Gradient Descent
Why?
딥러닝 모델의 손실함수는 매우 복잡하고, 이러한 식의 최솟값을 바로 구하는 것은 힘들다.
How?
각 가중치로 편미분한 값이 가리키는 손실이 줄어드는 방향으로 단계별로 가중치를 변경하면서 손실함수의 값을 줄여가며 학습한다.
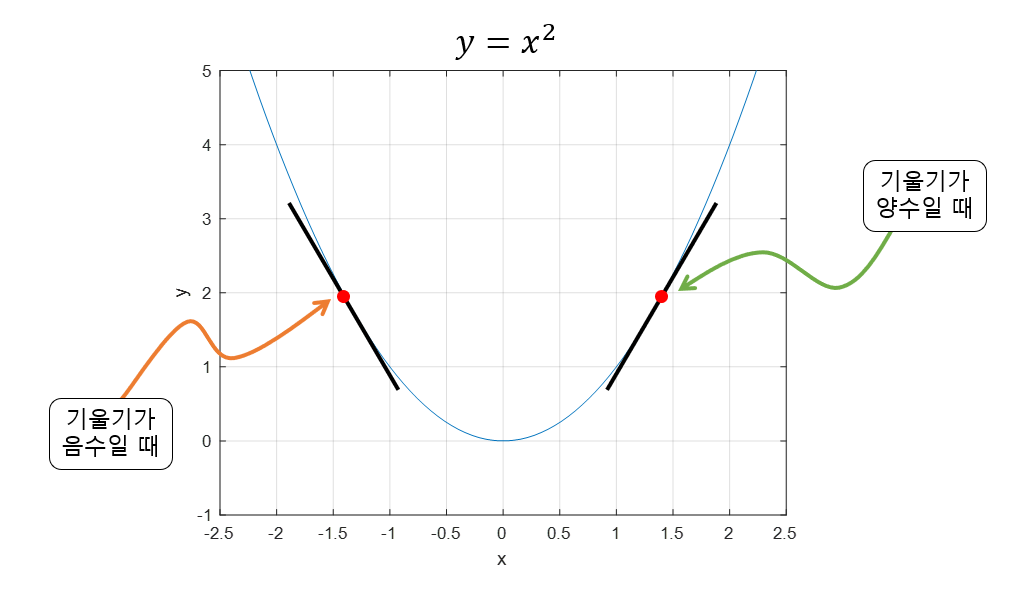
Q. 왜 -부호를 사용하는가?
기울기가 음수일때는 양의 방향으로 조정해야하고, 기울기가 양수라면 음의 방향으로 조정해야한다.
Backpropagation
Why?
그래디언트 계산의 편리함을 위하여 사용한다.
How?
최종적으로 나온 오차에서부터 앞단으로 각 노드별로 미분을 진행하고 이를 곱해가며 각 노드에서의 그래디언트를 구한다. chain rule의 원리를 사용한다.
Optimizer
What?
Gradient Descent를 더욱 잘하기 위한 장치이다.
How?
학습률을 조정하는 방법과 모멘텀을 이용하는 방법으로 나뉜다.
학습률을 조정하는 방법(Adagrad)

조정이 많이 된 가중치는 작은 lr을 조정이 안된 가중치는 큰 lr을 적용한다.
모멘텀을 이용하는 방법
바로 방향을 바꾸는 것이 아니라 이전의 방향성과 현재의 방향성을 더하여 적용하는 방식

이 두가지 방법을 모두 적용한 것이 Adam optimizer이다.
참고

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.