데이터프레임과 시리즈
- Series : 1개의 column
- DataFrame : 시리즈들이 모여만든 행과 열로 이루어진 표
pandas 라이브러리는 데이터 분석용 라이브러리로 데이터를 다루는 패키지 중 하나
대표적으로, DataFrame 이라는 자료구조를 가지고 있다.
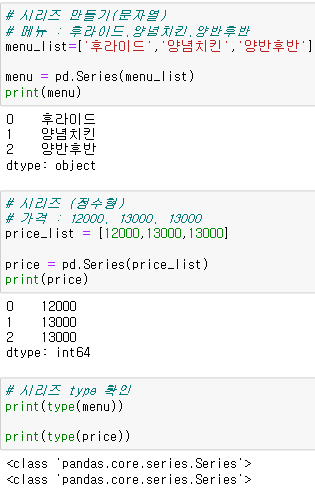
pd.Series(배열)배열을 파라미터로 넣어서 리스트를 생성할 수 있다.
데이터프레임을 만드는 법
1. 리스트 딕셔너리를 활용해서 직접 만들기
2. 파일을 통해 데이터를 가져오기
1. 리스트, 딕셔너리 활용
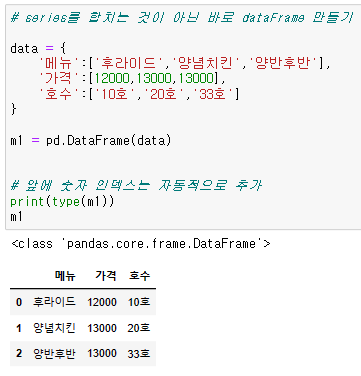
리스트 대신 시리즈를 활용해도 상관없다.
2. 파일을 통해 데이터를 가져오기
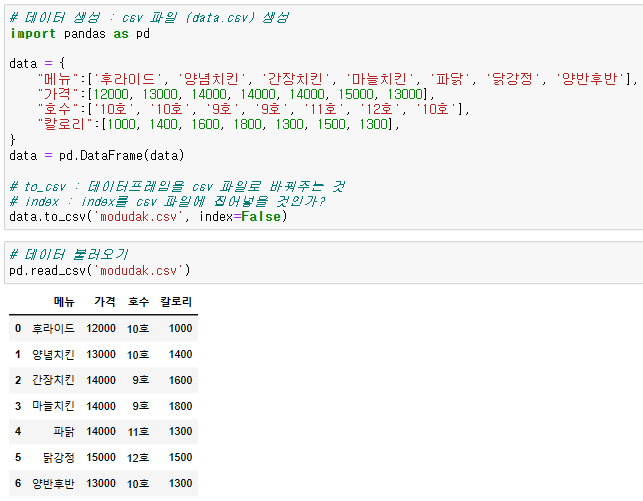
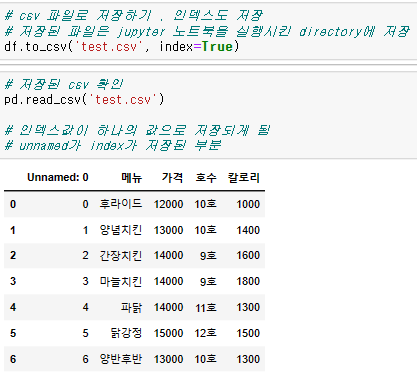
# 데이터를 csv로 저장
{데이터프레임}.to_csv({csv 이름})
# 만약, dataframe의 index까지 저장하고 싶다면
{데이터프레임}.to_csv({csv 이름}, index=True)
# csv를 dataframe으로 불러오기
pd.read_csv({csv 이름})데이터 샘플 확인
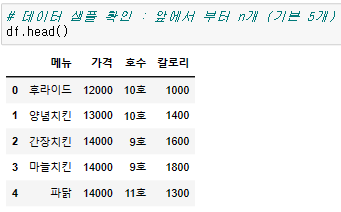
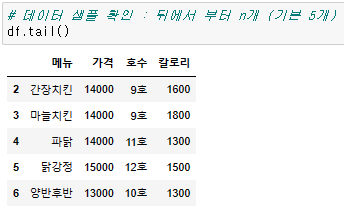
# 앞쪽 데이터 확인 (default=5)
{datframe명}.head()
# 뒤쪽 데이터 확인 (default=5)
{datframe명}.tail()데이터 선택하기
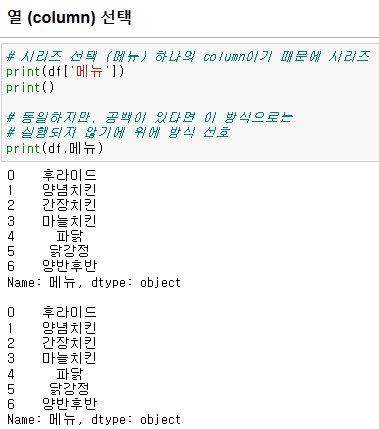

# 한 개의 column 선택
{데이터프레임 명}[column명]
# 여러 개의 column 선택
# 데이터프레임을 불러오기 위해서는 대괄호가 두개 있어야 한다.
{데이터프레임 명}[[column명1, column명2]]행 (row) 선택
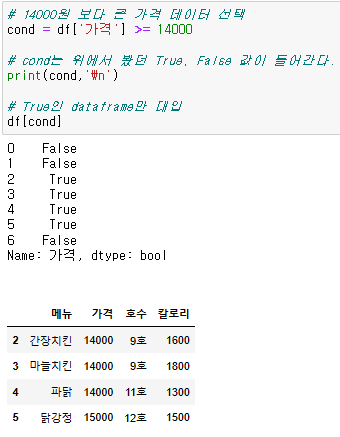

# 조건문을 사용해야할 경우 ( cond 라는 변수명 추천 )
cond = {조건}
# cond에는 조건문에 대해 행들의 True, False 반환
# True인 행에 대해서 반환
{dataframe명}[cond]
# 여러개의 조건문이 필요한 경우에는?
{dataframe명}[cond1 & cond2]
isin 함수: 해당 행이나 열이 안에 값이 들어가 있는지 확인
여러 값들이 있는지 확인하려면, 리스트로 구성
인덱싱 / 슬라이싱 (indexing / slicing)
그 전에, loc를 사용하기 전에 인덱스명을 바꾸자
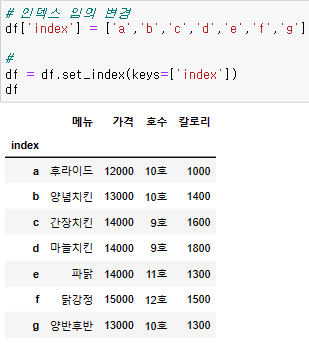
- loc
parameter로 index명과 colum명을 사용

만약, 띄어져 있는 데이터 값들은 어떻게 표현할까?

이렇게 대괄호 안에 column들을 집어넣는 것을 볼 수 있다.
- iloc
parameter로 index number와 parameter number 사용
슬라이싱을 할때 loc와 차이점은 리스트처럼 뒤에 나온 number 전까지만 해당한다는 점이다.

동일하게, 띄어져 있는 데이터 값들은 어떻게 표현할까?
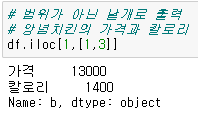
loc와 동일하게 대괄호 안에 표현하는 것을 볼 수 있다.
Index 다루기
- set_index : 맨 왼쪽에 있는 column인 index를 어떤 column으로 할 지 결정
# 선정된 column을 index로 사용하겠다는 의미
{df명}.set_index(keys=[{column명}])
# 모든 dataframe을 변경하는 것은 다시 재할당을 해줘야함
{df명} = {df명}.set_index(keys=[{column명}])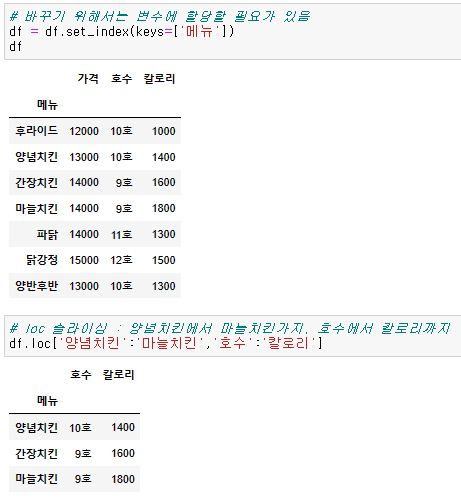
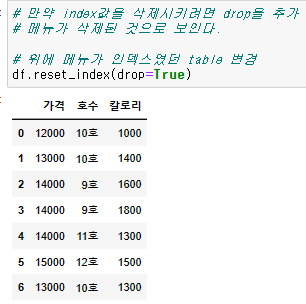
- reset_index : 정수형 인덱스로 모두 변경해주며, 원래 있던 인덱스에 처분을 결정 가능
# 동일하게 재할당 해줘야함
{df명} = {df명}.reset_index()
# 만약 원래있던 인덱스를 없애버리고 싶으면, drop = True 로 파라미터 추가
{df명} = {df명}.reset_index( drop = True )
행과 열 추가
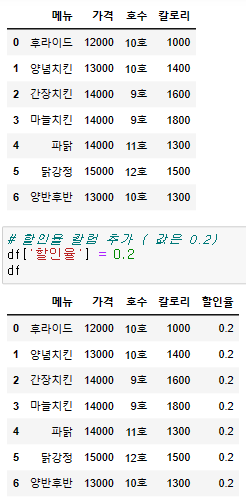
열 (column) 추가
# 리스트와 같은 형태로 값을 추가할 수 있다.
# 모든 열에 같은 값이 추가되는 것을 볼 수 있다.
{df명}[{colum명}] = {value}
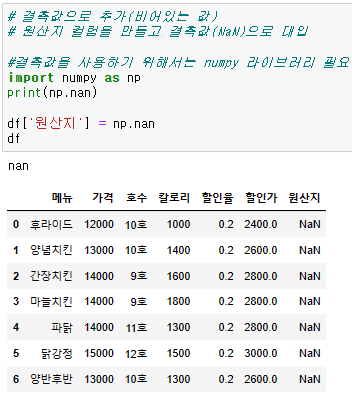
# 결측값 (비어있는 값) 을 추가하고 싶은 경우 (NaN)
# 결측값을 사용하기 위해서는 numpy 라이브러리 필요
import numpy as np
df['원산지'] = np.nan
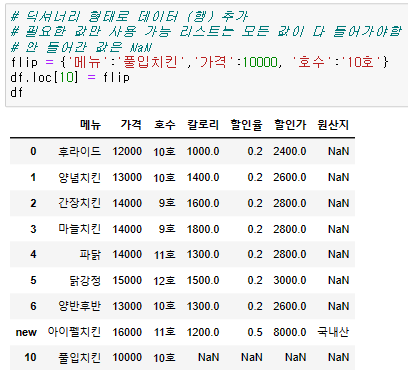
행 (row) 추가
행에 들어가는 value는 list, dictionary로 넣어야 한다.
차이점은 list는 모든 값을 정확히 넣어야 error가 발생되지 않고,
dictionary는 안 들어간 값을 NaN으로 띄워준다.
# 넣을 때에는 loc, iloc를 활용해서 데이터에 접근한다.
{df명}.loc[{추가할 index명}] = {value}
{df명}.iloc[{추가할 index number}] = {value}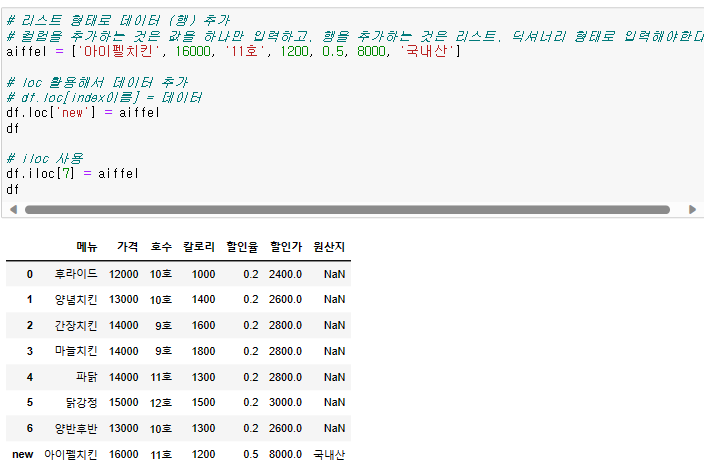
값 변경
값 변경
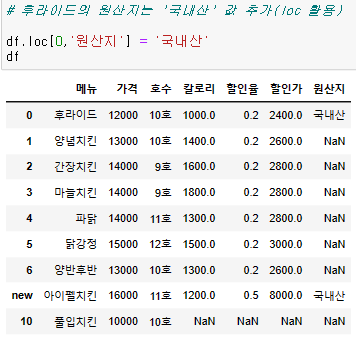
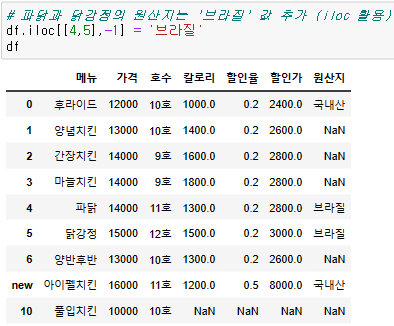
1. loc와 iloc 를 이용해서 데이터에 접근
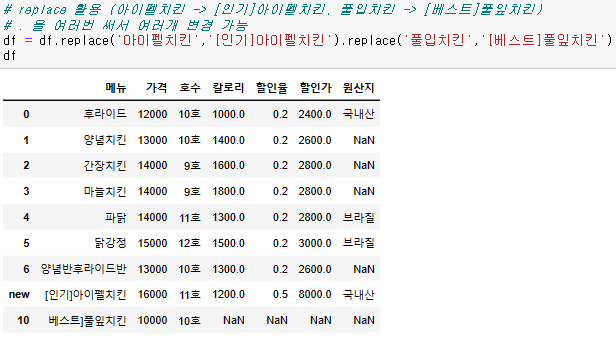
2. replace 함수를 사용해서 접근 ( 데이터 낱개, dictionary )
{df명}.loc[{위치}] = {바꿀 value}
{df명}.iloc[{위치}] = {바꿀 value}
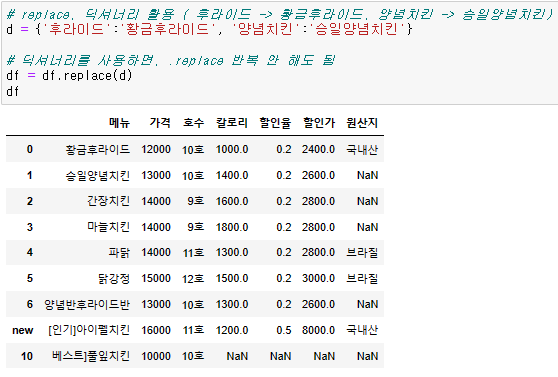
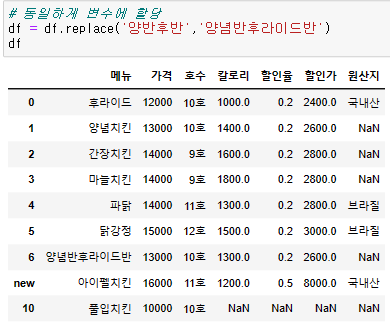
{df명} = {df명}.replace( {바뀌기 전 data}, {바꿀 데이터} )
# 만약 다수를 추가하는 경우, dictionary로 구성하는 것이 편하다.
dict = { {바뀌기 전 data} : {바꿀 데이터} , {바뀌기 전 data} : {바꿀 데이터} }
{df명} = {df명}.replace(dict)1. loc, iloc 활용
2. replace 활용
- 데이터 낱개
- dictionary