Original Paper : GPT-1 (https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf)
📥Background
Transformer
Transformer 정리 글 참고 https://velog.io/@angel5893/Transformer-Attention-Is-All-You-Need-2017
이전까지는 attention을 RNN의 보정 용도로 사용해왔다면, Transformer에서는 이 개념만 사용하여 RNN을 빼고 self-attention으로 Encoder와 Decoder를 구성했다.
(1) Positional Embedding
RNN 혹은 CNN 모델을 사용하지 않기 때문에 시퀀스의 순서를 나타내기 위해서 추가적인 위치 토큰을 삽입해야 한다. 이를 위해 encoder와 decoder 하단의 입력 임베딩에 "위치 임베딩"을 추가했다.
이때 사인-코사인 기반 인코딩을 사용하여 각 차원별로 다른 주파수를 적용했다.
(2) Attention
self-attention
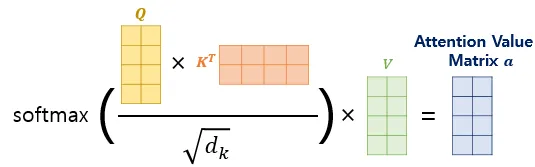
[그림1] self-attention 계산 과정 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [https://wikidocs.net/35596])
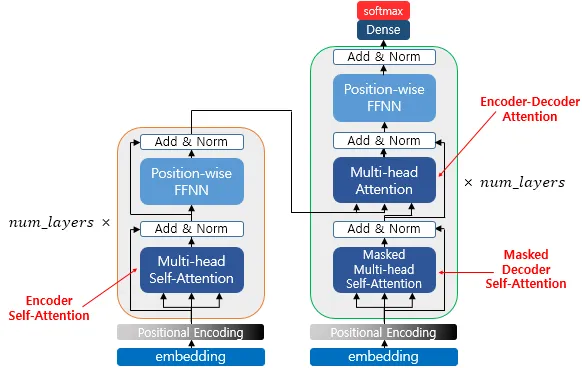
[그림2] encoder, decoder에서 사용되는 self-attention 종류 (출처 : 딥러닝을 이용한 자연어 처리 입문 - 16장 [https://wikidocs.net/35596])
1. encoder self-attention : 인코더에서 사용되는 어텐션
- 역할 : 소스 문장 내에서 단어들끼리의 관계를 학습
(각 단어가 문장에서 어떤 단어와 관계가 깊은 지 파악) - 방향성 : 양방향 = 모든 단어가 서로를 참고할 수 있음
- 출처 : query = key = value (원본 벡터 출처는 같음)
2. masked decoder self-attention : 디코더의 1번째 하위 계층
- 역할 : 타겟 문장에서 앞쪽 단어만 참고할 수 있도록 마스킹
- 현재 예측하는 단어보다 뒤에 오는 단어는 볼 수 없음)
← RNN과 다르게 문장을 통으로 입력하기 때문에 뒤에를 봐버리면 사전 관찰 - 출처 : query = key = value (원본 벡터 출처는 같음)
3. encoder-decoder attention : 인코더 벡터를 인풋으로 받는 어텐션
- 역할 : 인코더에서 출력한 context vector를 디코더에서 활용할 수 있도록 연결
- 디코더의 query 와 인코더의 key, value를 비교하여 가장 관련 있는 정보 찾기
- 출처
- query : from decoder input
- key = value : from encoder output
📄Paper Review
0. Abstract
NLP 분야는 문장 함의, QA, 의미적 유사성 평가 등 다양한 태스크가 존재하는데, 각 태스크에 대해 labeled data, 즉 정답이 존재하는 데이터는 매우 희소하다.
이에 본 논문은 unlabeled text로 사전학습한 후, 각 태스크에 대해서 fine-tuning하는 방식을 제안한다.
해당 모델은 다음 성과를 거두었다.
- 12개의 분야 중 9개의 분야에서 SOTA 기록.
- 상식적 추론 태스크 : 8.9% / QA : 5.7% / 텍스트 함의 : 1.5%
1. Introduction
(1) unlabeled data를 통한 비지도 학습의 중요성
raw data에서 효과적으로 학습하는 능력은 NLP에서 지도 학습에 대한 의존도를 줄이는 데 있어 매우 중요하다. 그런데 대부분의 딥러닝 기법은 방대한 양의 labeled data를 필요로 하며, 이는 label이 부족한 분야에 모델을 적용하는 데 있어 장애물이 될 수 있다.
이에 따라 unlabeled data로부터 언어적 정보를 활용할 수 있는 모델이 추가적인 라벨 작업 없이도 유용한 대안을 제공할 수 있다. 더불어, 충분한 지도 학습 데이터가 존재하는 경우에도, 비지도 방식으로 양질의 표현을 학습하는 것은 성능 향상에 큰 도움이 된다.
(2) 단어 의미 이상의 정보(문맥 등)를 비지도 학습으로 추출하는 것이 어려운 이유
-
어떤 목적 함수가 가장 적합한지 불분명하다. 최근 연구에 따르면, 태스크에 따라 각각 다른 최적화 목점 함수가 다른 것을 발견했다.
-
비지도적인 방법으로 학습된 표현을 전이하는 효과적인 방법이 통일되지 않았다. 현재, 구조 변경, 복잡한 학습 구조, 보조 목적 함수 추가 등으로 전이 학습을 진행하고 있기 때문에 효과적인 준지도 학습 방식을 정립하는 것이 어렵다.
본 논문에서는 다음 조합을 통해 준지도 접근법을 제안한다.
"비지도 방식의 사전학습 + 지도 방식의 fine-tuning "
1. 사전학습 : 같은 도메인이 아닌, universal한 unlabeled data를 학습함으로써 초기 파라미터 학습
2. fine-tuning : 각 태스크에 맞게 지도학습을 통해 파라미터를 조정
(3) Transformer 모델 활용
Transformer는 RNN보다 장기 의존성 처리에 있어 뛰어난 모습을 보이며 기계번역, 문서 생성 등에서 강력한 성능을 달성한 모델이라는 점에서 다양한 과제에 걸쳐 견고한 전이 성능을 달성할 수 있다.
전이 과정에서 탐색 기반 접근법을 사용하는데, 이는 구조화된 텍스트 입력을 하나의 연속적인 시퀀스로 처리하는 방식이다. 이 방법은 사전학습된 모델에 최소한의 변화를 주면서 fine-tuning을 효과적으로 할 수 있게 해준다.
(4) 실험 결과 : 모델 성능 개선
- 상식적 추론 태스크 : 8.9%
- QA : 5.7%
- 텍스트 함의 : 1.5%
- GLUE 벤치마크 : 5.5%
2. Related Work
(1) Semi-supervised learning for NLP
초기의 준지도 학습은 unlabeled data를 학습하여 단어 수준 혹은 구 수준의 통계정보를 계산한 뒤, 이를 지도 학습 모델의 feature로 활용하는 방식으로 사용되었다.
지난 몇 년간 많이 사용되었던 word embedding은 단어 수준, 즉 각 단어 자체의 의미 수준의 정보만 전이하는 데에 그쳤다.
최근 연구들은 unlabeled data로부터 구/문장 수준의 의미 표현을 학습하고, 이를 다양한 과제에서 활용 가능한 벡터 표현으로 전환하는 데 성공하고 있다.
(2) Unsupervised pre-training
준지도 학습의 특이 케이슬, 지도 학습 목적 함수를 수정하는 대신에 좋은 초기화 값을 찾는 것이 목표이다.
사전학습 후 fine-tuning을 진행하는 방식은 이미 선행 연구에서 제안되었으나, 해당 모델에서는 LSTM을 사용하였기 때문에 짧은 범주의 예측만 가능하다는 문제점이 있었다. 본 모델은 transformer를 통해 이러한 장기 기억 손실의 문제를 해결했다.
(3) Auxiliary training objectives
보조 학습 목표, 즉 주요 목표 외에 추가로 학습하는 목적 함수는 일반화 성능과 표현력을 높이는 방식으로, 일종의 준지도 학습이라고 할 수 있다.
POS 태킹, 청킹, 언어 모델링 목적 추가 등 최근 다양한 보조 목적을 통해 성능이 향상되지만, 본 연구에서는 강력한 비지도 사전학습 자체만으로도 많은 언어적 정보가 모델에 내재됨을 보여준다. 즉, 보조 목적은 옵션에 불과하며 사전학습만으로도 충분히 좋은 성능을 낼 수 있다.
3. Framework
3.1 Unsupervised pre-training
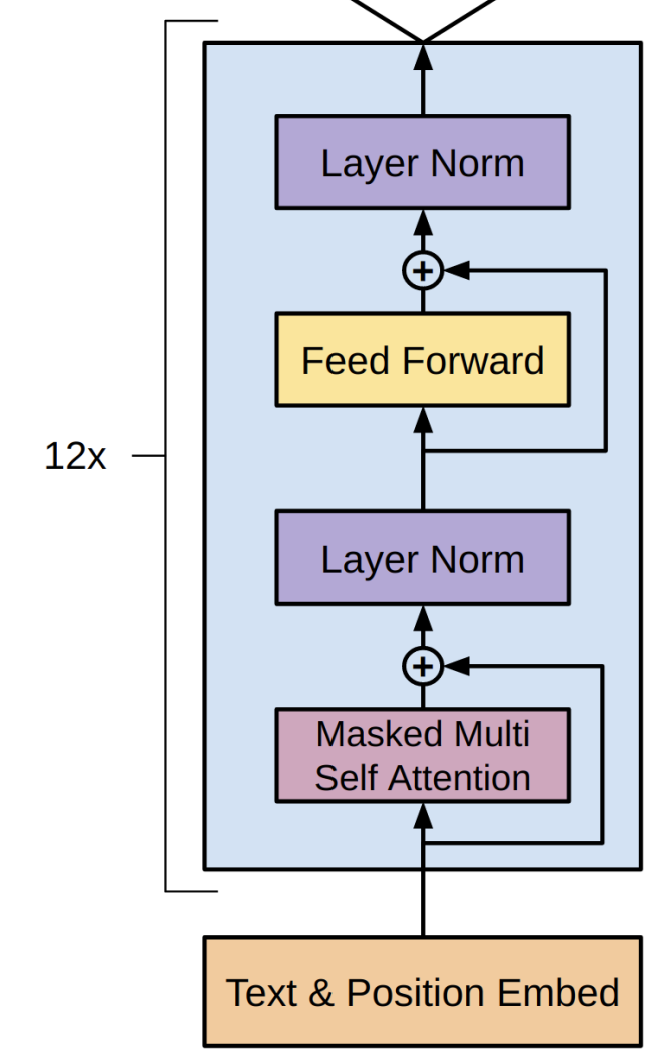
[그림3] unsupervised pre-training 구조 (출처 : 논문 발췌)
(1) 목적함수 (각 파라미터는 SGD를 통해 최적화)
( ※ 이때, )
(2) tranformer decoder
본 논문에서는 Transformer decoder를 12개 쌓은 모델을 사용했다. 각 과정은 다음과 같다.
(※아래 과정에 대한 내용은 논문에 나와있는 것이 아니라 필자가 서칭을 통해 정리한 내용으로 틀린 부분이 있을 수 있음)
1. 입력값 임베딩 :
- : 비지도 코퍼스의 토큰들
BPE로 토크나이즈되어 사전에서의 순서대로 각 토큰에 번호가 부여돼있는 상태- : 토큰 임베딩 행렬
- : 위치 임베딩 행렬
❓ 위 수식에서 들었던 의문
수식에서 와 가 곱해진다고 돼있는데, 룩업이 되려면 가 원-핫 벡터여야 가능한 것 아닌가? 내가 인터넷 찾아봤을 때, 는 사전에서의 각 순서가 번호로 나열돼있는 벡터라고 했는데 뭐지?
→ 수식에서만 저렇게 곱한다고 나타난 것이고, 실제로는 의 각 요소를 인덱스 삼아 에서 인덱싱하여 사용
e.g. [1] = 32 → [32] = [0.1, ... , 0.08] 에 더하기
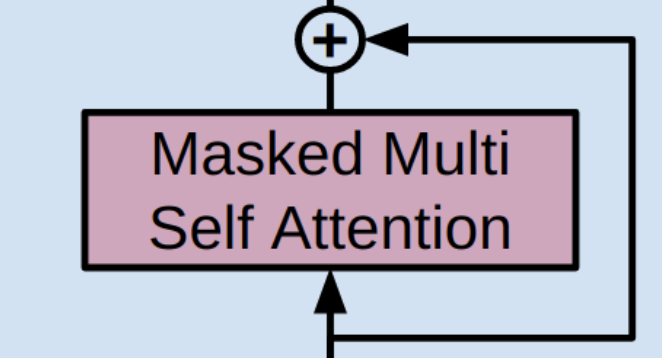
2. Masked Multi Self Attention
(1) 1.에서 계산한 임베딩 벡터를 원본 삼아 Q, K, V 벡터 생성
(2) 까지 구한 후, 상삼각 부분이 으로 구성돼있는 상삼각 행렬 더하기
→ 차원 :
(3) masking한 를 softmax에 통과시키기 =
(4) V와 곱한 다음에 나온 행렬을 head 개수만큼 concat한 후, 가중치 을 곱함으로써 선형 변환
글로만 적으면 다시 볼 때 이해하기 어려울 것 같으니 다음 예시를 통해 과정을 다시 한 번 복습해보자.
예시 문장 : "I am in Paris"
(0) 총 4개의 토큰에 대하여 토크나이징 → 토큰 임베딩 및 포지션 임베딩 진행
(1) 계산
(2) masking
(3) Softmax에 통과
(4) V와 곱하여 최종 attention output 계산 (multi-head concat 내용은 생략)
3. Residual Connection
- Transformer에서 사용된 잔차 연결을 GPT-1 모델에서도 사용
- 과 앞뒤로 잔차 학습 사용
- 잔차 학습의 목적
(1) 기울기 소실 방지→ 항등행렬로 인해 기울기가 항상 1 이상으로 유지됨
(2) 학습 안정성 향상 (연산량 감소X)
연산 자체는 이전 값을 더하는 것이기 때문에 약간 늘어난다고 할 수 있지만, 초기값을 이후에도 안정적으로 기억할 수 있다. (연산량 감소는 잔차 학습의 목적이 아님)
❓ ResNet 때부터 들었던 의문
잔차 학습이면 이전 값을 뺀 잔차값을 학습하는건가? 그럼 계산이 더 복잡해지지 않나?
→ 말이 "잔차" 학습이지, 사실은 그냥 이전 값에 새롭게 계산된 값을 더하는 것임!
4. Layer Norm
- Post LN : Residual Connection 뒤에 위치한 정규화를 의미
- 정규화의 역할 : 값의 scale 정돈 및 더 빠르고 안정적으로 학습하게 함
5. Feed Forward : 비선형성 추가
(1) ← 일반적으로
(2)
(3)
6. Mask 해두었던, 즉 미래 단어를 예측한 후, loss 계산 후 역전파 진행
- unsupervised pre-training인 만큼, 별도의 label이 존재하지 않는다.
- 앞서 2.에서 mask해둔 단어 예측
3.2 Supervised fine-tuning
1. 입력과 label
labeled dataset 사용
- 입력 시퀀스 :
- 정답 라벨 :
2. 출력 확률 계산
(1) 입력 시퀀스를 사전학습된 GPT 모델에 통과시켜 마지막 Transformer 블록의 마지막 토큰 출력 얻기
(2) 이 벡터를 새롭게 추가된 선형 분류기 에 넣어 예측 확률을 계산
3. fine-tuning 손실 함수
4. 기존 언어 모델링 손실 을 보조 학습 목표로 추가
fine-tuning 성능을 높이기 위해 앞서 사전학습에서 설정했던 을 보조로 같이 학습
→ 모델의 일반화 성능 향상 및 학습 수렴 속도 증가
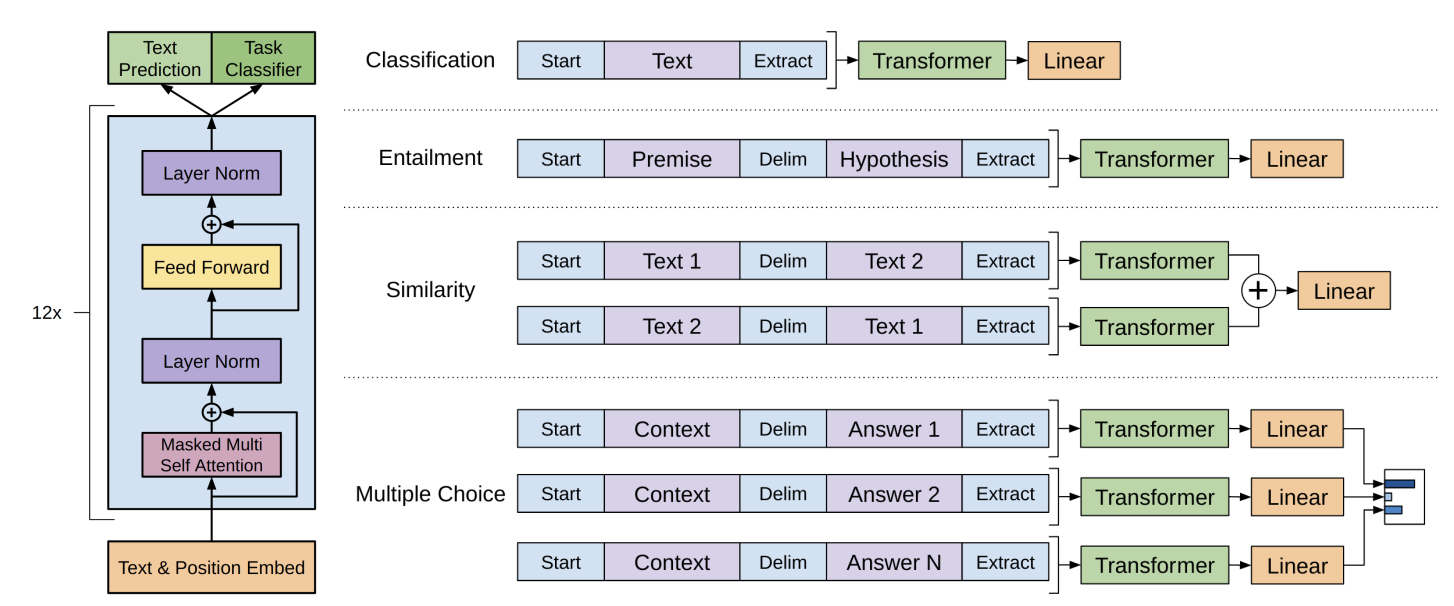
3.3 Task-specific input transformations
1. 문장 분류 : 기존 사전학습 모델에 layer 추가
(1) linear : 분류될 클래스 개수로 차원 변환
(2) softmax : 각 클래스에 속할 확률 계산
(3) loss 계산 후 역전파 진행
2. 텍스트 함의, 유사성, QA / Multi-turn QA, 상식적 추론 : input 처리
-
선행 연구에서는 추가적인 구조 커스터마이징 및 새 아키텍처를 필요로 함. 즉, 복잡한 과정이 필요했음.
-
탐색 기반 접근법을 통해 구조화된 텍스트 입력을 하나의 연속적인 시퀀스로 처리
(QA 예시)
context : 민성이가 치킨이 먹고 싶을 때마다 일본에 계신 아빠께 말씀드리면, 아빠께서 요기요로 치킨을 시켜주신다. Question : 민성이의 아빠는 어떻게 치킨을 시키시는가?=> context와 question을 하나로 합쳐서 input으로!
❓context에 대한 궁금증
context는 어떻게 붙여주는가? 사용자가 일일이 입력하지는 않을 것 같은데
→ fine-tuning : SQuAD 등의 데이터셋 활용
→ 실전 : RAG 모델이 context 후보를 찾아옴
🤔 My Thoughts
- 새로운 모델을 배울수록 이전 모델을 공부할 때는 생각나지 않던 새로운 궁금증이 생기고 이것을 해결하는 과정이 재밌었다.
- Transformer도 그렇고 GPT-1도 그렇고 선행 연구에서 특정 부분만 따왔다고 했는데, 어쩜 이런 생각들을 하는 건지 참 신기하다.
