참고한 커널을 거의 Copy한 정도이기 때문에 학습 등의 목적을 가지고 계신 분은 참고한 커널 Kaggle 공개 커널, 곽대훈님의 데이터 분석 어떻게 시작해야 하나요?로 이동해주세요.
이 글은 캐글 타이타닉으로 기초 쌓기 #3와 이어지는 내용입니다.
3. 특성 공학 (Feature Enginnering)
특성 공학이란 특정한 기능(AI 알고리즘 적용, 빅데이터 분석 등)을 수행하기 위해 데이터에 대한 지식을 활용하여 feature를 생성하거나 정제(가공)하는 과정을 이야기합니다.
가장 먼저 데이터 셋에 존재하는 null 데이터를 존재하는 값으로 채워주려고 합니다.
아무 의미없는 숫자로 채우면 안되고 해당 feature의 Statistics를 참고하거나 좋은 아이디어를 적용해서 채워야 합니다.
특히, feature enginnering은 실제 모델 학습에 사용하려고 진행하는 과정이기 떄문에 train dataset뿐 아니라 test dataset도 똑같이 적용해주어야 합니다!! 꼭 잊으면 안됩니다.
3.1 Fill Null
3.1.1 Fill null in Age using title
Age feature의 데이터가 null인 수가 177이나 됩니다.
177개의 null 데이터를 채울 수 있는 여러가지 아이디어가 있을텐데 참고 커널의 작성자는 데이터셋의 이름에 포함되어 있는
title(영어권에서 사용하는 Mr, Miss 등)을 이용합니다.
pandas series에는 data를 string으로 변환해주는 str 메소드와 정규표현식을 적용할 수 있게 해주는 extract 메소드가 있습니다.
두 메소드를 활용하여 title을 쉽게 추출할 수 있습니다.
title을 Initial이라는 이름의 column에 저장합시다.
그리고 pandas의 crosstab을 통해 추출한 Initial과 Sex간의 수를 살펴봅시다.
이름이 잘못 적혀져 있거나 성별을 잘못 분류했을 수도 있으니까 살펴봅니다.
df_train['Initial'] = df_train.Name.str.extract('([A-Za-z]+)\.')
df_test['Initial'] = df_test.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(df_train['Initial'], df_train['Sex']).T.style.background_gradient(cmap='summer_r')Output:

df_train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don', 'Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr', 'Mr'],inplace=True)
df_test['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don', 'Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr', 'Mr'],inplace=True)
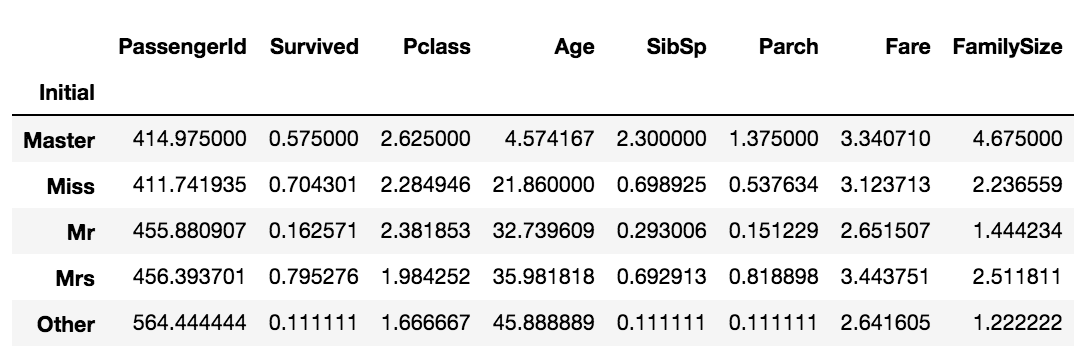
df_train.groupby('Initial').mean()Output:
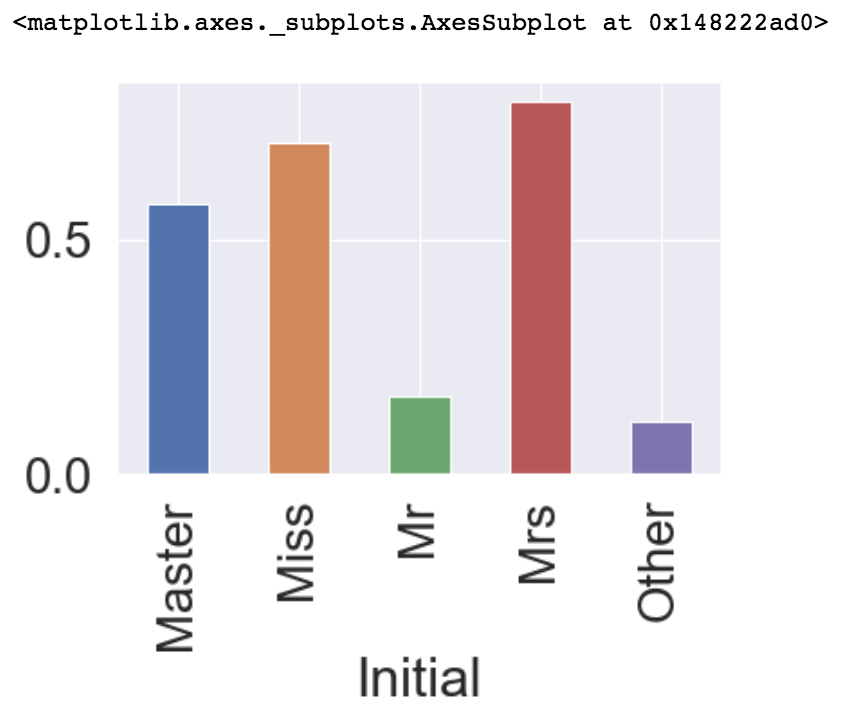
df_train.groupby('Initial')['Survived'].mean().plot.bar()Output:
이제 값을 변환했으니 Null 값을 채울 차례입니다.
Null 데이터를 채우는 방법은 매우 많은데 참고 커널의 작성자는 Statistics를 활용하는 방법을 사용합니다.
여기서 Statistics는 train data의 것을 의미합니다.
우리는 항상 test dataset을 unseen으로 두어야 합니다.
따라서, train dataset에서 얻은 statistics를 기반으로 Null 데이터를 채워주어야 합니다.
위의 mean 메소드를 통해 각 Initial feature 값의 평균을 알아내었습니다.
이를 이용하여 null 데이터를 passenger의 Initial 평균 값으로 채워줍시다.
df_train.loc[(df_train.Age.isnull()) & (df_train.Initial=='Mr'), 'Age'] = 33
df_train.loc[(df_train.Age.isnull()) & (df_train.Initial=='Mrs'), 'Age'] = 36
df_train.loc[(df_train.Age.isnull()) & (df_train.Initial=='Master'), 'Age'] = 5
df_train.loc[(df_train.Age.isnull()) & (df_train.Initial=='Miss'), 'Age'] = 22
df_train.loc[(df_train.Age.isnull()) & (df_train.Initial=='Other'), 'Age'] = 46
df_test.loc[(df_test.Age.isnull()) & (df_test.Initial=='Mr'), 'Age'] = 33
df_test.loc[(df_test.Age.isnull()) & (df_test.Initial=='Mrs'), 'Age'] = 36
df_test.loc[(df_test.Age.isnull()) & (df_test.Initial=='Master'), 'Age'] = 5
df_test.loc[(df_test.Age.isnull()) & (df_test.Initial=='Miss'), 'Age'] = 22
df_test.loc[(df_test.Age.isnull()) & (df_test.Initial=='Other'), 'Age'] = 46Age feature의 null 데이터를 모두 채웠으니 다른 어떤 feature가 null 데이터가 있는지 알아봅시다.
df_train.isnull().sum()[df_train.isnull().sum() > 0]
df_test.isnull().sum()[df_test.isnull().sum() > 0]Output[0]:
Cabin 687
Embarked 2
dtype: int64
Output[1]:
Cabin 327
dtype: int64
Embarked feature에 null데이터가 train dataset에만 2개 있고, Cabin feature는 각각 trainset에 687개 testset에 327개 있다.
딱 2개 있는 Embarked feature의 null 데이터부터 채워주고 필요없어 보이는 Cabin feature는 추후에 날려주겠습니다.
3.1.2 Fill Null in Embarked
Embarked feature는 null 데이터가 2개이고, S에서 가장 많은 승객이 탑승했으니 간단하게 S로 채워주겠습니다.
df_train['Embarked'].fillna('S', inplace=True)
df_train.isnull().sum()[df_train.isnull().sum() > 0]Output:
Cabin 687
dtype: int64
3.2 Change Age (continuous to categorical)
Age는 현재 연속적인 feature입니다. 그대로 사용해서 모델을 세울 수 있지만 Age를 몇 개의 group으로 나누어 카테고리화 시켜줄 수 있습니다.
연속적인 feature를 카테고리화하면 자칫 information loss가 발생할 수도 있습니다.
참고 커널에서는 다양한 방법을 소개해주는 것이 목적으로 진행하였기 때문에 같이 진행하도록 하겠습니다.
DF의 indexing 방법인 loc를 사용하여 직접해줄 수 있고, 아니면 apply를 사용해 함수를 넣어줄 수는 등의 여러가지의 방법이 있다고 합니다.
loc 예제는 위의 age mean 값을 채워주었을 때 사용해보았으므로 이번에는 apply를 사용해보도록 하겠습니다.
def category_age(x):
if x < 10:
return 0
elif x < 20:
return 1
elif x < 30:
return 2
elif x < 40:
return 3
elif x < 50:
return 4
elif x < 60:
return 5
elif x < 70:
return 6
else:
return 7
df_train['Age_cat'] = df_train['Age'].apply(category_age)
df_test['Age_cat'] = df_test['Age'].apply(category_age)
df_train.groupby(['Age_cat'])['PassengerId'].count()Output: Age_cat
0 66
1 102
2 256
3 304
4 89
5 48
6 19
7 7
Name: PassengerId, dtype: int64
파생 feature를 생성했으므로 기존 feature인 Age를 제거하는 것이 맞겠지만 참고 커널의 작성자는 상관 관계가 높아도 모델의 설명력(성능)에 도움이 될 수 있으니 남겨 진행하였기에 저도 남기겠습니다.
3.3 Change Initial, Embarked and Sex (string to numerical)
현재 Initial featuresms Mr, Mrs, Miss, Master, Other 총 5가지의 string type 데이터로 이루어져 있습니다.
이런 카테고리 데이터를 모델에 입력값으로 넣어줄 때 컴퓨터가 쉽게 인식할 수 있도록 수치화 시켜주는 것입니다.
map 메소드를 이용하여 매핑을 진행하겠습니다.
Sex와 Embarked feature들도 같은 과정을 진행하겠습니다.
df_train['Initial'] = df_train['Initial'].map({'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
df_test['Initial'] = df_test['Initial'].map({'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
df_train['Sex'] = df_train['Sex'].map({'female': 0, 'male': 1})
df_test['Sex'] = df_test['Sex'].map({'female': 0, 'male': 1})
df_train['Embarked'] = df_train['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
df_test['Embarked'] = df_test['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})이제 각 feature 간의 상관관계를 확인해보려고 합니다.
두 변수간의 Pearson correlation을 구하면 (-1, 1) 범위의 값을 얻을 수 있습니다.
- -1로 갈수록 음의 상관관계
- 1로 갈수록 양의 상관관계
- 0이 가까울 수록 상관관계가 없음
seaborn의 heatmap을 통해 시각화를 진행해보겠습니다.
heatmap_data = df_train[['Survived', 'Pclass', 'Sex', 'Fare', 'Embarked', 'FamilySize', 'Initial', 'Age_cat', 'Age']]
colormap = plt.cm.RdBu
plt.figure(figsize=(14, 12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr(), linewidths=0.1, vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True, annot_kws={"size": 16})
del heatmap_data
plt.show()Output:
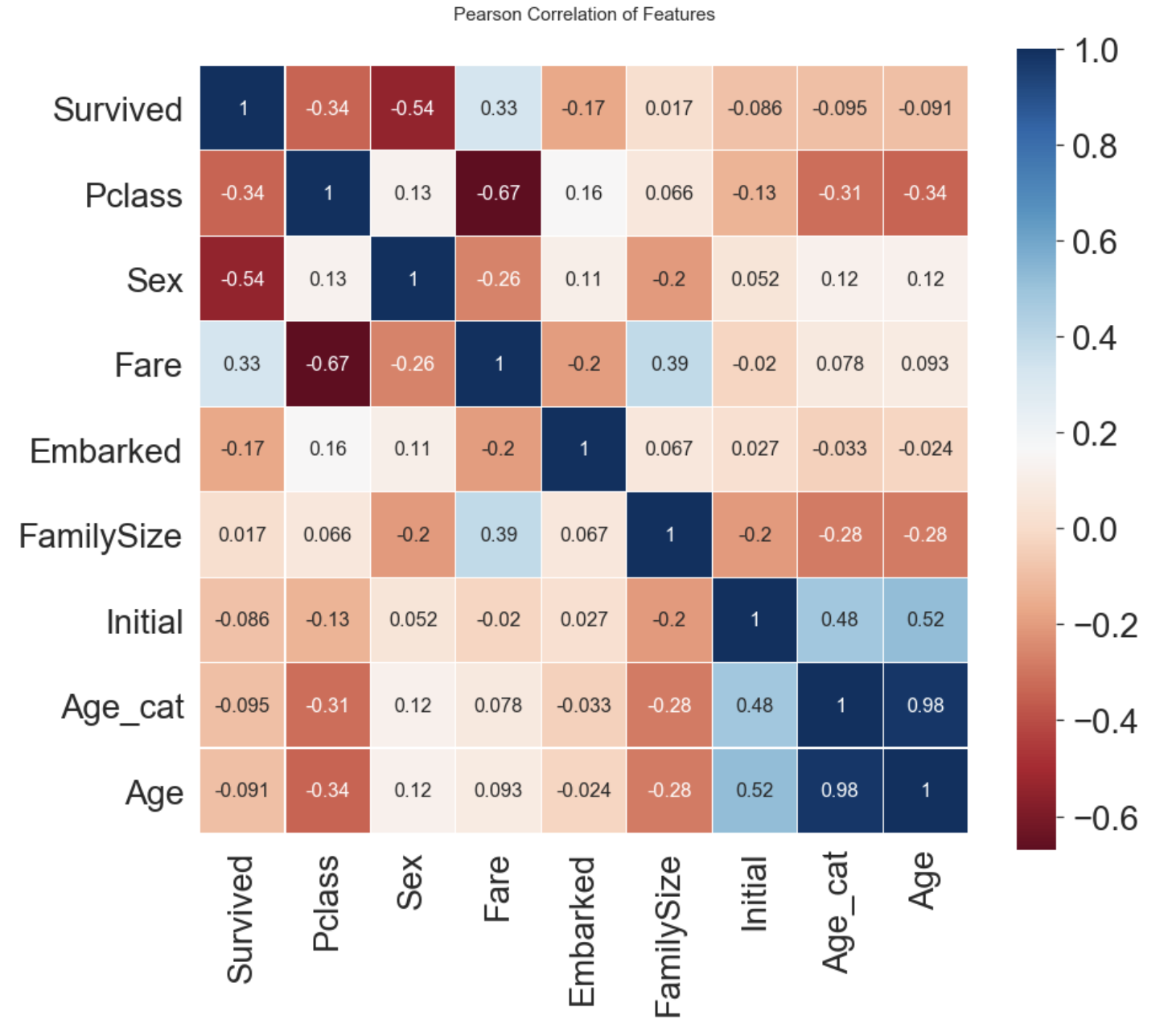
앞서 EDA에서 보았던 feature간 상관관계가 어느 정도 있는 것을 볼 수 있습니다.
heatmap을 보고 얻을 수 있는 또 하나의 정보는 서로 강한 상관관계를 가지는 feature들이 없다는 것입니다.
(Age - Age_cat 제외)
이 사실은 모델을 학습시킬 때 불필요한 feature가 없다는 것을 의미합니다. 강한 상관관계(1또는 -1)를 가진 두 feature가 있다면, 두 feature를 통해서 얻을 수 있는 정보는 하나일테니까요.
이제 모델 학습을 하기 전 data preprocessing(데이터 전처리)를 진행해봅시다.
3.4 One-hot encoding on Initial and Embarked
수치화를 진행한 카테고리 데이터를 그대로 모델에 사용해도 되지만 모델의 성능을 높이기 위해 one-hot encoding을 해줄 수 있습니다.
수치화는 간단하게 Master는 0, Miss는 1, Mr는 2 ... 처럼 매핑해주는 것을 의미합니다.
One-hot encoding은 위 카테고리를 아래와 같이 0또는 1로 이루어진 5차원의 벡터로 나타내는 것을 말합니다.
그렇게 되면 각 클래스간 연관성을 Orthogonal(직교, 동일하게) 만들 수 있습니다.
그래서 각 클래스 간의 상관 관계가 없어집니다.
단순하게 수치화를 했을 경우 Master와 Miss가 가까운 관계, Mrs와 Other이 가까운 관계로 해석될 수 있습니다.
더 자세한 정보는Label Encoding vs One-hot Encoding으로 검색해서 알아봅시다.
위와 같은 작업을 직접 코딩할 수도 있지만 pandas의 get_dummies를 사용하여 쉽게 해결할 수 있습니다.
총 5개의 카테고리니까 One-hot encoding을 하고나면 새로운 5개의 column이 생겨납니다.
Initial을 prefix로 두어서 구분이 쉽게 만들어 줍시다.
df_train = pd.get_dummies(df_train, columns=['Initial'], prefix='Initial')
df_test = pd.get_dummies(df_test, columns=['Initial'], prefix='Initial')
df_train = pd.get_dummies(df_train, columns=['Embarked'], prefix='Embarked')
df_test = pd.get_dummies(df_test, columns=['Embarked'], prefix='Embarked')
df_train.head()Output:
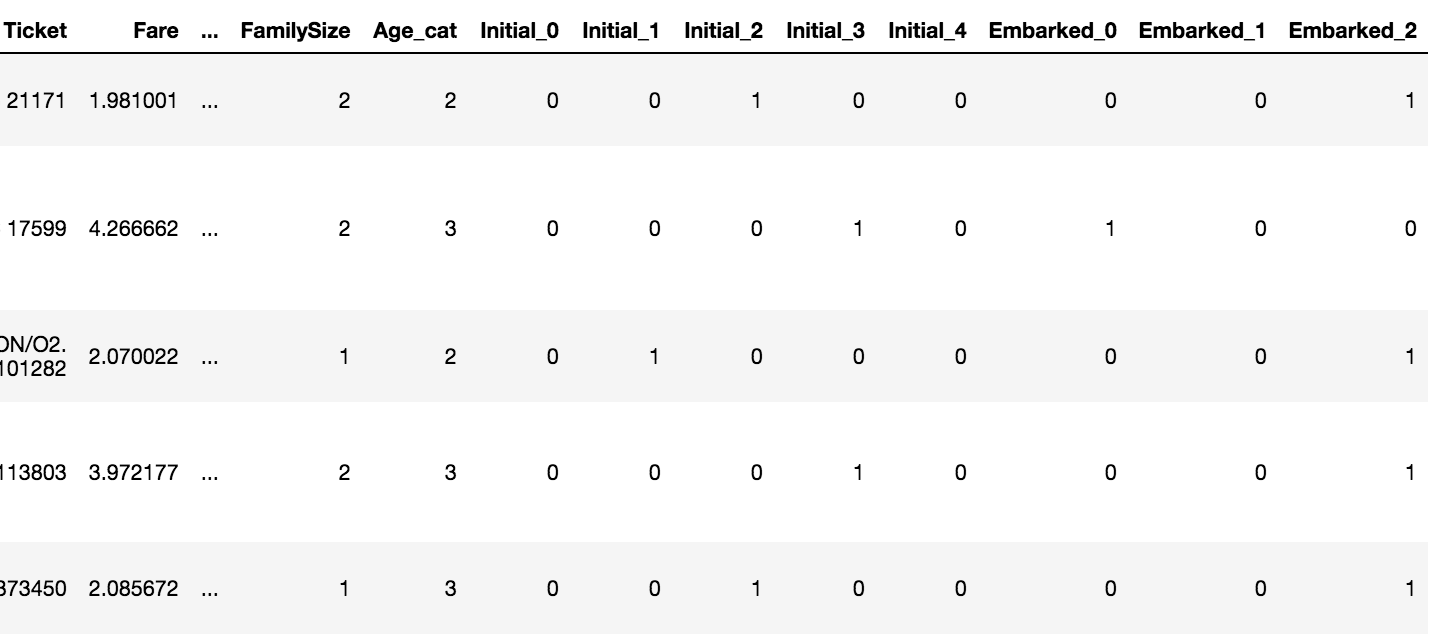
아주 간단하게 One-hot encoding을 적용했습니다!
잘모르겠다 더 알아보자
다른 패키지(sklearn 등)로도 One-hot encoding을 적용할 수 있지만 참고 커널의 작성자는 해당 커널에서 다루지 않았습니다.
가끔 카테고리가 100개가 넘어가는 경우 One-hot encoding을 가용하면 column이 100개가 생겨 학습시 매우 버거울 수 있습니다.(aka. 차원의 저주)
이런 경우에는 다른 방법을 사용하기도 하는데 다른 기회에 더 자세히 알아봅시다!
3.5 Drop columns
이제 마지막 feature engineering으로 필요없는 feature들을 없애버립시다.
- PassengerId, Cabin, Ticket - 영향(필요)이 거의 없는 feature
- Name - feature engineering 단계에서 Sex feature의 데이터를 채울 때 사용하고 이제 필요가 없습니다.
- SibSp, Parch - 두 feature 데이터 값을 더해서 FamilySize이름의 새 Feature를 생성하고 이제 필요가 없습니다.
df_train.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)
df_test.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)
df_train.dtypes
df_test.dtypesOutput[0]: Survived int64
Pclass int64
Sex int64
Age float64
Fare float64
FamilySize int64
Age_cat int64
Initial_0 uint8
Initial_1 uint8
Initial_2 uint8
Initial_3 uint8
Initial_4 uint8
Embarked_0 uint8
Embarked_1 uint8
Embarked_2 uint8
dtype: object
Output[1]: Pclass int64
Sex int64
Age float64
Fare float64
FamilySize int64
Age_cat int64
Initial_0 uint8
Initial_1 uint8
Initial_2 uint8
Initial_3 uint8
Initial_4 uint8
Embarked_0 uint8
Embarked_1 uint8
Embarked_2 uint8
dtype: object
Survived(target) feature를 제외하면 train, test 데이터 셋이 같은 column을 가진 것을 확인 할 수 있습니다.
