ILP를 위한 컴파일러 테크닉
컴파일러 방식과 하드웨어 방식
동적으로 instruction을 스케줄링하는 방식
이번 포스팅에서는 지난 ILP 시리즈에 이어 3번째 - dynamic instruction scheduling에 대해 정리한다.
CPI stall = CPI_structural hazard + CPI_data hazard + CPI_control hazard
지난 포스팅에서는 control hazard를 줄이기 위한 여러 방법들(dynamic branch prediction)에 대해 정리하였고, 그 전에는 data hazard를 줄이기 위한 방법으로 loop unrolling(static한 방식)을 정리하였다.
Dynamic Scheduling 방법을 통해서 알아볼 내용은 "하드웨어가 어떻게 동적으로 instruction을 re-scheduling하여 data hazard와 control hazard를 줄일 수 있는지"에 대한 부분이다.
Dynamic Scheduling
data flow와 exception behavior를 유지하는 범위 내에서 하드웨어적으로 instructions를 re-scheduling하여 stall을 줄이는 방법이다.
Dynamic Scheduling의 장점
- compile time에서 알 수 없는 instruction dependency에 대한 처리를 할 수 있다.
- allows the processor to tolerate unpredictable delays such as cache misses, by executing other code while waiting for the miss to resolve
- 한 파이프라인에서 컴파일된 코드가 다른 파이프라인에서 효율적으로 실행될 수 있게 해준다.
- 컴파일러가 단순해진다.
- Hardware speculation
Dynamic Scheduling 예제
DIVD F0, F2, F4
ADDD F10, F0, F8
SUBD F12, F8, F14DIVD와 ADDD 사이에는 RAW dependence(F0)가 존재하고, SUBD는 위의 두 명령어와 아무런 dependence가 존재하지 않는다. 따라서 SUBD는 먼저 실행되어도 상관 없다. 즉, 이러한 명령어들은 out-of-order execution과 out-of-order completion이 가능하다.
Dynamic Scheduling에서의 ID(Instruction-Decoding)
ID 단계에서는 2가지 작업을 처리한다
1) Instruction Issue: Instruction이 무엇인지 파악(decoding) & dependence 체크
2) Read Operands: data hazard가 없어질 때까지 wait, 이후에 read operands
따라서 Dynamic Scheduling에서는 ID를 위와 같이 2 stage로 쪼갠다.
In-order issue를 해주어야 한다! (out-of-order issue는 x)
DIVD F0, F2, F4
ADDD F10, F0, F2
SUBD F2, F8, F14위와 같이 명령어가 나열된 경우, DIVD에서 F0로 write이 완료되기 전까지는 ADDD에서 F0를 read하지 못한다. 즉, ADDD에서는 F0는 Read Operands 작업이 불가능한 상태이고, F2는 DIVD와 dependence가 없으므로 Read Operands가 가능한 상태이다. 이 때 ADDD의 F0에는 DIVD의 F0 작업이 끝나면 Read Operands를 할거라는 정보가 있는 pointer field를 담아둔다.(Reservation Stations)
그리고 마지막 instruction인 SUBD의 경우, ADDD의 F2가 Read Operands 작업을 하기 전까지는 F2에 write해서는 안된다.
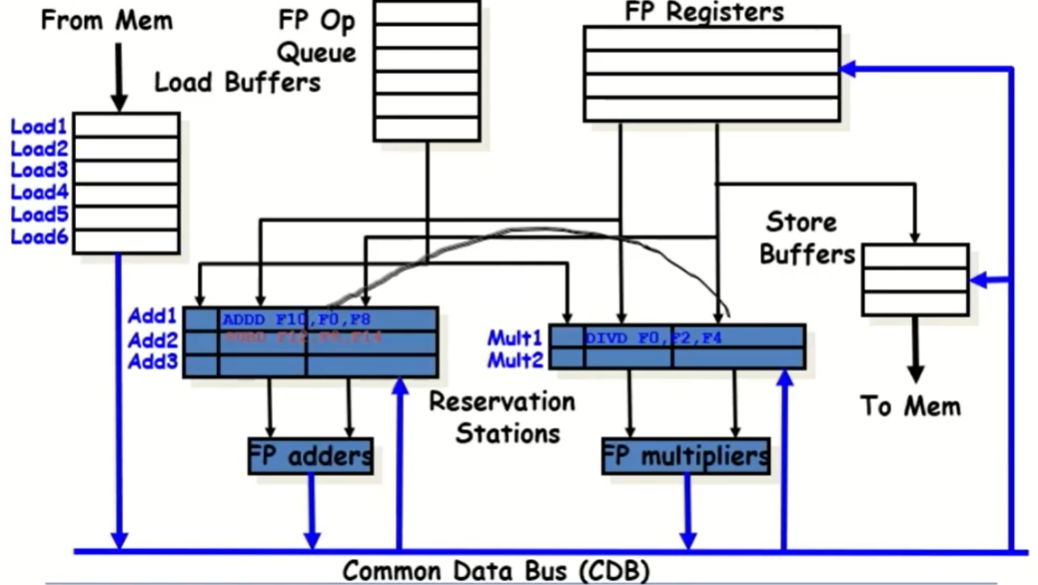
-
Issue단계 : ADDD, DIVD, SUBD와 같은 instructions를 Instruction Queue(FP OP Queue)에서 OP Block(Add1/Add2/Add3/Mult1/Mult2)로 보내주는 작업
-
Read Operands 단계: ADDD는 F0의 값을 읽기 위해 DIVD가 들어있는 Mult1의 위치를 기억해둔다. DIVD가 F0에 값을 write하면, 해당 정보(DIVD의 위치와 F0에 쓰인 값)가 Common Data Bus를 타고 이동하고, Add1에 있던 ADDD는 이 정보를 확인하여 DIVD의 F0에 쓰인 값을 자신의 F0에 저장한다.
Tomasulo Agorithm
Dynamic Scheduling을 위한 알고리즘을 Tomasulo Algorithm이라고 한다.
Tomasulo Algorithm 3단계
- Issue: instruction을 FP Op Queue에서 reservation station으로 가져온다.
- Execute: 만약 두 개의 source operands가 다 준비된 상태라면 execute한다. 준비되지 않았다면 CDB로 흘러나오는 결과들을 계속 모니터링한다.
- Write Result: CDB의 결과를 기다리는 모든 곳에 써주고, reservation station을 비워서 다른 instructions가 issue될 수 있도록 한다.
참고로 Write Result 단계에서는 처음 0.5 cycle은 write 작업을 수행하고, 나머지 0.5 cycle에는 read operand(다른 instruction에서 해당 instruction의 데이터를 읽는다) 작업이 오버랩된다.
일반적으로 CDB에는 "data + destination" 정보가 함께 들어있다. 여기서 destination이란 해당 data의 결과가 만들어진 곳을 의미한다. 예를 들어, Mult1에 있는 DIVD F0, F2, F4가 실행완료되어 F0의 값이 CDB로 나오게 되면, 해당 데이터 버스에는 "F0의 값 + Mult1"이 포함된다. 이후 CDB를 계속 모니터링하고 있던 다른 instructions 중 Mult1의 F0 값이 필요한 instructions는 해당 데이터 버스의 내용을 copy해서 가져오는 read operand 작업을 수행한다.
Tomasulo Algorithm의 특징
-
Tomasulo Algorithm은 out-of-order scheduling을 위한 알고리즘이다.
-
Static한 방식인 Loop Unrolling - loop body를 크게하여 instructions를 rescheduling & branch 수 줄임 - 을 하드웨어적으로 처리하는 것이 Tomasulo Algorithm.
-
사실상 RAW 외의 명령어들은 parallel하게 수행해도 되기 때문에, Tomasulo Algorithm은 기본적으로 true dependence(RAW)만 유지해주고, 나머지 명령어들은 하드웨어가 허락하는 한 빨리 parallel하게 실행시켜주려고 노력함.
-
Reservation Stations에 empty space가 있는 한(entry가 충분히 있는 한), FP OP Queue에 있는 instructions를 Reservation Station으로 보낼 수 있다. 이렇게 함으로써 이전 명령어들이 issue되지 않아 다음 명령어들이 기다려야 하는 문제를 해결함.
-
true dependence(RAW)가 있는 명령어들은 reservation stations에 머무르면서 read operands를 기다리는 구조
Reservation Stations의 7가지 fields
| field | description | example |
|---|---|---|
| OP | source operand S1과 S2에 적용할 operation | ADDD, MULTD |
| Qj, Qk | source operand. 아직 값이 만들어지지 않은 경우, Qj, Qk에 포인터 값이 저장됨 | Mult1, Add3 |
| Vj, Vk | source operand. 이미 값이 만들어진 경우, Vj, Vk에 유효한 값이 저장됨 | |
| A | 메모리 주소. Load, Store할 때만 사용 | |
| Busy | 사용 중인지 표시하는 flag |
Qj에 어떤 포인터 값이 들어가있으면 Vj에는 값이 들어가지 않고, 반대로 Vj에 어떤 유효한 값이 들어가있으면 Qj에는 값이 들어가지 않는다.(Q와 V 중 하나만 채워짐)
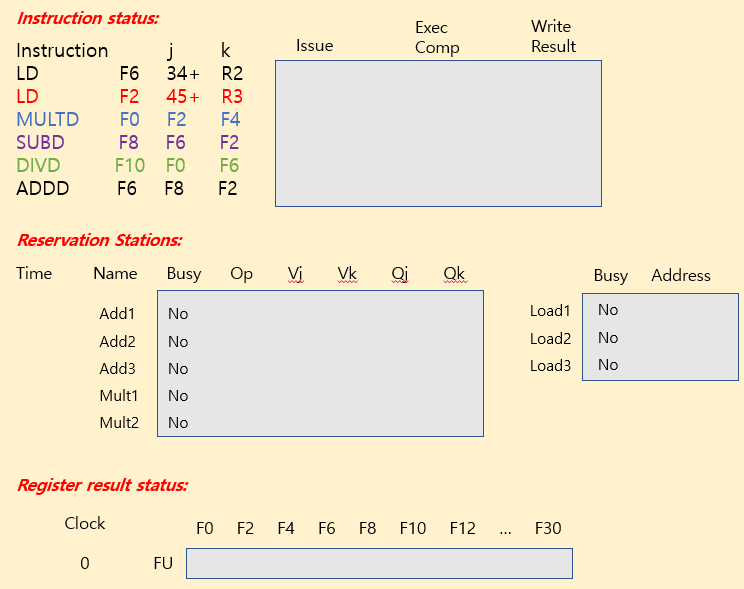
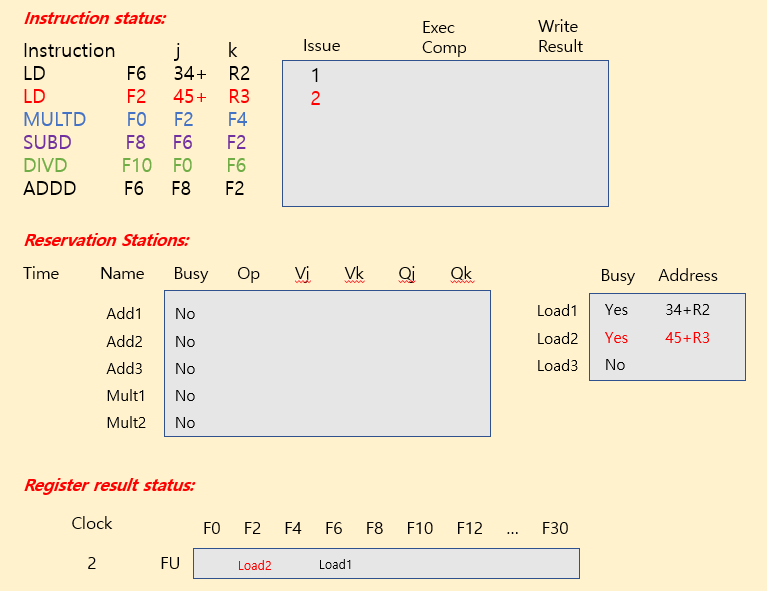
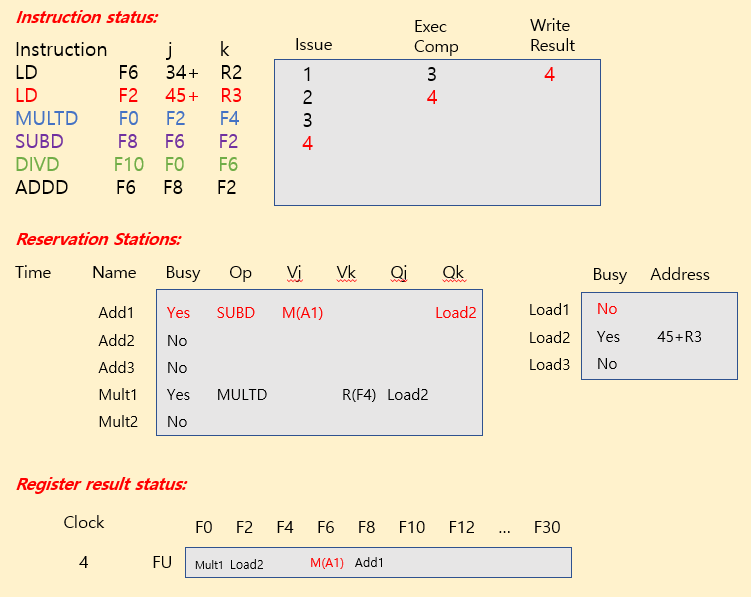
Tomasulo Example
| operation | clock cycle |
|---|---|
| FP add / sub | 2 clocks |
| FP mult | 10 clocks |
| FP div | 40 clocks |
| load | 2 clocks |


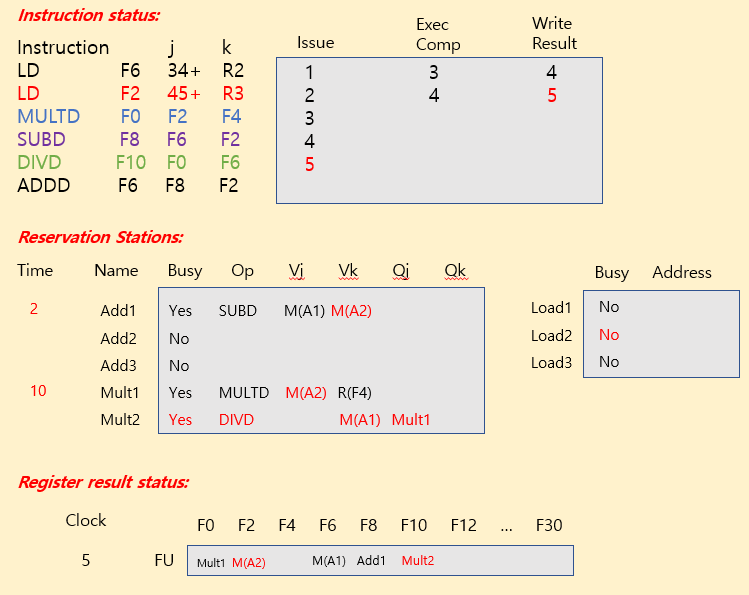

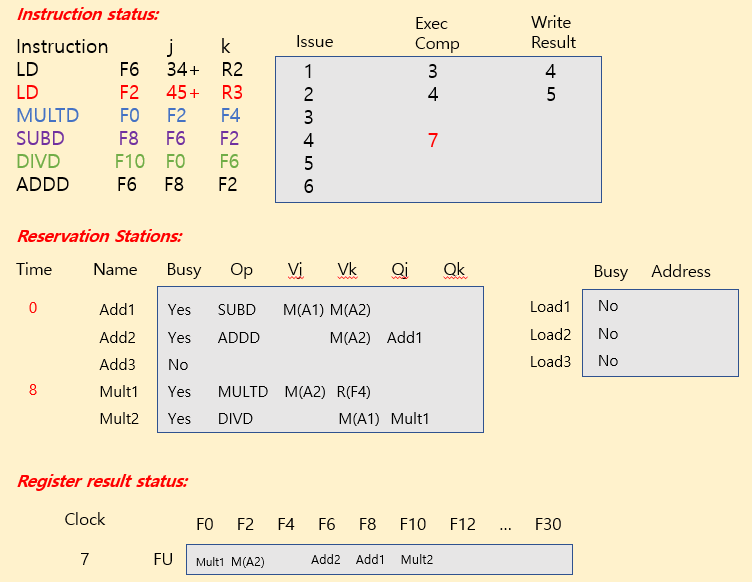
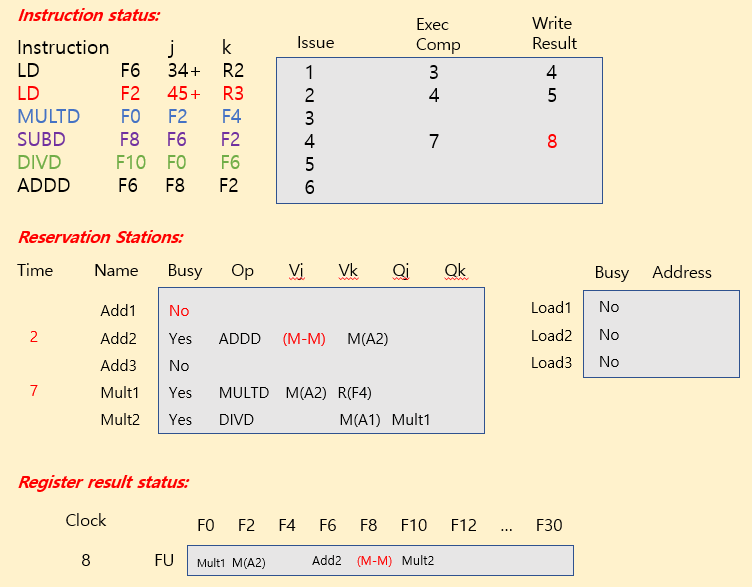
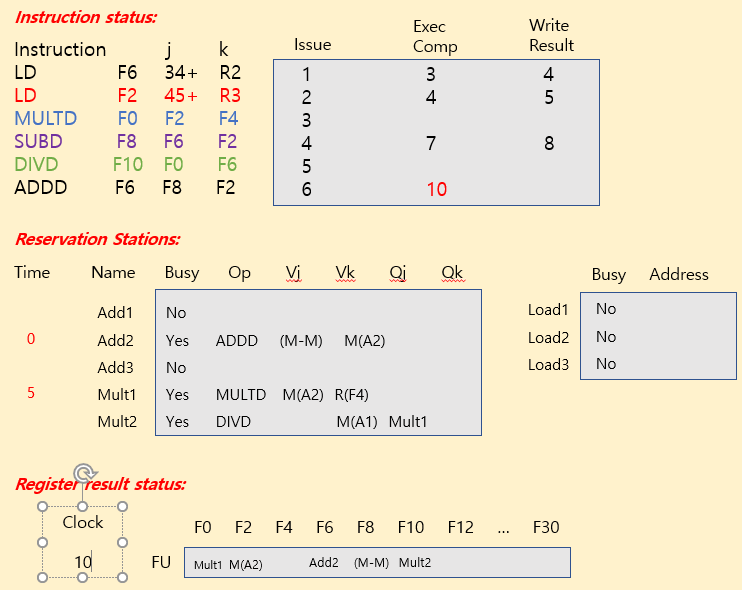
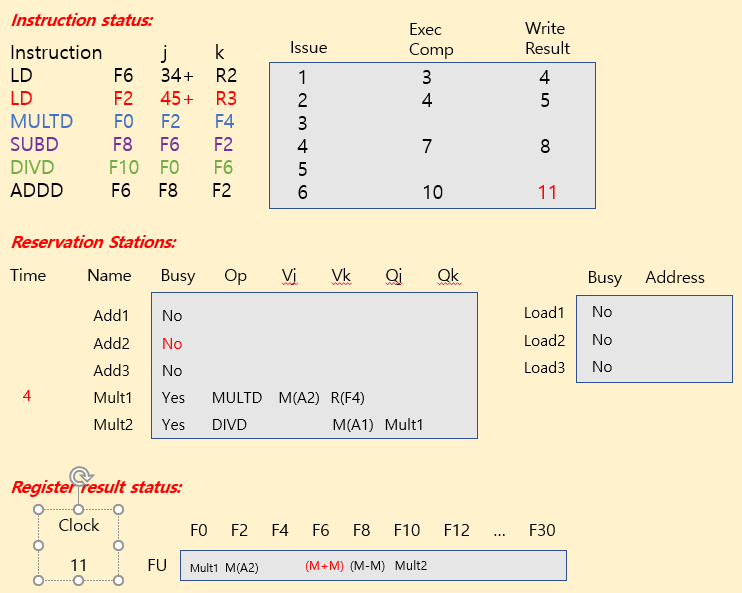
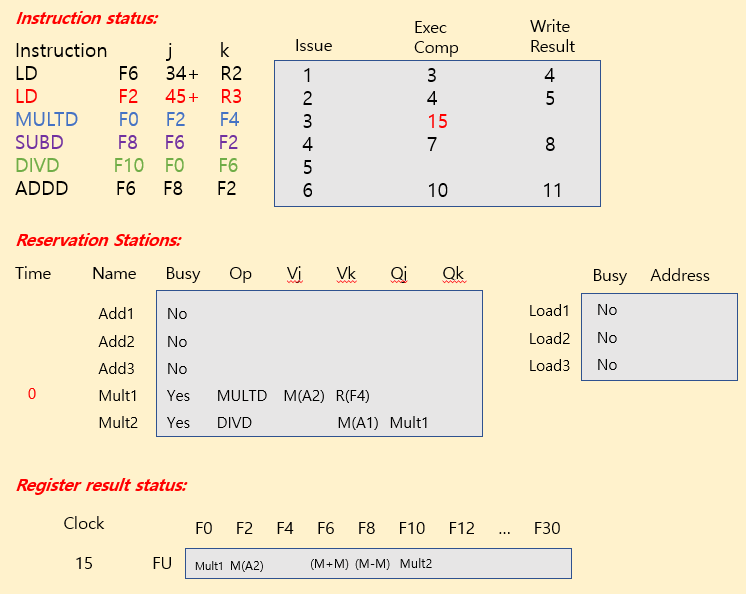
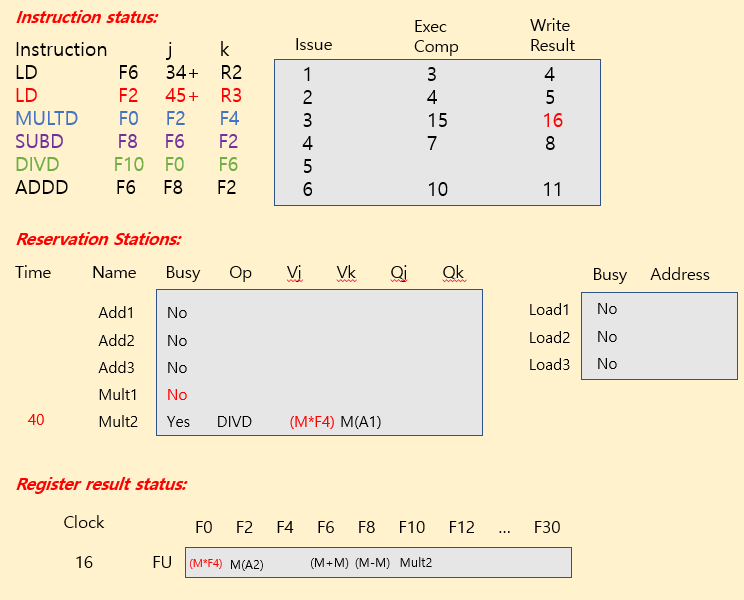
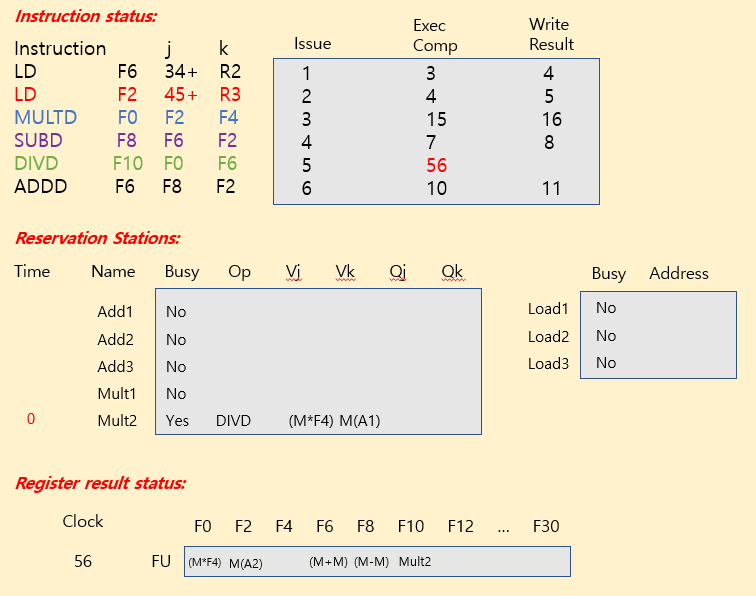
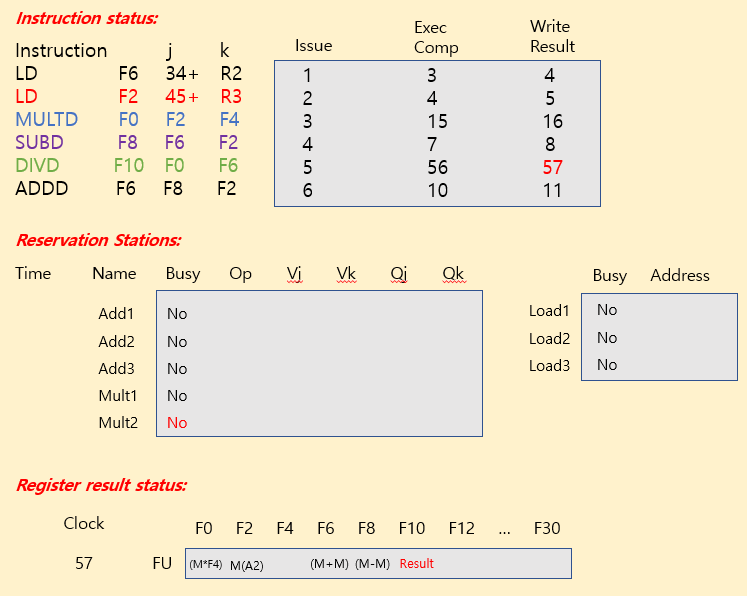
※ Summary
- Tomasulo: Issue - Execute - Write Back
- In-order issue
- 나머지는 out-of-order 가능
- CDB에는 data + destination 정보가 포함
+) 추가
static scheduling과 dynamic scheduling을 간략히 비교
1. Static한 방식: Loop Unrolling
- CPI = CPI_base + CPI_stall
- CPI_stall = structural stall + data stall + control stall + memory stall
- Loop Unrolling은 data hazard나 control hazard를 줄이는 방법이다.
- Loop Unrolling을 할 때는 register renaming을 compiler 차원에서 수행한다. 이 때 compiler는 여분의 register를 활용한다. 만약 register renaming을 해주지 않는다면, WAR이나 WAW hazard 발생으로 인해 성능이 저하될 수 있다.
2. Dynamic한 방식: Tomasulo Algorithm
- Tomasulo 알고리즘 역시 data / control hazard를 줄이기 위한 방법이다.
- Tomasulo에서 register renaming은 컴파일러에서 수행해주지 않는다. Tomasulo에서는 reservation station에 있는 virtual register들이 register renaming과 같은 역할을 해준다.
+) register renaming은 WAW나 WAR과 같은 data hazard가 발생하지 않게 함으로써 성능을 높여주는 역할을 한다.
Tomasulo 알고리즘의 장점
Tomasulo의 2가지 주요 장점 (static scheduling에 비교해서 더 좋은 이유)
1. hazard detection logic이 distribute되어 있다.
- instruction간의 dependence가 존재할 때 => 한 instruction의 연산이 끝나면 Control Data Bus를 통해 해당 instruction과 dependence가 있으면서 reservation station에 존재하는 모든 instruction들에게 parallel하게 정보를 뿌려줌. (성능 향상)
2. register renaming 효과를 통해 WAW나 WAR hazard로 인한 stall을 제거
Tomasulo의 문제점(결함)
1. Complexity
- 기존에 봤던 간단한 5 state MIPS pipeline과 같은 것들보다는 회로 및 메커니즘이 복잡한 편이다.
2. 동시 comparison으로 인한 cost가 매우 크게 발생
- 한 instruction의 execution이 끝나고 결과가 CDB를 통해 reservation stations에 있는 다른 instructions로 전달될 때, 해당 instructions에 대해 parallel한 비교가 수행된다. 이 때 발생하는 cost가 매우 큰 편이다.
- 심지어, 같은 cycle에 execution이 complete되는 instructions가 존재할 수 있으므로, CDB가 여러개 필요하다. 다수의 CDB를 필요로할 경우, parallel한 associative stores를 위해 더 많은 FU logic이 필요하게 되므로 역시 cost가 증가하게 된다.
※ Summary
- 성능 향상: Instruction Level Parallelism
1) static한 방법으로 ILP 향상: Loop Unrolling & Branch Prediction
2) dynamic한 방법으로 ILP 향상: Tomasulo Algorithm
