개요
앞서 본 Tomasulo 알고리즘에서는 branch prediction이 100% accurate 하다고 가정했었다. 따라서 Tomasulo의 유일한 문제점으로는 RAW 문제만 존재했다. 즉, instruction을 execute하는데 필요한 operand가 아직 준비되지 않았을 경우에 대한 문제만 고려해주면 되었다. 만약 Tomasulo 알고리즘이 적절하게 설계되어 있다면, RAW hazard를 제외한 다른 어떤 것도 program의 성능을 저하시킬 수 없다.
하지만 사실상 branch는 100%로 accurate하게 predict될 수 없다. 즉, 우리는 branch prediction이 accurate하지 않을 경우 역시 고려해주어야 한다.
기존의 Tomasulo 알고리즘은 branch prediction이 완벽하다는 가정하에 살펴보았다. 하지만 실제로는, 만약 branch prediction이 정확하지 않아서 이후에 잘못된 instruction이 fetch되는 상황이 발생할 수 있다. 이러한 경우, 오류를 정정하기 위해 이전 상태로 되돌아가는 일종의 rollback작업이 필요하다. 이러한 메커니즘을 위해 Speculation이라는 개념을 공부한다.
Speculation (예측) - branch prediction**
Q. branch prediction이 틀리면 어떻게 해야되는가?
A. 기본 아이디어 - rollback(잘못 fetch된 instruction을 버리고, 이전 상태로 되돌아가야 함)
rollback 여부를 결정하는 요인
컴퓨터 시스템에서는 이전 상태로 되돌아갈 수 있는지 없는지에 대한 여부가 다음 특징에 의해 결정된다.
instruction의 execution 결과로 나온 값이 아직 register나 memory에 업데이트 되지 않아야 한다. 즉, ALU operation이나 Store instruction의 결과가 register나 memory에 write되는 현상을 막아주는 메커니즘이 필요하다.
하지만 이렇게 될 경우, 해당 instruction과 dependent한 다른 instructions는 필요한 operand를 받지 못하게 된다. 이를 막기 위해 out-of-order execution으로 인해 만들어지는 결과들을 임시로 저장할 수 있는 temporal storage가 필요하다. (Reorder Buffer)
자세한 내용은 아래에서 다룬다.
Speculation
-
Speculation(Prediction)
: Branch Prediction이 항상 수행된다는 가정 하에 instructions를 fetch, issue, execute해주는 것이다. -
Dynamic Scheduling
: instructions를 out of order로 execute/complete할 수 있다는 개념이다. -
Speculative Tomasulo
: Speculation + Dynamic Scheduling ☞ 굉장히 강력한 ILP 실현 (성능 향상)
[HW-based Speculation의 3가지 components]
1. Dynamic Branch Prediction
: branch 직후에 어떤 instruction을 실행시킬 것인지 선택한다.
2. Reorder Buffer
: Branch Prediction이 정확하게 이루어지지 않고, 잘못된 instruction fetch가 발생할 경우, ILP는 성능에 있어서 상당한 제약이 걸린다. 따라서 Speculation이 제대로 이루어지지 않았을 경우를 대비하여 roll back과 비슷한 기능을 수행할 수 있어야 한다.
3. Schedule different combinations of basic blocks
: 서로 다른 basic blocks 여러개를 parallel하게 scheduling함으로써 성능을 향상시킬 수 있다.
Tomasulo에 Speculation 추가하기 - Speculative Tomasulo
[기존 Tomasulo]
Issue - Execution - Write Back
[Speculative Tomasulo]
Issue - Execution - Write Result - Instruction Commit
-
Issue
: reservation station이 꽉 찬 상태가 아니고 + ROB도 꽉 찬 상태가 아닐 경우 (둘 다 free할 경우) issue가 이루어질 수 있다. -
Execution
: both operands가 둘 다 ready되면 execute한다. 만약 둘 중 하나라도 ready되지 않으면, ready되지 않은 operand의 result 값을 얻기 위해 CDB를 계속 watch한다. -
Write Result - finish execution
: dependent한 instructions를 위해 CDB를 통해 결과 값을 update하는 과정 + reorder buffer에 데이터를 업데이트하는 과정 -
Instruction Commit - update reg&mem with reorder result
: reorder buffer에 있던 내용을 reg나 mem에 업데이트 시키는 과정이다. 즉, branch prediction이 정확하다는 결론이 나오면 그제서야 reg file이나 mem을 업데이트한다. 이 때 주의할 점은, ROB에서 top(큐의 head pointer가 가리키는 위치)에 있는 instruction이면서 ready가 Y여야만 instruction commit이 이루어진다. (ready가 Y이더라도, 해당 instruction이 ROB의 top에 존재하지 않으면 instruction commit이 이루어지지 않는다.) -
Requires additional set of buffers to hold results of instructions that have finished execution but have not committed (ROB - reorder buffer)
-
최신 결과(latest result)는 ROB에 존재한다.
: 기존 Tomasulo에서는 latest result를 얻기 위해 register file만 들여다보면 된다.
: 하지만 Speculative Tomasulo에서는 instruction commits가 일어나기 전까지는 register file에 latest result가 업데이트되지 않는다. 따라서 latest result를 얻기 위해서는 ROB를 먼저 체크해야 한다. 만약 ROB에 값이 존재한다면 해당 값을 참조하고, 그렇지 않을 경우 register file을 들여다보면 된다.
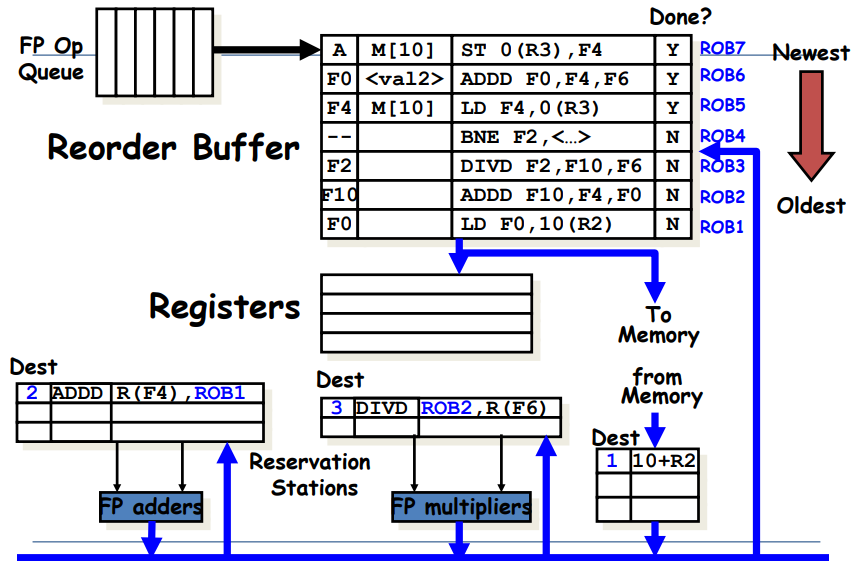
Reorder Buffer
[reorder buffer]
-
out-of-order execution에 대한 결과들이 임시로 저장되는 공간 (reg나 mem이 아직 업데이트되지 않도록 해줌) => FIFO (큐방식)
-
issue 순서대로 reorder buffer를 채워넣는다.
즉, issue단계에서 reservation station도 채우고, reorder buffer도 채운다. -
instruction의 execution이 complete되면, 결과 값이 reorder buffer에 저장된다.
-
Reservation station에 Source ID를 tagging했던 기존 Tomasulo와 달리, ROB를 사용할 때는 ROB buffer number를 이용해 결과 값을 tagging한다.
-
instruction commit이 되면 ROB에 있던 value가 register나 memory로 업데이트된다.
-
결과적으로, mispredicted brach에 대해서 undo 메커니즘을 잘 수행할 수 있다.
-
ROB가 꽉차면 structural hazard로 인해 더이상 instruction issue가 불가능해진다.
[Reorder Buffer Entry]
ROB의 각 entry는 4가지 fields를 포함한다.
1. Instruction type
- branch: destination result가 존재하지 않음 (branch는 mem이나 reg를 업데이트하지 않기 때문)
- store: destination에 memory address가 들어감
- register operation: ALU op나 load와 같은 명령어. register destination이 존재
2. Destination
- register number (ALU op / load)나 memory address(store)가 들어감
- instruction의 결과가 쓰여질 위치를 명시함
3. Value
- instruction의 결과 값이 저장됨 (commit 전까지 임시로 결과 값이 저장될 공간이 필요한데, 그 역할을 value field가 해줌)
4. Ready
- instuction이 execution complete상태이고, value가 ready 상태인지를 나타냄
예제
ROB: 왼쪽부터 순서대로 Destination, Value, Instruction type, Ready field이다.
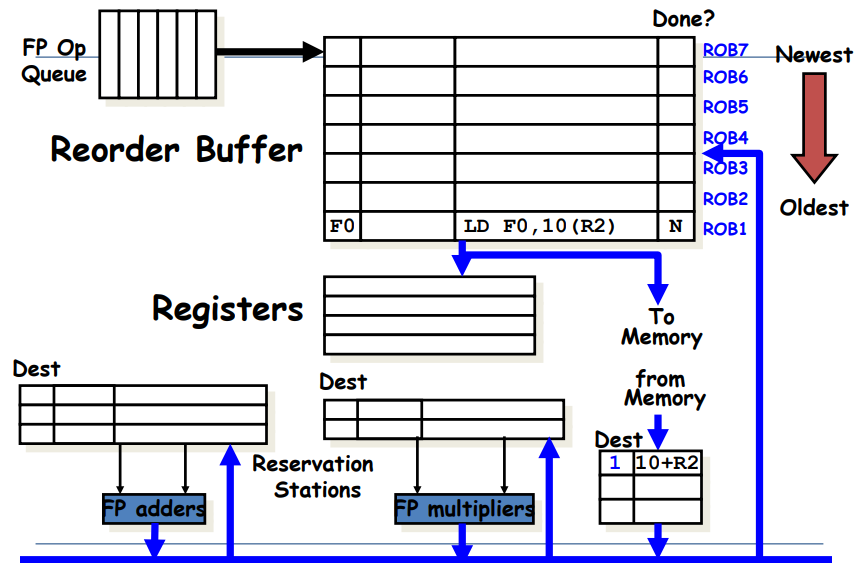
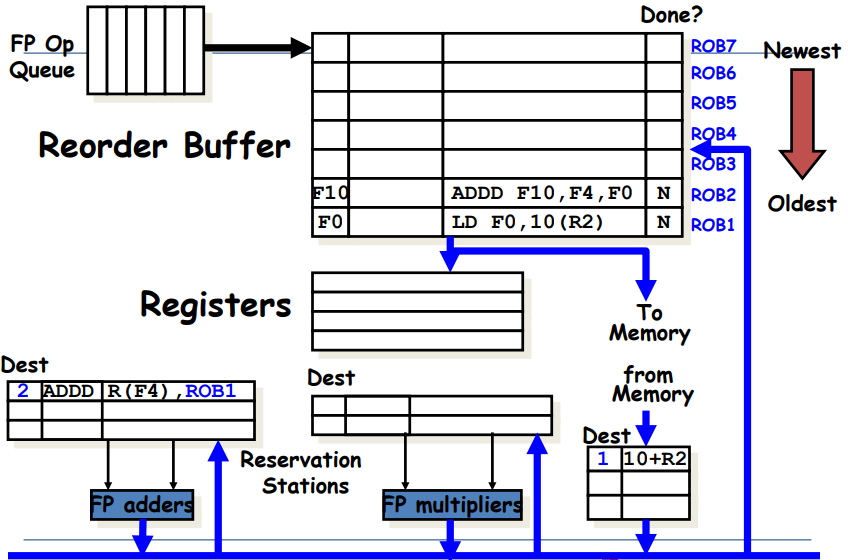


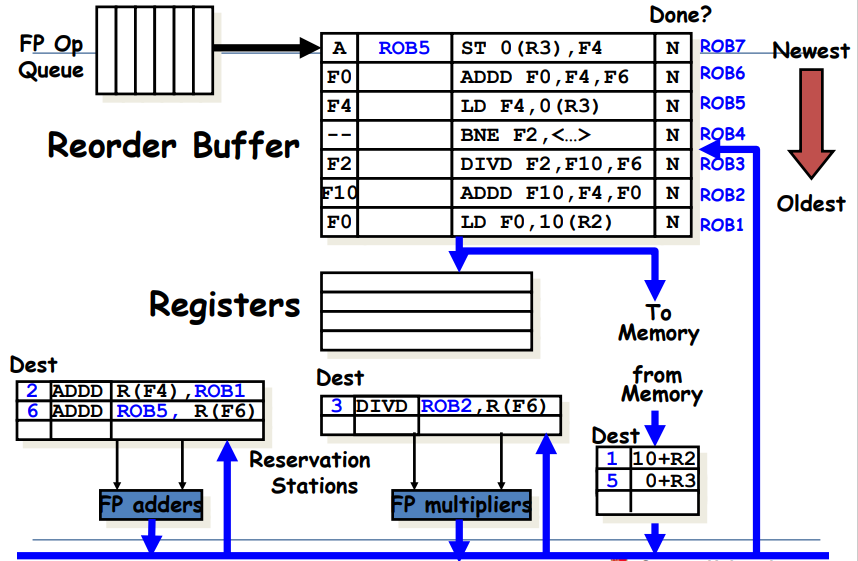
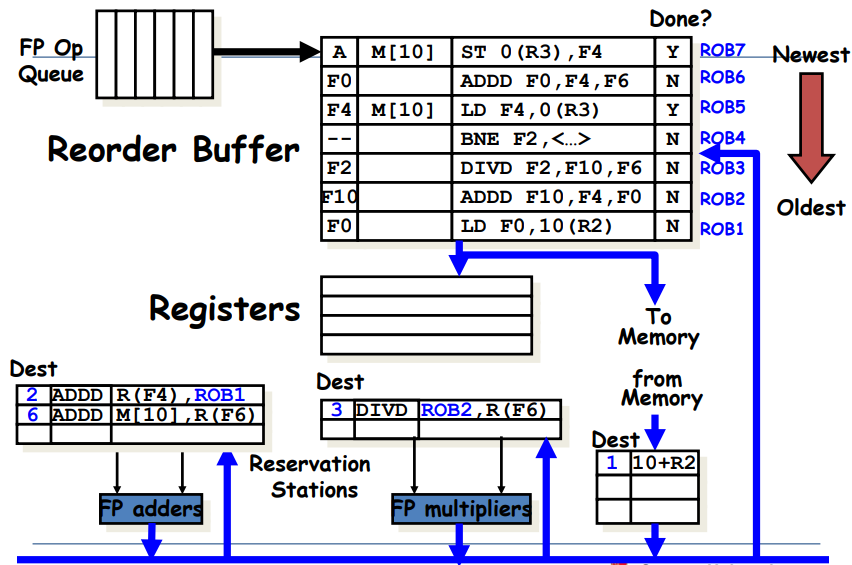
<undo과정>
위 그림에서 head pointer는 맨 밑에를 가리키고, tail pointer는 맨 위를 가리키는 상태라고 해보자. 이 때 만약 Branch가 Mispredict된 상황이라고 하면, Branch부터 그 위에 있는 명령어들은 싹 날려주면 됨. 즉, tail pointer가 BNE를 가리키게 하고, 그 위는 싹 날려버리면 된다.
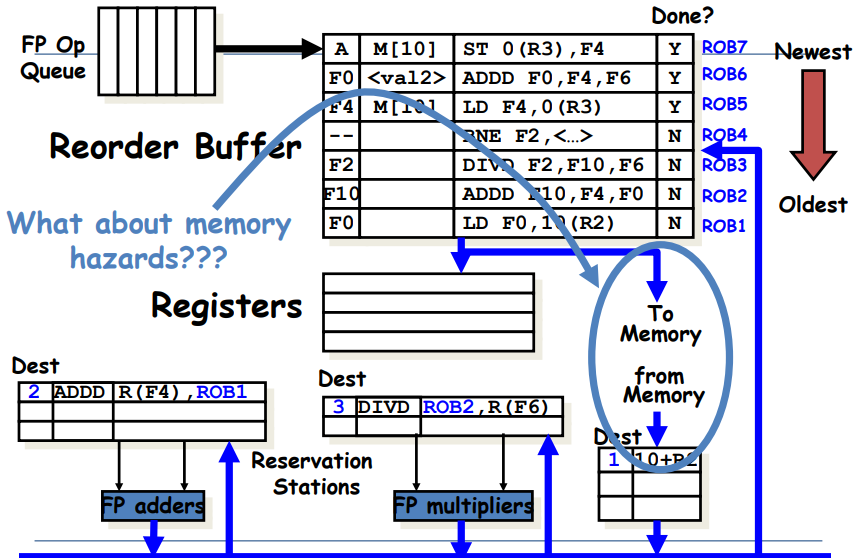
Memory Hazard(RAW / WAR / WAW)
-
Speculative Tomasulo에서는 memory에 대한 WAW나 WAR hazard가 발생하지 않는다.
: 원래는 다수의 sw instructions가 parallel하게 수행됨으로써 같은 위치의 memory를 동시에 업데이트하여 충돌이 일어날 가능성이 있는데, Speculative Tomasulo에서는 ROB를 사용하여 실질적으로 memory가 update되는 과정이 in order로 이루어지게 하였기 때문이다. (Instruction Commit 과정에서) -
memory에 대한 RAW hazard는 두 가지 방법을 이용해 해결될 수 있다.
1) store op가 끝날 때까지 load op가 일어나지 못하게 막는다. 예를 들어, 아래와 같은 순서로 명령어가 수행되는 경우에는 이 방법을 사용할 수 있다.
sw f0, 10($1)
lw f4, 20($4)
이 때 sw와 lw가 접근하려는 메모리 주소가 동일한지 아닌지 알 수 없다. 따라서 이들 사이에 메모리 RAW hazard가 발생할 수도, 아닐 수도 있다. 이를 방지하기 위해 반드시 load보다 store가 먼저 수행-종료되도록 설정한다.
2) load전에 존재하는 모든 store op들에 대해, store가 전부 수행 종료할 때까지 load는 기다리도록 한다.
+) CPI = CPI_base + CPI_stall = 1 + CPI_stall
+) CPI = Cycles Per Instruction
+) IPC = 1/CPI
+) IPC = Instruction Per Cycle (1사이클에 몇 개의 instructions를 실행시킬 수 있는가)
