복습
python의 built-in data-type 으로는 6가지가 존재했다.
- numeric
- sequence : list[], tuple(), range(start, end, step)
- text sequence : list
- mapping : dictionary{}
- set : set{}
- bool : True/False
많은 양의 데이터를 한 번에 처리할 때 시간적으로 메모리적으로 효율을 챙길 수 있도록 외부의 라이브러리를 사용하게 되는데 그것이 numpy 가 제공하는 ndarray 라는 배열.
기존의 파이썬에는 list 자료구조가 있을 뿐, 배열 자료구조가 없었기 때문에 다차원의 개념이 존재하지 않았다.
import numpy as np
np.array([리스트])
np.arange(정수)
np.array([리스트]).reshape((튜플))
np.shape
np.size
...하지만 실 사용에는 사용하기가 불편하기 때문에, numpy가 제공하는 자료구조(ndarray) 를 이용해서 편하게 데이터 분석을 할 수 있도록 도와주는 외부 라이브러리를 사용하게 된다.
그것이 pandas 이다.
pandas 의 사용 목적은 여럿 존재한다.
- EDA, 탐색적 데이터 분석이 가능해진다.
- 데이터 전처리
** 머신러닝, 딥러닝을 할 때에는 데이터를 기계에게 학습시키는 과정이 필요하다. 그리고, 학습을 시키는 데이터는 정확한 신뢰도가 있어야만 기계에게 학습시키는 의미가 존재하고, 정확한 데이터로 학습이 되어야만 올바른 추론이 가능해진다.
이를 위해서 많은 양의 데이터를 학습에 적합한 데이터로 전처리를 하는 과정이 필요한데, 이 때 pandas 를 사용하게 된다.
Pandas 에는 Series 와 DataFrame 이라는 개념이 존재한다.
-
Series : 1차원의 개념.
1차원 ndarray 를 표현하는데 기존의 numpy 와의 가장 큰 차이점은 사용자 지정 인덱스를 생성할 수 있다는 점이다. 사용자 지정 인덱스의 경우, 시계열 인덱스(날짜)를 생성할 때 자주 하게 된다. -
DataFrame : 2차원의 개념.
2차원 ndarray 를 표현하고, Series 의 집합이라고도 볼 수 있다. 즉 여러 개의 Series 를 각각의 컬럼으로 모아놓는, 일종의 excel 의 테이블과도 같은 구조를 띈다.
일반적으로 csv file 로 되어 있는 데이터를 읽어들여서 DafaFrame 을 생성하게 된다.
수동적으로 생성할 경우, dictionary 자료구조를 이용해서 dataframe 을 만들 수 있다.
주의해야 할 점은, dataframe 은 columns index 와 row index 가 존재한다.
pandas 에서 원하는 데이터를 가져오기 위해서는 4가지 방식을 사용하게 된다.
- index 를 직접적으로 명시해서 가져오는 방법
- slicing 을 통해 가져오는 방법
- boolean indexing 을 통해 조건을 걸어서 가져오는 방법
- fnacy indexing 을 통해서 원하는 행/열의 인덱스를 지정해서 가져오는 방법
연습문제

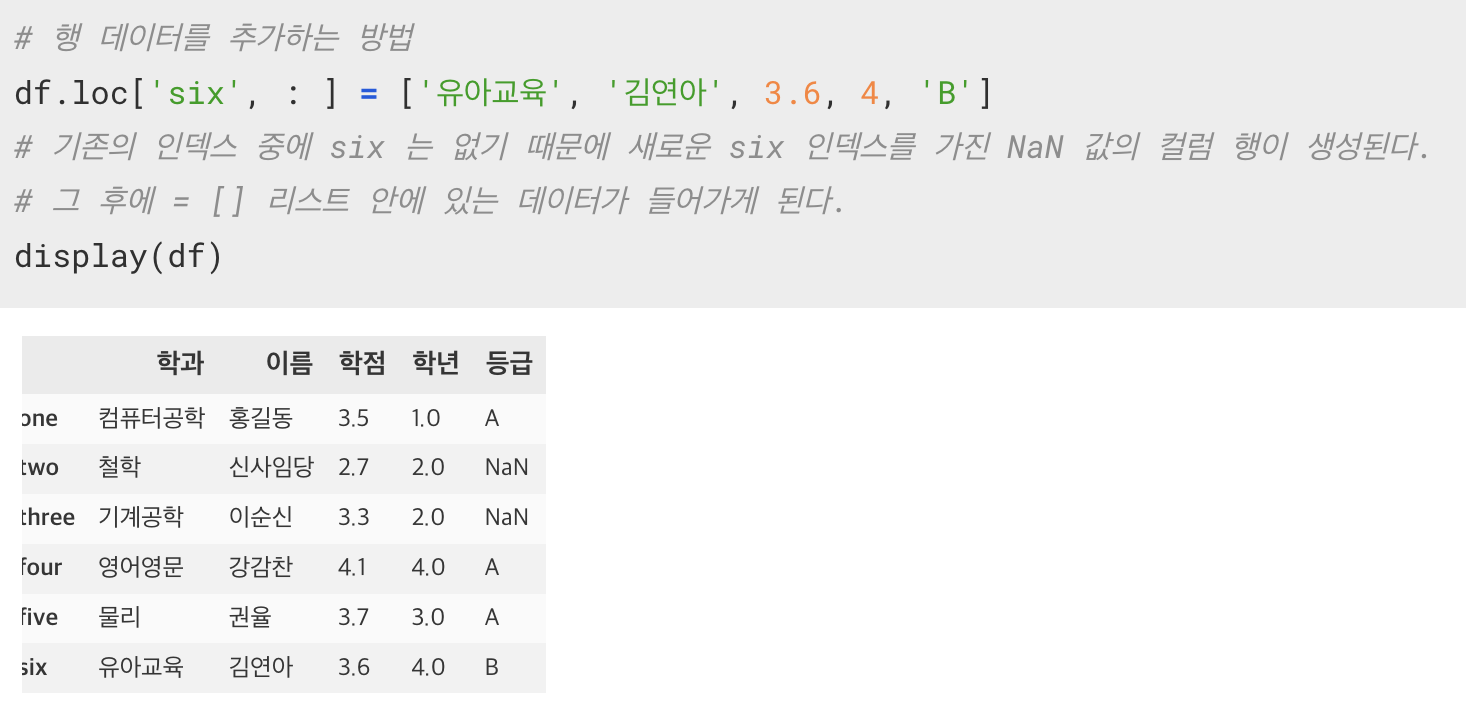
DataFrame 에 행 데이터 추가하기
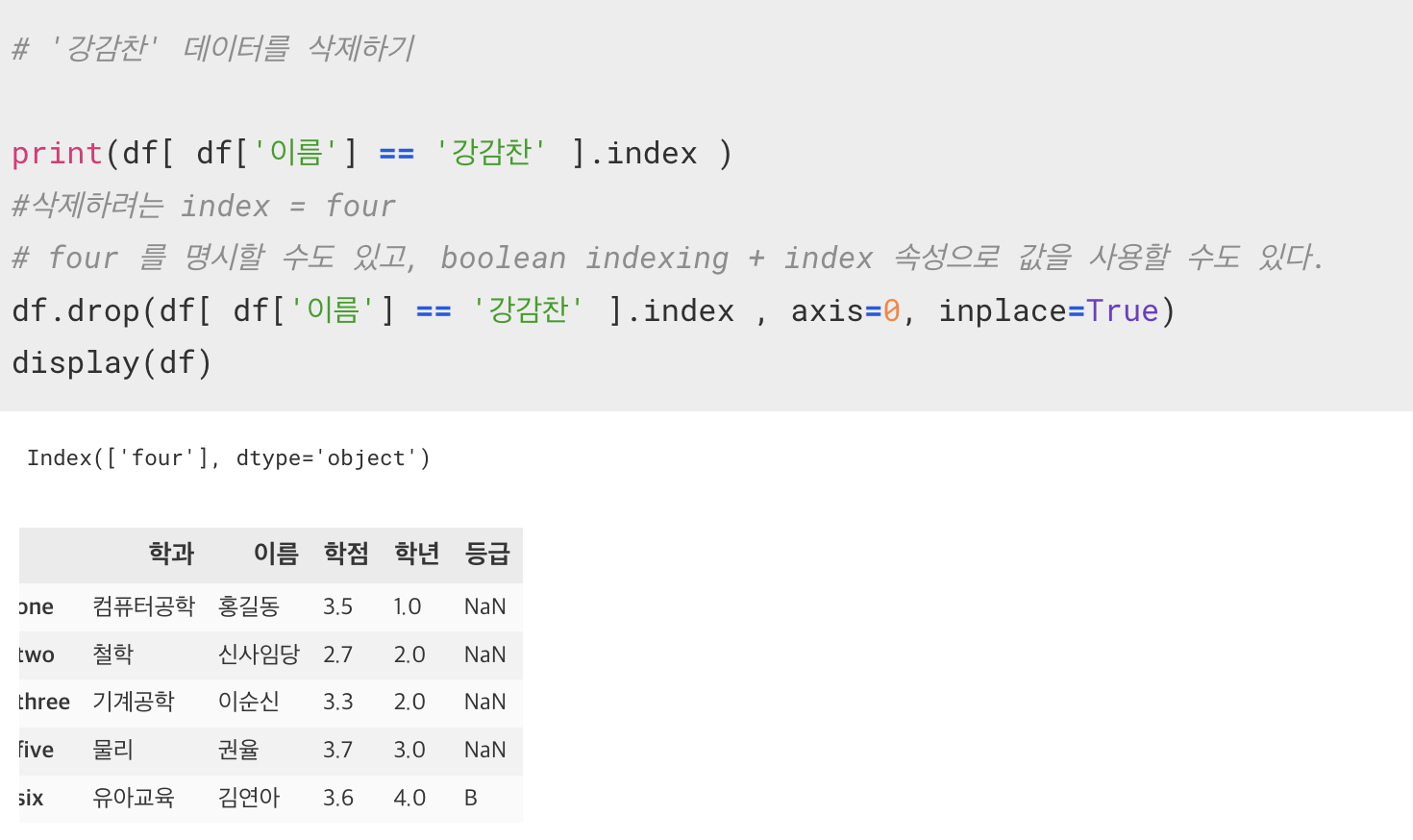
DataFrame 에서 행 데이터 삭제하기
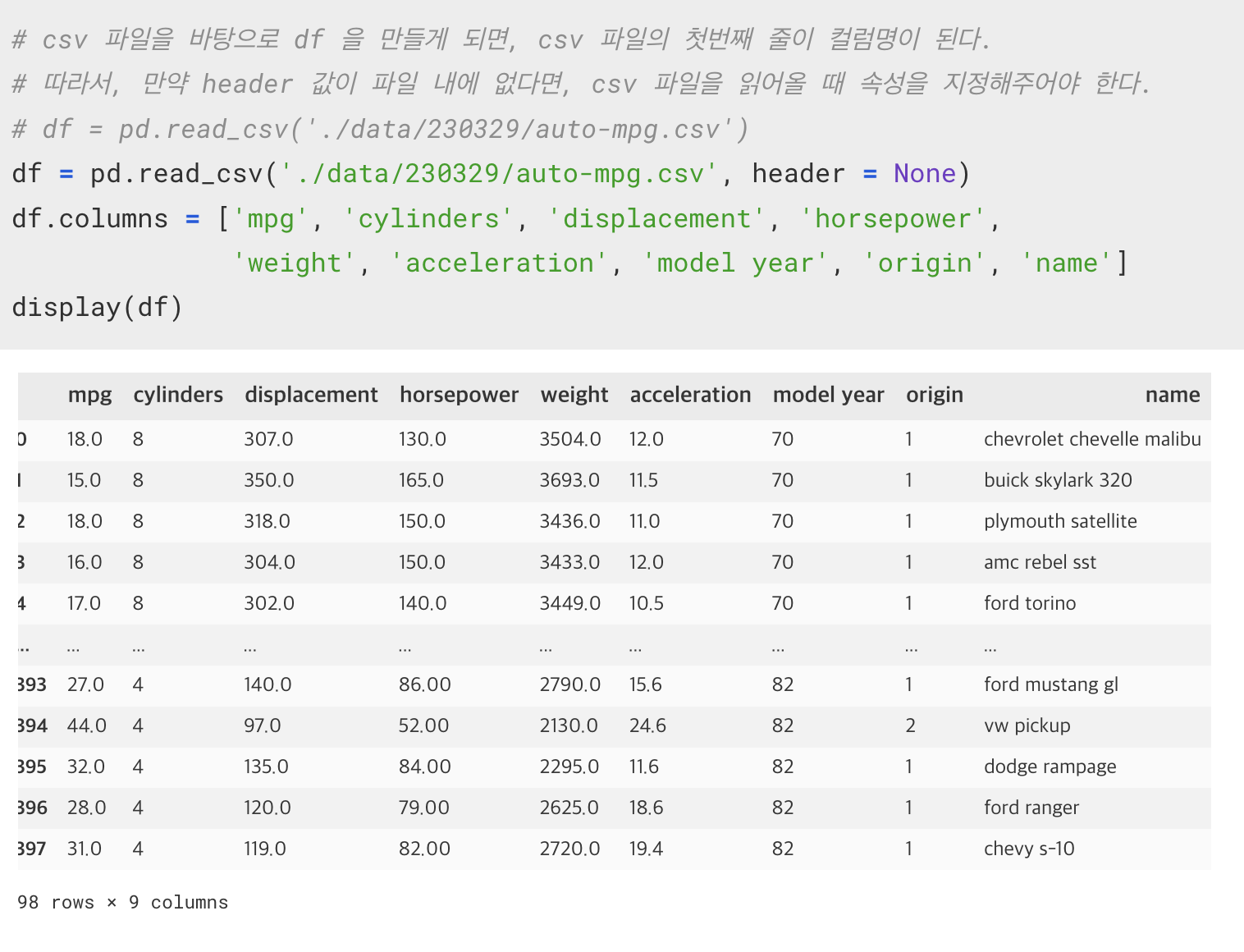
csv 파일을 통해 DataFrame 생성
numpy 에서 제공하는 함수
np.random.perimutation()

Pandas 에서 제공하는 함수
pd.date_range('시작날짜', periods=날짜)
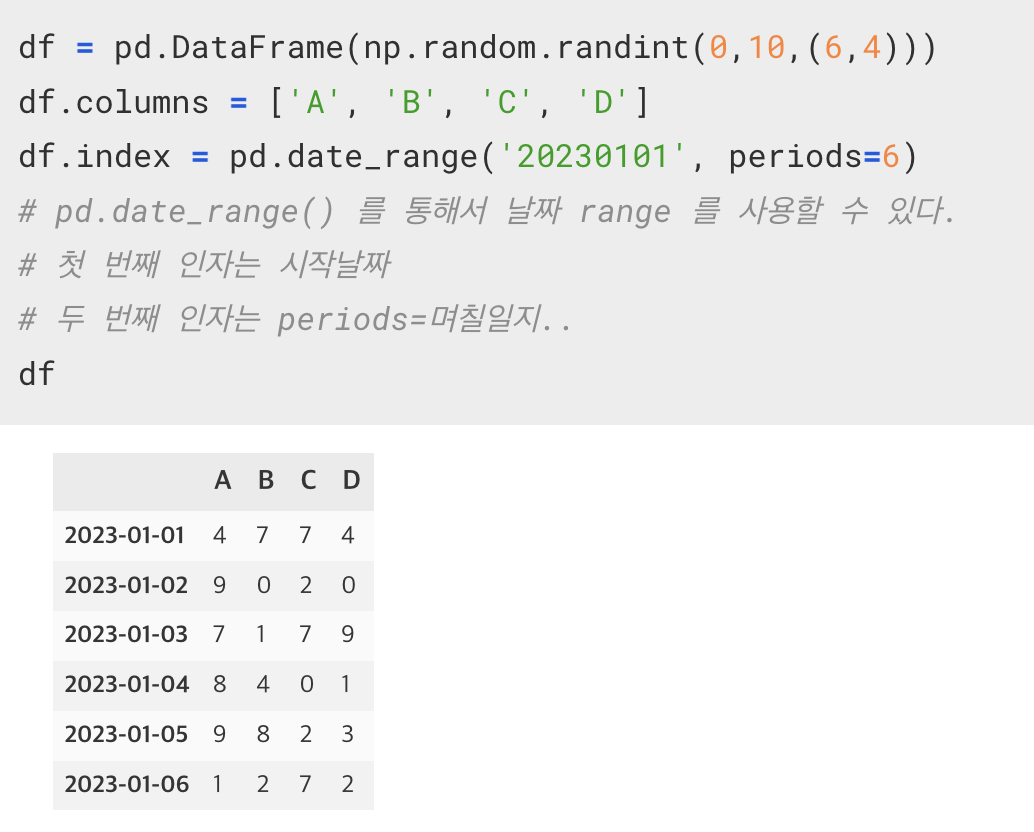
pd.date_range() 를 통해서 날짜 range 를 사용할 수 있다.
첫 번째 인자는 시작날짜
두 번째 인자는 periods=며칠일지..
DataFrame 이 제공하는 함수
1. head(), tail()
: 데이터를 확인할 때 상위 몇 개, 하위 몇 개를 출력하는 함수.
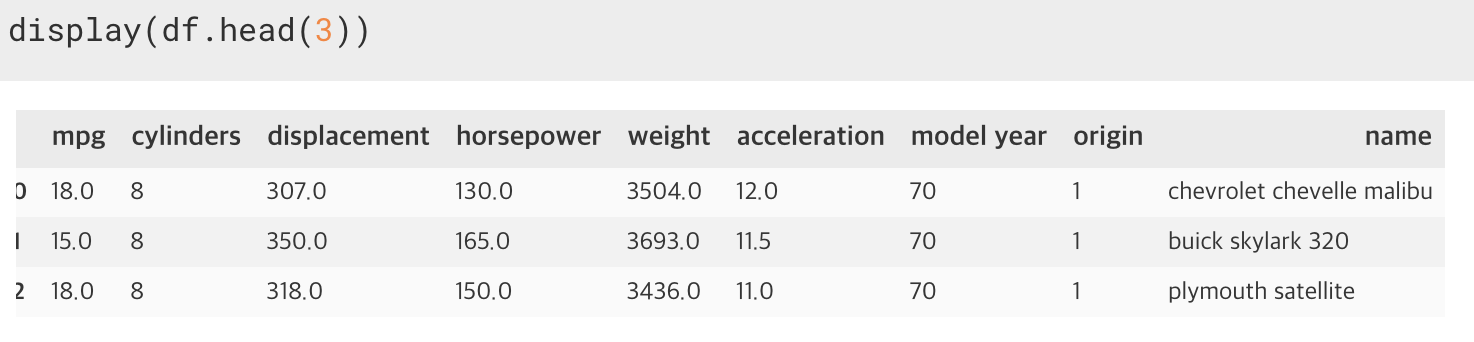
인자로 정수값을 입력하면 해당 정수값만큼 출력한다. 기본값은 5개이다.
2. shape
: 데이터의 갯수, 행과 열의 개수를 알고 싶을 때.

3. count()
: 각 컬럼이 가지는 값의 개수를 알려준다. 중요한 것은 유효한 데이터의 개수만 세줘요.
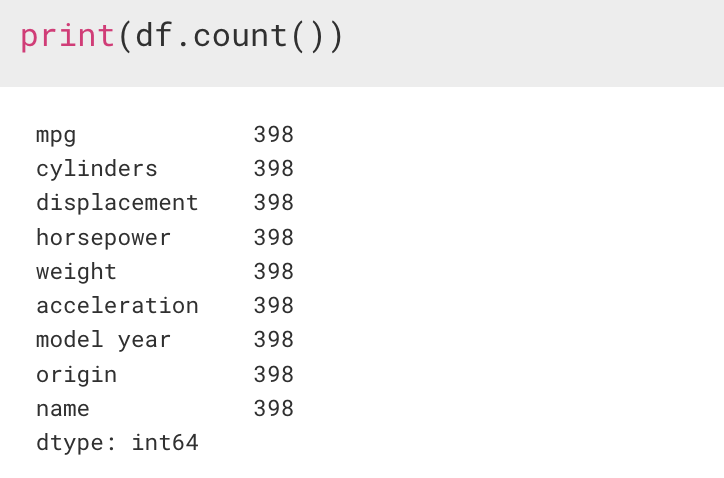
기본적으로 머신러닝에 사용하는 데이터는 결측치가 있으면 안된다.
결측치란 데이터가 빠져있거나 공백인 것을 의미한다. 이유는 기계의 결함, 사람의 실수 등 여러 이유가 존재할 수 있지만 NaN 이라는, 값이 없는 형태로 나오게 되면 안된다.
** 그래서 데이터를 받아오게 되면 가장 먼저 해야만 하는 것이 count() 함수를 사용해서 결측치가 있는지 없는지를 확인하는 것이 가장 먼저 이다.
만약 결측치가 발견되면 1) 삭제 하든가 2) 수정 하든가 해서 반드시 결측치를 제거해주어야 한다.
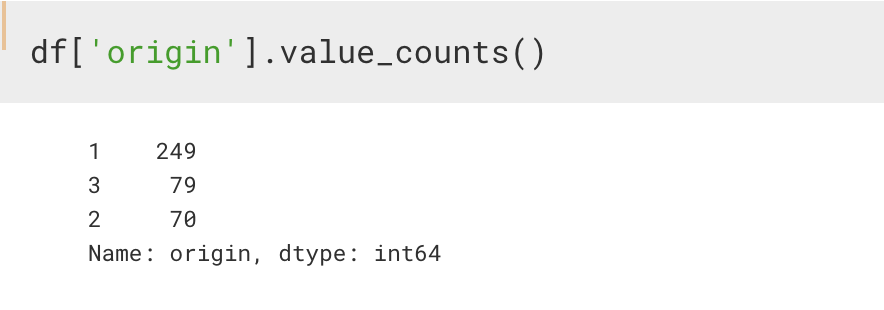
4. value_counts()
Series 에 적용하는 함수로, 고유값을 셀 때 사용하는 함수이다.
5. unique()
value_counts() 와 마찬가지로 Series 에 적용하는 함수이다.
중복을 제거하는 함수이다.

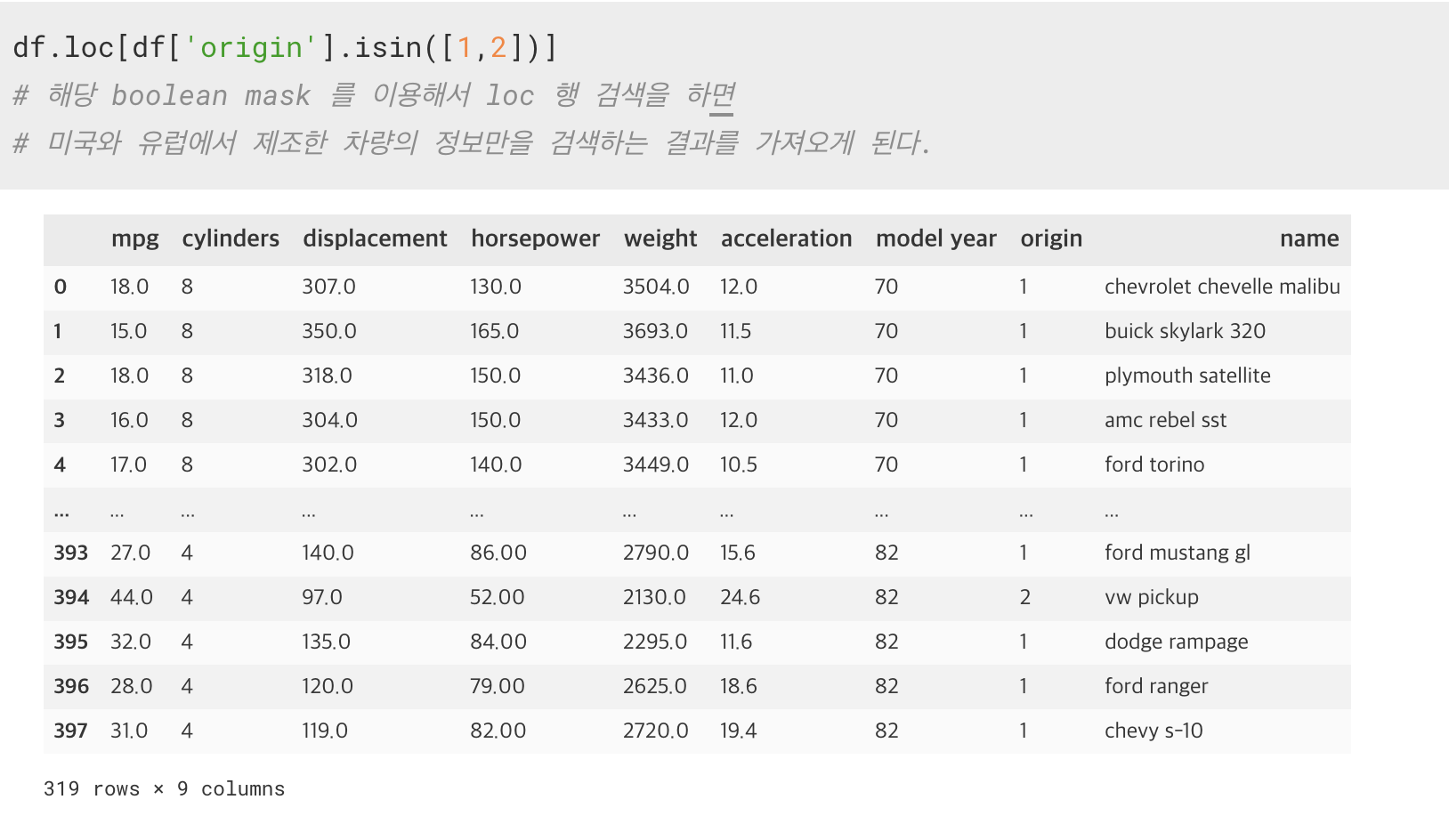
6. isin([리스트])
Series 안에 인자 값이 존재하는 지를 확인하고 True/False 로 리턴하는 함수
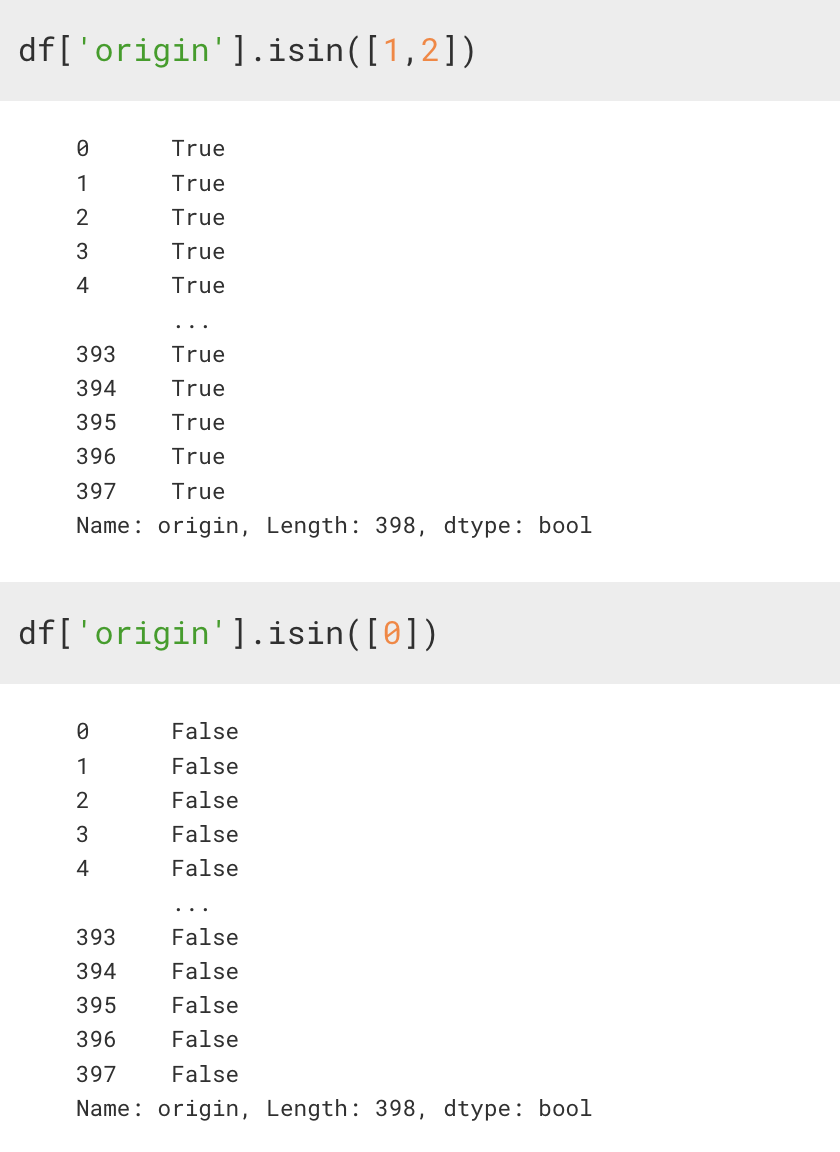
이걸 활용해서 Boolean_mask 를 만들어서 사용할 수도 있게 된다.
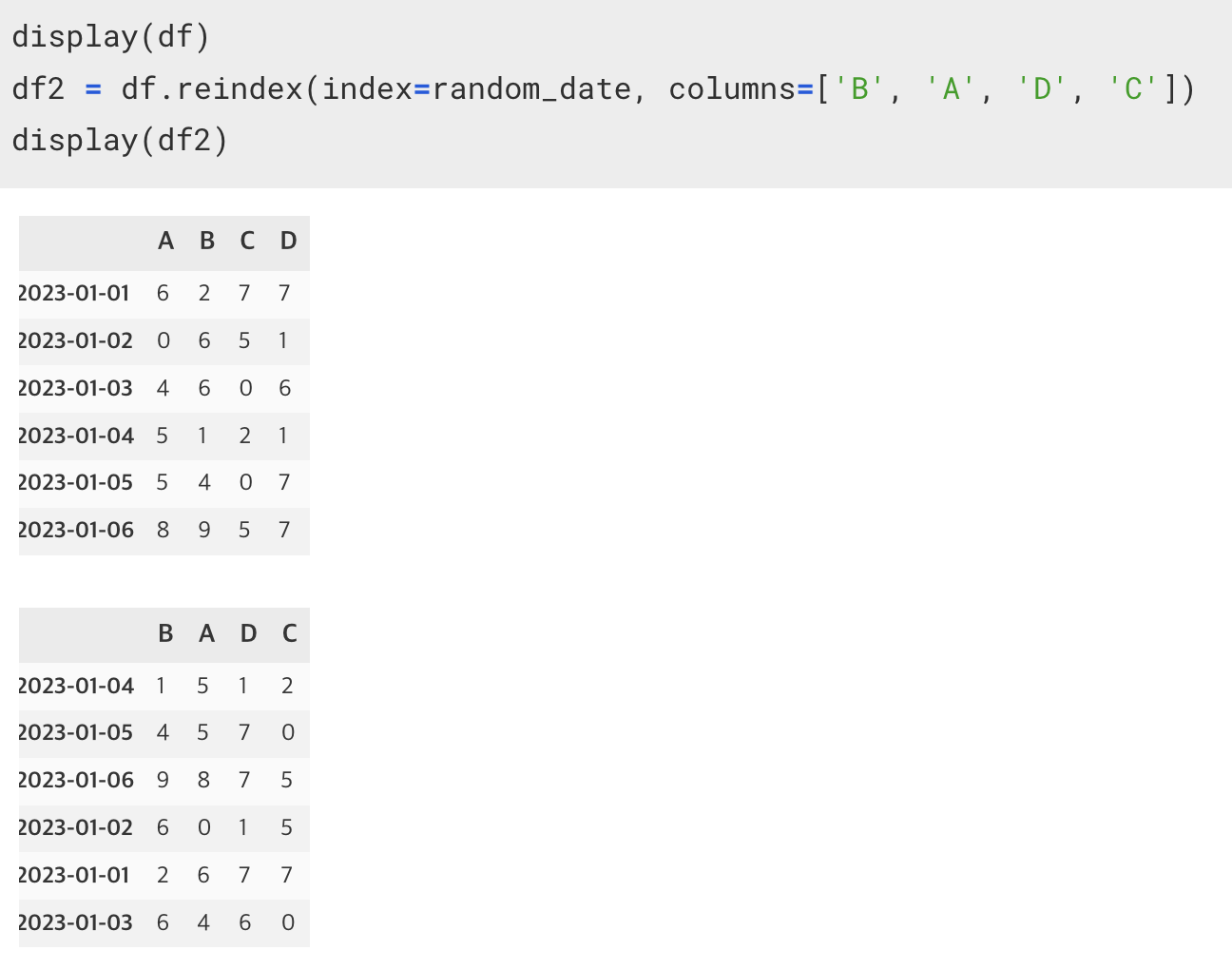
7. reindex(index=[], columns=[])
기존의 df에서 새로운 인덱스, columns 값을 가진 df를 만드는 함수
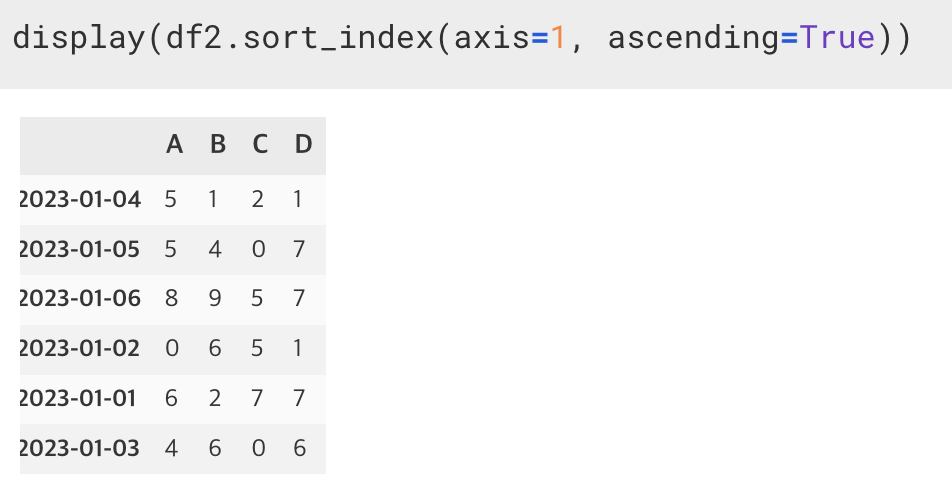
8-1. 인덱스를 가지고 정렬 : sort_index(axis= , ascending=True/False)
8-2. 값을 가지고 정렬 : sort_values(by='정렬하려는columns명', ascending=True/False)

만약, 값이 동일하게 되면 2차 정렬 기준을 기입해주어야 한다.
sort_values(by=['B', 'A'], ascending=True/False)
정렬하려는 columns명을 리스트에 담게 되면 2차, 3차 정렬 조건이 되게 된다.
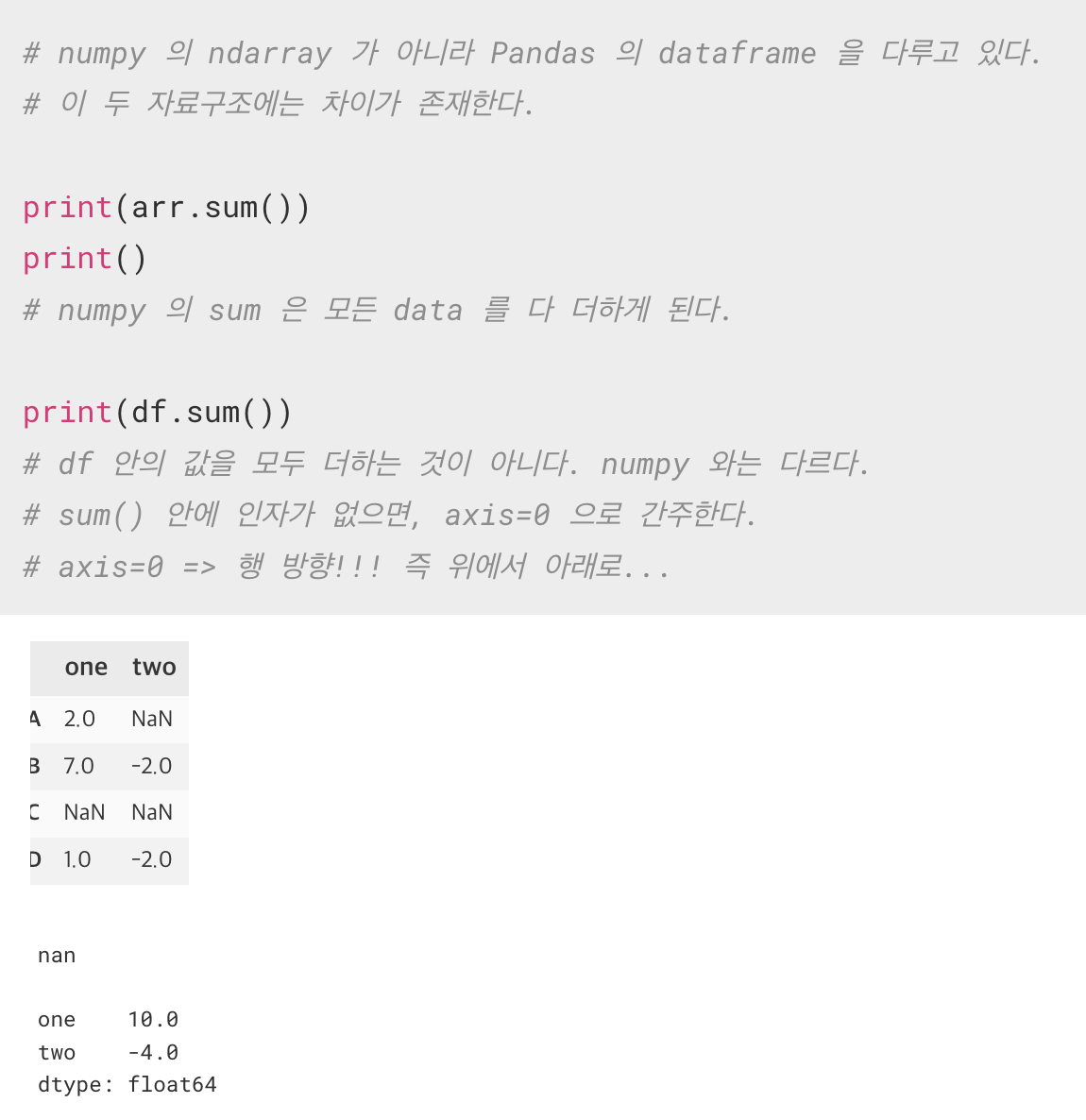
9. sum(), mean()
통계에는 기술 통계 와 분석 통계 등 여러 가지가 존재하는데 , 그 중에서 기술 통계(describe) 부분에는 대표적으로 평균, 합, 편차, 분산, 표준편차, 사분위, 공분산, 상관관계... 등이 있다.


그렇기 때문에 NaN 를 처리해줄 필요가 있다. 처리 방법은 두 가지가 있다.
- 삭제 : 가장 효과적인 방법이지만, 데이터가 충분하지 않을 경우 샘플 데이터의 수가 너무 적어지게 된다.
=> 그렇다면, 데이터의 충분 의 개념은 얼마만큼을 의미하는가?
그 정답은 그때 그때 다르다. 일반적인 상황에서는 10만 건을 기준으로 삼는다.
- 보간(수정) : NaN 을 적절하게 수정해서 사용해야 한다.(Interpolation)
- 값들 중에서 평균 값을 넣기
- 값 중에서 가장 큰 값을 넣기
- 값 중에서 가장 작은 값을 넣기
- NaN 중에서 가장 가까운 위치에 있는 값을 넣기
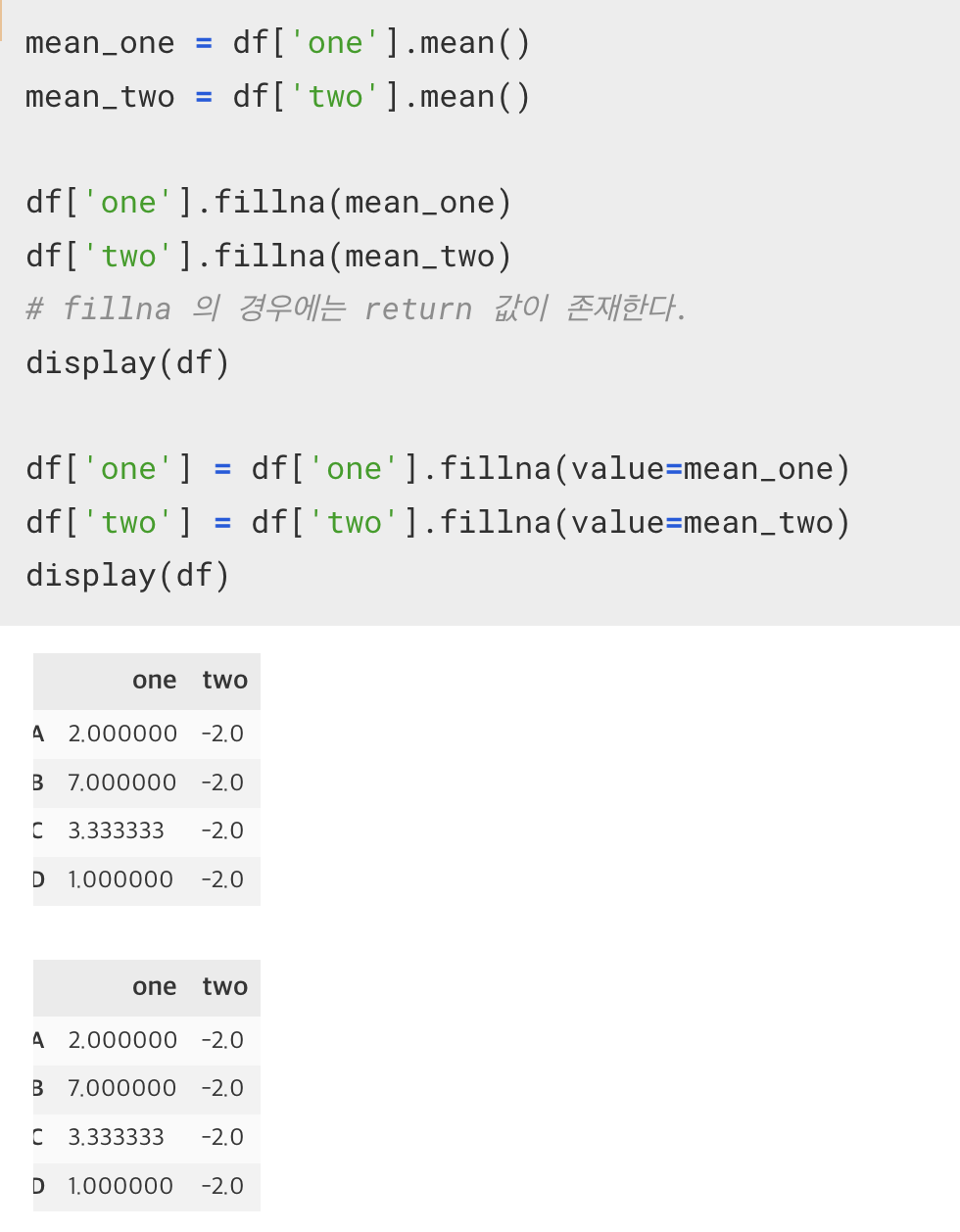
10. fillna()
Series 에서 NaN 값에 대해서 인자 값으로 채우는 함수
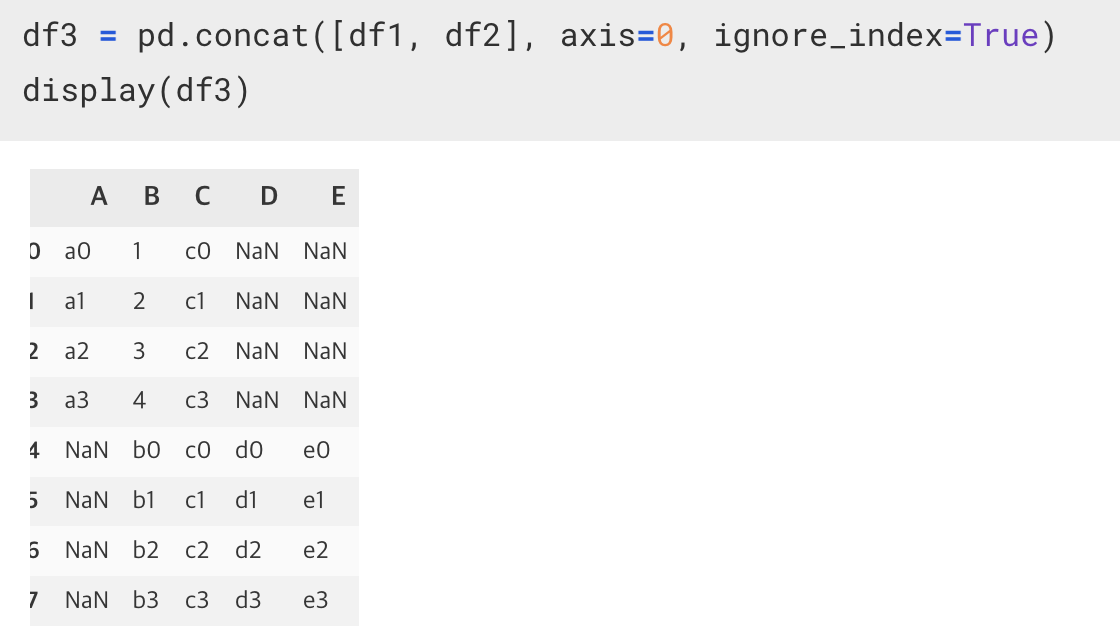
11-1. concat([연결할 df 리스트], axis=어떤방향으로 이어붙일지, ignore_index=True/False 기존의 인덱스를 무시할지말지)
DataFrame 의 연결 혹은 결합에 사용하는 함수
- 위-아래 방향으로 이어 붙인다 => 행 방향으로 이어붙인다.
그 때 사용하게 되는 것은 같은 컬럼명을 기준으로 붙이게 된다.

그러면, 같은 컬렴명이 존재할 경우 이어 붙이게 되고, 같은 컬럼명이 없다면 NaN 으로 처리가 되게 된다.
그런데, 문제는 사용자 지정 index 가 중복이 될 수 있다. (df1 의 인덱스 0123 과 df2 의 인덱스 0123)
- 열 방향으로 합친다 => 인덱스를 기준으로 가로 방향으로 값을 합치게 된다.

11-2. pd.merge(df1, df2, on='join하려는 기준컬럼명', how='inner/outer')

11-3. pd.merge(df1, df2, left_on='df1의 컬럼명', right_on='df2의 컬럼명', how='inner')

12. df.groupby([그루핑할 컬럼명])
sql 의 group by 와 같이 기준을 가지고 그룹으로 묶는 함수

그런데, groupby 를 통해 그룹지어진 dataframe 는 그 자체로는 제대로 묶였는지 확인이 불가능하다.
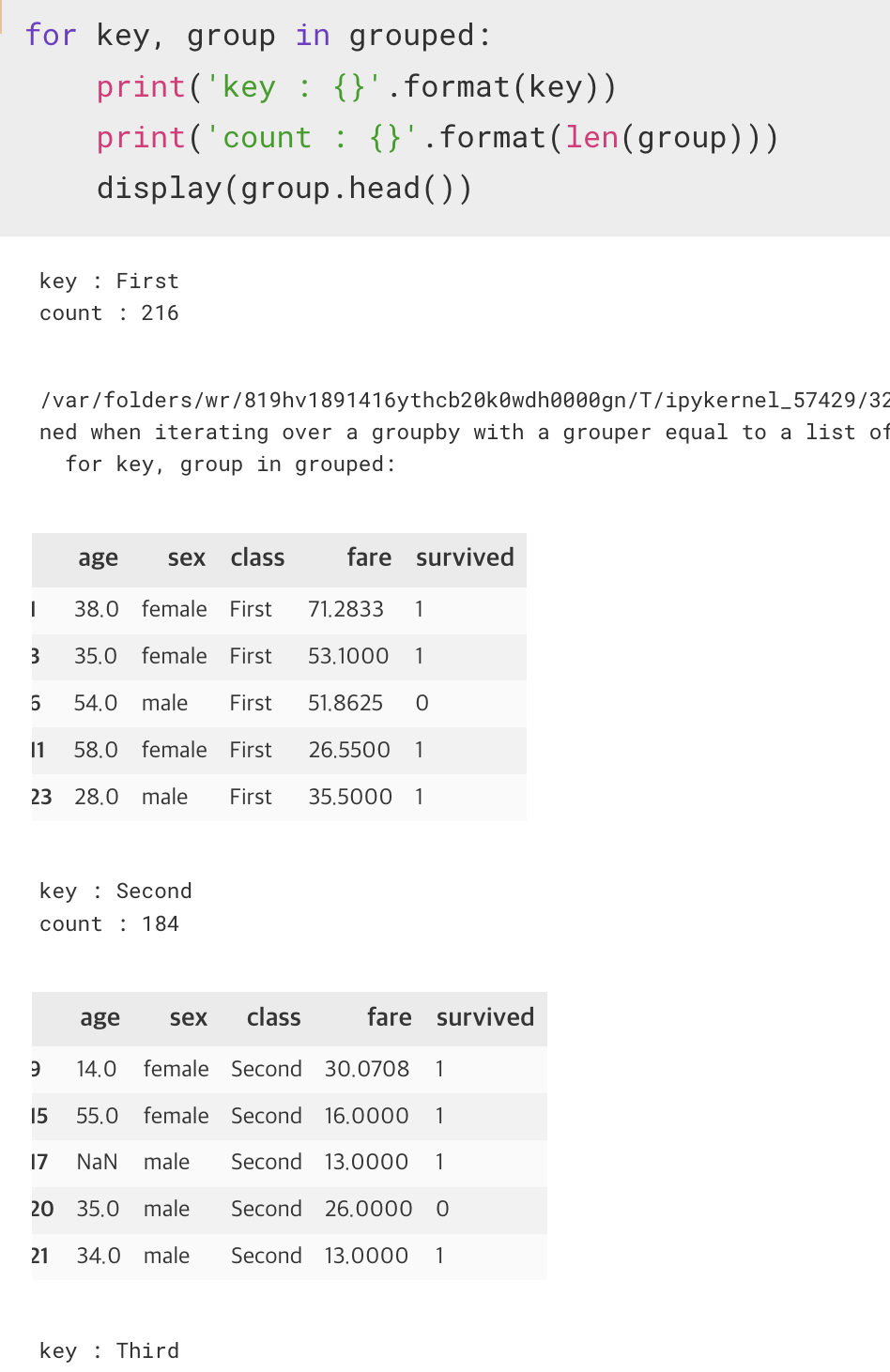
때문에 이것을 확인하기 위해서는 for문을 통해서 값을 뽑아가면서 확인을 돌려야 한다.
grouped.get_group('찾으려는 그루핑의 컬럼명')
** 또한 grouping 은 2차 그루핑도 가능하다.
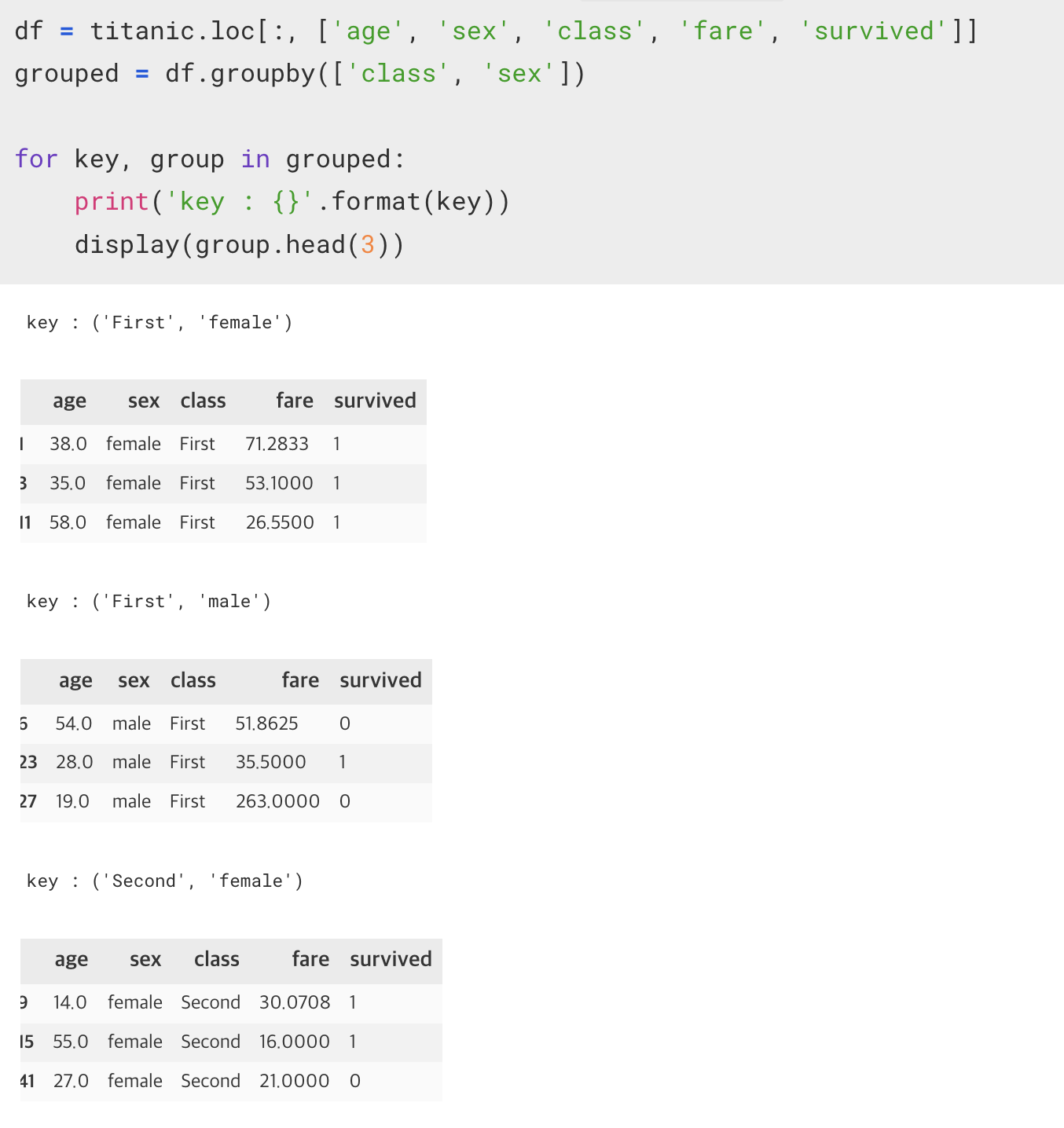
1차적으로 class 로 그룹을 잡은 뒤, 2차적으로 sex 로 그룹을 나누었다.
결과 6개의 그룹이 생성된 것을 볼 수 있다.
group4 = grouped.get_group(('Third', 'female'))
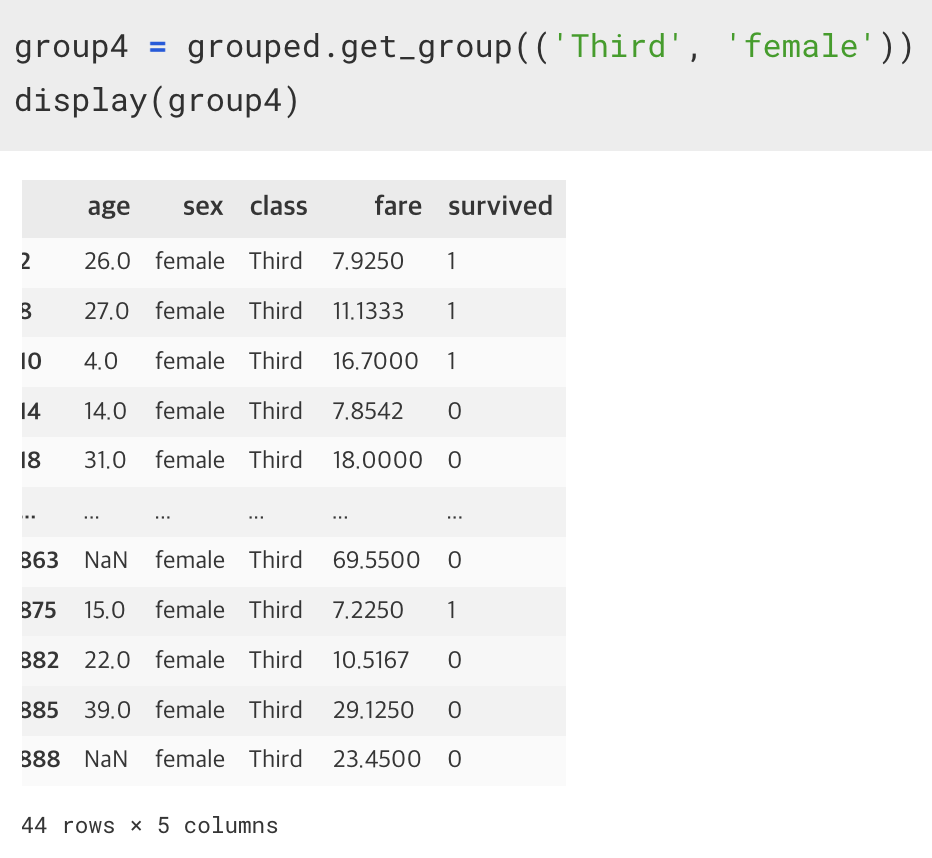
만약 여러 컬럼을 가지고 그루핑된 그룹을 가지고 오게 된다면, 튜플 형식으로 컬럼명을 인자에 넣어준다.
함수매핑
sns.load_dataset('가져오려는 데이터셋 이름')
seaborn 라이브러리 사용
apply(인자)

인자가 하나라면, 그냥 함수의 reference 만 적어주면 된다.
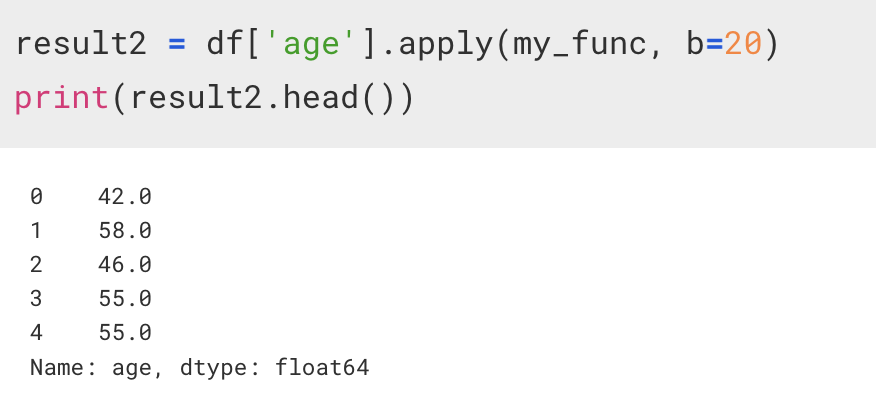
만약 함수의 인자가 2개 이상이라면, 추가적인 인자를 apply에 콤마를 찍어서 나타내준다.
람다식을 이용해서 익명함수를 만들어서 사용도 가능하다.
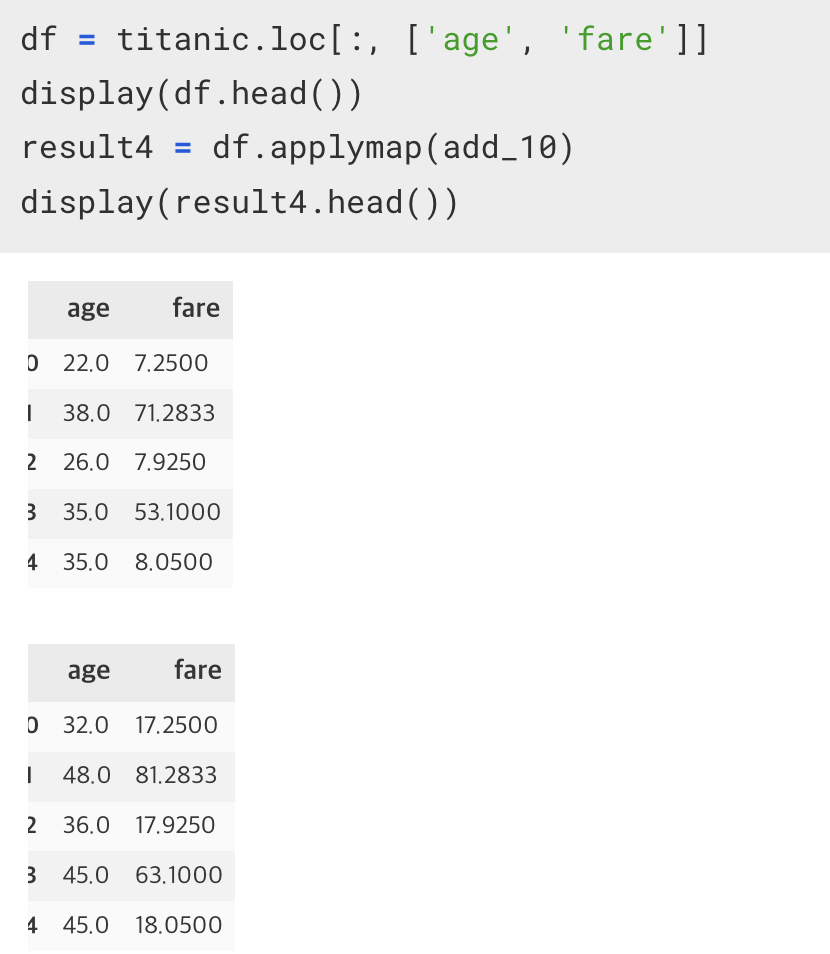
applymap()
이전의 apply 가 Series 를 가지고 함수매핑을 하는 거라면, applymap() 은 dataframe 을 가지고 함수매핑을 하는 함수이다.