VGGNet
VGGNet은 Visual Geometry Group VGG에서 발표한 모델이고
ILSVRC-2014 대회에서 준우승을 한 모델입니다.
준우승이였지만 사용하기 쉬운 구조와 성능이 우수해
우승한 GoogleNet보다 더 큰 인기를 얻었습니다.
대표적으로 VGGNet16, VGGNet19 두 종류가 있는데 뒤에 붙은 숫자들은
각각 레이어의 갯수에 따라 숫자가 붙었습니다.
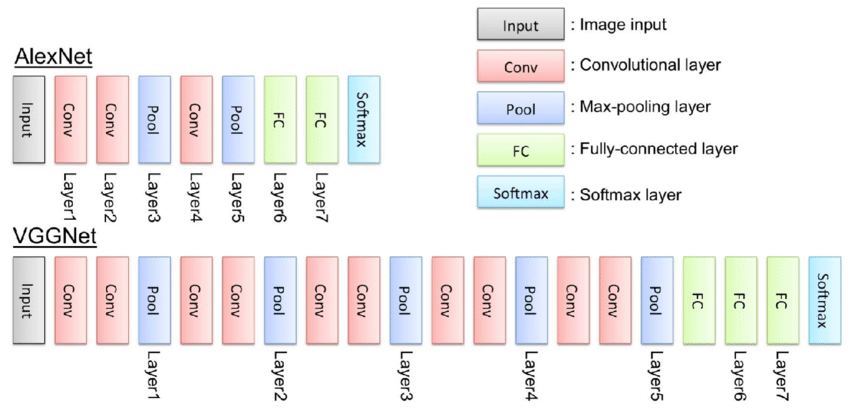
2012년의 AlexNet과 비교해 보면 레이어의 깊이가 2배 넘게 차이나는 것을 확인할 수 있습니다.
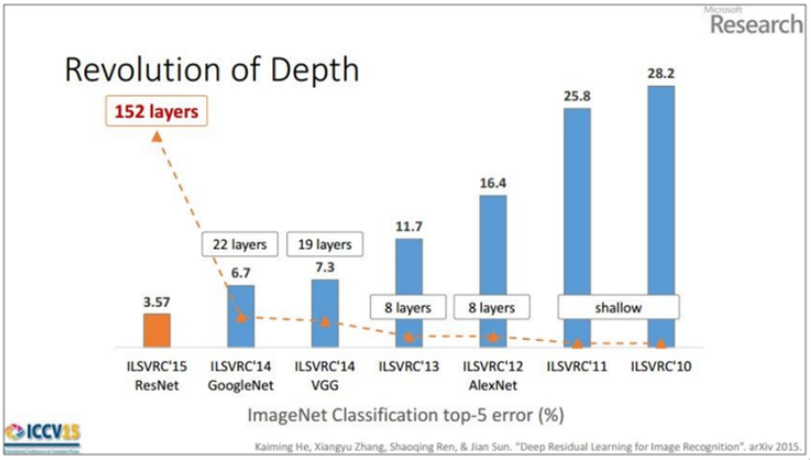
2012년과 2013년에 우승한 모델들은 레이어의 갯수가 8개의 층으로 이루어져 있지만
2014년의 VGGNet(VGGNet19)는 19개로 구성되었습니다.
네트워크의 층이 깊어질수록 더욱 에러율이 낮아진다는걸 확인 할 수 있습니다.
결론적으로 성능이 상승되었습니다.
VGGNet 구조
이 논문의 이 연구의 핵심은 네트워크의 깊이를 깊게 만드는 것이
성능에 어떤 영향을 미치는지를 확인하고자 하는 것입니다.
그래서 레이어의 깊이에 따른 영향만을 확인하기 위해 conv 필터 커널의 사이즈는
가장 작은 3x3 사이즈로 고정했습니다
필터 커널의 크기를 가장 작게 만들었기 때문에 네트워크의 깊이를 깊게 만들 수 있었습니다.
만일 필터 커널의 사이즈가 더 크다면 이미지의 사이즈가 금방 축소되기 때문에
네트워크를 충분히 깊게 만들 수가 없습니다.
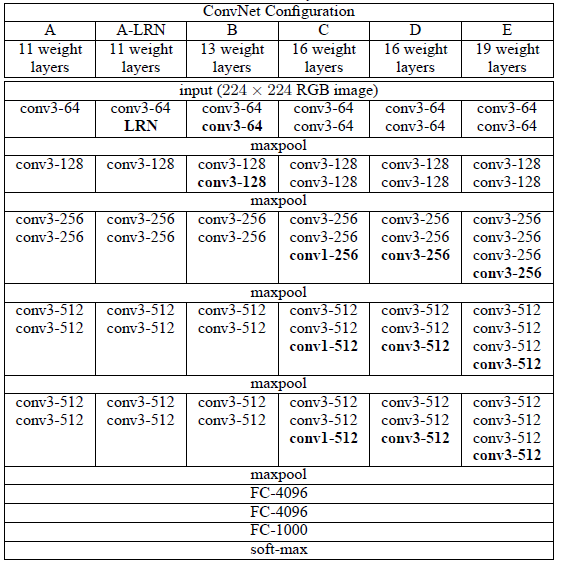
VGGNet에선 총 6개의 레이어 구조를 만들어 성능을 비교했습니다.
(A, A-LRN, B, C, D, E)
여러 개의 구조를 만든 것은 깊이의 따른 성능 비교를 위해서인데,
이중 D 구조가 VGGNet16, E 구조가 VGGNet19입니다.
저자는 AlexNet과 VGG-F, VGG-M 등에서 사용되던 LRN이
A와 A-LRN 구조의 성능을 비교해 본 결과 성능 향상에 별로 효과가 없다고 테스트를 통해 확인했습니다.
(LRN은 간단하게 말하면 매우 높은 하나의 픽셀값이 주변 픽셀에 영향을 미치는 것을 방지하기 위한 정규화입니다.)
이러한 이유로 더 깊은 B, C, D, E 구조에는 LRN을 적용하지 않았습니다.
또한 깊이가 11층, 13층, 16층으로 점점 깊어질수록 분류 에러가 감소하는걸 관찰했습니다.
즉 깊어질수록 성능이 좋아진다는 것입니다.
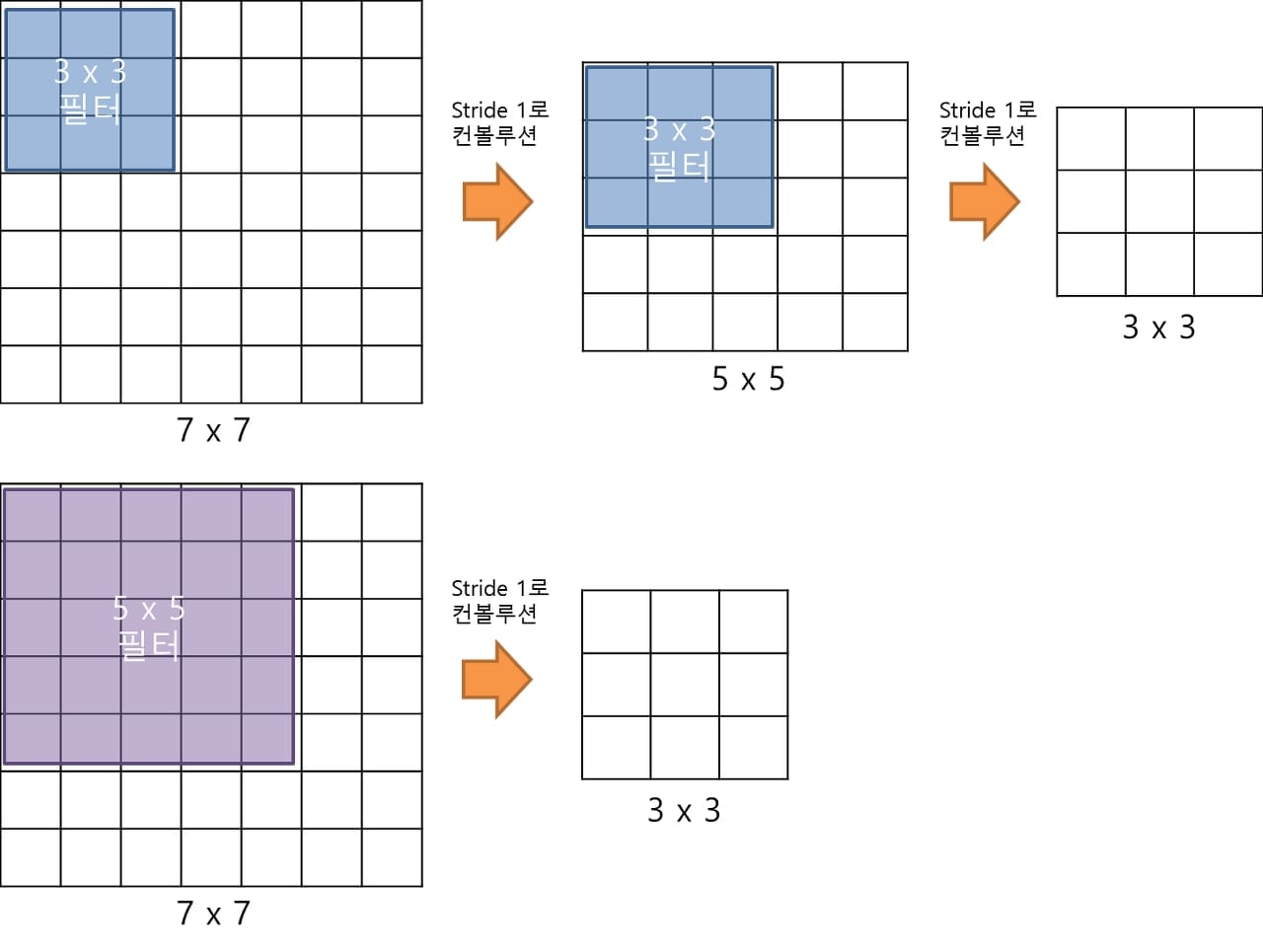
VGGNet의 세부 구조를 먼저 보기 전에 짚고 넘어가야 할 것이 있는데,
3x3 필터로 두 차례 컨볼루션을 하는 것과 5x5 필터로 한 번 컨볼루션을 하는 것이
결과적으로는 똑같은 사이즈의 특성맵을 생성합니다.
또한 3x3 필터로 3번 컨볼루션 하는 것은 7x7 필터로 1번 컨볼루션 하는 것과 대응됩니다.
그러면 3x3 사이즈로 3번 컨볼루션 하는 것과 7x7 사이즈로 1번 하는 것과는
무슨 차이가 있냐 하면 가중치 또는 파라미터의 갯수가 다릅니다.
3x3 필터가 3개면 총 27개의 가중치를 갖지만, 7x7 필터는 49개의 가중치를 갖습니다.
가중치가 적다는 것은 곧 훈련시킬 것이 곧 적어진다는 의미입니다.
그래서 학습의 속도가 빨라집니다.
VGGNet16 구조 분석
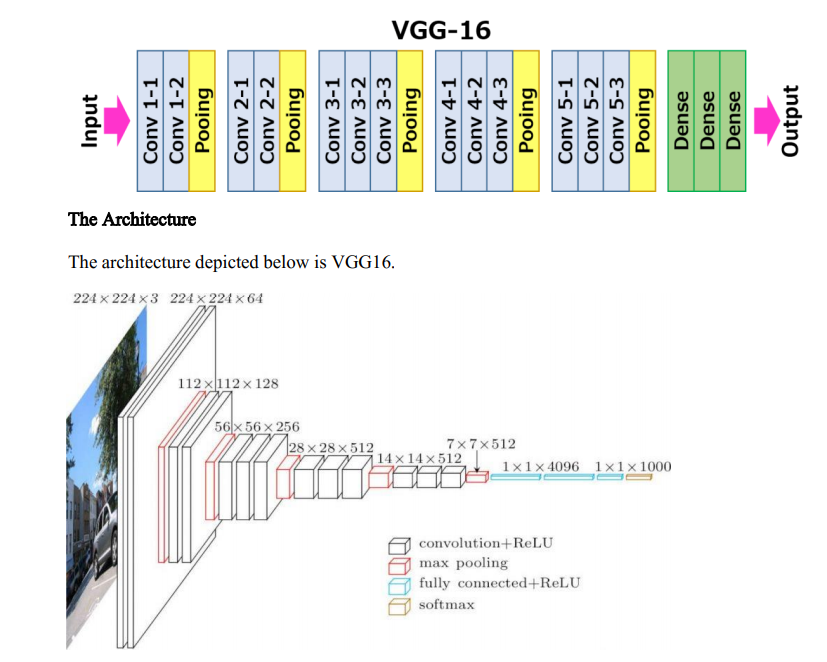
먼저 인풋으로 224x224x3(R, G, B 총 3개) 사이즈의 이미지를 읽어들입니다.
1) 1층(conv1_1)
64개의 3 x 3 x 3 필터커널로 입력이미지를 컨볼루션해줍니다.
zero padding은 1만큼 해줬고, stride는 1로 설정합니다. 결과적으로 64장의 224 x 224 특성맵(224 x 224 x 64)들이 생성되고, 활성화 함수로 ReLU 함수가 적용됩니다.
(ReLU함수는 마지막 16층을 제외하고는 항상 적용)
2) 2층(conv1_2)
64개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해줍니다. 결과적으로 64장의 224 x 224 특성맵들(224 x 224 x 64)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용함으로 특성맵의 사이즈를 112 x 112 x 64로 줄인다.
3) 3층(conv2_1)
128개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해줍니다. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출됩니다.
4) 4층(conv2_2)
128개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션해줍니다. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출되고, 그 다음에 2 x 2 최대 풀링을 stride 2로 적용합니다. 특성맵의 사이즈가 56 x 56 x 128로 줄어들었습니다.
5) 5층(conv3_1)
256개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성됩니다.
6) 6층(conv3_2)
256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성됩니다.
7) 7층(conv3_3)
256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성되고, 그 다음에 2 x 2 최대 풀링을 stride 2로 적용합니다. 특성맵의 사이즈가 28 x 28 x 256으로 줄어들었습니다.
8) 8층(conv4_1)
512개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성됩니다.
9) 9층(conv4_2)
512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성되었습니다.
10) 10층(conv4_3)
512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성되고, 2 x 2 최대 풀링을 stride 2로 적용합니다. 특성맵의 사이즈가 14 x 14 x 512로 줄어들었습니다.
11) 11층(conv5_1)
512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성됩니다.
12) 12층(conv5_2)
512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성됩니다.
13) 13층(conv5-3)
512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션합니다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성되고, 2 x 2 최대 풀링을 stride 2로 적용합니다. 특성맵의 사이즈가 7 x 7 x 512로 줄어들었습니다.
14) 14층(fc1)
7 x 7 x 512의 특성맵을 flatten 해줍니다. flatten은 전 층의 출력을 받아서 1차원의 벡터로 펼쳐주는 것을 의미합니다. 결과적으로 7 x 7 x 512 = 25088개의 뉴런이 되고, fc1층의 4096개의 뉴런과 fully connected 됩니다. 훈련시 dropout이 적용되었습니다.
15) 15층(fc2)
4096개의 뉴런으로 구성됩니다. fc1층의 4096개의 뉴런과 fully connected 되고, 훈련시 dropout이 적용됩니다.
16) 16층(fc3)
1000개의 뉴런으로 구성됩니다. fc2층의 4096개의 뉴런과 fully connected 됩니다. 출력값들은 softmax 함수로 활성화됩니다. 1000개의 뉴런으로 구성되었다는 것은 1000개의 클래스로 분류하는 목적으로 만들어진 네트워크란 뜻입니다.
