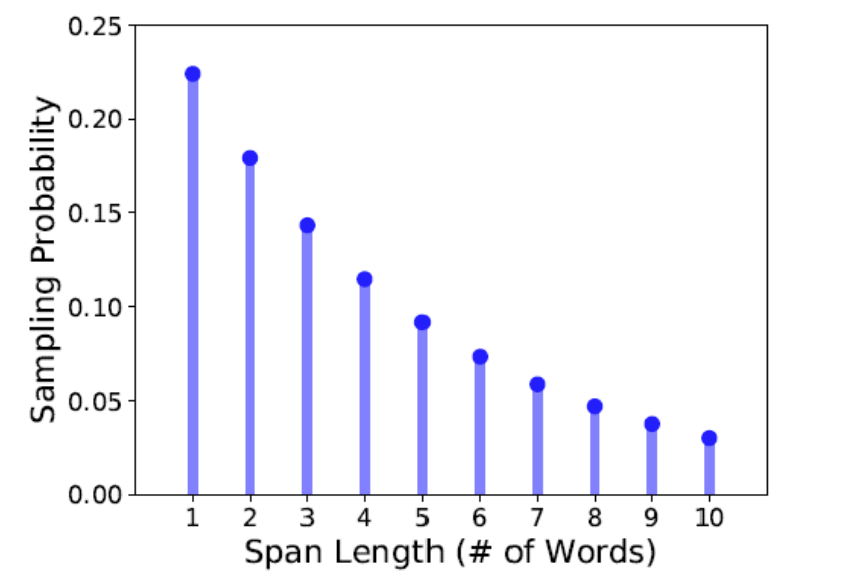
[그림3] Span Masking (출처 : 논문 발췌)
3.1 Span Masking
SpanBERT는 개별 토큰이 아닌 연속된 span 단위로 마스킹한다.
마스킹 과정
- 전체 토큰의 15%를 마스킹 (마스킹된 토큰 처리 방식은 BERT와 동일)
- 80%: [MASK] 토큰으로 대체
- 10%: 랜덤한 다른 토큰으로 대체
- 10%: 원래 토큰 유지
- 기하 분포(Geo(p=0.2))에서 스팬 길이를 샘플링하여 짧은 스팬이 더 자주 선택된다.
(최대 스팬 길이 = 10 / 평균 스팬 길이 = 3.8)
- 마스킹 시작점은 단어의 시작 위치여야 하며, 서브워드 단위가 아닌 완전한 단어 단위로 선택된다.
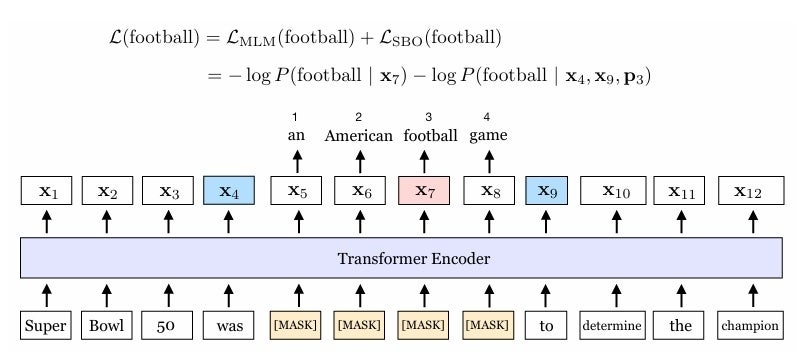
3.2 Span Boundary Objective (SBO)
개요
- SBO는 마스킹된 span 내부의 토큰을 경계 토큰의 정보만으로 예측하는 목표 함수
- 기존의 span 기반 모델들이 경계 토큰을 활용해 span을 표현하는 방식에서 착안했다.
SBO의 원리
트랜스포머 인코더의 출력을 x_1,x_2,...,x_n 이라 할 때, 마스킹된 span(x_s, ..., x_e)의 내부 토큰 x_i를 다음과 같이 표현한다.
- 왼쪽 경계 토큰 : x_{s-1}
- 오른쪽 경계 토큰 : x_{e+1}
- 상대적 위치 임베딩 : p_{i-s+1}
-
이를 입력으로 하는 2-layer feed-forward 네트워크 사용하여 y_i 생성한다.
-
GeLU 활성화, Layer Normalization를 포함한다.
GeLU 활성화 함수 사용 이유
- ReLU보다 부드러운 비선형성(nonlinearity)을 제공
→ Gradient 흐름이 더 안정적이라 모델이 더 자연스럽게 학습할 수 있도록 도움. - NLP에서는 GeLU가 더 좋은 성능을 보이기 때문에 BERT 및 SpanBERT에서 사용됨.
- ReLU보다 부드러운 비선형성(nonlinearity)을 제공
예시
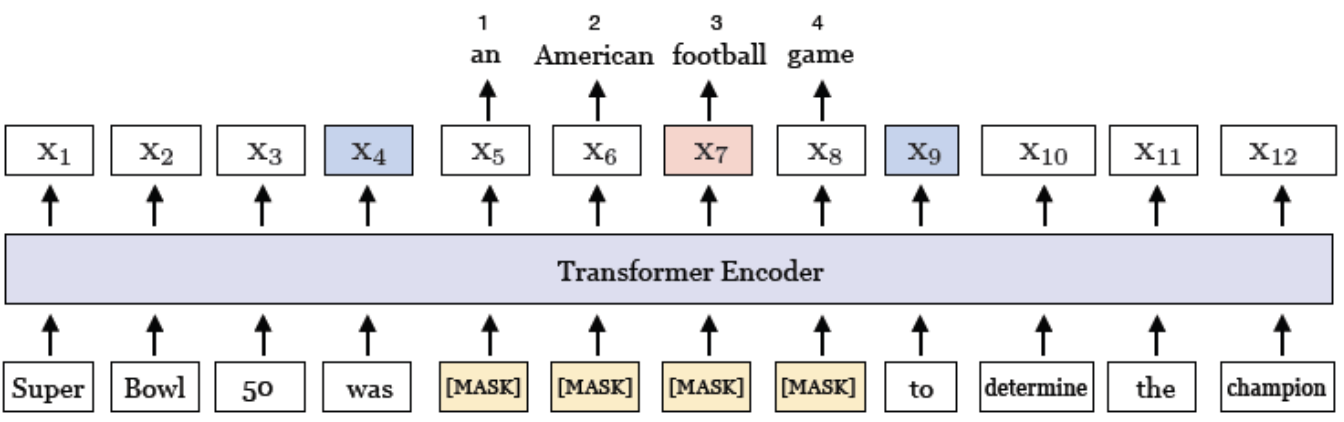
[그림4] Span Boundary Objective(SBO) (출처 : 논문 발췌)
- Span length: 4 / starting point: 5 / end point: 8
- 와 , 두 boundary token의 representation만으로 span 내부에 있는 각각의 토큰을 예측
손실 함수
마스킹된 토큰 x_i를 예측하기 위해 두 가지 손실을 합산
- MLM 손실: 원래 BERT의 마스킹된 토큰 복원 손실
- SBO 손실: SBO를 활용하여 마스킹된 토큰을 복원하는 손실
여기서 다음과 같은 의문이 들었고 관련하여 검색보았다.
왜 만 사용하지 않는가?
- Span 내부의 개별 단어 정보 없이 Boundary Token만으로 학습하는 방식이므로, 모든 문맥 정보를 활용하지 못할 가능성이 있음
- Boundary Token만 가지고 복원하려다 보니, 정확도가 떨어질 가능성이 있음
- 예시
The Eiffel Tower is [MASK] [MASK] [MASK] in Paris.
- SBO Loss는
"is"와"in"의 정보를 사용하여 마스킹된 Span을 복원하지만,- "located in France" 또는 "built in 1889" 같은 여러 가능성이 있을 수 있음.
- 즉, Boundary Token만으로는 정보가 부족할 수 있음.
SBO의 역할
- 모델이 span 내부 정보를 경계 토큰에 더 효과적으로 저장하도록 학습한다.
- span 예측이 중요한 태스크(질의응답, 개체 연결 등)에서 BERT보다 더 강력한 성능을 발휘한다.
3.3 Single-Sequence Training
SpanBERT는 BERT의 NSP 태스크를 제거하고, single-sequence training을 사용한다.
NSP 제거의 이유
-
BERT는 두 개의 문장 , 를 사용하여 NSP 태스크를 학습했지만, 이는 단일 시퀀스를 사용하는 것보다 성능이 낮은 경우가 많다.
"문맥 이해 능력보다는 단순한 문장 연결 여부를 학습할 가능성이 크다."
-
단순한 문장 관계만을 학습하고, 문맥적 이해에는 큰 기여를 하지 못한다.
(특히, 질문 응답(QA)처럼 단일 문장(Context)에서 정답을 찾는 태스크에서는 불필요한 학습 요소) -
두 문장을 강제로 묶어야 하기 때문에, 각 문장이 서로 관련 없는 경우에도 하나의 입력으로 들어갈 수 있다.
-
특히, 서로 다른 문서에서 온 문장을 강제로 연결할 경우, 모델이 불필요한 잡음을 학습할 가능성이 있다.
SpanBERT의 개선점 : single BERT
NSP를 제거하고, 최대 512 토큰 길이의 단일 연속 시퀀스를 학습
※ RoBERTa(2019) 등 최신 모델들은 NSP를 제거하고 단일 문장 학습(Single Segment) 방식을 채택하여 성능을 향상
BERT - SpanBERT 비교
| BERT | SpanBERT | |
|---|---|---|
| Masking | Token masking | Span masking |
| Pretraining Objective | MLM + NSP | MLM + SBO |
| Input sequence | Bi-sequence | Single-sequence |
4. Experimental Setup
BERT-large 설정을 유지하면서 몇 가지 주요 변경 사항을 적용
(1) 마스킹 방식 변경
BERT는 데이터 처리 시 각 시퀀스에 대해 10개의 다른 마스크를 미리 생성하지만, SpanBERT는 각 에포크마다 새로운 마스크를 적용
(2) 시퀀스 길이 수정
- BERT: 128 토큰 길이로 먼저 학습한 후, 512 토큰으로 확장하는 방식을 사용
- SpanBERT: 항상 최대 512 토큰을 유지하며, 문서 경계를 만날 때까지 시퀀스를 유지
(3) 학습 및 최적화 설정
- 학습률: 첫 10,000 스텝 동안 1e-4까지 워밍업, 이후 선형 감소
- AdamW 옵티마이저 사용: β1 = 0.9, β2 = 0.999 / weight decay = 0.1 / Epsilon = 1e-8
- 총 2.4M 스텝 동안 학습
- dropout 0.1 및 GeLU 활성화 함수 적용
(4) SBO(Position Embedding) 설정
200차원 포지션 임베딩을 사용하여 경계 토큰 기준 상대적 위치를 표시
(5) 학습 환경
- 32개의 Volta V100 GPU 사용, 15일 동안 사전 학습 진행.
- Batch size = 256, 최대 512 토큰 사용
🤔 My Thoughts
- BITAmin 딥러닝 논문리뷰 세션에서 다뤘던 논문으로, 3월 달에 읽고 다시 읽으니까 확실히 이지한 느낌이 있음
- 기존 BERT에서 다른 점은 span단위로 분석하고 single sequence를 사용한다는 것
- 개인적으로 세션에서 발표를 하면서도 느낀 것이지만, 좋은 아키텍처 혹은 뛰어난 아이디어 때문에 더 나은 성능을 보였다기보다는, 조금이라도 좋은 성능임을 증명하기 위해서 이것저것 튜닝을 많이 한 듯한 느낌이다.

역시 대단하십니다! 많은 공부가 되네요