Original Paper (Arxiv) : RoBERTa (https://arxiv.org/pdf/1907.11692)
📥Background : BERT
(1) MLM
입력 텍스트의 15%를 랜덤으로 마스킹한다.
- 80% : [MASK]
- 10% : 랜덤으로 대체
- 10% : 미변경 (원래 단어 그대로)
해당 토큰들 이외에 다른 토큰에 대한 예측은 무시한다.
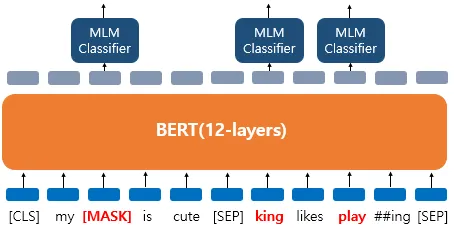
[그림1] Masking 후 출력되는 과정 (출처 : BERT 논문 발췌)
(2) NSP
다음에 올 문장을 예측하는 과정으로, 2개의 문장을 준 후에 서로 이어지는 문장인지 아닌지를 맞추는 방식이다.
1. 실제 이어지는 2개의 문장 & 랜덤으로 이어붙인 2개의 문장 input


2. segment embedding
[CLS] He went to school [SEP] He studied math [SEP]
- "He went to school" → Segment A
- "He studied math" → Segment B
[CLS],[SEP]도 Segment A, B 중 하나로 처리
3. transformer encoder 통과
두 문장의 정보를 종합한 벡터를 계산한다.
4. 앞서 Masked 벡터만 가져와서 softmax에 넣은 것처럼 [CLS] 벡터를 softmax에 넣어서 확률 출력
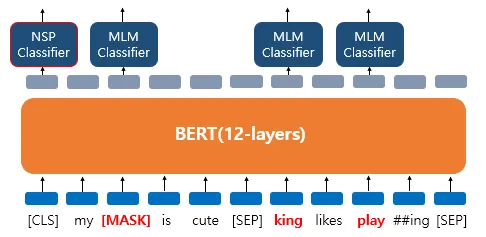
[그림2] NSP classifier (출처 : 딥러닝을 이용한 자연어 처리 입문 - 17장 https://wikidocs.net/115055)
- "YES" (1) → 문장 A와 B가 실제 연속된 문장 - "NO" (0) → 문장 A와 B가 랜덤하게 선택된 문장5. 손실함수 계산 및 학습
y_hat과 y를 비교하여 Cross-Entropy Loss 계산한다.
📌 왜 BERT를 재학습할 필요가 있었는가?
BERT의 성능은 모델 구조 때문이라기보다는, 학습 설정과 데이터 양, 마스킹 전략 등 다양한 요소에 의해 좌우된다는 연구들이 잇따라 등장하였다.
- NSP가 실제로 downstream task에서 유의미한 역할을 하는지
- 고정된 마스킹 방식(static masking)은 충분히 다양한 문맥을 모델이 접하지 못하게 한다는 한계
📄Paper Review
0. Abstract
RoBERTa는 BERT의 모델 구조, 즉 Transformer encoder는 동일하게 가져가지만, 학습 과정과 데이터, 마스킹 전략, objective 등 사전학습의 모든 구성요소를 재설계하였다.
🧠 핵심적인 변경사항
1. NSP 제거: 문장 간 관계 예측을 위한 NSP task를 제거
2. Dynamic Masking: 학습 중 각 배치마다 다른 마스킹을 적용하여 다양한 문맥을 학습
3. 10배 이상 큰 데이터: BookCorpus 외에도 CC-News, OpenWebText 등 총 160GB 이상의 데이터를 사용
4. 더 큰 배치 사이즈, 더 긴 학습 시간: 학습 배치 사이즈를 8k로 늘리고, 학습 스텝도 최대 1.5M까지 증가시킴
이러한 변화들을 통해 RoBERTa는 GLUE, SQuAD, RACE 등 다양한 벤치마크에서 BERT를 압도하며, 단순한 구조 변경보다 학습 전략 최적화의 중요성을 부각시켰다.
1. Introduction
BERT는 NLP 분야에 큰 성과를 가져다주었지만, 그 학습 설정은 최적이 아니었을 수 있으며, 구조보다는 설정의 한계일 수 있다는 문제를 제기한다.
📌 주요 의문
- NSP가 downstream task 성능에 기여하는가?
- 고정된 마스킹 방식은 문맥 다양성을 제한하지 않는가?
- 더 많은 데이터와 연산량이 주어졌다면 더 좋은 성능이 가능했을까?
2. Background
해당 목차에서는 BERT의 사전훈련 접근 방식과 훈련 과정에서 선택한 설정에 대해 이야기한다.
2.1 Setup
BERT는 입력으로 두 개의 segment를 [CLS], [SEP] 등 특수 토큰과 함께 연결하여 처리한다. Segment는 일반적으로 하나 이상의 문장으로 구성되며, 전체 시퀀스 길이는 최대 길이 T 이하로 제한된다. 사전학습은 라벨 없는 대규모 텍스트로 진행되며, 이후 다운스트림 태스크에 대해 파인튜닝된다.
2.2 Architecture
BERT는 Transformer 인코더 아키텍처를 사용한다.
구성
- L: 레이어 수
- A: self-attention head 수
- H: hidden dimension
RoBERTa는 BERT와 동일한 아키텍처를 사용하며, base 모델은 110M, large 모델은 355M 파라미터를 가진다.
2.3 Training Objectives
MLM (Masked Language Modeling)
- 입력 시퀀스의 15% 토큰을 마스킹
- 이 중 80%는 [MASK], 10%는 원형 유지, 10%는 랜덤 대체
NSP (Next Sentence Prediction)
- 두 세그먼트가 원래 문서에서 연속된 것인지 아닌지를 이진 분류
- 실제 연속 문장과 다른 문서에서 추출한 문장을 50%씩 사용
2.4 Optimization
- optimizer: Adam (β1=0.9, β2=0.999, ε=1e-6), weight decay=0.01
- learning_rate: warm-up 후 선형 감소 (peak=1e-4)
- dropout: 0.1, activation: GELU
- max seq length = 512, batch size = 256, 총 1M step 학습
3. Experimental Setup
3.1 Implementation
- FAIRSEQ 프레임워크로 BERT 재구현
- 일부 하이퍼파라미터 (learning rate, warmup step, Adam ε 등)는 별도 튜닝
- full-length sequence만 사용 (short sequence 사용 안함)
- mixed precision, 1024 V100 GPU 기반 분산 학습
3.2 Data
총 160GB 이상의 영어 코퍼스
- BookCorpus + Wikipedia (BERT와 동일): 16GB
- CC-News: CommonCrawl 뉴스 데이터 (76GB)
- OpenWebText: Reddit 링크 기반 웹 텍스트 (38GB)
- Stories: story-like 스타일 (31GB)
3.3 Evaluation
3개의 벤치마크 사용
- GLUE: 9개의 자연어이해 태스크 포함
- SQuAD 1.1/2.0: span prediction (2.0은 unanswerable 포함)
- RACE: 중고등학생용 시험에서 추출된 100,000개의 질문 포함
4. Training Procedure Analysis
4.1 Static vs. Dynamic Masking
-
BERT
마스킹된 토큰의 위치가 학습 전에 고정(static)되어 있으며, 학습 도중 동일한 마스크 조합만 사용된다. -
RoBERTa
dynamic masking 방식을 도입하여 각 학습 step마다 새로운 마스킹 위치를 샘플링한다. 이렇게 하면 모델이 보다 다양한 문맥을 접할 수 있으며, 단일 예제에 대해서도 더 넓은 분포의 예측 패턴을 학습할 수 있게 된다.
실험 결과, dynamic masking이 static masking보다 SQuAD 및 GLUE 태스크에서 약간의 성능 향상을 보였으며, 특히 계산 효율성 측면에서도 동적 마스킹이 유리한 것으로 나타났다. 따라서 RoBERTa는 기본적으로 dynamic masking을 채택하였다.
4.2 Model Input Format and Next Sentence Prediction
RoBERTa는 NSP의 제거가 성능에 미치는 영향을 분석하기 위해 다양한 입력 포맷을 실험했다.
- SEGMENT-PAIR + NSP: BERT와 동일한 방식. 두 문장을 segment로 나누고 NSP task 수행
- SENTENCE-PAIR + NSP: 문장 단위 쌍을 이용하되 NSP 유지
- FULL-SENTENCES: NSP를 제거하고 단일 문장을 최대한 길게 이어붙여 입력 (문장 경계 무시)
- DOC-SENTENCES: NSP 제거, 동일 문서 내 문장들로만 구성
결과적으로 NSP를 제거한 FULL-SENTENCES 또는 DOC-SENTENCES 방식이 NSP를 유지한 방식보다 MNLI, RACE 등에서 더 좋은 성능을 보였다. 이는 NSP가 사전학습 효율에 기여하지 않으며, 오히려 더 많은 양의 시퀀스를 활용하는 것이 성능 향상에 유리하다는 것을 보여준다.
4.3 Training with large batches
RoBERTa는 batch size 증가가 학습 효율과 성능에 미치는 영향을 분석했다.
실험
- batch size: 256 → 2K → 8K
- 각 실험에서는 동일한 총 학습 step 수 유지
결과
- batch size가 클수록 학습 수렴 속도가 빨라지고, GLUE 및 SQuAD 등의 downstream task에서도 성능이 향상
- 8K 배치에서는 BERT 대비 더 빠른 수렴 속도와 높은 안정성이 관찰됨
이러한 실험은 대규모 GPU 자원이 있다면 더 큰 배치와 더 긴 시퀀스를 활용하는 것이 효과적이라는 점을 실증적으로 보여준다.
4.4 Text Encoding
RoBERTa는 텍스트 전처리 방식에도 변화를 주었다. 기존 BERT는 character-level BPE vocabulary (30K)를 사용했지만, RoBERTa는 byte-level BPE vocabulary (50K)를 사용하였다.
byte-level BPE vocabulary
- 모든 문자를 byte 단위로 처리하기 때문에 텍스트 전처리의 복잡도를 줄이고, 다양한 언어 및 특수 문자 표현에 보다 유연하게 대응 가능
- 실험 결과 char-level BPE에 비해 성능 차이는 거의 없었으나, 확장성과 범용성이 뛰어나 기본 설정으로 채택되었다.
5. RoBERTa
RoBERTa는 Section 4에서 분석한 모든 요소를 반영하여 구성된 최종 모델이다.
주요 특징
- Dynamic masking 적용
- NSP 제거 (FULL-SENTENCES 방식 채택)
- Large batch training (최대 8K)
- Byte-level BPE 사용
- 160GB 대규모 텍스트 데이터
- 최대 500K step 이상 학습
5.1 GLUE Results
GLUE 벤치마크에서 RoBERTa는 9개 모든 태스크에서 BERT, XLNet을 상회하는 성능을 기록했다. 특히 MNLI, RTE, QNLI, SST-2 등 다양한 영역에서 높은 정확도를 보였다. 실험에서는 single model 기준이며, ensemble 없이도 SOTA 성능을 기록했다.
또한 RoBERTa는 MNLI에서 학습한 모델을 RTE, MRPC 등 다른 태스크에 전이하여도 좋은 성능을 보여 transfer learning 효과도 탁월했다.
5.2 SQuAD Results
RoBERTa는 SQuAD 1.1과 2.0에 대해 데이터 증강 없이 fine-tuning만으로 최고 성능을 달성했다.
- SQuAD 1.1: EM 88.9 / F1 94.6
- SQuAD 2.0: EM 86.5 / F1 89.4
이는 당시 기준 모든 모델을 능가하는 성능으로, pretraining 설정만 변경해도 큰 성능 향상이 가능함을 보여준다.
5.3 RACE Results
RACE 데이터셋은 지문, 질문, 보기, 네 개 중 정답을 고르는 다지선다 문제이다. RoBERTa는 입력 시 passage, question, 각 candidate를 연결하여 4-way classification을 수행했다.
결과
- RoBERTa-large: 전체 Accuracy 83.2%
- BERT-large 대비 약 11.2%p 향상 (BERTLARGE 72.0%)
- XLNet-large 대비 1.5%p 향상 (XLNetLARGE 81.7%)
특히 RACE-Middle과 RACE-High 두 하위 데이터셋 모두에서 가장 우수한 성능을 기록했다.
🤔 My Thoughts
- BERT를 처음 읽었을 때 정말 신기했는데, 여기서 더 발전시킨 모델을 보니 더 신기했다.
- 연구실에 Robusting 공부하시는 분들이 많았는데, 그냥 막연하게 알던 내용을 좀 더 공부하고 싶다는 생각이 들었다.
