AlexNet
AlexNet은 Alex Krizhevsky, Ilya Sutskever와 Geoffrey Hinton이 설계한 CNN 아키텍처입니다.
논문의 이름은 저자의 이름을 따서 AlexNet이라 부릅니다.
> 논문 주소 <

컴퓨터 비전 분야의 올림픽이라 불리는 이미지 인식 대회
ImageNet Large Scale Visual Recognition Challenge
ILSVRC의 2012년 우승 결과입니다.
위 사진의 SuperVision이라 쓰여 있는게 AlexNet인데 오차율이 2등과 약 10%정도 차이가 나며 압도적인 성능을 보이는데요, 이 시점부터 딥러닝이 유명해지게 됩니다.
1. 전반적인 아키텍처
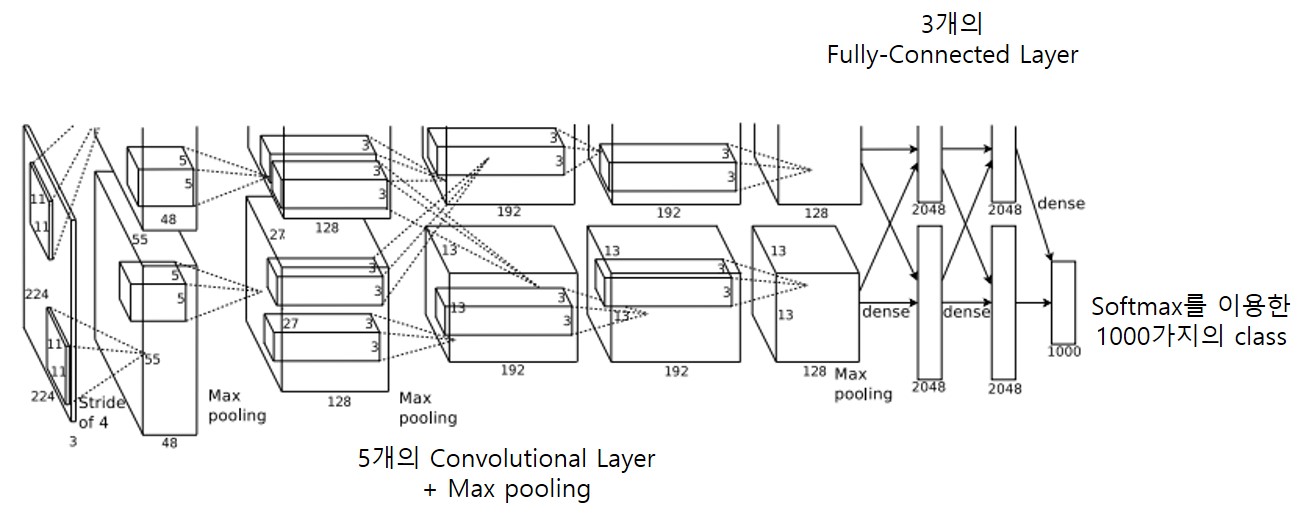
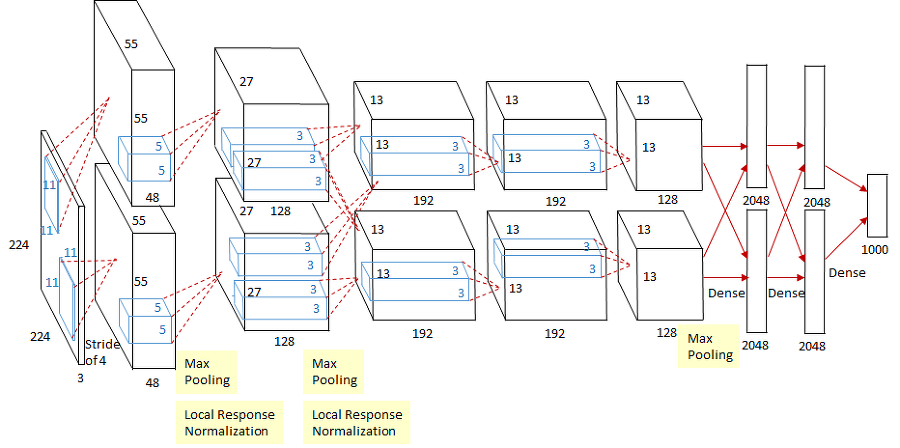
5개의 Convolutional Layer와 3개의 Fully-Connected Layer로 이루어져 있습니다.
연산에 사용한 GPU(GTX 580 3GB)는 2대를 병렬처리를 해 상하로 존재합니다.
활성화 함수로는 ReLU 함수를 사용했고 dropout을 썼다고 합니다.
2. 데이터셋
데이터셋은 ILSVRC 2010년에 쓰였던 set(120만개의 train set, 5만개의 validation set, 15만개의 test set)을 주로 사용했습니다.
전처리의 과정은 이미지넷에서 제공되는 이미지의 사이즈가 각각 다르기 때문에
짧은 면을 기준으로 256픽셀이 되도록 줄이고 그 다음 256x256 사이즈로 잘라냈습니다.
3. 아키텍처
1. ReLU 활성화 함수
2. GPU 2대에서 훈련
3. Local Response Normalization
4. Overlapping Pooling
3-1. ReLU 활성화 함수
예전에는 보통 tanh나 sigmoid같은 활성화 함수를 많이 사용했지만
AlexNet에서는 제프리 힌튼의 ReLU를 사용했습니다.
 (실선이 ReLu, 점선이 Tanh)
(실선이 ReLu, 점선이 Tanh)
위 그래프는 Error rate가 0.25에 도달하기 위한 epoch(학습) 횟수인데요,
ReLU같은 경우는 epoch 6번만에 0.25에 도달했지만 Tanh는 36번만에 도달했습니다. 대략 6배의 속도죠.
ReLU와 Tanh 실험을 할때는 데이터셋을 CIFAR-10 데이터셋을 사용했고
둘다 정규화는 하지 않은 상태에서 학습률은 각자 최적으로 맞춰서 진행했다 합니다.
돌릴때 항상 6배라는 숫자가 나오지는 않았지만 ReLU가 훨씬 더 빠르게 수렴했습니다.
3-2. GPU 2대에서 훈련
GPU 2대를 쓴 이유는 '시간을 줄이기 위해서'보다는 보유한 GPU로는 12000여 장의
더 많은 데이터셋을 돌릴 수가 없어서 메모리가 부족해 GPU 2대를 병렬로 사용했습니다.

- Intra GPU connection :1,2,4,5번째 conv layer에서는 같은 GPU내에서의 커널만 사용 가능
- Inter GPU connection : 3번째 conv layer와 3개의 fc layer에서는 모든 커널 사용 가능
예시로 Conv1에 의해서 커널이 96개가 나온다면 위 gpu1에 48개, gpu2에 48개로
반반 나눠 가집니다. 48개에 대해서 커널을 256을 쓰는데 반반 나뉘어 128이 나옵니다.
논문에서는 additional trick을 사용했는데 특정 레이어에서만 gpu에 상관없이
모든 커널을 가져다 사용할 수 있는걸 이야기합니다.
이런 과정으로 실제로 top5에러는 1.2%, top1에러는 1.7% 정도 감소를 할 수 있었다고 합니다.
3-3. Local Response Normalization(LRN)
- ReLU 함수는 무한하기 때문에 LRN이 일반화(generalization)에 도움이 됨
- 특정 값에 의해 과대적합 되는 것을 방지할 수 있음
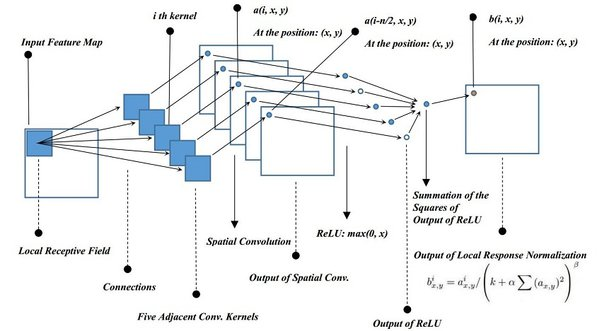
예시로 주변이 다 1인데 가운데만 10이면 전체적으로 값이 높게 뛰는게요,
이렇게 특정값에 의해 오버피팅이 되는 것을 방지하기 위해 LRN 사용했습니다.
만약 현재 10번째 커널이라면 8번째 커널부터 12번째 커널까지의 제곱합으로
나눠주어 정규화를 진행했습니다.
결과로 top1 에러랑 top5에러가 각각 1.4%, 1.2% 감소했습니다.
3-4. Overlapping Pooling

traditional pooling은 겹치지 않고 두칸씩 줄였지만 overlapping pooling은
1~3, 2~4 이렇게 겹치게 pooling window의 크기가 stride의 크기보다 크게 구현했고요,
나오는 output size는 똑같지만 오버피팅이 덜 되기 때문에 에러도 0.4%, 0.3% 줄일수 있었다고 합니다.
4-1. Reducing Overfitting : Data argumentation
Image Translation and horizontal reflection
- 256x256 사이즈로 만든 이미지를 랜덤으로 잘라 224x224 사이즈로 잘라 1024배 증가시킴
- 좌우반전을 사용해 이미지의 양을 2배로 증가시킴
- (256 - 224)^2 * 2 = 2048배 증가, 1만장을 2천만장으로 증가시킴
이러한 과정으로 인해 과적합이 감소하는 효과를 볼 수 있었습니다.
Test
- 4개의 코너, 중심 5개의 patch를 좌우반전시켜 총 10개의 224x224 patch 생성
- 10개의 patch의 softmax 결과값을 평균을 내서 사용
4-2. Reducing Overfitting : Jittering
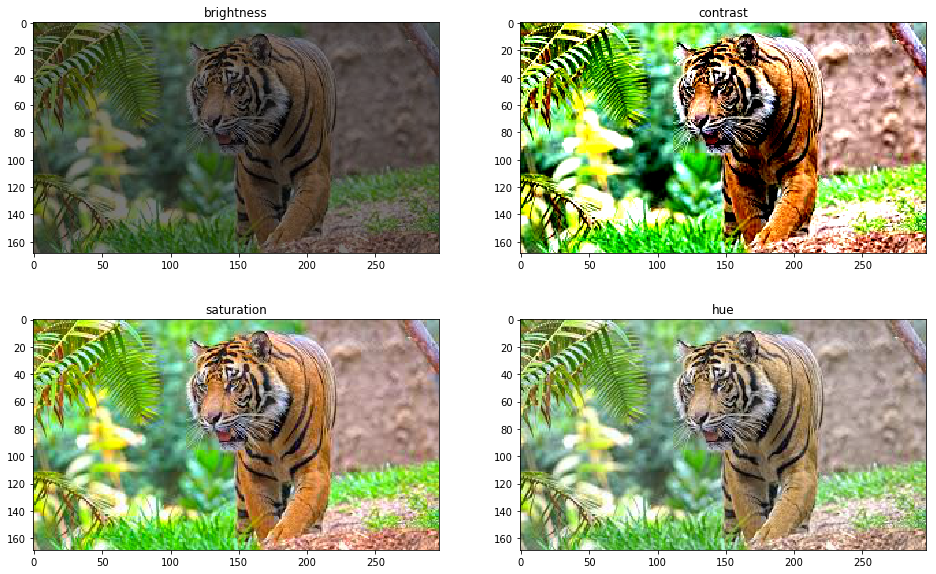
-
RGB 픽셀 값에 PCA를 통해 찾은 중요성분들만큼 랜덤하게 더함
-
전체 이미지의 R, G, B 공분산(3x3)에서 고유벡터, 고유값을 구함
-
다음과 같은 값을 모든 픽셀에 더함
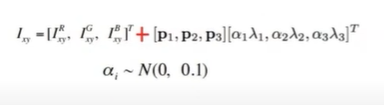
-
top1 error rate를 1% 이상 줄였음
4-3. Reducing Overfitting : DropOut
-
0.5의 확률로 hidden neuron의 값을 0으로 바꿈
-
드랍아웃된 hidden neuron은 forward, backpropagation시 영향을 끼치지 않음
-
뉴런들 사이의 의존성을 낮추고, co-adaptaion을 피할 수 있음

-
3개의 Fully-connected Layer 중 앞의 2개에만 적용
-
Test시 드랍아웃을 적용하지 않고 대신 0.5를 곱함
5. Qualitative Evaluations

병렬 처리를 하는 GPU 두대는 각기 상하로 처리하는 정보를 나눴는데
GPU1은 색감과 관련이 없는 정보를 학습시키고 GPU2는 색감과 관련있는 정보를 학습시켰습니다.
