어제 docker의 tensorflow 이미지로 진행하다가 다 날려먹고 오늘 다시 처음부터 분석을 시작했습니다.
참고한 커널을 거의 Copy한 정도이기 때문에 학습 등의 목적을 가지고 계신 분은 참고한 커널 Kaggle 공개 커널, 곽대훈님의 데이터 분석 어떻게 시작해야 하나요?로 이동해주세요.
데이터 분석 시작해보자
본 커널은 DHH(Digital Health Hack)에 참가하게 되어 기초가 부족한 상태에서 다른 팀원분들의 진행 과정을 최소한이라도 이해하고 따라가기 위해 학습하는 과정을 기록한 커널입니다.
Reference
해당 커널은 아래 링크의 멋지고 환상적인 분석을 해주신 곽대훈님의 캐글 커널을 참고하였습니다.
Kaggle 공개 커널, 곽대훈님의 데이터 분석 어떻게 시작해야 하나요?
참고한 튜토리얼의 프로세스 진행에 맞춰 학습하였습니다.
참고 커널의 진행 과정
- 데이터 셋 확인
- 탐색적 데이터 분석 (EDA, Exploratory Data Analysis)
- 특성 공학 (Feature Engineering)
- 모델 개발 및 학습
- 모델 예측 및 평가
1. 데이터 셋 확인
일단 필요한 패키지(라이브러리)들을 import 합니다.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import keras
import sklearn
plt.style.use('seaborn')
sns.set(font_scale=2.5)위의 코드는 참고 커널의 필자가 항상 쓰는 방법이라고 합니다.
matplotlib의 기본 schema 말고 seaborn의 scheme를 세팅하여 사용하면 편하다고 합니다.
import missingno as msno
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
os.listdir('./input')Output: ['test.csv', 'train.csv', 'gender_submission.csv']
필요한 파일들을 root 경로에서 input 폴더를 생성하고 생성한 폴더로 옮겨주었습니다.
os.listdir 메소드를 이용하여 확인해보았습니다.
df_train = pd.read_csv('./input/train.csv')
df_test = pd.read_csv('./input/test.csv')
df_submit = pd.read_csv('./input/gender_submission.csv')
df_train.shape, df_test.shape, df_submit.shapeOutput: ((891, 12), (418, 11), (418, 2))
df_train.columns
df_submit.columns
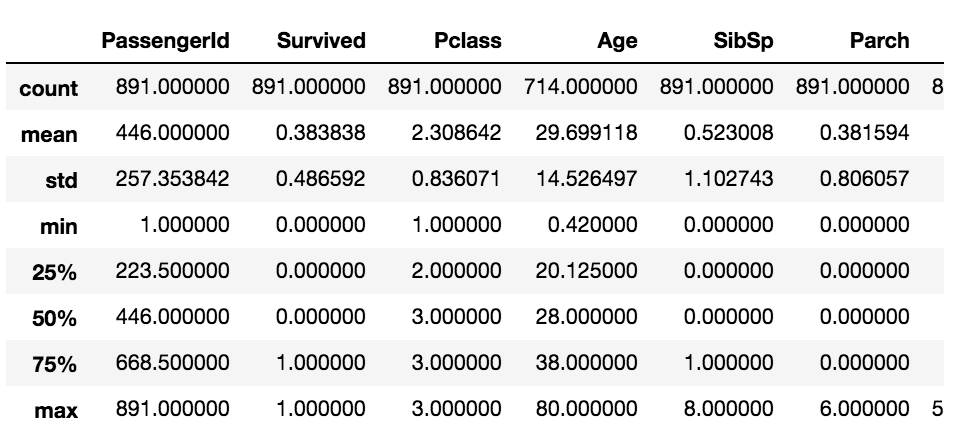
df_train.describe()
df_submit.describe()Output[0]: Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
Output[1]: Index(['PassengerId', 'Survived'], dtype='object')
Output[2]:
Output[3]:
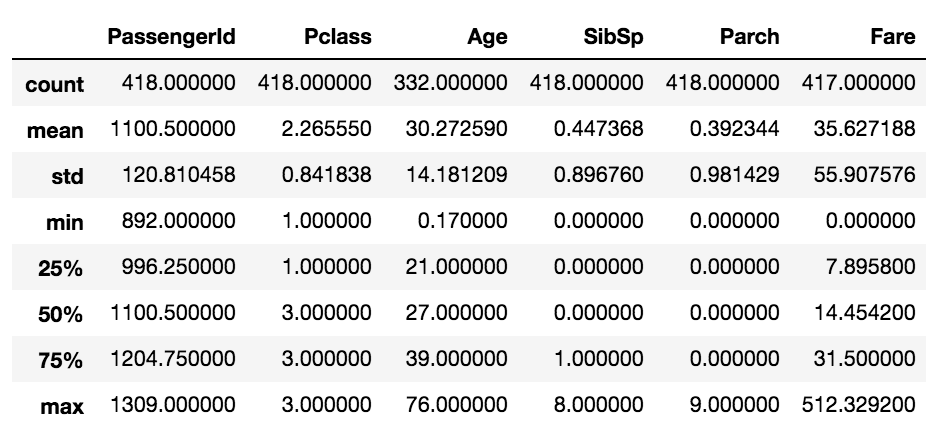
각 csv 파일들을 pandas 패키지의 read_csv 메소드를 통해 읽어 저장하고 저장된 데이터를 colums으로 Feature들을 확인하고, shape, head, describe 등의 메소드를 통해 살펴보았습니다.
- shape : DataFrame의 (row num, column num)을 반환해줍니다.
- head : 데이터의 row를 index 오름차순으로 정렬했을 때 상위 5개의 row를 보여줍니다.
- describe : DataFrame의 각 feature가 가지는 통계치를 반환해줍니다.
1.1 결측치 확인
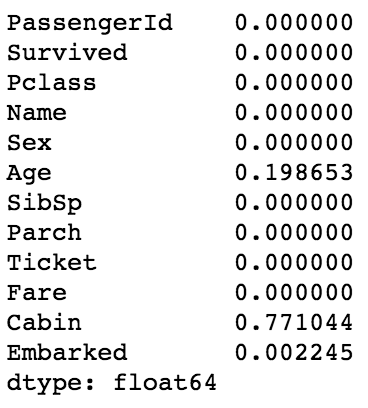
df_train.isnull().sum() / df_train.shape[0]
df_test.isnull().sum() / df_test.shape[0]Output[0]:
Output[1]:
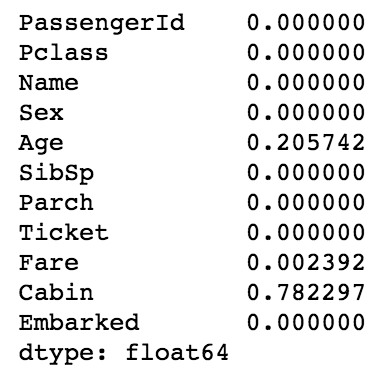
train set과 test set의 feature별 결측치(데이터가 null인 비율)을 확인해보았습니다.
Age feature와 Cabin feature에 각 약 20%, 약78%의 결측치가 있음을 볼 수 있습니다.
f, ax = plt.subplots(1, 2, figsize=(18, 8))
df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('pie plot - Survived')
ax[0].set_ylabel('')
sns.countplot('Survived', data=df_train, ax=ax[1])
ax[1].set_title('count plot - Survived')
plt.show()Output:
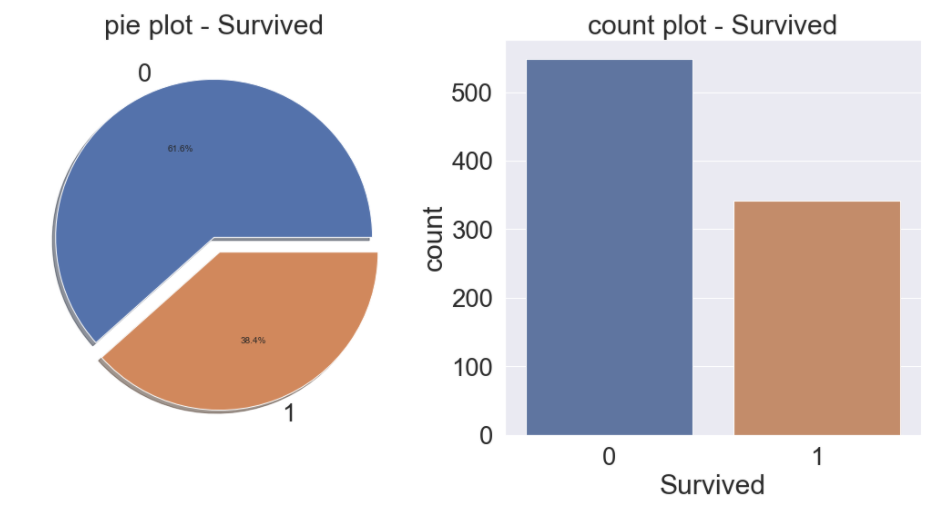
우리의 목표는 Test set 데이터에 존재하는 Passenger의 Survived 값이 0인지 1인지를 예측하는 것입니다.
먼저 Train set 데이터에서 Survived feature의 비율을 확인해보았습니다.
0인 값이 61.6%, 1인 값이 38.4%의 비율로 생존한 비율이 더 낮다는 걸 볼 수 있습니다.
